原创教程,转载请联系作者并注明出处:https://github.com/WalkerLau
源码地址:https://github.com/WalkerLau/Accelerating-CNN-with-FPGA
【2019.12更新】本项目GPU加速版本请查看:https://github.com/WalkerLau/GPU-CNN
最近发现很多小伙伴都想用FPGA加速卷积神经网络运算,而恰好我刚做完的本科毕设就是这个题目,所以就有了写这个教程的想法,希望能给还没开始的小伙伴一点思路与帮助,更希望大神们给出一些进一步优化的建议。
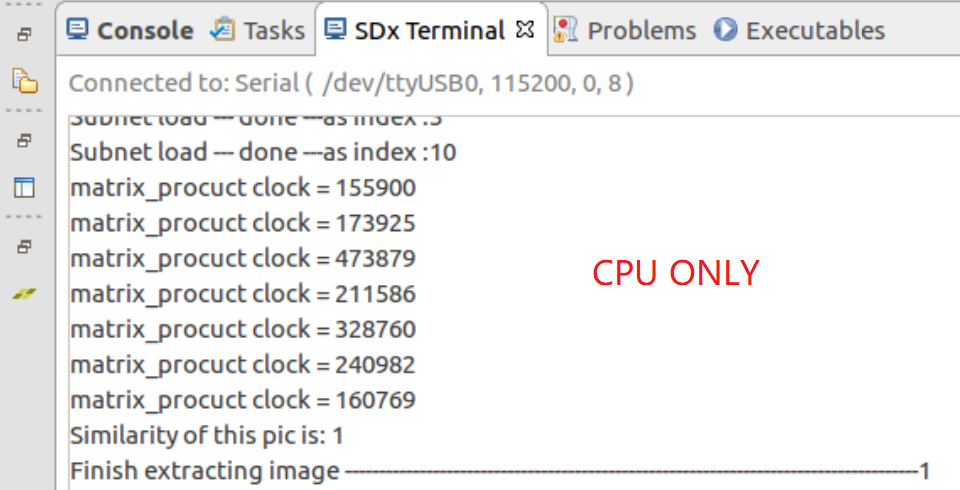
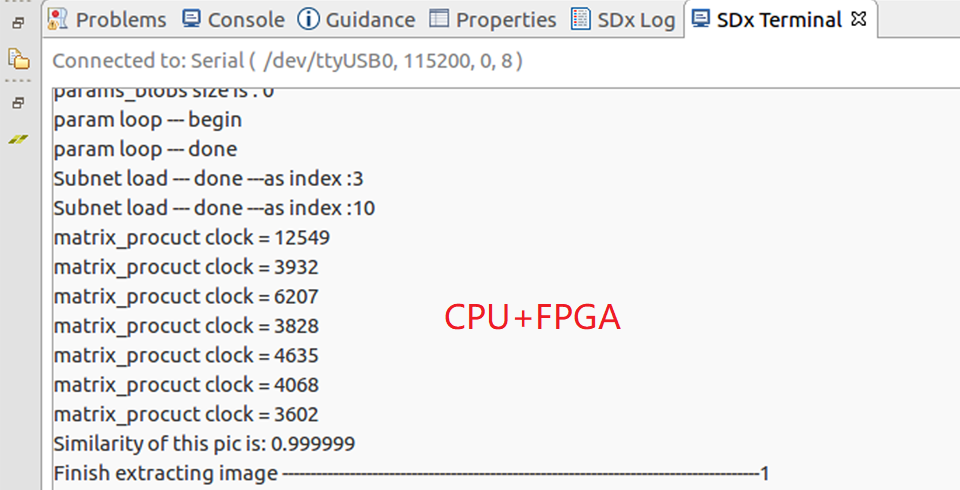
话不多说,先看最终的加速效果。本加速系统仅加速卷积层的运算,下图展示了仅采用CPU和采用CPU+FPGA加速系统来处理VIPLFaceNet人脸识别算法时,计算7个卷积层所耗费的时钟数的对比。由图可见,相比于4核ARM A53处理器,本加速系统最终可以对VIPLFaceNet的大部分卷积层实现45~75倍的运算加速。
本加速系统采用中科院计算所的SeetaFace人脸识别项目进行加速功能的验证,所用的卷积神经网络模型是VIPLFaceNet。本项目的设计工具是Xilinx SDSOC,个人认为这是个人或小团队进行FPGA嵌入式开发最高效的工具,因此不会涉及HDL的编写。本加速系统具有以下特点:
-
容易移植:本项目采用Xilinx SDSOC进行设计,可以直接把C/C++代码综合成FPGA电路,只需修改FPGA加速模块的代码中卷积层结构相关的参数就可以移植到别的卷积神经网络算法中。
-
高性能,采用了如下几种加速策略,具体原理见最后一节:
-
独创的输入体复用架构
-
数据的低精度转换
-
16通道并行计算单元及加法树结构
-
流水线策略
-
片上存储BRAM的partition及卷积层间共享
-
多层卷积的加速实施策略
-
-
硬件:
- Xilinx Ultrascale+ MPSOC ZCU102 (也可以用ZCU104或其他合适的Xilinx嵌入式开发板)
-
软件:
-
Ubuntu 16.04 操作系统(用于安装和运行SDSOC,由于后面需要编译板载Linux系统,必须使用Linux主机不能用Windows,以下所有开发都在Linux环境中进行)
-
Xilinx SDSOC 2018.2 开发套件(戳这里的SDSOC安装及配置教程,请务必跟教程走)
-
Xilinx reVISION platform(由于SeetaFace的小部分代码用到了OpenCV,这里安装reVISION是为了使用里面的xfopencv库,上一项的SDSOC安装教程详细讲了reVISION的安装与使用方法)
-
[可选,建议安装] CodeBlocks(用于对算法程序进行离板调试)
-
[可选,建议安装] 安装OpenCV 2.4.13.6(SeetaFace的小部分代码用到了OpenCV,用于对算法程序进行离板调试)
-
-
一些基本知识:
-
虽然在上面的SDSOC安装及配置教程的最后一节中已经提到过SDSOC的官方使用教程和相应的手册,还是要强调一下这个教程的重要性,它写的很好可以快速带你入门SDSOC,请跟着教程了解SDSOC后再阅读以下内容。
-
基本的 C/C++ 知识。
-
-
下载本项目文件夹。
-
创建SDSOC项目并配置编译环境,具体步骤请戳SDSOC安装及配置教程,查看其中第二节的“工程配置”及“设置编译选项”两个小节。
-
把
src文件夹中的所有代码文件添加到SDSOC项目。这里想说一下的是,src中的代码文件是SeetaFace的源码的FPGA加速版,我把SeetaFace的所有源码都集中到这一个文件夹里了。项目的顶层main函数在 test_face_recognizer.cpp 文件中,若你想直接查看底层经过FPGA加速优化的卷积层运算代码,可以直接跳到 conv_net.cpp 文件。 -
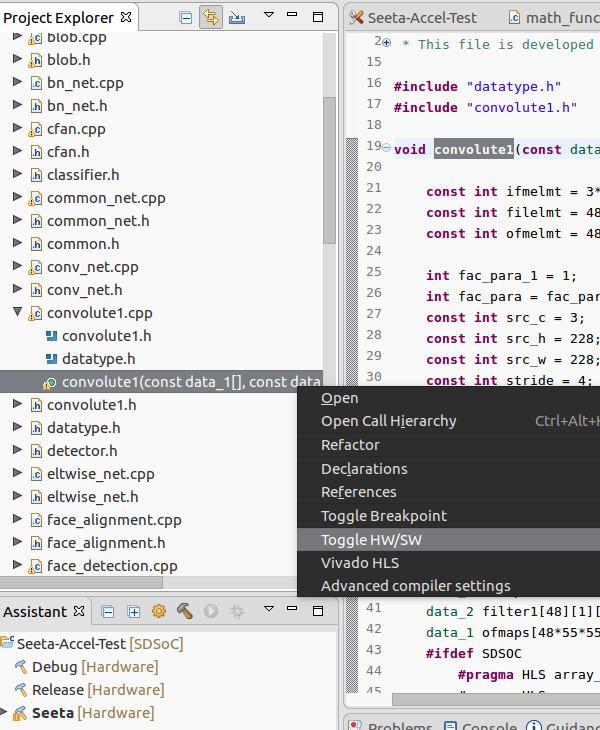
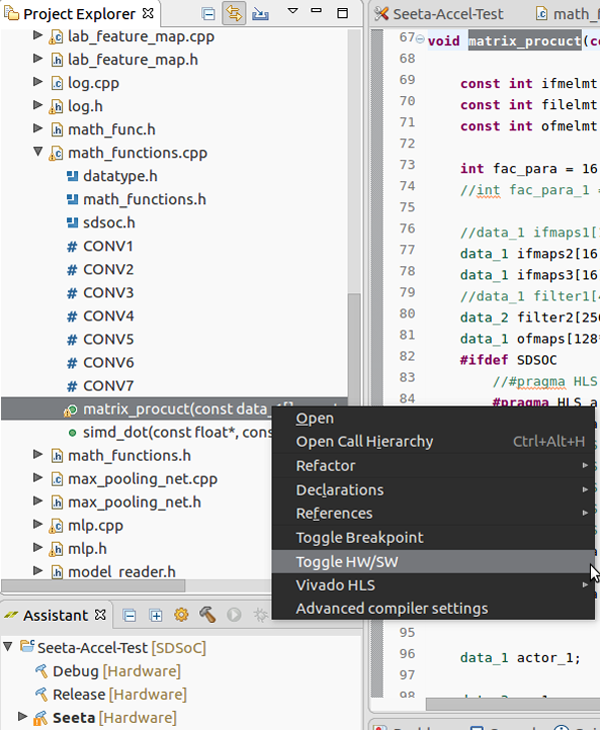
然后在SDSOC的project explorer窗口找到 convolute1.cpp 并展开,如图在带绿点的convolute1上右键,选择“Toggle HW/SW”;同样地,再找到 math_functions.cpp 并展开,在带绿点的matrix_procuct上右键,选择“Toggle HW/SW”。Toggle HW/SW 是把函数标记为硬件函数,硬件函数将被放进FPGA进行处理。Toggle完了以后可以在项目设置窗口看到有两个函数被标记为了硬件函数。

-
在项目设置窗口(Application Project Setting)勾选Generate SD card image后,就可以准备编译了。在SDSOC左下角的assistant窗口,选中之前根据教程配置好的编译环境(图中显示的是Seeta,但它和教程中修改的release配置是一样的),点击上方的锤子图片进行编译。本项目的编译一般需要1~3个小时。
-
编译结束后,在SDSOC项目文件目录中导航到与编译环境同名的文件夹(我这里是
Seeta,若你跟教程走的话就是release),在里面找到sd_card文件夹,把里面的所有文件复制到SD卡根目录,准备下板。
-
打开本项目的
model文件夹,解压里面的两个压缩包,得到一个大约110MB大小的参数文件 seeta_fr_v1.0.bin,然后把这个参数文件移动到model目录下。 -
把本项目文件中
model和data两个文件夹也拷贝到SD卡的根目录。 -
根据SDSOC安装及配置教程第二节中“配置 uart”小节的指导,完成下板操作并查看加速效果。
我们在上面介绍了本项目的安装流程,其中所有的代码都将在FPGA开发板上运行。但假如你要修改本项目的代码或把本项目的FPGA加速方法移植到其他算法中,你就需要对代码进行离板调试。离板调试仍然需要在Linux环境中进行。
-
下载OpenCV 2.4.13.6,并安装(OpenCV安装教程)。
-
安装codeblocks,创建工程项目,然后配置OpenCV环境(codeblocks中OpenCV的配置教程,可直接跳到该教程的第六步。注意,这个教程不是我写的,它调用的是适配于Visaul Studio的lib,而我们要用的是之前自己安装的lib,添加路径和lib文件的时候要注意这点)。
-
SeetaFace源码用到了C++11标准,所以还要在codeblocks的build option中勾选对c++11的支持。
-
复制
off-board debug文件夹中的两个 .cpp 文件,粘贴到src文件夹并替换掉其中的两个同名 .cpp 文件,然后把src文件夹的所有代码文件导入codeblocks的工程中。 -
编译工程并运行。
衷心感谢西安电子科技大学王树龙老师和高全学老师对本项目的指导与支持。
FPGA加速计算的代码主要集中在 conv_net.cpp 、convolute1.cpp、math_functions.cpp 三个文件中,你会发现其中的代码风格可能显得有些奇怪,比如为什么不采用函数或模板来代替重复的代码?为什么计算部分的代码如此冗长?为什么不用动态内存分配而采用固定大小的数组?为什么......?
事实上,所有代码都是经过精心调校与测试的(当然不排除本人水平不足导致有的问题处理得并不完美,希望大神们指出)。上面奇怪的代码风格只是为了让编译器能综合出可运行的且性能更佳的FPGA电路,至于本系统所设计的一系列加速策略的具体优化原理,请看下面非常长的讲解。
在数据传输进FPGA之前,我对所有参与卷积层的数据都进行了低精度处理,即把所有数据从32位单精度浮点数强制转换为16位半精度浮点数。测试表明,与单精度浮点数相比,采用半精度浮点数处理完VIPLFaceNet的7个卷积层和2个全连接层后,所得的特征值与原来仍保持高达99.9999%的相似度。然而,采用半精度浮点数可以节省许多硬件资源,尤其是片上存储BRAM资源减少了近一半,计算速度也提升了30%左右。
并行计算能力是FPGA的显著优势,也是本加速系统非常关键的加速策略之一。本系统的底层计算是并行的:以VIPLFaceNet的第四层卷积为例,其过滤器有尺寸为 3 × 3 × 128,本系统采用了一个16通道并行的底层计算单元,即可以同时完成 3 × 3 × 16 一共144个数据的乘加运算,极大提升了计算速度。当然,你也可以选择8通道并行或32通道并行,这会影响硬件资源使用量和加速性能,采用32通道并行有时会引起时序问题。
该底层并行计算单元的加法部分由加法树结构组成,负责把144个乘积尽可能快地加起来得到一个部分和。测试表明引入加法树结构后可以将总加速性能提高19%左右。
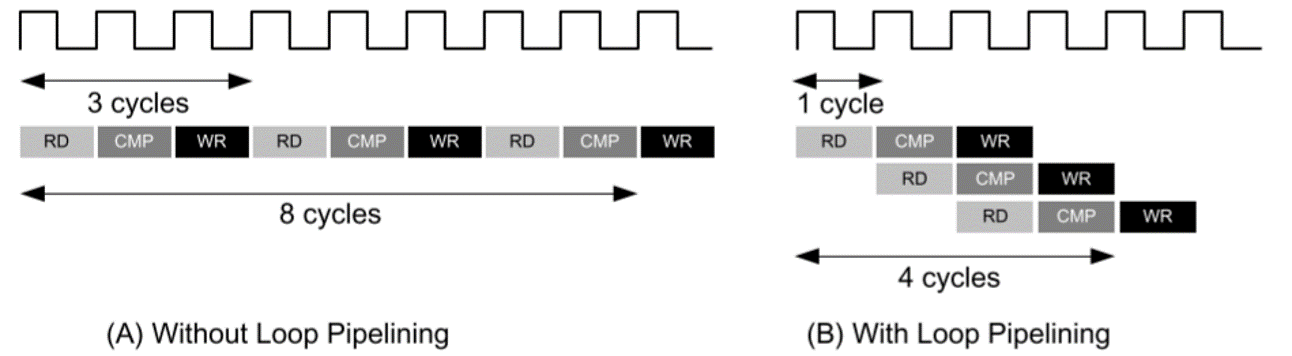
流水线(Pipeline)算是一种比较常用的提高处理效率的方法了,具体的原理如图(图是从Xilinx文档扒下来的)。Xilinx SDSOC 可以很好地支持流水线的综合,具体可以查看文档UG1235第四章流水线相关的内容。本系统在底层并行计算单元中应用了流水线。
输入体复用架构是一种针对卷积层的优化运算策略。高能预警!!! Σ(っ °Д °;)っ 后面的内容可能略微抽象,那就....多看几次就好了hhhh。
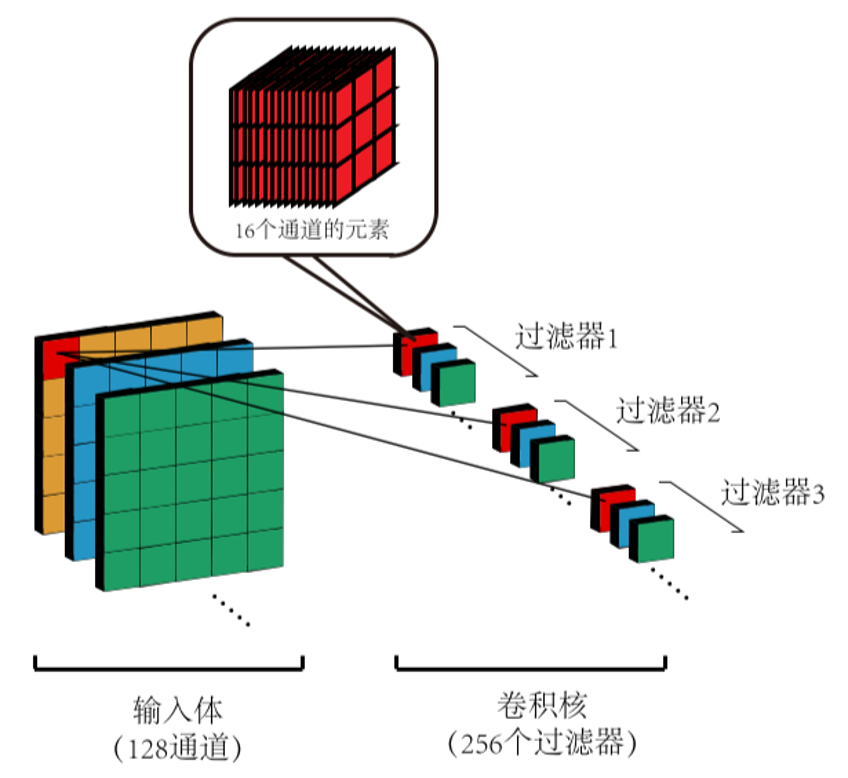
输入体复用架构的完整计算策略如图所示(图中展示第四层卷积的情况)。 首先,计算单元将分别从输入体(input volume)和卷积核的第一个过滤器中读取前 16 个通道的 144 个元素并进行卷积运算,得到输出体(output volume)中第一张特征图的第一个元素的部分和(注意是部分和而不是完整的输出体元素值)。随后,保留计算单元中来自输入体的 144 个 操作数不变,把来自卷积核的 144 个操作数更新为卷积核中第二个过滤器的前 16 个通道的 144 个参数,并与输入体操作数进行卷积运算,得到输出体中第二张特征图的第一个元素的部分和。如此循环,在得到了输出体第 256 张特征图的第一个元素的部分和后,我们将进行首次移窗,同时首次更新计算单元中的 144 个来自输入体的操作数。随后,如前面所述那样计算出输出体的新的 256 个 元素的部分和。在移窗结束后,我们便得到输出体所有元素的“第一轮部分和”。 接下来,我们回到原点,让计算单元分别从输入体和卷积核中读取第 17 到第 32 个 通道的 144 个元素,并计算新的一轮部分和。对第四层而言,我们总共需要计算 8 (128 ÷ 16)轮部分和,把输出体元素每一轮的部分和进行累加,就可以算出最终的输出体。输出体复用架构可以提升性能10倍左右。
在后期的测试发现 PS 与 PL 间的数据传输时间占了 FPGA 总处理时间的很大一部分,所以要尽量减少数据的片外传输。借助 FPGA 的片上存储资源 BRAM(block RAM)来缓存数据,可以让计算所需的所有数据仅经过一次片外传输。
然而,每个 BRAM 单元仅有2个数据访问端口,即同时只能从一个 BRAM 单元中读写2个数据。这里需要提醒的是,我们之前提到的16通道并行的底层计算单元需要同时计算144个数据,所以假如把所有数据都放到同一个 BRAM 单元中就会导致数据的访问瓶颈,阻碍加速性能的发挥。
如何解决这个瓶颈问题?Xilinx 为开发者提供了一个解决方案,可以对存放数据的数组进行partition,让它们分别存放到不同的 BRAM 单元中,从而增加数据的读写端口。关于Array Partition的更多详情可查看文档UG1235。
在把这些加速策略应用到不同卷积层时需要注意几个问题。第一个问题是为了减少片上BRAM资源的使用,本系统采取了层间共享BRAM的策略。针对VIPLFaceNet的结构特点,本系统为各层输入体分配了3个独立共享空间,分别用来存第一层、第二到第三层、第四到第七层卷积的输入体数据;为各层卷积核分配了2个共享空间,分别存第一层和其余六层卷积的卷积核数据。
第二个是传输界面阻塞的问题。在数据的片外传输上,本系统采用的accelerator interface是streaming interface,该interface要求数据的实际传输量必须等于预期传输量。由于每层卷积的结构不同,所以每层实际的数据传输量也不一样,但我们所有层都共用一个accelerator interface,这似乎无法满足streaming interface的要求,造成传输界面阻塞,最终下板的时候会使程序卡住不能结束该层的计算。为了解决这个问题,要引入防阻塞机制。首先,把传输界面的预期数据传输量设置为各个层中的最大值;然后,加入防阻塞机制(代码中已备注为actor),在FPGA结束了对实际传输数据的读写之后,继续从DDR中读取一些无用数据,直到读够预期数据传输量为止。显然,防阻塞机制会使系统性能略微下降(毕竟读取无用数据会带来额外的处理时间),但由于毕设后期时间紧迫,暂时没想到更好的解决方法,如果你有更好的方法记得请@我一下哦~
文档UG1235:介绍了常见的SOSOC优化策略,讲的比较概括,可以提供大体的优化思路。
文档UG902:把C/C++编译成FPGA IP核的工作是SDSOC通过调用HLS完成的,UG902是HLS的详细介绍,包括如何编写高效的C/C++代码以及哪些代码不能被综合成硬件电路等。
文档UG1253:用C/C++高级综合转换到硬件电路常常需要添加一些编译指令(pragma)来告诉编译器一些额外的操作,UG1253详细介绍了这些编译指令的使用方法。
最后再回到SDSOC这个工具的使用上,可以参考文档UG1027和文档UG1146,文档UG1282介绍了SDSOC的Debug方法。