| description |
|---|
本章将介绍汇编语言最大的优势之一:基本的二进制移位和循环移位技术。位操作是计算机图形学、数据加密和硬件控制的固有部分。实现位操作的指令是功能强大的工 具,但是高级语言只能实现其中的一部分,并且由于高级语言要求与平台无关,所以这些指令在一定程度上被弱化了。本章将展示一些对移位操作的应用,包括乘除法的优化。并非所有的高级编程语言都支持任意长度整数的运算。但是汇编语言指令使得它能够加减几乎任何长度的 |
移位指令与前面介绍的按位操作指令一起形成了汇编语言最显著的特点之一。位移动 (bit shifting) 意味着在操作数内向左或向右移动。
x86 处理器在这方面提供了相当丰富的指令集如下表所示,这些指令都会影响溢出标志位和进位标志位。
| SHL | 左移 | ROR | 循环右移 |
|---|---|---|---|
| SHR | 右移 | RCL | 带进位的循环左移 |
| SAL | 算术左移 | RCR | 带进位的循环右移 |
| SAR | 算术右移 | SHLD | 双精度左移 |
| ROL | 循环左移 | SHRD | 双精度右移 |
移动操作数的位有两种方法。第一种是逻辑移位 (logic shift),空出来的位用 0 填充。如下图所示,一个字节的数据向右移动一位。也就是说,每一位都被移动到其旁边的低位上。注意,位 7 被填充为 0:

下图所示为二进制数 1100 1111 逻辑右移一位,得到 OllOOlll。最低位移入进位标志位:

另一种移位的方法是算术移位 (arithmetic shift),空出来的位用原数据的符号位填充:

例如,二进制数 1100 1111,符号位为 1。算术右移一位后,得到 1110 0111:

SHL(左移)指令使目的操作数逻辑左移一位,最低位用 0 填充。最高位移入进位标志位,而进位标志位中原来的数值被丢弃:

若将 1100 1111 左移 1 位,该数就变为 1001 1110:

SHL 的第一个操作数是目的操作数,第二个操作数是移位次数:
SHL destination,count
该指令可用的操作数类型如下所示:
SHL reg, imm8
SHL mem, imm8
SHL reg, CL
SHL mem, CL
x86 处理器允许 imm8 为 0〜255 中的任何整数。另外,CL 寄存器包含的是移位计数。上述格式同样适用于 SHR、SAL、SAR、ROR、ROL、RCR 和 RCL 指令。
【示例】下列指令中,BL 左移一位。最高位复制到进位标志位,最低位填充 0:
mov b1, 8Fh ; BL = 10001111b
shl bl, 1 ; CF = 1, BL = 00011110b
当一个数多次进行左移时,进位标志位保存的是最后移岀最高有效位(MSB)的数值。下例中,位 7 没有留在进位标志位中,因为,它被位 6(0)替换了:
mov al, 10000000b
shl al, 2 ; CF = 0, AL = 00000000b
同样,当一个数多次进行右移时,进位标志位保存的是最后移出最低有效位(LSB)的数值。
数值进行左移(向 MSB 移动)即执行了位元乘法(Bitwise Multiplication)。例如,SHL 可以通过 2 的幕进行乘法运算。任何操作数左移 n 位,即将该数乘以 2n。现将整数 5 左移一位则得到 5 x 2¹ = 10:
mov dl, 5 ; 移动前:00000101 = 5
shl dl, 1 ; 移动后:00001010 = 10
若二进制数 0000 1010(十进制数 10)左移两位,其结果与 10 乘以 2² 相同:
mov dl, 10 ;移动前:00001010
shl dl, 2 ;移动后:00101000
SHR(右移)指令使目的操作数逻辑右移一位,最高位用 0 填充。最低位复制到进位标志位,而进位标志位中原来的数值被丢弃:

SHR 与《SHL指令》一节中介绍的 SHL 的指令格式相同。在下面的例子中,AL 中的最低位 0 被复制到进位标志位,而 AL 中的最高位用 0 填充:
mov al, 0D0h ; AL = 11010000b
shr al, 1 ; AL = 01101000b, CF = 0
在多位移操作中,最后一个移出位 0(LSB)的数值进入进位标志位:
mov al, 00000010b
shr al, 2 ; AL = 00000000b, CF = 1
数值进行右移(向 LSB 移动)即执行了位元除法(Bitwise Division)。将一个无符号数右移 n 位,即将该数除以 2n。下述语句将 32 除以 2¹,结果为 16:
mov dl, 32 ;移动前:00100000 = 32
shr dl, 1 ;移动后:00010000 = 16
下例实现的是 64 除以 2³:
mov al, 01000000b ;AL = 64
shr al, 3 ;除以 8, AL = 00001000b
用移位的方法实现有符号数除法可以使用 SAR 指令,因为该指令会保留操作数的符号位。
SAL(算术左移)指令的操作与《SHL指令》一节中的 SHL 指令一样。每次移动时,SAL 都将目的操作数中的每一位移动到下一个最高位上。最低位用 0 填充;最高位移入进位标志位,该标志位原来的值被丢弃:

如,二进制数 1100 1111 算术左移一位,得到 1001 1110:

SAR(算术右移)指令将目的操作数进行算术右移:

SAL 与 SAR 指令的操作数类型与 SHL 和 SHR 指令完全相同。移位可以重复执行,其次数由第二个操作数给出的计数器决定:
SAR destination, count
下面的例子展示了 SAR 是如何复制符号位的。执行指令前 AL 的符号位为负,执行指令后该位移动到右边的位上:
mov al, 0F0h ; AL = 11110000b (-16)
sar al, 1 ; AL = 11111000b (-8) , CF = 0
使用 SAR 指令,就可以将有符号操作数除以 2 的幂。下例执行的是 -128 除以2³,商为 -16:
mov dl, -128 ; DL = 10000000b
sar dl, 3 ; DL = 11110000b
设 AX 中为有符号数,现将其符号位扩展到 EAX。首先把 EAX 左移 16 位,再将其算术右移 16 位:
mov ax, -128 ; EAX = ????FF80h
shl eax, 16 ; EAX = FF800000h
sar eax, 16 ; EAX = FFFFFF80h
以循环方式来移位即为位元循环(Bitwise Rotation)。一些操作中,从数的一端移出的位立即复制到该数的另一端。还有一种类型则是把进位标志位当作移动位的中间点。
ROL(循环左移)指令把所有位都向左移。最高位复制到进位标志位和最低位。该指令格式与 SHL 指令相同:

位循环不会丢弃位。从数的一端循环出去的位会出现在该数的另一端。在下例中,请注意最高位是如何复制到进位标志位和位 0 的:
mov al,40h ; AL = 01000000b
rol al,1 ; AL = 10000000b, CF = 0
rol al,1 ; AL = 00000001b, CF = 1
rol alz1 ; AL = 00000010b, CF = 0
当循环计数值大于 1 时,进位标志位保存的是最后循环移出 MSB 的位:
mov al,00100000b
rol al,3 ; CF = 1, AL = 00000001b
利用 ROL 可以交换一个字节的高四位(位 4〜7)和低四位(位 0〜3)。例如,26h 向任何方向循环移动 4 位就变为 62h:
mov al, 26h
rol al, 4 ; AL = 62h
当多字节整数以四位为单位进行循环移位时,其效果相当于一次向右或向左移动一个十六进制位。例如,将 6A4Bh 反复循环左移四位,最后就会回到初始值:
mov ax, 6A4Bh
rol ax, 4 ; AX = A4B6h
rol ax, 4 ; AX = 4B6Ah
rol ax, 4 ; AX = B6A4h
rol ax, 4 ; AX = 6A4Bh
ROR(循环右移)指令把所有位都向右移,最低位复制到进位标志位和最高位。该指令格式与 SHL 指令相同:

在下例中,请注意最低位是如何复制到进位标志位和结果的最高位的:
mov al, 0lh ; AL = 00000001b
ror al, 1 ; AL = 10000000b, CF = 1
ror al, 1 ; AL = 01000000b, CF = 0
当循环计数值大于 1 时,进位标志位保存的是最后循环移出 LSB 的位:
mov al, 00000100b
ror al, 3 ; AL = 10000000b, CF = 1
RCL(带进位循环左移)指令把每一位都向左移,进位标志位复制到 LSB,而 MSB 复制到进位标志位:

如果把进位标志位当作操作数最高位的附加位,那么 RCL 就成了循环左移操作。下面的例子中,CLC 指令清除进位标志位。第一条 RCL 指令将 BL 最高位移入进位标志位,其他位都向左移一位。第二条 RCL 指令将进位标志位移入最低位,其他位都向左移一位:
clc ; CF = 0
mov bl, 88h ; CF,BL = 0 1000100Ob
rcl bl, 1 ; CF,BL = 1 00010000b
rcl b1, 1 ; CF,BL = 0 00100001b
RCL 可以恢复之前移入进位标志位的位。下面的例子把 testval 的最低位移入进位标志位,并对其进行检查。如果 testval 的最低位为 1,则程序跳转;如果最低位为 0,则用 RCL 将该数恢复为初始值:
.data
testval BYTE 01101010b
.code
shr testval, 1 ; 将lsb移入进位标志位
jc exit ; 如果该标志位置 1,则退出
rcl testval, 1 ; 否则恢复该数原值
RCR(带进位循环右移)指令把每一位都向右移,进位标志位复制到 MSB,而 LSB 复制到进位标志位:

从上图来看,RCL 指令将该整数转化成了一个 9 位值,进位标志位位于 LSB 的右边。下面的示例代码用 STC 将进位标志位置 1,然后,对 AH 寄存器执行一次带进位循环右移操作:
stc ; CF = 1
mov ah, 10h ; AH, CF = 00010000 1
rcr ah, 1 ; AH, CF = 10001000 0
如果有符号数循环移动一位生成的结果超过了目的操作数的有符号数范围,则溢出标志位置 1。换句话说,即该数的符号位取反。下例中,8 位寄存器中的正数(+127)循环左移后变为负数(-2):
mov al, +127 ; AL = 01111111b
rol al, 1 ; OF = 1, AL = 11111110b
同样,-128 向右移动一位,溢出标志位置 1。AL 中的结果(+64)符号位与原数相反:
mov al, -128 ; AL = 10000000b
shr al, 1 ; OF = 1, AL = 01000000b
如果循环移动次数大于 1,则溢出标志位无定义。
SHLD(双精度左移)指令将目的操作数向左移动指定位数。移动形成的空位由源操作数的高位填充。源操作数不变,但是符号标志位、零标志位、辅助进位标志位、奇偶标志位和进位标志位会受影响:
SHLD dest, source, count
下图展示的是 SHLD 执行移动一位的过程。源操作数的最高位复制到目的操作数的最低位上。目的操作数的所有位都向左移动:
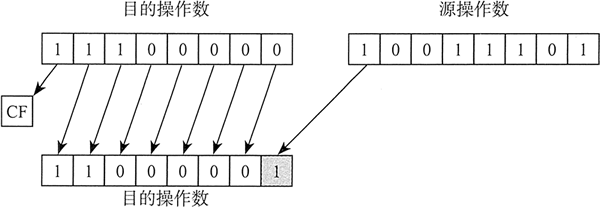
SHRD(双精度右移)指令将目的操作数向右移动指定位数。移动形成的空位由源操作数的低位填充:
SHRD dest, source, count
下图展示的是 SHRD 执行移动一位的过程:
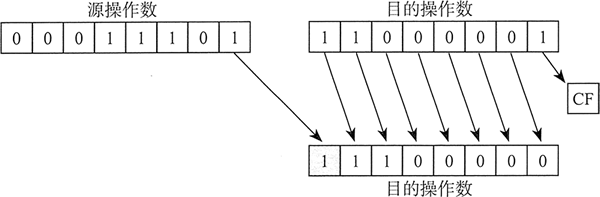
下面的指令格式既可以应用于 SHLD 也可以应用于 SHRD。目标操作数可以是寄存器或内存操作数;源操作数必须是寄存器;移位次数可以是 CL 寄存器或者 8 位立即数:
SHLD regl6, regl6, CL/imm8
SHLD meml6, regl6, CL/imm8
SHLD reg32, reg32, CL/imm8
SHLD mem32, reg32, CL/imm8
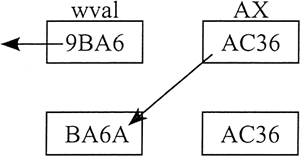
【示例 1】下述语句将 wval 左移 4 位,并把 AX 的高 4 位插入 wval 的低 4 位:
.data
wval WORD 9BA6h
.code
mov ax, 0AC36h
shld wval, ax, 4 ; wval = BA6Ah
数据移动过程如下图所示:
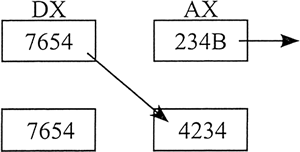
【示例 2】下例中,AX 右移 4 位,DX 的低 4 位移入 AX 的高 4 位:
mov ax, 234Bh
mov dx,7654h
shrd ax, dx, 4
为了在屏幕上重定位图像而必须将位元组左右移动时,可以用 SHLD 和 SHRD 来处理位映射图像。另一种可能的应用是数据加密,如果加密算法中包含位的移动的话。最后,对于很长的整数来说,这两条指令还可以用于快速执行其乘除法。
下面的代码示例展示了用 SHRD 如何将一个双字数组右移 4 位:
.data
array DWORD 648B2165h, 8C943A29h, 6DFA4B86h, 91F76C04h, 8BAF9857h
.code
mov bl, 4 ;移位次数
mov esi, OFFSET array ;数组的偏移量
mov ecx, (LENGTHOF array) - 1 ;数组元素个数
L1: push ecx ;保存循环计数
mov eax, [esi + TYPE DWORD]
mov cl, bl ;移动次数
shrd [esi], eax, cl ;EAX [ESI] 的高位
add esi, TYPE DWORD ;指向下一对双字
pop ecx ;恢复循环计数
loop L1
shr DWORD PTR [esi], 4 ;最后一个双字进行移位
当程序需要将一个数的位从一部分移动到另一部分时,汇编语言是非常合适的工具。有时,把数的位元子集移动到位 0,便于分离这些位的值。本节将展示一些易于实现的常见移位和循环移位的应用。
对于已经被分割为字节、字或双字数组的扩展精度整数可以进行移位操作。在此之前,必须知道该数组元素是如何存放的。保存整数的常见方法之一被称为小端顺序 (little-endian order)。
其工作方式如下:将数组的最低字节存放到它的起始地址,然后,从该字节开始依序把高字节存放到下一个顺序的内存地址中。除了可以将数组作为字节序列存放外,还可以将其作为字序列和双字序列存放。如果是后两种形式,则字节和字节之间仍然是小端顺序,因为 x86 机器是按照小端顺序存放字和双字的。
下面的步骤说明了怎样将一个字节数组右移一位。
步骤 1):把位于 [ESI+2] 的最高字节右移一位,其最低位自动复制到进位标志位。
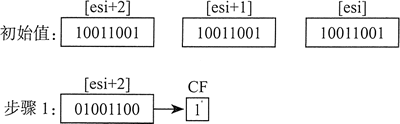
步骤 2):把 [ESI+1] 循环右移一位,即用进位标志位填充最高位,而将最低位移入进位标志位:
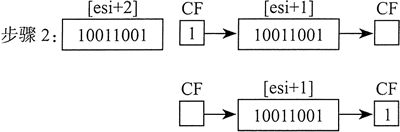
步骤 3) :把 [ESI] 循环右移一位,即用进位标志位填充最高位,而将最低位移入进位标志位:
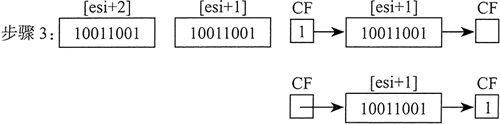
步骤 3 完成后,所有的位都向右移动了一位:
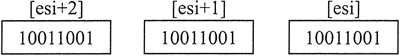
实现的是上述 3 个步骤,代码如下:
.data
ArraySize = 3
array BYTE ArraySize DUP(99h) ; 每个半字节的值都是 1001
.code
main PROC
mov esi,0
shr array[esi+2],1 ; 高字节
rcr array[esi+1],1 ; 中间字节,包括进位标志位
rcr array[esi],1 ; 低字节,包括进位标志位
虽然这个例子只有 3 个字节进行了移位,但是它能很容易被修改成执行字数组或双字数组的移位操作。利用循环,可以对任意大小的数组进行移位操作。
有时程序员会压榨出任何可以获得的性能优势,他们会使用移位而非 MUL 指令来实现整数乘法。当乘数是 2 的幂时,SHL 指令执行的是无符号数乘法。
一个无符号数左移 n 位就是将其乘以 2n。其他任何乘数都可以表示为 2 的幂之和。例如,若将 EAX 中的无符号数乘以 36,则可以将 36 写为 25+22,再使用乘法分配律:
EAX * 36 = EAX * (2⁵ + 2²)
= EAX * (32 + 4)
= (EAX * 32) + (EAX * 4)
下图展示了乘法 123*36 得到结果 4428 的过程:

请注意这里有个有趣的现象,乘数 (36) 的位 2 和位 5 都为 1,而整数 2 和 5 又是需要移位的次数。利用这个现象,下面的代码片段使用 SHL 和 ADD 指令实现了 123 乘以 36:
mov eax, 123
mov ebx, eax
shl eax, 5 ; 乘以 2⁵
shl ebx, 2 ; 乘以 2²
add eax, ebx ; 乘积相力口
将二进制整数转换为 ASCII 码的位串,并显示出来是一种常见的编程任务。SHL 指令适用于这个要求,因为每次操作数左移时,它都会把操作数的最高位复制到进位标志位。下面的 BinToAsc 过程是该功能一个简单的实现:
;---------------------------------------------------------
BinToAsc PROC
;
; 将 32 位二进制整数转换为 ASCII 码的二进制形式。
; 接收:EAX = 二进制整数,EST 为缓冲区指针
; 返回:包含 ASCII 码二进制数字的缓冲区
;---------------------------------------------------------
push ecx
push esi
mov ecx,32 ; EAX 中的位数
L1: shl eax,1 ; 最高位移入进位标志位
mov BYTE PTR [esi],'0' ; 选择0作为默认数字
jnc L2 ; 如果进位标志位为0,则跳转到L2
mov BYTE PTR [esi],'1' ; 否则将1送入缓冲区
L2: inc esi ; 指向下一个缓冲区位置
loop L1 ; 下一位进行左移
pop esi
pop ecx
ret
BinToAsc ENDP
当存储空间非常宝贵的时候,系统软件常常将多个数据字段打包为一个整数。要获得这些数据,应用程序就需要提取被称为位串(bit string)的位序列。例如,在实地址模式下,MS-DOS 函数 57h 用 DX 返回文件的日期戳。
(日期戳显示的是该文件最后被修改的日期。)其中,位 0〜 位 4 表示的是 1〜31 内的日期;位 5〜 位 8 表示的是月份;位 9〜 位 15 表示的是年份。如果一个文件最后被修改的日期是 1999 年 3 月 10 日,则 DX 寄存器中该文件的日期戳就如下图所示(年份以 1980 为基点):
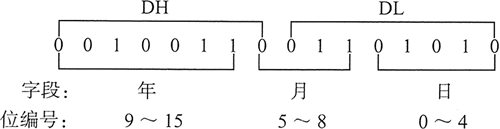
要提取一个位串,就把这些位移到寄存器的低位部分,再清除掉其他无关的位。下面的代码示例从一个日期戳中提取日期字段,方法是:复制 DL,然后屏蔽与该字段无关的位:
mov al, dl ; 复制 DL
and al, 00011111b ; 清除位 5 〜 位 7
mov day, al ; 结果存入变量 day
要提取月份字段,就把位 5〜 位 8 移到 AL 的低位部分,再清除其他无关位,最后把 AL 复制到变量中:
mov ax, dx ;复制 DX
shr ax, 5 ;右移5位
and al, 00001111b ;清除位 4 〜位 7
mov month, al ;结果存入变量month
年份字段(位 9〜 位 15)完全包含在 DH 寄存器中,将其复制到 AL,再右移 1 位:
mov al, dh ;复制 DH
shr al, 1 ;右移1位
mov ah, 0 ;将 AH 清零
add ax, 1980 ;年份基点为1980
mov year, ax ;结果存入变量year
32 位模式下,MUL(无符号数乘法)指令有三种类型:
- 第一种执行 8 位操作数与 AL 寄存器的乘法;
- 第二种执行 16 位操作数与 AX 寄存器的乘法;
- 第三种执行 32 位操作数与 EAX 寄存器的乘法。
乘数和被乘数的大小必须保持一致,乘积的大小则是它们的一倍。这三种类型都可以使用寄存器和内存操作数,但不能使用立即数:
MUL reg/mem8
MUL reg/meml6
MUL reg/mem32
MUL 指令中的单操作数是乘数。下表按照乘数的大小,列出了默认的被乘数和乘积。由于目的操作数是被乘数和乘数大小的两倍,因此不会发生溢岀。
| 被乘数 | 乘数 | 乘积 |
|---|---|---|
| AL | reg/mem8 | AX |
| AX | reg/mem16 | DX:AX |
| EAX | reg/mem32 | EDX:EAX |
如果乘积的高半部分不为零,则 MUL 会把进位标志位和溢出标志位置 1。因为进位标志位常常用于无符号数的算术运算,在此我们也主要说明这种情况。例如,当 AX 乘以一个 16 位操作数时,乘积存放在 DX 和 AX 寄存器对中。其中,乘积的高 16 位存放在 DX,低 16 位存放在 AX。如果 DX 不等于零,则进位标志位置 1,这就意味着隐含的目的操作数的低半部分容纳不了整个乘积。
有个很好的理由要求在执行 MUL 后检查进位标志位,即,确认忽略乘积的高半部分是否安全。
下述语句实现 AL 乘以 BL,乘积存放在 AX 中。由于 AH(乘积的高半部分)等于零,因此进位标志位被清除(CF=0):
mov al, 5h
mov bl, 10h
mul bl ; AX = 0050h, CF = 0
下图展示了寄存器内容的变化:

下述语句实现 16 位值 2000h 乘以 0100h。由于乘积的高半部分(存放于 DX)不等于零,因此进位标志位被置 1:
.data
val1 WORD 2000h
val2 WORD 0l00h
.code
mov ax, val1 ; AX = 2000h
mul val2 ; DX:AX = 00200000h, CF = 1

下述语句实现 12345h 乘以 1000h,产生的 64 位乘积存放在 EDX 和 EAX 寄存器对中。EDX 中存放的乘积高半部分为零,因此进位标志位被清除:
mov eax, 12345h
mov ebx, 1000h
mul ebx ; EDX:EAX = 0000000012345000h, CF = 0
下图展示了寄存器内容的变化:

64 位模式下,MUL 指令可以使用 64 位操作数。一个 64 位寄存器或内存操作数与 RAX 相乘,产生的 128 位乘积存放到 RDX:RAX 寄存器中。下例中,RAX 乘以 2,就是将 RAX 中的每一位都左移一位。RAX 的最高位溢出到 RDX 寄存器,使得 RDX 的值为 0000 0000 0000 0001h:
mov rax, 0FFFF0000FFFF0000h
mov rbx, 2
mul rbx ; RDX:RAX = 0000000000000001FFFE0001FFFE0000
下面的例子中,RAX 乘以一个 64 位内存操作数。该寄存器的值乘以 16,因此,其中的每个十六进制数字都左移一位(一次移动 4 个二进制位就相当于乘以 16)。
.data
multiplier QWORD 10h
.code
mov rax, OAABBBBCCCCDDDDh
mul multiplier ; RDX:RAX = 00000000000000000AABBBBCCCCDDDDOh
IMUL(有符号数乘法)指令执行有符号整数乘法。与 MUL 指令不同,IMUL 会保留乘 积的符号,实现的方法是,将乘积低半部分的最高位符号扩展到高半部分。
x86 指令集支持三种格式的 IMUL 指令:单操作数、双操作数和三操作数。单操作数格式中,乘数和被乘数大小相同,而乘积的大小是它们的两倍。
单操作数格式将乘积存放在 AX、DX:AX 或 EDX:EAX 中:
IMUL reg/mem8 ; AX = AL * reg/mem8
IMUL reg/meml6 ; DX:AX = AX * reg/meml6
IMUL reg/mem32 ; EDX:EAX = EAX * reg/mem32
和 MUL 指令一样,其乘积的存储大小使得溢出不会发生。同时,如果乘积的高半部分不是其低半部分的符号扩展,则进位标志位和溢出标志位置 1。利用这个特点可以决定是否忽略乘积的高半部分。
32 位模式中的双操作数 IMUL 指令把乘积存放在第一个操作数中,这个操作数必须是寄存器。第二个操作数(乘数)可以是寄存器、内存操作数和立 即数。16位格式如下所示:
IMUL regl6, reg/meml6
IMUL regl6, imm8
IMUL regl6, imml6
32 位操作数类型如下所示,乘数可以是 32 位寄存器、32 位内存操作数或立即数(8 位 或 32 位):
IMUL reg32, reg/mem32
IMUL reg32, inun8
IMUL reg32, imm32
双操作数格式会按照目的操作数的大小来截取乘积。如果被丢弃的是有效位,则溢出标志位和进位标志位置 1。因此,在执行了有两个操作数的 IMUL 操作后,必须检查这些标志位中的一个。
32 位模式下的三操作数格式将乘积保存在第一个操作数中。第二个操作数可以是 16 位寄存器或内存操作数,它与第三个操作数相乘,该操作数是一个8位或16 位立即数:
IMUL regl6, reg/meml6,imm8
IMUL regl6, reg/meml6, iirrnl6
而 32 位寄存器或内存操作数可以与 8 位或 32 位立即数相乘:
IMUL reg32, reg/mem32, imm8
IMUL reg32, reg/mem32, imm32
IMUL 执行时,若乘积有效位被丢弃,则溢出标志位和进位标志位置 1。因此,在执行了有三个操作数的 IMUL 操作后,必须检查这些标志位中的一个。
在 64 位模式下,IMUL 指令可以使用 64 位操作数。在单操作数格式中,64 位寄存器或内存操作数与 RAX 相乘,产生一个 128 位且符号扩展的乘积存放到 RDX:RAX 寄存器中。在下面的例子中,RBX 与 RAX 相乘,产生 128 位的乘积 -16。
mov rax, -4
mov rbx, 4
imul rbx ; RDX = 0FFFFFFFFFFFFFFFFh, RAX = -16
也就是说,十进制数 -16 在 RAX 中表示为十六进制 FFFF FFFF FFF0,而 RDX 只包含 TRAX 的高位扩展,即它的符号位。
三操作数格式也可以用于 64 位模式。如下例所示,被乘数 (-16) 乘以 4,生成 RAX 中的乘积 -64:
.data
multiplicand QWORD -16
.code
imul rax, multiplicand, 4 ; RAX = FFFFFFFFFFFFFFC0 (-64)
由于有符号数和无符号数乘积的低半部分是相同的,因此双操作数和三操作数的 IMUL 指令也可以用于无符号乘法。但是这种做法也有一点不便的地方:进位标志位和溢出标志位将无法表示乘积的高半部分是否为零。
下述指令执行 48 乘以 4,乘积 +192 保存在 AX 中。虽然乘积是正确的,但是 AH 不是 AL 的符号扩展,因此溢出标志位置 1:
mov al,48
mov bl, 4
imul bl ; AX = 00C0h, OF = 1
下述指令执行 -4 乘以 4,乘积 -16 保存在 AX 中。AH 是 AL 的符号扩展,因此溢出标志位清零:
mov al, -4
mov bl, 4
imul bl ; AX = FFF0h, OF = 0
下述指令执行 48 乘以 4,乘积 +192 保存在 DX:AX 中。DX 是 AX 的符号扩展,因此溢出标志位清零:
mov ax, 48
mov bx, 4
imul bx ; DX:AX = 000000C0h, OF = 0
下述指令执行 32 位有符号乘法 (4 823 424*-423),乘积 -2 040 308 352 保存在 EDX:EAX 中。溢出标志位清零,因为 EDX 是 EAX 的符号扩展:
mov eax, +4823424
mov ebx, -423
imul ebx ; EDX:EAX = FFFFFFFF86635D80h, OF = 0
下述指令展示了双操作数格式:
.data
word1 SWORD 4
dword1 SDWORD 4
.code
mov ax, -16 ; AX = -16
mov bx, 2 ; BX = 2
imul bx, ax ; BX = -32
imul bx, 2 ; BX = -64
imul bx, word1 ; BX = -256
mov eax, -16 ; EAX = -16
mov ebx, 2 ; EBX = 2
imul ebx, eax ; EBX = -32
imul ebx, 2 ; EBX = -64
imul ebx, dword1 ; EBX = -256
双操作数和三操作数 IMUL 指令的目的操作数大小与乘数大小相同。因此,有可能发生有符号溢出。执行这些类型的 IMUL 指令后,总要检查溢岀标志位。下面的双操作数指令展示了有符号溢出,因为 -64000 不适合 16 位目的操作数:
mov ax, -32000
imul ax, 2 ; OF = 1
下面的指令展示的是三操作数格式,包括了有符号溢出的例子:
.data
word1 SWORD 4
dword1 SDWORD 4
.code
imul bx, word1, -16 ; BX = word1 * -16
imul ebx, dword1, -16 ; EBX = dword1 * -16
imul ebx, dword1, -2000000000 ; 有符号溢出!
通常,程序员发现用测量执行时间的方法来比较一段代码与另一段代码执行的性能是很有用的。Microsoft Windows API 为此提供了必要的工具,lrvine32 库中的 GetMseconds 过程可使其变得更加方便使用。该过程获取系统自午夜过后经过的毫秒数。
在下面的代码示例中,首先调用 GetMseconds,这样就可以记录系统开始时间。然后调用想要测量其执行时间的过程 (FirstProcedureToTest)。最后,再次调用 GetMseconds,计算开始时间和当前毫秒数的差值:
.data
startTime DWORD ?
procTime1 DWORD ?
procTime2 DWORD ?
.code
call GetMseconds ;获得开始时间
mov startTime, eax
.
call FirstProcedureToTest
.
call GetMseconds ;获得结束时间
sub eax, startTime ;计算执行花费的时间
mov procTime1, eax ;保存执行花费的时间
当然,两次调用 GetMseconds 会消耗一点执行时间。但是在衡量两个代码实现的性能时间之比时,这点开销是微不足道的。现在,调用另一个被测试的过程,并保存其执行时间 (procTime2):
call GetMseconds ;获得开始时间
mov startTime, eax
.
call SecondProcedureToTest
.
call GetMseconds ;获得结束时间
sub eax, startTime ;计算执行花费的时间
mov procTime2, eax ;保存执行花费的时间
则 procTime1 和 procTime2 的比值就可以表示这两个过程的相对性能。
对老的 x86 处理器来说,用移位操作实现乘法和用 MUL、IMUL 指令实现乘法之间有着明显的性能差异。可以用 GetMseconds 程比较这两种类型乘法的执行时间。下面的两个过程重复执行乘法,用常量 LOOP_COUNT 决定重复的次数:
mult_by_shifting PROC
;
;用 SHL 执行 EAX 乘以 36,执行次数为LOOP_COUNT
mov ecx, LOOP_COUNT
L1: push eax ;保存原始 EAX
mov ebx, eax
shl eax, 5
shl ebx, 2
add eax, ebx
pop eax ;恢复 EAX
loop LI
ret
mult_by_shifting ENDP
mult_by_MUL PROC
;
;用MUL执行EAX乘以36,执行次数为LOOP_COUNT
mov ecx, LOOP_COUNT
LI: push eax ;保存原始 EAX
mov ebx, 36
mul ebx
pop eax ;恢复 EAX
loop L1
ret
mult_by_MUL ENDP
下述代码调用 multi_by_shifting,并显示计时结果。
.data
LOOP_COUNT = 0FFFFFFFFh
.data
intval DWORD 5
startTime DWORD ?
.code
main PROC
call GetMseconds ; 获取开始时间
mov startTime,eax
mov eax,intval ; 开始乘法
call mult_by_shifting
call GetMseconds ; 获取结束时间
sub eax,startTime
call WriteDec ; 显示乘法执行花费的时间
用同样的方法调用 mult_by_MUL,在传统的 4GHz 奔腾 4 处理器上运行的结果为:SHL 方法执行时间是 6.078 秒,MUL 方法执行时间是 20.718 秒。也就是说,使用 MUL 指令速度会慢 2.41 倍。
但是,在近期的处理器上运行同样的程序,调用两个函数的时间是完全一样的。这个例子说明,Intel 在近期的处理器上已经设法大大地优化了 MUL 和 IMUL 指令。
32 位模式下,DIV(无符号除法)指令执行 8 位、16 位和 32 位无符号数除法。其中,单寄存器或内存操作数是除数。格式如下:
DIV reg/mem8
DIV reg/meml6
DIV reg/mem32
下表给出了被除数、除数、商和余数之间的关系:
| 被除数 | 除数 | 商 | 余数 |
|---|---|---|---|
| AX | reg/mem8 | AL | AH |
| DX:AX | reg/mem16 | AX | DX |
| EDX:EAX | reg/mem32 | EAX | EDX |
64 位模式下,DIV 指令用 RDX:RAX 作被除数,用 64 位寄存器和内存操作数作除数, 商存放到 RAX,余数存放在 RDX 中。
下述指令执行 8 位无符号除法 (83h/2),生成的商为 41h,余数为 1:
mov ax, 0083h ; 被除数
mov bl, 2 ; 除数
div bl ; AL = 41h, AH = Olh
下图展示了寄存器内容的变化:
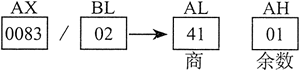
下述指令执行 16 位无符号除法 (8003h/100h),生成的商为 80h,余数为 3。DX 包含的是被除数的高位部分,因此在执行 DIV 指令之前,必须将其清零:
mov dx, 0 ; 清除被除数高16位
mov ax, 8003h ; 被除数的低16位
mov ex, 100h ; 除数
div ex ; AX = 0080h, DX = 0003h
下图展示了寄存器内容的变化:
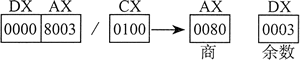
下述指令执行 32 位无符号除法,其除数为内存操作数:
.data
dividend QWORD 0000000800300020h
divisor DWORD 00000100h
.code
mov edx, DWORD PTR dividend + 4 ; 高双字
mov eax, DWORD PTR dividend ; 低双字
div divisor ; EAX = 08003000h, EDX = 00000020h
下图展示了寄存器内容的变化:

下面的 64 位除法生成的商 (0108 0000 0000 3330h) 在 RAX 中,余数 (0000 0000 0000 0020h) 在 RDX 中:
.data
dividend_hi QWORD 0000000000000108h
dividend_lo QWORD 0000000033300020h
divisor QWORD OOOOOOOOOOOlOOOOh
.code
mov rdx, dividend_hi
mov rax, dividend_lo
div divisor ; RAX = 0108000000003330
; RDX = 0000000000000020
请注意,由于被 64k 除,被除数中的每个十六进制数字是如何右移 4 位的。(若被 16 除,则每个数字只需右移一位。)
有符号除法几乎与无符号除法相同,只有一个重要的区别:在执行除法之前,必须对被除数进行符号扩展。
符号扩展是指将一个数的最高位复制到包含该数的变量或寄存器的所有高位中。为了说明为何有此必要,让我们先不这么做。下面的代码使用 MOV 把 -101 赋给 AX,即 DX:AX 的低半部分:
.data
wordVal SWORD -101 ; 009Bh
.code
mov dx, 0
mov ax, wordVal ; DX:AX = 0000009Bh (+155
mov bx, 2 ; BX 是除数
idiv bx ; DX:AX除以BX (有符号操作)
可惜的是,DX:AX 中的 009Bh 并不等于 -101,它等于 +155。因此,除法产生的商为 +77,这不是所期望的结果。而解决该问题的正确方法是使用 CWD( 字转双字 ) 指令,在进行除法之前在 DX:AX 中对 AX 进行符号扩展:
.data
wordVal SWORD -101 ; 009Bh
.code
mov dx, 0
mov ax, wordVal ; DX:AX = 0000009Bh (+155)
cwd ; DX:AX = FFFFFF9Bh (-101 )
mov bx, 2
idiv bx
x86 指令集有几种符号扩展指令。首先了解这些指令,然后再将其应用到有符号除法指令 IDIV 中。
Intel 提供了三种符号扩展指令:CBW、CWD 和 CDQ。CBW(字节转字)指令将 AL 的符号位扩展到 AH,保留了数据的符号。如下例所示,9Bh(AL 中)和 FF9Bh (AX 中)都等于十进制的 -101:
.data
byteVal SBYTE -101 ; 9Bh
.code
mov al, byteVal ; AL = 9Bh
cbw ; AX = FF9Bh
CWD(字转双字)指令将 AX 的符号位扩展到 DX:
.data
wordVal SWORD -101 ; FF9Bh
.code
mov ax, wordVal ; AX = FF9Bh
cwd ; DX:AX = FFFFFF9Bh
CDQ(双字转四字)指令将 EAX 的符号位扩展到 EDX:
.data
dwordVal SDWORD -101 ; FFFFFF9Bh
.code
mov eax, dwordVal
Cdq ; EDX:EAX = FFFFFFFFFFFFFF9Bh
IDIV(有符号除法)指令执行有符号整数除法,其操作数与 DIV 指令相同。执行 8 位除法之前,被除数(AX)必须完成符号扩展。余数的符号总是与被除数相同。
【示例 1】下述指令实现 -48 除以 5。IDIV 执行后,AL 中的商为 -9,AH 中的余数为 -3:
.data
byteVal SBYTE -48 ;D0 十六进制
.code
mov al, byteVal ;被除数的低字节
cbw ;AL扩展到AH
mov bl,+5 ;除数
idiv bl ;AL = -9, AH = -3
下图展示了 AL 是如何通过 CBW 指令符号扩展为 AX 的:
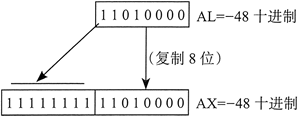
为了理解被除数的符号扩展为什么这么重要,现在在不进行符号扩展的前提下重复之前的例子。下面的代码将 AH 初始化为 0,这样它就有了确定值,然后没有用 CBW 指令转换被除数就直接进行了除法:
.data
byteVal SBYTE -48 ;D0 十六进制
.code
mov ah, 0 ;被除数高字节
mov al, byteVal ;被除数低字节
mov bl, +5 ;除数
idiv bl ;AL = 41z AH = 3
执行除法之前,AX=00D0h ( 十进制数 208)。 IDIV 把这个数除以 5,生成的商为十进制数 41,余数为3。这显然不是正确答案。
【示例 2】16 位除法要求 AX 符号扩展到 DX。下例执行 -5000 除以 256:
.data
wordVal SWORD -5000
.code
mov ax, wordVal ;被除数的低字
cwd ;AX扩展到DX
mov bx, +256 ;除数
idiv bx ;商 AX=-19,余数 DX=-13 6
【示例 3】32 位除法要求 EAX 符号扩展到 EDX。下例执行 50 000 除以 -256:
.data
dwordVal SDWORD +50000
.code
mov eax, dwordVal ;被除数的低双字
cdq ;EAX 扩展至q EDX
mov ebx, -256 ;除数
idiv ebx ;商 EAX=-195,余数 EDX=+80
执行 DIV 和 IDIV 后,所有算术运算状态标志位的值都不确定。
如果除法操作数生成的商不适合目的操作数,则产生除法溢出 (divide overflow)。这将导致处理器异常并暂停执行当前程序。例如,下面的指令就产生了除法溢出,因为它的商 (100h) 对 8 位的 AL 目标寄存器来说太大了:
mov ax,1000h
mov bl,10h
div bl ; AL无法容纳100h
运行这段代码时,Visual Studio 就会产生如下所示的结果错误。如果试图运行除以零的代码,也会显示相同的对话框。
Unhandled exception at 0x00401016 in Project.exe:0xC0000095:Integer overflow.
对此有个建议:使用 32 位除数和 64 位被除数来减少出现除法溢出条件的可能性。如下面的代码所示,除数为 EBX,被除数在 EDX 和 EAX 组成的 64 位寄存器对中:
mov eax,1000h
cdq
mov ebx,10h
div ebx ; EAX = 00000100h
要预防除以零的操作,则在进行除法之前检查除数:
mov ax, dividend
mov bl, divisor
cmp bl, 0 ;检查除数
je NoDivideZero ;为零?显不错误
div bl ;不为零:继续
.
.
NoDivideZero: ;显示 "Attmpt to divide by zero"
前面已经介绍了如何用加减指令实现算术表达式,现在还可以再加上乘法和除法指令。初看上去,实现算术表达式的工作似乎最好是留给编译器的编写者,但是动手研究一下还是能学到不少东西。
读者可以学习编译器怎样优化代码。此外,与典型编译器在乘法操作后检查乘积大小相比,还能实现更好的错误检查。进行 32 位操作数相乘时,绝大多数高级语言编译器都会忽略乘积的高 32 位。而在汇编语言中,可以用进位标志位和溢出标志位来说明乘积是否为 32 位。
有两种简单的方法可以查看 C++ 编译器生成的汇编代码:
- 一种方法是用 Visual Studio 调试时,在调试窗口中右键点击,选择 Go to Disassembly。
- 一种方法是,在 Project 菜单中选择 Properties,生成一个列表文件。在 Configuration Properties,选择 Microsoft Macro Assembler,再选择 Listing Fileo 在对话窗口中,将 Generate Preprocessed Source Listing 设置为 Yes,List All Available Information 也设置为 Yes。
【示例 1】使用 32 位无符号整数,用汇编语言实现下述 C++ 语句:
var4 = (var1 + var2) * var3;这个问题很简单,因为可以从左到右来处理 (先加法再乘法)。执行了第二条指令后,EAX 存放的是 val1 与 var2 之和。第三条指令中,EAX 乘以 var3,乘积存放在 EAX 中:
mov eax, var1
add eax, var2
mul var3 ; EAX = EAX * var3
jc tooBig ;无符号溢出?
mov var4, eax
jmp next
tooBig: ;显示错误消息
如果 MUL 指令产生的乘积大于 32 位,则 JC 指令跳转到有标号指令来处理错误。
【示例 2】使用 32 位无符号整数实现下述 C++ 语句:
var4 = (var1 * 5) / (var2 - 3);本例有两个用括号括起来的子表达式。左边的子表达式可以分配给 EDX:EAX,因此不必检查溢出。右边的子表达式分配给 EBX,最后用除法完成整个表达式:
mov eax, var1 ;左边的子表达式
mov ebx, 5
mul ebx ;EDX:EAX=乘积
mov ebx, var2 ;右边的子表达式
sub ebx, 3
div ebx ;最后的除法
mov var4, eax
【示例 3】使用 32 位有符号整数实现下述 C++ 语句:
var4 = (varl * -5) / (-var2 % var3);与之前的例子相比,这个例子需要一些技巧。可以先从右边的表达式开始,并将其保存在 EBX 中。由于操作数是有符号的,因此必须将被除数符号扩展到 EDX,再使用 IDIV 指令:
mov eax,var2 ;开始计算右边的表达式
neg eax
cdq ;符号扩展被除数
idiv var3 ;EDX = 余数
mov ebx,edx ;EBX = 右边表达式的结果
第二步,计算左边的表达式,并将乘积保存在 EDX:EAX 中:
mov eax, -5 ;开始计算左边表达式
imul var1 ;EDX:EAX=左边表达式的结果
最后,左边表达式结果 (EDX:EAX) 除以右边表达式结果 (EBX):
idiv ebx ;最后计算除法
mov var4,eax ;商
ADC(带进位加法)指令将源操作数和进位标志位的值都与目的操作数相加。该指令格式与 ADD 指令一样,且操作数大小必须相同:
ADC reg, reg
ADC mem, reg
ADC reg, mem
ADC mem, imm
ADC reg, imm
例如,下述指令实现两个 8 位整数相加 (FFh+FFh),产生的 16 位和数存入 DL:AL,其值为 01FEh:
mov dl, 0
mov al, 0FFh
add al, 0FFh ; AL = FEh
adc dl, 0 ; DL/AL = OlFEh
下图展示了这两个数相加过程中的数据活动。首先,FFh 与 AL 相加,生成 FEh 存入 AL 寄存器,并将进位标志位置 1。然后,将 0 和进位标志位与 DL 寄存器相加:

同样,下述指令实现两个 32 位整数相加 (FFFF FFFFh+ FFFF FFFFh),产生的 64 位和数存入 EDX:EAX,其值为:0000 0001 FFFF FFFEh:
mov edx, 0
mov eax, 0FFFFFFFFh
add eax, 0FFFFFFFFh
adc edx, 0
接下来将说明过程 Extended_Add 实现两个大小相同的扩展整数的加法。利用循环,该过程将两个扩展整数当作并行数组实现加法操作。数组中每对数值相加时,都要包括前一次循环迭代执行的加法所产生的进位标志位。实现过程时,假设整数存储在字节数组中,不过 本例很容易就能修改为双字数组的加法。
该过程接收两个指针,存入 ESI 和 EDI,分别指向参与加法的两个整数。EBX 寄存器指向缓冲区,用于存放和数,该缓冲区的前提条件是必须比两个加数大一个字节。此外,过程还用 ECX 接收最长加数的长度。
两个加数都需要按小端顺序存放,即其最低字节存放在该数组的起始地址。过程代码如下所示,添加了代码行编号便于进行详细讨论:
;------------------------------------------
Extended_Add PROC
; 计算两个以字节数组存放的扩展整数之和。
; 接收:ESI和EDI为两个加数的指针
; EBX 为和数变量指针,
; ECX为
; 相加的字节数。
; 和数存储区必须比输入的操作数多一个字节。
; 返回:无
;------------------------------------------
pushad
clc ;清除进位标志位
L1: mov al, [esi] ;取第一个数
adc al, [edi] ;与第二个数相加
pushfd ;保存进位标志位
mov [ebx], al ;保存部分和
add esi, 1 ;三个指针都加1
add edi, 1
add ebx, 1
popfd ;恢复进位标志位
loop L1 ;重复循环
mov byte ptr [ebx], 0 ;清除和数高字节
adc byte ptr [ebx], 0
popad ;加上其他的进位
ret
Extended_Add ENDP
当第14行和第15行将两个数组的最低字节相加时,加法运算可能会将进位标志位置 1。因此,第16行将进位标志位压入堆栈进行保存就很重要,因为在循环重复时会用到进位 标志位。第17行保存了和数的第一个字节,第18〜20行将三个指针(两个操作数,一个和数)都加 1。第 21 行恢复进位标志位,第 22 行将循环返回到第 14 行。
(LOOP 指令不会修改 CPU 的状态标志位。)再次循环时,第 17 行进行的是第二对字节的加法,其中包括进位标志位的值。因此,如果第一次循环过程产生了进位,则第二次循环就要包括该进位。按照这种方式循环,直到所有的字节都完成了加法。然后,最后的第 24 行和第 25 行检查操作数最高字节相加是否产生进位,若产生了进位,就将该值加到和数多岀来的那个字节中。
下面的代码示例调用 Extended_Add,并向其传递两个 8 字节的整数。要注意为和数多分配一个字节:
.data
op1 BYTE 34h,12h,98h,74h,06h,0A4h,0B2h,0A2h
op2 BYTE 02h,45h,23h,00h,00h,87h,10h,80h
sum BYTE 9 dup(0) ; = 0122C32B0674BB5736h
.code
main PROC
mov esi,OFFSET op1 ; 第一个操作数
mov edi,OFFSET op2 ; 第二个操作数
mov ebx,OFFSET sum ; 和数
mov ecx,LENGTHOF op1 ; 字节数
call Extended_Add
; 显示和数
mov esi,OFFSET sum
mov ecx,LENGTHOF sum
call Display_Sum
call Crlf
上述程序的输出如下所示,加法产生了一个进位:
0122C32B0674BB5736
过程 Display_Sum 按照正确的顺序显示和数,即从最高字节开始依次显示到最低字节:
Display_Sum PROC
pushad
; 指向左后一个数组
add esi,ecx
sub esi,TYPE BYTE
mov ebx,TYPE BYTE
L1: mov al,[esi] ; 取一个数组字节
call WriteHexB ; 显示该字节
sub esi,TYPE BYTE ; 指向前一个字节
loop L1
popad
ret
Display_Sum ENDP
SBB(带借位减法)指令从目的操作数中减去源操作数和进位标志位的值。允许使用的操作数与《ADC指令》一节中介绍的 ADC 指令相同。
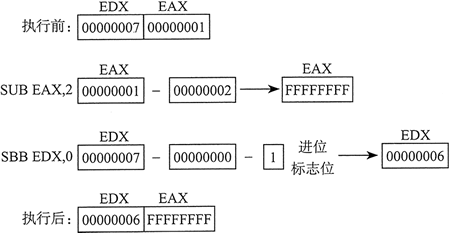
下面的示例代码用 32 位操作数实现 64 位减法,EDX:EAX 的值为 0000 0007 0000 0001h,从该值中减去 2。低 32 位先执行减法,并设置进位标志位,然后高 32 位再进行包括进位标志位的减法:
到目前为止,本教程讨论的整数运算处理的都是二进制数。虽然 CPU 用二进制运算,但是也可以执行 ASCII 十进制串的运算。使用后者进行运算,对用户而言既便于输入也便于在控制台窗口显示,因为不用进行二进制转换。
假设程序需要用户输入两个数,并将它们相加。若用户输入 3402 和 1256,则程序输出如下所示:
输入第一个数: 3402
输入第二个数: 1256
和数: 4658
有两种方法可以计算并显示和数:
1) 将两个操作数都转换为二进制,进行二进制加法,再将和数从二进制转换为 ASCII 数字串。
2) 直接进行数字串的加法,按序相加每对 ASCII 数字(2+6、0+5、4+2、3+1)。和数为 ASCII 数字串,因此可以直接显示在屏幕上。
第二种方法需要在执行每对 ASCII 数字相加后,用特殊指令来调整和数。有四类指令用于处理 ASCII 加法、减法、乘法和除法,如下所示:
| AAA | (执行加法后进行 ASCII 调整) | AAM | (执行乘法后进行 ASCII 调整) |
|---|---|---|---|
| AAS | (执行减法后进行 ASCII 调整) | AAD | (执行除法前进行 ASCII 调整) |
非压缩十进制整数的高 4 位总是为零,而 ASCII 十进制数的高 4 位则应该等于 0011b。在任何情况下,这两种类型的每个数字都占用一个字节。
下面的例子展示了 3402 用这两种类型存放的格式:

尽管 ASCII 运算执行速度比二进制运算要慢很多,但是它有两个明显的优点:
1) 不必在执行运算之前转换串格式。
2) 使用假设的十进制小数点,使得实数操作不会出现浮点运算的舍入误差的危险。
ASCII 加减法运行操作数为 ASCII 格式或非压缩十进制格式,但是乘除法只能使用非压缩十进制数。
在 32 位模式下,AAA ( 加法后的 ASCII 调整 ) 指令调整 ADD 或 ADC 指令的二进制运算结果。设两个 ASCII 数字相加,其二进制结果存放在 AL 中,则 AAA 将 AL 转换为两个非压缩十进制数字存入 AH 和 AL。一旦成为非压缩格式,通过将 AH 和 AL 与 30h 进 OR 运算,很容易就能把它们转换为 ASCII 码。
下例展示了如何用 AAA 指令正确地实现 ASCII 数字 8 加 2。在执行加法之前,必须把 AH 清零,否则它将影响 AAA 执行的结果。最后一条指令将 AH 和 AL 转换为 ASCII 数字:
mov ah, 0
mov al, '8' ; AX = 0038h
add al, '2' ; AX = 006Ah
aaa ; AX = 0100h (结果进行 ASCII 调整)
or ax, 3030h ; AX = 3130h ='10' (转换为 ASCH 码)
现在来查看一个过程,其功能为实现包含了隐含小数点的 ASCII 十进制数值相加。由于每次数字相加的进位标志位都要传递到更高位,因此,过程的实现要比想象的更复杂一些。下面的伪代码中,acc 代表的是一个 8 位的累加寄存器:
esi (index) = length of first_number - 1
edi (index) = length of first_number
ecx = length of first_number
set carry value to 0
Loop
acc = first_number[esi]
add previous carry to acc
save carry in carry1
acc += second_number[esi]
OR the carry with carry1
sum[edi] = acc
dec edi
Until ecx == 0
Store last carry digit in sum
进位值必须总是被转换为 ASCII 码。将进位值与第一个操作数相加时,就需要用 AAA 来调整结果。程序清单如下:
; ASCII Addition (ASCII_add.asm)
; 对有隐含固定小数点的串执行 ASCII 运算。
INCLUDE Irvine32.inc
DECIMAL_OFFSET = 5 ; 距离右侧的偏移量
.data
decimal_one BYTE "100123456789765" ; 1001234567.89765
decimal_two BYTE "900402076502015" ; 9004020765.02015
sum BYTE (SIZEOF decimal_one + 1) DUP(0),0
.code
main PROC
; 从最后一个数字开始
mov esi,SIZEOF decimal_one - 1
mov edi,SIZEOF decimal_one
mov ecx,SIZEOF decimal_one
mov bh,0 ; 进位值清零
L1: mov ah,0 ; 执行加法前清除AH
mov al,decimal_one[esi] ; 取第一个数字
add al,bh ; 加上之前的进位值
aaa ; 调整和数 (AH = 进位值)
mov bh,ah ; 将进位保存到 carry1
or bh,30h ; 将其转化为 ASCII 码
add al,decimal_two[esi] ; 加第二个数字
aaa ; 调整和数 (AH = 进位值)
or bh,ah ; 将进位值 carry1 进行 OR 运算
or bh,30h ; 将其转换为 ASCII 码
or al,30h ; 将 AL 转换为 ASCII 码
mov sum[edi],al ; 将 AL 保存到 sum
dec esi ; 后退一个数字
dec edi
loop L1
mov sum[edi],bh ; 保存最后的进位值
; 显示和数字符串
mov edx,OFFSET sum
call WriteString
call Crlf
exit
main ENDP
END main
程序输出如下所示,和数没有显示十进制小数点:
1000 5255 3329 1780
32 位模式下,AAS(减法后的 ASCII 调整)指令紧随 SUB 或 SBB 指令之后,这两条指令执行两个非压缩十进制数的减法,并将结果保存到 AL 中。AAS 指令将 AL 转换为 ASCII 码的数字形式。
只有减法结果为负时,调整才是必需的。比如,下面的语句实现 ASCII 码 数字 8 减去 9:
.data
val1 BYTE '8'
val2 BYTE '9'
.code
mov ah, 0
mov al,val1 ; AX = 0038h
sub al,val2 ; AX = OOFFh
aas ; AX = FF09h
pushf ; 保存进位标志位
or al,30h ; AX = FF39h
popf ; 恢复进位标志位
执行 SUB 指令后,AX 等于 00FFh。AAS 指令将 AL 转换为 09h,AH 减 1 等于 FFh,并且把进位标志位置 1。
32 位模式下,MUL 执行非压缩十进制乘法,AAM(乘法后的 ASCII 调整)指令转换由其产生的二进制乘积。乘法只能使用非压缩十进制数。
下面的例子实现 5 乘以 6,并调整 AX 中的结果。调整后,AX=0300h,非压缩十进制表示为 30:
.data
AscVal BYTE 05h, 06h
.code
mov bl, ascVal ;第一个操作数
mov al, [ascVal+1] ;第二个操作数
mul bl ;AX = 001Eh
aam ;AX = 0300h
同样在 32 位模式下,AAD(除法之前的 ASCII 调整)指令将 AX 中的非压缩十进制被除数转换为二进制,为执行 DIV 指令做准备。
下面的例子把非压缩 0307h 转换为二进制数,然后除以 5。DIV 指令在 AL 中生成商 07h,在 AH 中生成余数 02h:
.data
quotient BYTE ?
remainder BYTE ?
.code
mov ax, 0307h ; 被除数
aad ; AX = 0025h
mov bl, 5 ; 除数
div bl ; AX = 0207h
mov quotient,al
mov remainder,ah
本节讨论的指令仅用于 32 位编程模式。压缩十进制数的每个字节存放两个十进制数字,每个数字用 4 位表示。如果数字个数为奇数,则最高的半字节用零填充。存储大小可变:
bcd1 QWORD 2345673928737285h ;十进制数 2 345 673 928 737 285
bcd2 DWORD 12345678h ;十进制数 12 345 678
bcd3 DWORD 08723654h ;十进制数 8 723 654
bcd4 WORD 9345h ;十进制数 9345
bcd5 WORD 0237h ;十进制数 237
bcd6 BYTE 34h ;十进制数 34
压缩十进制存储至少有两个优势:
1) 数据几乎可以包含任何个数的有效数字。这使得以很高的精度执行计算成为可能。
2) 实现压缩十进制数与 ASCII 码之间的相互转换相对简单。
DAA(加法后的十进制调整)和 DAS(减法后的十进制调整)这两条指令调整压缩十进制数加减法的结果。可惜的是,目前还没有与乘除法有关的相似指令。在这些情况下,相乘或相除的数必须是非压缩的,执行后再压缩。
下面分别对 DAA 指令和 DAS 指令做详细介绍: 《DAA 指令》 《DAS 指令》
32 位模式下,ADD 或 ADC 指令在 AL 中生成二进制和数,DAA(加法后的十进制调整)指令将和数转换为压缩十进制格式。比如,下述指令执行压缩十进制数 35 加 48。二进制和数(7Dh)被调整为 83h,即 35 和 48 的压缩十进制和数。
mov al, 35h
add al, 48h ; AL = 7Dh
daa ; AL = 83h (调整后的结果)
【示例】下面的程序执行两个 16 位压缩十进制整数加法,并将和数保存在一个压缩双字中。加法要求和数变量的存储大小比操作数多一个数字:
; 压缩十进制示例 (AddPacked.asm)
; 演示压缩十进制加法。
INCLUDE Irvine32.inc
.data
packed_1 WORD 4536h
packed_2 WORD 7207h
sum DWORD ?
.code
main PROC
; 初始化和数与索引
mov sum,0
mov esi,0
; 低字节相加
mov al,BYTE PTR packed_1[esi]
add al,BYTE PTR packed_2[esi]
daa
mov BYTE PTR sum[esi],al
; 高字节相加,包括进位标志位
inc esi
mov al,BYTE PTR packed_1[esi]
adc al,BYTE PTR packed_2[esi]
daa
mov BYTE PTR sum[esi],al
; 若还有进位,则加上该进位值
inc esi
mov al,0
adc al,0
mov BYTE PTR sum[esi],al
; 用十六进制显示和数
mov eax,sum
call WriteHex
call Crlf
exit
main ENDP
END main
32 位模式下,SUB 或 SBB 指令在 AL 中生成二进制结果,DAS(减法后的十进制调整)指令将其转换为压缩十进制格式。
具体调整规则如下:
- 如果 AL 的低四位大于 9,或 AF=1,那么,AL=AL-06H,并置 AF=1;
- 如果 AL 的高四位大于 9,或 CF=1,那么,AL=AL-60H,并置 CF=1;
- 如果以上两点都不成立,则清除标志位 AF 和 CF。
经过调整后,AL 的值仍是压缩型 BCD 码,即:二个压缩型 BCD 码相减,并进行调整后,得到的结果还是压缩型 BCD 码。
比如,下面的语句计算压缩十进制数 85 减 48,并调整结果:
mov bl,48h
mov al,85h
sub al,bl ; AL = 3Dh
das ; AL = 37h (调整后的结果)
DAS 的内部逻辑请参阅 Intel 指令集参考手册。