The Self Service Cloud-Native Data Analysis Platform is a project to build an end-to-end data analysis platform using managed services considering the tradeoffs they offer.
Our project aims to satisfy real world use cases of managed data science technology to accomplish data analysis tasks. The cloud toolkit is constantly growing and data scientists must consider the tradeoffs of managed services in order to select a toolkit that meets their specific requirements. Through researching data science application and cloud technologies, along with following guidelines set by our mentors, our team will target specific data analysis use cases and build an end-to-end data analysis platform for use by data scientists.
Goals:
- Explore the variety of managed services that exist for each component (Compute, Storage, Data Analysis, Security, and UI) and make selections based on our use-case requirements
- Develop each component using selected managed services
- Provide capability to accomplish a realworld, end-to-end, data analysis use case
- Implement infrastructure that can:
- Pull and store data in a storage solution
- Perform transform operations and analysis on data
- Leverage standardized data science software (Tensorflow, Jupyter, etc.)
- Secure data and implement authorization requirements
The platform will be used by data scientists with end-to-end data analysis use cases utilizing cloud technologies.
It doesn’t target:
- Data scientists with strict security and compliance requirements (Ex: HIPAA)
- Data scientists with pre-defined, non-matching technology requirements
- Compute
- Provide a compute environment using IaaS solutions
- Does not need to provide several compute options
- Storage
- Provide cloud storage solution
- Users must be able to push and pull data from one or more sources
- Data Analysis
- Support ability to run scripts (Python) to transform and analyze data
- Users are free to install tools and services on their compute environment, beyond what we provide
- Security
- Authorization settings to control which users can access and modify specific data
- Platform is not HIPAA compliant
- Fine-grained access control between users is not provided
- User Interface
- Web interface through which users can register to our platform
- Does not provide capability to perform data analysis tasks, users must SSH into their individual compute environments
- Provides limited capability to control individaul cloud resources
- Programmatic infrastructure management and orchestration using Terraform
The core concept behind this project is to develop an end-to-end data analysis platform that uses various cloud resources, data analysis tools, and other technologies to provide a managed service for use by data scientists. Users of our platform will find that it is a far more efficient method of setting up data analysis environment and will enable them to complete certain data science tasks. The platform will not be an all-encompassing solution, but will have to make certain tradeoffs based on requirements from our mentors and what our team learns through research.
High-level outline of the solution:
- Compute: Use existing IaaS solutions like AWS EC2 or GCP (can also use Container solution)
- Storage: Cloud-native technologies like AWS S3/GCP GCS/ DynamoDB/Spanner
- Data Analysis: Use data analysis platforms like Jupyter and Pandas to support machine learning programs of Tensorflow/Pytorch.
- Permission and Access Control: Provide security solutions between services and external access (AWS IAM).
- Front-end UI: HTML/CSS/JS for webpage and Python Flask for web application
Architecture Diagram:
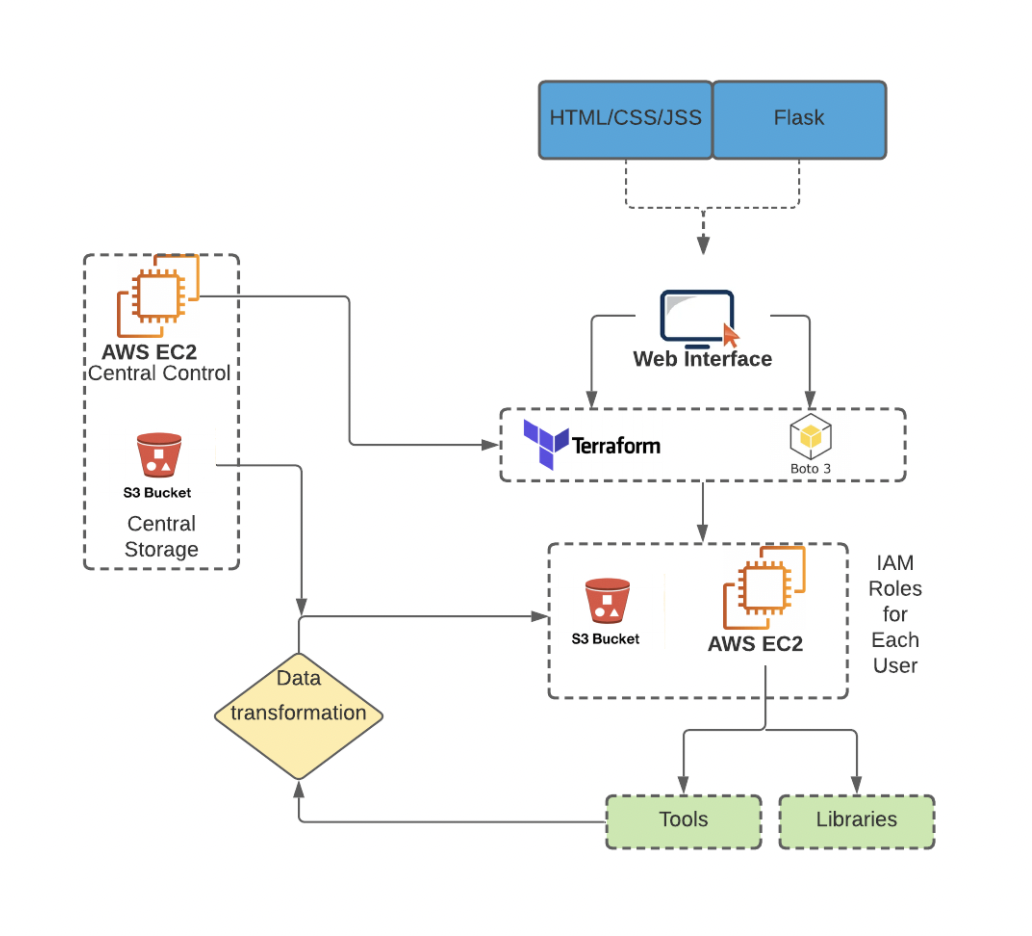
Minimum acceptance criteria is a self service platform that can:
- Provide a compute environment for data analysis tasks.
- Provide storage from which users can extract and store data.
- Support standardized data science software (Tensorflow, Jupyter, etc).
- Allocate storage and computation resources to ETL pipelines based on user requirement.
- Implement security controls to enable authorization requirements
Stretch goals include:
- Use this project to analyze Boston Open Data
- Provide several compute and storage configurations
- Build a user friendly UI to interact with the platform
- Provide cloud infrastructure options from other cloud providers (Azure, Google Cloud Platform, etc.)
Release #1 (due by Week 5) - Demo #1:
- Explore compute, storage, data anaylsis, and security managed services and technologies
- When end-users decide to upload the data, we can extract the data from their buckets and store them in our built databases.
Release #2 (due by Week 9) - Demo #2:
- Implement storage using S3 and push and pull data
- Utilize Terraform to automate AWS infrastructure deployment
- Use Parquet and SQLite to manage data
Release #3 (due by Week 11) - Demo #3:
- Launch a Jupyter Notebook on an EC2 container via Terraform
- Use Terraform to create storage buckets
- Expand on data analysis functionality
Release #4 (due by Week 13) - Demo #4:
- Implement security and access functionality in platform
- Use Terraform to extract and upload data in storage
- Expand on platform functionality
Release #5 (due by Week 15) - Demo #5:
- Implement web interface
- Prepare final product
Deployment Instructions Wiki page
- Dan Hyland: dan.hyland@twosigma.com
- Edward Yang: edward.yang@twosigma.com
- Ibrahim Chand: ichand@bu.edu
- Zihang Jiang: jzh15@bu.edu
- Anish Yennapusa: anishry@bu.edu
- Ze Yu: zey@bu.edu