- What is DevOps?
- DevOps - when Development meets Operations
- Benefits of DevOps
- DevOps Practices
- Linux commands in DevOps
- Overview of Virtual Machine
- Overview of Container
- Container Orchestration
- Cloud Computing
DevOps is an approach to culture, automation, and platform design intended to deliver increased business value and responsiveness through rapid, high-quality service delivery.
The word "DevOps" is a mashup of "development’ and "operations" but it represents a set of ideas and practices much larger than those two terms alone, or together. DevOps describes approaches to speed up the processes by which an idea (like a new software feature, a request for enhancement, or a bug fix) goes from development to deployment in a production environment where it can provide value to the user. These approaches require that development teams and operations teams communicate frequently and approach their work with empathy for their teammates.
-
Development: the infrastructure needed to unify development, from distributing resources to writing code and algorithms for enterprise applications, which can benefit from advanced capabilities such as AI/machine learning, containers, and serverless features. In addition, testing, archiving, tracking coding errors, and other important tasks are performed during the development phase, all on the way to release. Some frequently used tools for development: Git for code input, Github or the evolutionary Bitbucket for managing code repositories.
-
Operations - after an application is deployed, the operations side takes over, focusing on ensuring that cloud platforms are running smoothly. This function includes addressing issues such as user security, database management, scalability of production workflows, and patching. Some commonly used tools for operations: Terraform, Ansible, Puppet, and Chef for infrastructure and configuration management.
The result is an efficient model that maximizes resources and works at the ever-faster pace of the software development process, something that has become increasingly difficult to achieve with the traditional development model. In conclusion, a strong DevOps model enables companies to fix problems, grow users, and serve customers better by developing and iterating software products faster.
 With a flexible DevOps model, technology is optimized according to current lifecycle needs. In many cases, DevOps uses the latest machine learning and artificial intelligence technologies to achieve speed. DevOps also emphasizes automation and continuous integration/delivery, freeing staff from a number of manual activities to focus on innovation. On the development side, engineers can reach their coding goals faster or collaborate more effectively. On the operations side, system administrators can use automation frameworks to easily provision and upgrade new applications and infrastructure.
With a flexible DevOps model, technology is optimized according to current lifecycle needs. In many cases, DevOps uses the latest machine learning and artificial intelligence technologies to achieve speed. DevOps also emphasizes automation and continuous integration/delivery, freeing staff from a number of manual activities to focus on innovation. On the development side, engineers can reach their coding goals faster or collaborate more effectively. On the operations side, system administrators can use automation frameworks to easily provision and upgrade new applications and infrastructure.
 Increase the frequency and pace of releases so you can innovate and improve your product faster. The quicker you can release new features and fix bugs, the faster you can respond to your customers' needs and build competitive advantage. Continuous integration and continuous delivery are practices that automate the software release process, from build to deploy.
Increase the frequency and pace of releases so you can innovate and improve your product faster. The quicker you can release new features and fix bugs, the faster you can respond to your customers' needs and build competitive advantage. Continuous integration and continuous delivery are practices that automate the software release process, from build to deploy.
 Ensure the quality of application updates and infrastructure changes so you can reliably deliver at a more rapid pace while maintaining a positive experience for end users. Use practices like continuous integration and continuous delivery to test that each change is functional and safe. Monitoring and logging practices help you stay informed of performance in real-time.
Ensure the quality of application updates and infrastructure changes so you can reliably deliver at a more rapid pace while maintaining a positive experience for end users. Use practices like continuous integration and continuous delivery to test that each change is functional and safe. Monitoring and logging practices help you stay informed of performance in real-time.
 Operate and manage your infrastructure and development processes at scale. Automation and consistency help you manage complex or changing systems efficiently and with reduced risk. For example, infrastructure as code helps you manage your development, testing, and production environments in a repeatable and more efficient manner.
Operate and manage your infrastructure and development processes at scale. Automation and consistency help you manage complex or changing systems efficiently and with reduced risk. For example, infrastructure as code helps you manage your development, testing, and production environments in a repeatable and more efficient manner.
 Build more effective teams under a DevOps cultural model, which emphasizes values such as ownership and accountability. Developers and operations teams collaborate closely, share many responsibilities, and combine their workflows. This reduces inefficiencies and saves time (reduced handover periods between developers and operations, writing code that takes into account the environment in which it is run).
Build more effective teams under a DevOps cultural model, which emphasizes values such as ownership and accountability. Developers and operations teams collaborate closely, share many responsibilities, and combine their workflows. This reduces inefficiencies and saves time (reduced handover periods between developers and operations, writing code that takes into account the environment in which it is run).
 Move quickly while retaining control and preserving compliance. You can adopt a DevOps model without sacrificing security by using automated compliance policies, fine-grained controls, and configuration management techniques. For example, using infrastructure as code and policy as code, you can define and then track compliance at scale.
Move quickly while retaining control and preserving compliance. You can adopt a DevOps model without sacrificing security by using automated compliance policies, fine-grained controls, and configuration management techniques. For example, using infrastructure as code and policy as code, you can define and then track compliance at scale.
- Continuous Integration
- Continuous Delivery
- Microservices
- Infrastructure as Code
- Monitoring & Logging
- Communication & Collaboration
 The most important step for continuous software operation is continuous integration (CI). CI is a development practice where developers commit code changes (usually small and incremental) to a centralized source repository, which triggers a set of automated builds and tests. This repository allows developers to catch coding errors early and automatically, before they are pushed to production. The continuous integration process typically involves a number of steps, from committing code to automatically performing basic continuous/static analysis, capturing dependencies, and finally generating the software and performing some basic testing before generating the final version. Source code management systems like Github, Gitlab, etc. offer webhooks integration, to which CI tools like Jenkins can subscribe to start running builds and automated tests after each code upload.
The most important step for continuous software operation is continuous integration (CI). CI is a development practice where developers commit code changes (usually small and incremental) to a centralized source repository, which triggers a set of automated builds and tests. This repository allows developers to catch coding errors early and automatically, before they are pushed to production. The continuous integration process typically involves a number of steps, from committing code to automatically performing basic continuous/static analysis, capturing dependencies, and finally generating the software and performing some basic testing before generating the final version. Source code management systems like Github, Gitlab, etc. offer webhooks integration, to which CI tools like Jenkins can subscribe to start running builds and automated tests after each code upload.
 Continuous delivery begins where our continuous integration story ends. CD automates the delivery of applications to cloud infrastructure environments. Most teams work with multiple development and test environments other than the main production server. Continuous delivery will provide an automated way to propagate tested code changes across all cloud environments.
Continuous delivery begins where our continuous integration story ends. CD automates the delivery of applications to cloud infrastructure environments. Most teams work with multiple development and test environments other than the main production server. Continuous delivery will provide an automated way to propagate tested code changes across all cloud environments.
 The microservices architecture is a design approach to build a single application as a set of small services. Each service runs in its own process and communicates with other services through a well-defined interface using a lightweight mechanism, typically an HTTP-based application programming interface (API). Microservices are built around business capabilities; each service is scoped to a single purpose. You can use different frameworks or programming languages to write microservices and deploy them independently, as a single service, or as a group of services.
The microservices architecture is a design approach to build a single application as a set of small services. Each service runs in its own process and communicates with other services through a well-defined interface using a lightweight mechanism, typically an HTTP-based application programming interface (API). Microservices are built around business capabilities; each service is scoped to a single purpose. You can use different frameworks or programming languages to write microservices and deploy them independently, as a single service, or as a group of services.
 Infrastructure as code is a practice in which infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration. The cloud’s API-driven model enables developers and system administrators to interact with infrastructure programmatically, and at scale, instead of needing to manually set up and configure resources. Thus, engineers can interface with infrastructure using code-based tools and treat infrastructure in a manner similar to how they treat application code. Because they are defined by code, infrastructure and servers can quickly be deployed using standardized patterns, updated with the latest patches and versions, or duplicated in repeatable ways.
Infrastructure as code is a practice in which infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration. The cloud’s API-driven model enables developers and system administrators to interact with infrastructure programmatically, and at scale, instead of needing to manually set up and configure resources. Thus, engineers can interface with infrastructure using code-based tools and treat infrastructure in a manner similar to how they treat application code. Because they are defined by code, infrastructure and servers can quickly be deployed using standardized patterns, updated with the latest patches and versions, or duplicated in repeatable ways.
 Organizations monitor metrics and logs to see how application and infrastructure performance impacts the experience of their product’s end user. By capturing, categorizing, and then analyzing data and logs generated by applications and infrastructure, organizations understand how changes or updates impact users, shedding insights into the root causes of problems or unexpected changes. Active monitoring becomes increasingly important as services must be available 24/7 and as application and infrastructure update frequency increases. Creating alerts or performing real-time analysis of this data also helps organizations more proactively monitor their services.
Organizations monitor metrics and logs to see how application and infrastructure performance impacts the experience of their product’s end user. By capturing, categorizing, and then analyzing data and logs generated by applications and infrastructure, organizations understand how changes or updates impact users, shedding insights into the root causes of problems or unexpected changes. Active monitoring becomes increasingly important as services must be available 24/7 and as application and infrastructure update frequency increases. Creating alerts or performing real-time analysis of this data also helps organizations more proactively monitor their services.
 Increased communication and collaboration in an organization is one of the key cultural aspects of DevOps. The use of DevOps tooling and automation of the software delivery process establishes collaboration by physically bringing together the workflows and responsibilities of development and operations. Building on top of that, these teams set strong cultural norms around information sharing and facilitating communication through the use of chat applications, issue or project tracking systems, and wikis. This helps speed up communication across developers, operations, and even other teams like marketing or sales, allowing all parts of the organization to align more closely on goals and projects.
Increased communication and collaboration in an organization is one of the key cultural aspects of DevOps. The use of DevOps tooling and automation of the software delivery process establishes collaboration by physically bringing together the workflows and responsibilities of development and operations. Building on top of that, these teams set strong cultural norms around information sharing and facilitating communication through the use of chat applications, issue or project tracking systems, and wikis. This helps speed up communication across developers, operations, and even other teams like marketing or sales, allowing all parts of the organization to align more closely on goals and projects.
In this section, we will have a look at the most frequently used Linux commands that are used while working in DevOps.
-
ls -> this command lists all the contents in the current working directory.
Syntax: $ ls {flag}
ls -> By specifying the path after ls, the content in that path will be displayed
ls -l -> using ‘l’ flag, lists all the contents along with its owner settings, permissions & timestamp (long format)
ls -a -> using ‘a’ flag, lists all the hidden contents in the specified directory -
sudo -> this command executes only that command with root/ superuser privileges. Syntax: $ sudo
-
cat -> this command can read, modify or concatenate text files. It also displays file contents.
Syntax: $ cat {filename}
cat -b -> this adds line numbers to non-blank lines
cat -n -> this adds line numbers to all lines
cat -s -> this squeezes blank lines into one line
cat -E -> this shows $ at the end of line\ -
grep -> this command searches for a particular string/ word in a text file. This is similar to “Ctrl+F” but executed via a CLI. Syntax: $ grep {filename}
grep -i -> returns the results for case insensitive strings
grep -n -> returns the matching strings along with their line number
grep -v -> returns the result of lines not matching the search string
grep -c -> returns the number of lines in which the results matched the search string -
sort -> this command sorts the results of a search either alphabetically or numerically. It also sorts files, file contents, and directories. Syntax: $ sort {filename}
sort -r -> the flag returns the results in reverse order
sort -v -> the flag does case insensitive sorting
sort -n -> the flag returns the results as per numerical order. -
tail -> it is complementary to head command. The tail command, as the name implies, print the last N number of data of the given input. By default, it prints the last 10 lines of the specified files. If you give more than one filename, then data from each file precedes by its file name.
Syntax: tail [OPTION]... [FILE]...\ -
chown -> is used to change the file Owner or group. Whenever you want to change ownership you can use chown command.
*Syntax: chown [OPTION]… [OWNER][:[GROUP]] FILE… *
Example: To change owner of the file: chown owner_name file_name -
chmod -> this command is used to change the access permissions of files and directories.
Syntax: chmod <permissions of user,group,others> {filename}
4 – read permission
2 – write permission
1 – execute permission
0 – no permission -
ifconfig -> is used to configure the kernel-resident network interfaces. It is used at the boot time to set up the interfaces as necessary. After that, it is usually used when needed during debugging or when you need system tuning. Also, this command is used to assign the IP address and netmask to an interface or to enable or disable a given interface.
Syntax: ifconfig [...OPTIONS] [INTERFACE]
-a : This option is used to display all the interfaces available, even if they are down. Syntax: ifconfig -a
-s : -s : Display a short list, instead of details. Syntax: ifconfig -s. -
cut -> is used for extracting a portion of a file using columns and delimiters. If you want to list everything in a selected column, use the “-c” flag with cut command.For example, lets select the first two columns from our demo1.txt file.
Syntax: cut -c1-2 demo1.txt -
diff -> is used to find the difference between two files. This command analyses the files and prints the lines which are not similar.
Syntax: diff test.txt test1.txt -
history -> is used to view the previously executed command.
Syntax: history -
find -> is a command-line utility for walking a file hierarchy. It can be used to find files and directories and perform subsequent operations on them. It supports searching by file, folder, name, creation date, modification date, owner and permissions.
Syntax: find [where to start searching from] -
free -> command which displays the total amount of free space available along with the amount of memory used and swap memory in the system, and also the buffers used by the kernel.
Syntax: $free [OPTION] - OPTION: refers to the options compatible with free command.\
As free displays the details of the memory-related to your system, its syntax doesn’t need any arguments to be passed but only options which you can use according to your wish. When no option is used then free command produces the columnar output as shown above where column:\
- total displays the total installed memory (MemTotal and SwapTotal e present in /proc/meminfo).
- used displays the used memory.
- free displays the unused memory.
- shared displays the memory used by tmpfs(Shmen epresent in /proc/meminfo and displays zero in case not available).
- buffers displays the memory used by kernel buffers.
- cache displays the memory used by the page cache and slabs(Cached and Slab available in /proc/meminfo).
- buffers/cache displays the sum of buffers and cache.

Options for free command
-b, – -bytes :It displays the memory in bytes.
-k, – -kilo :It displays the amount of memory in kilobytes(default).
-m, – -mega :It displays the amount of memory in megabytes.
-g, – -giga :It displays the amount of memory in gigabytes
-
curl -> is a command-line tool to transfer data to or from a server, using any of the supported protocols (HTTP, FTP, IMAP, POP3, SCP, SFTP, SMTP, TFTP, TELNET, LDAP or FILE).
Syntax: curl [options] [URL...] The most basic uses of curl is typing the command followed by the URL. -
df, du -> The df (disk free) command reports the amount of available disk space being used by file systems. The du (disk usage) command reports the sizes of directory trees inclusive of all of their contents and the sizes of individual files.
Syntax: To check in a human-readable format: $ sudo df -h -
ps -> Every process in Linux has a unique ID and can be seen using the command ps. Syntax: $ sudo ps aux

a = show processes for all users
u = display the process’s user/owner
x = also show processes not attached to a terminal -
kill -> is a built-in command which is used to terminate processes manually. This command sends a signal to a process that terminates the process.
Syntax: $ kill -l -> to display all the available signals you can use below command option \
\- Negative PID values are used to indicate the process group ID. If you pass a process group ID then all the processes within that group will receive the signal.
- A PID of -1 is very special as it indicates all the processes except kill and init, which is the parent process of all processes on the system.
- To display a list of running processes use the command ps and this will show you running processes with their PID number. To specify which process should receive the kill signal we need to provide the PID. kill pid: To show how to use a PID with the kill command. Syntax: $kill pid
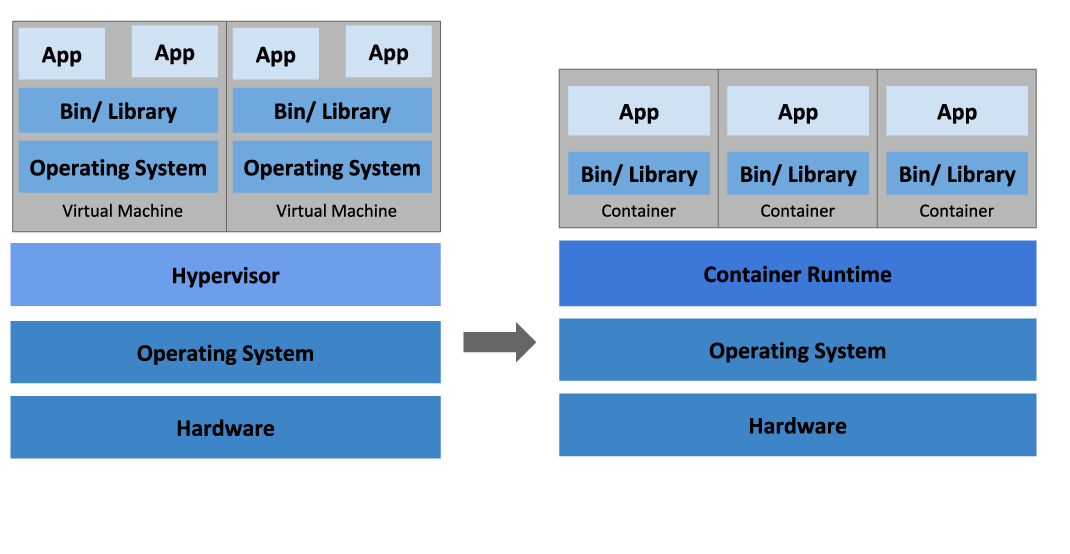
Virtual machines are software computers that provide the same functionality as physical computers. Like physical computers, they run applications and an operating system. However, virtual machines are computer files that run on a physical computer and behave like a physical computer. In other words, virtual machines behave as separate computer systems.
Virtual machines are created to perform specific tasks that are risky to perform in a host environment, such as accessing virus-infected data and testing operating systems. Since the virtual machine is sandboxed from the rest of the system, the software inside the virtual machine cannot tamper with the host computer. Virtual machines can also be used for other purposes such as server virtualization.
- Provides disaster recovery and application provisioning options
- Virtual machines are simply managed, maintained, and are widely available
- Multiple operating system environments can be run on a single physical computer
- Running multiple virtual machines on one physical machine can cause unstable performance
- Virtual machines are less efficient and run slower than a physical computer
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
Containers are an abstraction at the app layer that packages code and dependencies together. Multiple containers can run on the same machine and share the OS kernel with other containers, each running as isolated processes in user space. Containers take up less space than VMs (container images are typically tens of MBs in size), can handle more applications and require fewer VMs and Operating systems.
- Enables more efficient use of system resources
- Enables faster software delivery cycles
- Enables application portability
- Shines for microservices architecture
- Containers don't run at bare-metal speeds
- The container ecosystem is fractured. Its based on companies developments. Example: Openshift RedHat's container-as-a-service platform works only with Kubernetes container orchestrator.
- Persistent data storage is complicated
- Graphical applications don't work well
- Not all applications benefit from containers
Container orchestration is the process of managing containers using automation. It allows organizations to automatically deploy, manage, scale and network containers and hosts, freeing engineers from having to complete these processes manually.
Container orchestration is fundamentally about managing the container life cycle and the containerization of your environment. In general, the container life cycle follows the build-deploy-run phases of traditional software development, though the specific steps may vary slightly depending on the container orchestration tool being used. A typical life cycle might look like this:
- Build: In this first step, developers decide how to take the capabilities they’ve selected and build the application.
- Acquire: In this next step, containerized applications are usually acquired from public or private container image repositories. Developers start with a base image from one application and extend its functionality by placing a layer from another application over it. While using existing code from multiple sources in this way is more efficient and productive than creating everything from scratch, it also introduces the challenge of tracking the interdependencies among the various images.
- Deploy: This includes the process of placing and integrating the tested application into production.
- Maintain: In this step, developers continuously monitor the application to ensure it performs correctly. If it deviates from its desired state or fails, they try to understand the problem and fix it.
Container orchestration is used to automate and manage tasks across the container life cycle. This includes:
- Configuration and scheduling
- Provisioning and deployment
- Health monitoring
- Resource allocation
- Redundancy and availability
- Updates and upgrades
- Scaling or removing containers to balance workloads across the infrastructure
- Moving containers between hosts
- Load balancing and traffic routing
- Securing container interactions
One big advantage of container orchestration is that you may implement it in any environment where you can run containers, from on-premises servers to public, private, or multi-cloud running AWS, Microsoft Azure or Google Cloud Platform.


Cloud computing is a general term for anything that involves delivering hosted services over the internet. These services are divided into three main categories or types of cloud computing: infrastructure as a service (IaaS), platform as a service (PaaS) and software as a service (SaaS).
A cloud can be private or public. A public cloud sells services to anyone on the internet. A private cloud is a proprietary network or a data center that supplies hosted services to a limited number of people, with certain access and permissions settings. Private or public, the goal of cloud computing is to provide easy, scalable access to computing resources and IT services.
Cloud infrastructure involves the hardware and software components required for proper implementation of a cloud computing model. Cloud computing can also be thought of as utility computing or on-demand computing.

For what we are concerned, as devops engineers, we will look at IaaS offerings from cloud providers. Major players on the market at the time of this writing are:
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
Throughout the exercises we will be using GCP, as it offers an extensive trial program of 3 months, with 99% of the services available (mostly services that require external licensing are unavailable - for example Windows Server VMs)
| Google Cloud Platform products span the following categories: | ||
|---|---|---|
| 1. | Artificial intelligence & Machine Learning | AI Hub (beta), Cloud AutoML (beta), Cloud TPU, Cloud Machine Learning Engine, Diagflow Enterprise Edition, Cloud Natural Language, Cloud Speech-to-Text, Cloud Text-to-Speech, Cloud Translation, Cloud Vision, Cloud Video Intelligence, Cloud Inference API (alpha), and more |
| 2. | API management | API Analytics, API Monetization, Cloud Endpoints, Developer Portal, Cloud Healthcare API |
| 3. | Compute | Compute Engine, Shielded VMs, Container Security, App Engine, Cloud Functions, GPU, and more |
| 4. | Data Analytics | BigQuery, Cloud Dataflow, Cloud Dataproc, Cloud Datalab, Cloud Dataprep, Cloud Composer, and more |
| 5. | Databases | Cloud SQL, Cloud Bigtable, Cloud Spanner, Cloud Datastore, Cloud Memorystore |
| 6. | Developer Tools | Cloud SDK, Container Registry, Cloud Build, Cloud Source Repositories, Cloud Tasks, and more, as well as Cloud Tools for IntelliJ, PowerShell, Visual Studio, and Eclipse |
| 7. | Internet of Things (IoT) | Cloud IoT Core, Edge TPU (beta) |
| 8. | Hybrid and multi-cloud | Google Kubernetes Engine, GKE On-Prem, Istio on GKE (beta), Anthos Config Management, Serverless, Stackdriver, and more |
| 9. | Management Tools | Stackdriver, Monitoring, Trace, Logging, Debugger, Cloud Console, and more |
| 10. | Media | Anvato, Zync Render |
| 11. | Migration | Cloud Data Transfer, Transfer Appliance, BigQuery Data Transfer Service, Velostrata, VM Migration, and more |
| 12. | Networking | Virtual Private Cloud (VPC), Cloud Load Balancing, Cloud Armor, Cloud CDN, Cloud NAT, Cloud Interconnect, Cloud VPN, Cloud DNS, Network Service Tiers, Network Telemetry |
| 13. | Security | Access Transparency, Cloud Identity, Cloud Data Loss Prevention, Cloud Key Management Service, Cloud Security Scanner, and more |
| 14. | Storage | Cloud Storage, Persistent Disk, Cloud Filestore, and more |