We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
在点评口碑上,经常有类似的场景,搜索 “1公里以内的美食”,那么这个1公里怎么实现呢?
在数据库中可以通过暴力计算、矩形过滤、以及B树对经度和维度建索引,但这性能仍然很慢(可参考 为什么需要空间索引 )。搜索里用了一个很巧妙的方法,Geo Hash。
如上图,表示根据 GeoHash 对北京几个区域生成的字符串,有几个特点:
地球上任何一个位置都可以用经纬度表示,纬度的区间是 [-90, 90],经度的区间 [-180, 180]。比如天安门的坐标是 39.908,116.397,整体编码过程如下:
一、对纬度 39.908 的编码如下:
二、对经度 116.397 的编码如下:
三、合并组码
即最后天安门的4位 Geo Hash 为 “WX4G”,如果需要经度更准确,在对应的经纬度编码粒度再往下追溯即可。
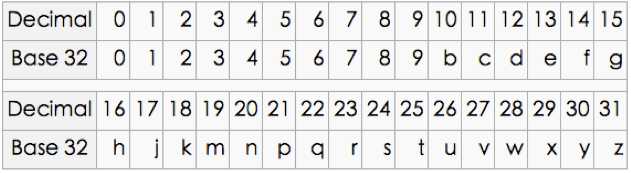
附:Base32 编码图
举个例子,搜索天安门附近 200 米的景点,如下是天安门附近的Geo编码
搜索过程如下:
由上面步骤可以看出,Geo Hash 将原本大量的距离计算,变成一个字符串检索缩小范围后,再进行小范围的距离计算,及快速又准确的进行距离搜索。
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线。当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
The text was updated successfully, but these errors were encountered:
No branches or pull requests
在点评口碑上,经常有类似的场景,搜索 “1公里以内的美食”,那么这个1公里怎么实现呢?
在数据库中可以通过暴力计算、矩形过滤、以及B树对经度和维度建索引,但这性能仍然很慢(可参考 为什么需要空间索引 )。搜索里用了一个很巧妙的方法,Geo Hash。
如上图,表示根据 GeoHash 对北京几个区域生成的字符串,有几个特点:
Geo Hash 如何编码?
地球上任何一个位置都可以用经纬度表示,纬度的区间是 [-90, 90],经度的区间 [-180, 180]。比如天安门的坐标是 39.908,116.397,整体编码过程如下:
一、对纬度 39.908 的编码如下:
二、对经度 116.397 的编码如下:
三、合并组码
即最后天安门的4位 Geo Hash 为 “WX4G”,如果需要经度更准确,在对应的经纬度编码粒度再往下追溯即可。
附:Base32 编码图
Geo Hash 如何用于地理搜索?
举个例子,搜索天安门附近 200 米的景点,如下是天安门附近的Geo编码
搜索过程如下:
由上面步骤可以看出,Geo Hash 将原本大量的距离计算,变成一个字符串检索缩小范围后,再进行小范围的距离计算,及快速又准确的进行距离搜索。
Geo Hash 依据的数学原理
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线。当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
The text was updated successfully, but these errors were encountered: