FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection
Monocular 3D object detection is an important task for autonomous driving considering its advantage of low cost. It is much more challenging than conventional 2D cases due to its inherent ill-posed property, which is mainly reflected in the lack of depth information. Recent progress on 2D detection offers opportunities to better solving this problem. However, it is non-trivial to make a general adapted 2D detector work in this 3D task. In this paper, we study this problem with a practice built on a fully convolutional single-stage detector and propose a general framework FCOS3D. Specifically, we first transform the commonly defined 7-DoF 3D targets to the image domain and decouple them as 2D and 3D attributes. Then the objects are distributed to different feature levels with consideration of their 2D scales and assigned only according to the projected 3D-center for the training procedure. Furthermore, the center-ness is redefined with a 2D Gaussian distribution based on the 3D-center to fit the 3D target formulation. All of these make this framework simple yet effective, getting rid of any 2D detection or 2D-3D correspondence priors. Our solution achieves 1st place out of all the vision-only methods in the nuScenes 3D detection challenge of NeurIPS 2020.
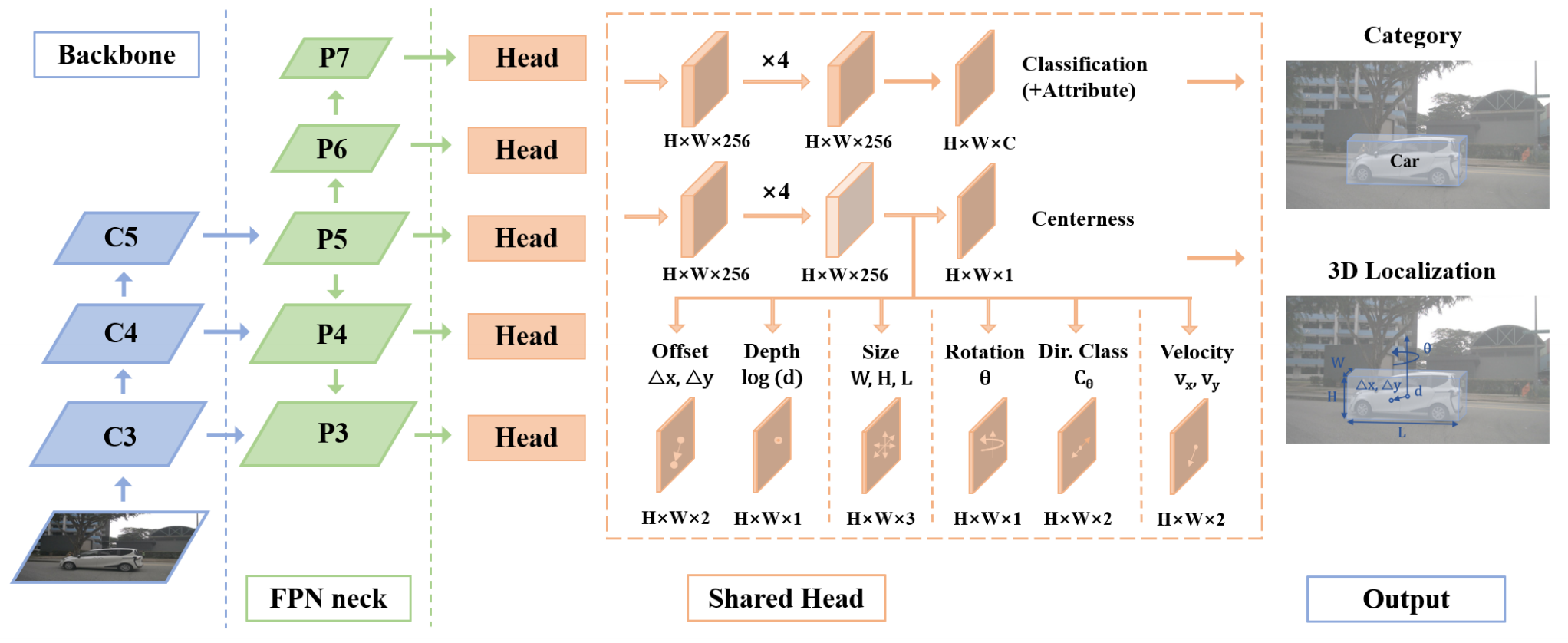
FCOS3D is a general anchor-free, one-stage monocular 3D object detector adapted from the original 2D version FCOS. It serves as a baseline built on top of mmdetection and mmdetection3d for 3D detection based on monocular vision.
Currently we first support the benchmark on the large-scale nuScenes dataset, which achieved 1st place out of all the vision-only methods in the nuScenes 3D detecton challenge of NeurIPS 2020.

After supporting FCOS3D and monocular 3D object detection in v0.13.0, the coco-style 2D json info files will include related annotations by default (see here if you would like to change the parameter). So you can just follow the data preparation steps given in the documentation, then all the needed infos are ready together.
The way to training and inference a monocular 3D object detector is the same as others in mmdetection and mmdetection3d. You can basically follow the documentation and change the config, work_dirs, etc. accordingly.
We implement test time augmentation for the dense outputs of detection heads, which is more effective than merging predicted boxes at last.
You can turn on it by setting flip=True in the test_pipeline.
Due to the scale and measurements of depth is different from those of other regression targets, we first train the model with depth weight equal to 0.2 for a more stable training procedure. For a stronger detector with better performance, please finetune the model with depth weight changed to 1.0 as shown in the config. Note that the path of load_from needs to be changed to yours accordingly.
We also provide visualization functions to show the monocular 3D detection results. Simply follow the documentation and use the single-gpu testing command. You only need to add the --show flag and specify --show-dir to store the visualization results.
| Backbone | Lr schd | Mem (GB) | Inf time (fps) | mAP | NDS | Download |
|---|---|---|---|---|---|---|
| ResNet101 w/ DCN | 1x | 8.69 | 29.8 | 37.7 | model | log | |
| above w/ finetune | 1x | 8.69 | 32.1 | 39.5 | model | log | |
| above w/ tta | 1x | 8.69 | 33.1 | 40.3 |
@inproceedings{wang2021fcos3d,
title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
year={2021}
}
# For the original 2D version
@inproceedings{tian2019fcos,
title = {{FCOS: Fully} Convolutional One-Stage Object Detection},
author = {Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2019}
}