Few things that can be learnt here:
- What are ELMo embeddings
- How to use Tensorflow Hub to generate ELMo embeddings
- Tensorflow implementation for Named Entity Recognition using twitter dataset
ELMo is a technique which lead the task of creating word embeddings to a whole new level. So far, Word2Vec, GloVe were widely used for various NLP tasks to deal with language.
The idea of any word embeddings in simple terms is to give words/tokens in a language a numeric form that can be understood by machine learning models.
Word2Vec showed that we can use a vector (a list of numbers) to properly represent words in a way that captures
a. semantic or meaning-related relationships (e.g. the ability to tell if words are similar, or opposites, or that a pair of words like “King” and “Queen” have the same relationship between them as “Man” and “Woman” have between them), as well as,
b. syntactic, or grammar-based, relationships (e.g. the relationship between “had” and “has” is the same as that between “was” and “is”).
There are two ways to obtain word embeddings:
- Learn word embeddings jointly with the main task at hand like text classification, named entity recognition
- Load into your model word embeddings that were precomputed using a different machine learning task than the one at hand. Thesea are called pretrained word embeddings.
And, it was quickly realized that it’s a great idea to use embeddings that were pre-trained on vast amounts of text data instead of training them alongside the model on what was frequently a small dataset. So it became possible to download a list of words and their embeddings generated by pre-training with Word2Vec or GloVe.
If we’re using, for example say, GloVe representation, then the word “stick” would be represented by one particular vector no-matter what the context was.
But ELMo wants to commit a vector to a word only after meeting one condition. It cares about context. So if you ask your ELMo, what is the vector representation of word "stick" it will ask back "What is the context? Use the word in a sentence please?". So basically ELMo needs to see entire sentence in which the word is used before generating its representative numeric vector/embedding. This is how contextual word embeddings were born!!!
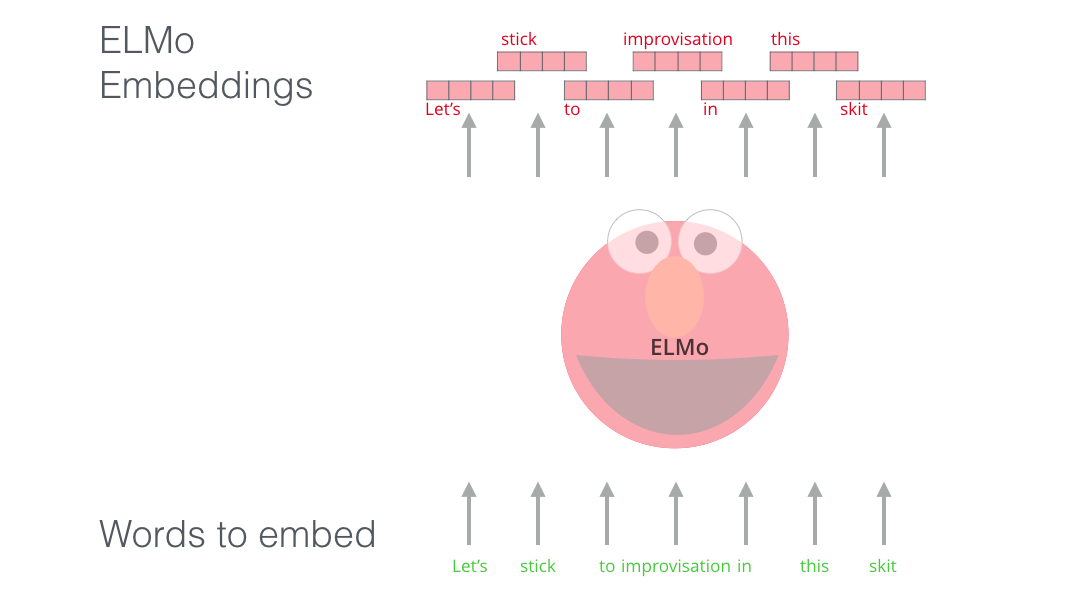
For further intuitive understanding refer to this blog ELMo explained
The detailed explanation about its functioning and architecuture can be referred from the paper Deep contextualized word representations
So what is the secret of ELMo?
ELMo gained its language understanding from being trained to predict the next word in a sequence of words - a task called Language Modeling. This is convenient because we have vast amounts of text data that such a model can learn from without needing labels.
For training language model, it utilizes bidirection LSTMs so that it can caputre context of a word from either sides. It is mentioned in the paper as pre-trained biLM.
As described in the paper (see section 3.4), the final ELMo model (used for pre-training) contains 2 biLSTM layers each will produce their own hidden states. Input to the first biLSTM layer can be some context-independent token representation for each token (character based representations). Finally, contextualized embedding comes through grouping together (by weighted summation) of the following outputs:
- Initial embeddings used
- biLSTM layer 1
- biLSTM layer 2
As a result, the biLM provides three layers of representations for each input token, including those outside the training set due to purely character input. In contrast, traditional word embedding methods that only provide one layer of representation for tokens in a fixed vocabulary.
This biLM can be pretrained on 1B Word Benchmark and later used for downstream tasks by finetuning.
TensorFlow has come up with a deep learning framework called TensorFlow Hub to help us perform the widely utilised activity of Transfer Learning by importing large and popular models in a few lines of code. Deep learning models here are termed as modules.
For this tutorial we will need ELMo module from the hub which contains word embeddings from a language model trained on the 1 Billion Word Benchmark. Check this out TensorFlow Hub ELMo module
Basically, TensorFlow Hub Module just provides us with graph comprising of architecture of model along with it’s weights trained on certain datasets.
The module outputs fixed embeddings at each LSTM layer, a learnable aggregation of the 3 layers, and a fixed mean-pooled vector representation of the input.
- Trainable parameters
The module exposes 4 trainable scalar weights for layer aggregation. (check out equation 1 in the paper), to train them we need to set the trainable parameter to True when creating the module.
- Inputs The module defines two signatures: default and tokens.
With the default signature, the module takes untokenized sentences as input. The input tensor is a string tensor with shape [batch_size]. The module tokenizes each string by splitting on spaces.
With the tokens signature, the module takes tokenized sentences as input. The input tensor is a string tensor with shape [batch_size, max_length] and an int32 tensor with shape [batch_size] corresponding to the sentence length. The length input is necessary to exclude padding in the case of sentences with varying length. For our task we are using tokens signature
- Outputs The output dictionary contains:
word_emb: the character-based word representations with shape [batch_size, max_length, 512].
lstm_outputs1: the first LSTM hidden state with shape [batch_size, max_length, 1024].
lstm_outputs2: the second LSTM hidden state with shape [batch_size, max_length, 1024].
elmo: the weighted sum of the 3 layers, where the weights are trainable. This tensor has shape [batch_size, max_length, 1024].
default: a fixed mean-pooling of all contextualized word representations with shape [batch_size, 1024].
Section 5.3 in the paper talks about what information is captured by the biLM's representations in ELMo model. Intuitively, the biLM must be disambiguating the meaning of words using their context. The paper takes example of word play and illustrates how biLM chooses nearest neighbors differently than GloVe. Refer Table 4 for the same.
This leads to the Word sense disambiguation task which shows how biLM representations can be used to directly make predictions about the sense of a target word. It is illustrated in the notebook Visualizing_ELMo_capture_Semantic_info.ipynb
It takes 5 sentences as examples: Here word work either symbolizes some object made or some sort of action taken in each of the sentences.
- ["I", "love", "this", "beautiful","work", "by", "Vincent", "Van", "Gogh",""]
- ["Tiya", "works", "really", "hard", "for", "exams", "every", "day","",""],
- ["My", "sister", "likes", "working", "at", "Google","","","",""],
- ["This", "amazing", "work", "was", "done", "in", "the", "early", "nineteenth", "century"],
- ["Hundreds", "of", "people", "work", "in", "this", "building","","",""]
For 2 layer biLSTM model employed by us from TensorFlow Hub, we have 2 biLSTM layer representations.
Below are the projection results using PCA, each color point represents the word vector of work in its context:
By using contextual vectors, work has different word vectors depending on different contexts, and the words with the same sense will be close to each other in vector space!
Let's observe the result of 1st LSTM layer

We can cluster the above contextual vectors into 2 groups. The word vectors of work in upper right corner corresponds to the word being used to show some object like piece of art. Whereas on the bottom left corner work represents some action of studying or doing job.
Similarly, we can see there are 2 clusters in the layer 2 ELMo vector space.
Let's observe the result of 2nd LSTM layer

If you compare layer 2 results with layer 1 we can deduct that looking at layer 1 vectors, we can not immediately tell one cluster apart from the other. However, we know that the left three vectors have work as a verb, which means to work, and the right 3 vectors have work as a noun meaning something done or made.
Implies that the cluster formations is more clear and the distance between cluster centroid is larger in the layer 2 ELMo vector space compared to layer 1. The ELMo paper mentions that using the second layer in the Word Sense Disambiguation task results in a higher F1 score than using the first layer. Our observation of the greater distance in the layer 2 vector space shows a possible explanation for the paper’s finding.
The paper claims that lower layers capture basic syntactic information better while higher layers are proficient in capturing semantic information. It demonstrates how different layers in the biLM represent different types of information and thus concludes the success of ELMo in including all biLM layers for the highest performance in downstream tasks.
Finally we attempt the task of recognizing named entities on Twitter with LSTMs in the IPython Notebook Elmo_in_my_NER.ipynb The task of this notebook is to use a recurrent neural network and ELMo embeddings to solve Named Entity Recognition (NER) problem.
Entire problem is implemented in Tensorflow and uses ELMo module from TensorFlow Hub for word embeddings. This notebook is part of homework assignment from Coursera course Natural language processing
- References: