序列学习对应的问题,通常为对于一个输入序列得到一个目标的输出序列,比如 词性标注、语音识别、双语翻译等等。在这些任务中,输入输出序列的任务是端到端,一一对应的。因此,可以直接根据预测输出与标签的差异计算loss,训练模型。
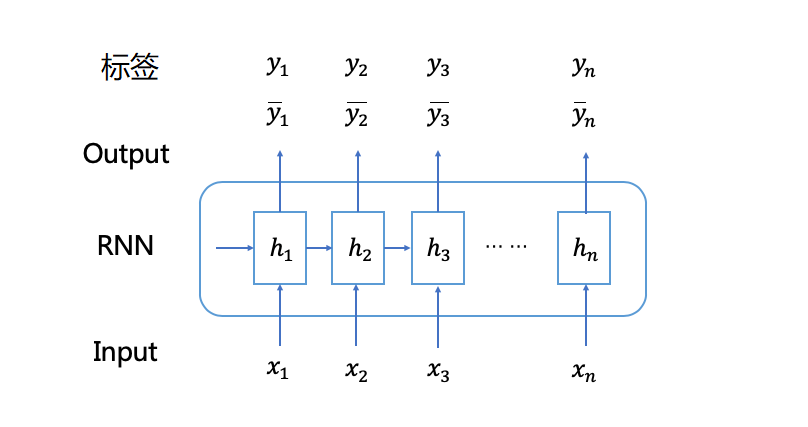
但是在语音识别、手写字符识别等任务中,连续输入信号逐一分割标记的成本太高,在实际应用中费时费力。如果可以在输入输出序列中没有对应标注情况下训练,就可以大大减轻工作量。

Connectionist Temporal Classification(CTC)[1]是一种端到端的RNN训练方法,它可以让RNN直接对序列数据进行学习,而无需事先标注好训练数据中输入序列和输入序列的映射关系,使得RNN模型在语音识别等序列学习任务中取得更好的效果,在语音识别和图像识别等领域CTC算法都有很比较广泛的应用。总的来说,CTC的核心思路主要分为以下几部分:
- 扩展了 RNN 的输出层,在输出序列和最终标签之间增加了多对一的空间映射,并在此基础上定义了 CTC Loss 函数
- 借鉴了 HMM(Hidden Markov Model)的 Forward-Backward 算法思路,利用动态规划算法有效地计算CTC Loss 函数及其导数,从而解决了 RNN 端到端训练的问题
- 结合 CTC Decoding 算法 RNN 可以有效地对序列数据进行端到端的预测

以OCR识别为例,输入图像
$$ \begin{aligned} argmax_Y P(Y|X) &= \argmax_Y P(Y|A)*P(A|X) \ A&=[a_1, a_2, \cdots, a_n] \end{aligned} $$ 其中, $ P(A|X) $是 CNN网络,$P(Y|A)$ 是解码部分。
因此,问题可以定义为训练一个分类器$h(x)= argmax_{Y \in L^T } P(Y|X)$。
- 若只考虑卷积特征解码部分,输入序列为$A=[a_1, a_2, \cdots, a_n]$ 的长度大于输出预测的字符长度
上面的介绍可以看到,输入的特征数目大于要输出的字符数,因此需要定义一个多对一的映射方式,来完成rnn输出到最终预测的映射关系。

对于输出空间的字符集$L$扩展, 添加一个分割字符
定义如下的一个映射规则
- 连续相同的字符,去重
- 去除空字符
那么对于期望的输出 apple 可以由以下的输出得到:
blank a a p p p blank p l ea a p p p blank p blank l blank ea p p p blank p l eblank blank a p blank p l e- ·····
那么最终就是把所有可能路径的概率相加,再计算loss即可。
RNN的任意时刻的输出相互独立,每个路径的概率以及最终的概率为
$$ \begin{array} {l}{\boldsymbol{p}(\boldsymbol{\pi} | \boldsymbol{x})=\prod_{\mathrm{t}=1}^{T} \boldsymbol{y}{\boldsymbol{\pi}{t}}^{t}, \forall \boldsymbol{\pi} \in \boldsymbol{L}^{\prime \mathrm{T}}} \ {\boldsymbol{p}(\boldsymbol{z} | \boldsymbol{x})=\sum_{\boldsymbol{\pi} \in \mathcal{B}^{-1}(\boldsymbol{z})} \boldsymbol{p}(\boldsymbol{\pi} | \boldsymbol{x})} \end{array} $$
其中:$\mathcal{B}^{-1}(\boldsymbol{z})$是全部路径集合的映射函数
那ctc loss函数定义为
$$ \begin{aligned} \mathcal{L}(\boldsymbol{S}) &= -\ln \prod_{(\boldsymbol{x}, \boldsymbol{z}) \in S} p(\boldsymbol{z} | \boldsymbol{x}) \ &=-\sum_{(\boldsymbol{x}, \boldsymbol{z}) \in S} \ln p(\boldsymbol{z} | \boldsymbol{x}) \ &=-\sum_{(\boldsymbol{x}, \boldsymbol{z}) \in S} \ln \sum_{\boldsymbol{\pi} \in \mathcal{B}^{-1}(\boldsymbol{z})} \boldsymbol{p}(\boldsymbol{\pi} | \boldsymbol{x}) \ &=-\sum_{(\boldsymbol{x}, \boldsymbol{z}) \in S} \ln \sum_{\boldsymbol{\pi} \in \mathcal{B}^{-\boldsymbol{1}}(\boldsymbol{z})} \prod_{t=1}^{\boldsymbol{T}} \boldsymbol{y}{\boldsymbol{\pi}{t}}^{\boldsymbol{t}}, \quad \forall \boldsymbol{\pi} \in \boldsymbol{L}^{\prime \mathrm{T}} \end{aligned} $$
则用LSTM作为RNN,模型可以表示为
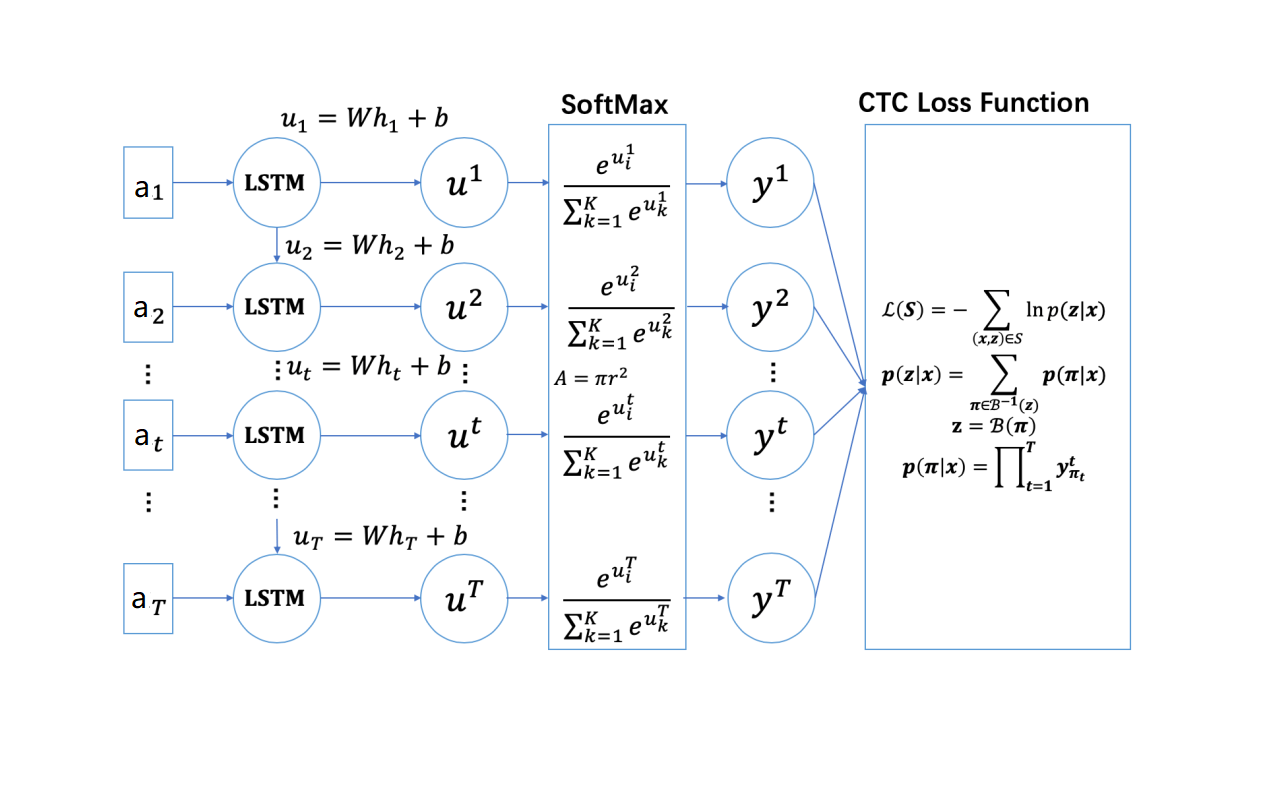
直接对所有解空间暴力搜索计算概率,时间复杂度非常高,作者借鉴了HMM中Forward-Backward的思路,采用动态规划的思路计算。
如下图,x轴表示时间序列, Y轴表示输出序列。以apple为例,首位中间添加blank得到_a_p_p_l_e_
即有:



图中并不是所有的路径都是合法路径,所有的合法路径需要遵循一些约束,如下图:





则所有路径如下

接下来,计算这些路径的概率总和。作者借鉴HMM的Forward-Backward算法思路,利用动态规划算法求解,可以将路径集合分为前向和后向两部分,如下图所示:





通过动态规划求解出前向概率之后,可以用前向概率来计算CTC Loss函数,如下图:

类似地方式,我们可以定义反向概率,并用反向概率来计算CTC Loss函数,如下图:





去掉箭头方向,把前向概率和后向概率结合起来也可以计算CTC Loss函数,这对于后面CTC Loss函数求导计算是十分重要的一步,如下图所示:



总结一下,根据前向概率计算CTC Loss函数,得到以下结论:

根据后向概率计算CTC Loss函数,得到以下结论:

根据任意时刻的前向概率和后向概率计算CTC Loss函数,得到以下结论:

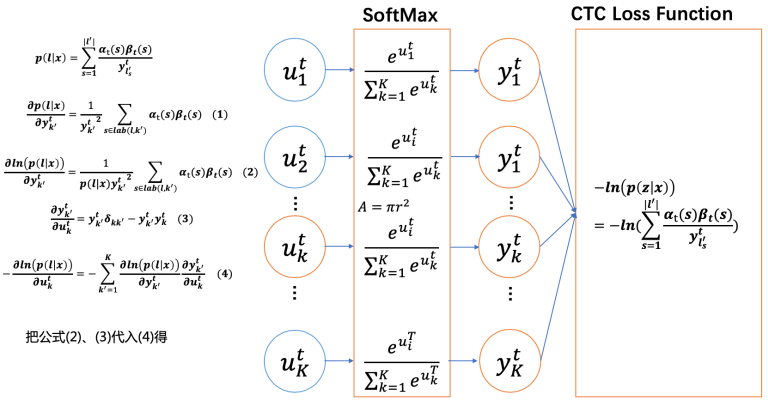
我们先回顾下RNN的网络结构,如下图飘红部分是CTC Loss函数求导的核心部分

CTC Loss函数相对于RNN输出层元素的求导过程如下图所示:

参考文献 本文内容参考自:https://xiaodu.io/ctc-explained/