The main reason why I decided to develop this process queue was the learning of Erlang/OTP structures and APIs using Elixir. There are probably many other processing queue in-background services that are far more efficient than the one written here.
However, I believe that it is interesting for beginners to just have access to simpler structures, both from a programming logic and OTP operational perspective. That's why I chose to make a this software from the get-go in order to be able to explain the decision making and, eventually, improve it as the community shows that one or another option is better, through pull requests or issues in this repository. I am sure that what is dealt with here will be of great help for everyone learning, or seeking to improve his/her skills in Elixir, including me.
The picture below shows a complete diagram of the data flow and possible system events.
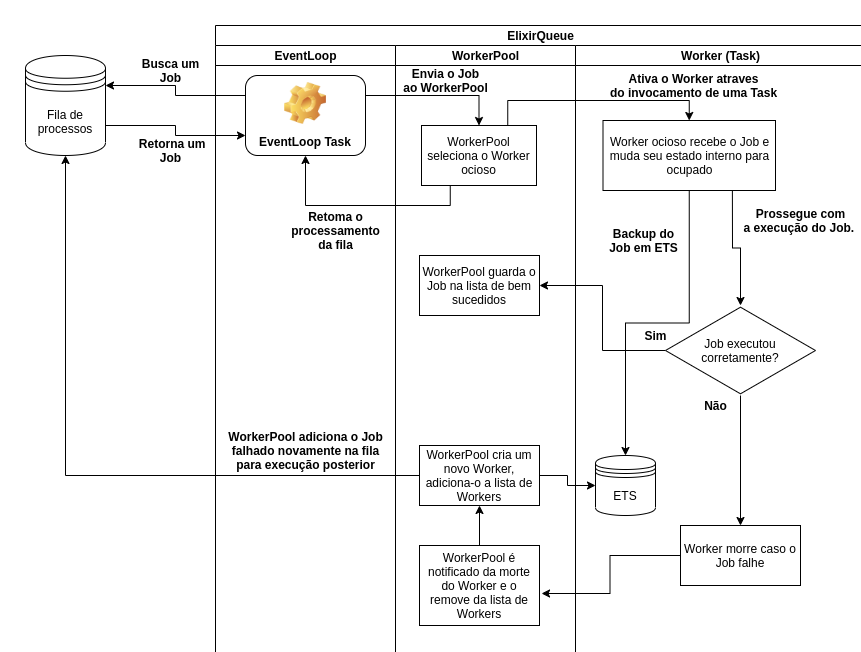
The Application of this process queue supervises the processes that will create/consume the queue. Here are the children of ElixirQueue.Supervisor:
children = [
{ElixirQueue.Queue, name: ElixirQueue.Queue},
{DynamicSupervisor, name: ElixirQueue.WorkerSupervisor, strategy: :one_for_one},
{ElixirQueue.WorkerPool, name: ElixirQueue.WorkerPool},
{ElixirQueue.EventLoop, []}
]The children, from top to bottom, represent the following structures:
ElixirQueue.Queueis theGenServerthat stores the queue state in a tuple.ElixirQueue.WorkerSupervisoris theDynamicSupervisorof the dynamically added workers always equal to or less than the number of onlineschedulers.ElixirQueue.WorkerPoolis the process responsible for saving thepidsof the executed workers and jobs, whether successful or failed.ElixirQueue.EventLoop, which is theTaskthat "listens" to the changes in theElixirQueue.Queue(i.e., in the process queue) and removes jobs to be executed.
The specific functioning of each module I will explain as it seems useful to me.
Here is the process that controls the removal of elements from the queue. A event loop by default is a function that executes in an iteration/recession pseuedo-infinitetely, since there is no intention to break the loop. With each cycle the loop looks for jobs added to the queue - that is, in a way ElixirQueue.EventLoop "listens" for changes that have occurred in the queue and reacts from these events - it directs them to ElixirQueue.WorkerPool to be executed.
This module assumes the behavior of Task and its only function (event_loop/0) does not return any value since it is an eternal loop: it searches the queue for some element and can receive either:
- a tuple
{:ok, job}with the task to be performed. In this case, it sends to theElixirQueue.WorkerPoolthe task and executesevent_loop/0again. - a tuple
{:error, :empty}in case the queue is empty. In the second case it just executes the function itself recursively, continuing the loop until it finds some relevant event (element insertion in the queue).
The ElixirQueue.Queue module holds the heart of the system. Here the jobs are queued up to be consumed later by the workers. It is a GenServer under the supervision of ElixirQueue.Application, which stores a tuple as a state and in that tuple the jobs are stored - to understand why I preferred a tuple rather than a chained list (List), I explained this decision in the section Performance Analysis further below.
The Queue is a very simple structure, with trivial functions that basically clean, look for the first element of the queue to be executed and insert an element at the end of the queue, so that it can be executed later, as inserted.
Here is the module capable of communicating with both the queue and the workers. When the Application is started and the processes are supervised, one of the events that occurs is precisely the initiation of the workers under the supervision of the ElixirQueue.WorkerSupervisor, the DynamicSupervisor, and their respective PIDs are added to the ElixirQueue.WorkerPool state. In addition, each worker started within the scope of the WorkerPool is also supervised by this, the reason for this will be addressed later.
When WorkerPool receives the request to execute a job it looks for any of its workers PIDs that are in the idle state, that is, without any jobs being executed at the moment. Then, for each job received by the WorkerPool through its perform/1, it links the job to a worker PID, which goes to the busy state. When the worker finishes the execution, it clears its state and then transitions itself to idle, waiting for another job.
In this case, what we call a worker is nothing more than a Agent which stores in its state which job is being executed linked to that PID; it serves as a limiting ballast since the WorkerPool starts a new Task for each job. Imagine the scenario where we didn't have workers to limit the amount of jobs being executed concurrently: our EventLoop would start Tasks at its whim, and could cause some trouble, e.g. memory overflow if Queue received a big load of jobs at once.
In this module we have the actors responsible for taking the jobs and executing them. But the process is a little more than just executing the job; it actually works as follows:
- The
Workerreceives a request to perform a certain job, adds it to its internal state (internal state of the past PID agent) and also to a backup:etstable. - Then it goes to the execution of the job itself. It is indispensable to remember that the execution occurs in the scope of the
Taskinvoked by theWorkerPool, and not in the scope of the Agent's process. It is an implementation detail I chose because of its simplicity, but it can be done in other ways. - Finally, with the job finished, the
Workerreturns its internal state to idle and excludes the backup of this worker from the:etstable. - With the
Workerfunction having been fulfilled, the execution track goes back to theTaskinvoked by theWorkerPooland completes the race by inserting the job in the list of successful jobs.
What happens if a Worker dies? Asked differently, why do we need an WorkerPool supervisioning Workers?
As you might have noticed, there is no point in the jobs execution trail where we worry about the question: what happens if a badly done function is passed as a job to the execution queue, or even!, what happens if some Agent Worker process simply corrupts the memory and dies?
In order to write the code as robust as possible, and as idiomatic as possible too, what has been done is precisely to add guarantees that if the processes fail (and it will fail!) the system can react in such a way as to mitigate the errors.
When a worker fails to die via the EXIT signal, the WorkerPool (which monitors all their workers via the Process.monitor) replaces this dead worker with another, adding it to the WorkerSupervisor. This also removes the PID from the dead Worker list and adds the new one. But it doesn't stop there: the WorkerPool checks for some backup created from the dead Worker and, finding it, replaces the job in the queue with its value of attempt_retry plus one. The WorkerPool will always add the job back to the queue a predetermined number of times, defined in the mix.exs file in the environment of application.
For the process queue to work normally, I just need to insert at the end and remove from the head. Clearly this can be done with both List and Tuple, and I opted for tuple simply because it is faster. Result from Benchee's output running mix run benchmark.exs at the root of the project:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
Number of Available Cores: 8
Available memory: 15.56 GB
Elixir 1.10.2
Erlang 22.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking Insert element at end of linked list...
Benchmarking Insert element at end of tuple...
Name ips average deviation median 99th %
Insert element at end of tuple 4.89 K 204.42 μs ±72.94% 119.45 μs 571.85 μs
Insert element at end of linked list 1.24 K 808.27 μs ±54.67% 573.68 μs 1896.52 μs
Comparison:
Insert element at end of tuple 4.89 K
Insert element at end of linked list 1.24 K - 3.95x slower +603.85 μs
I prepared a stress test for the application that queues 1000 fake jobs, each one sorting a List in reverse order with 3 million elements, using Enum.sort/1 (according to the documentation, the algorithm is a merge sort). To execute it just enter the terminal via iex -S mix and run ElixirQueue.Fake.populate; the execution takes a few minutes (and at least 2gb of RAM), and then you can check the results with ElixirQueue.Fake.spec.
To see the process queue working just execute iex -S mix at the project root and use the commands below. Unless you are in test mode, you will see logs about the execution of the job.
You can build the struct of the job by hand and pass it to the queue.
iex> job = %ElixirQueue.Job{mod: Enum, func: :reverse, args: [[1,2,3,4,5]]}
iex> ElixirQueue.Queue.perform_later(job)
:okWe can also manually pass the module values, function and arguments to perform_later/3.
iex> ElixirQueue.Queue.perform_later(Enum, :reverse, [[1,2,3,4,5]])
:ok