
浩瀚宇宙,从 点 到线,线到面,面到体,组成了丰富多彩的世界。动物、植物和其他物体正是存储在 宇宙 这个数据结构中。
前几篇文章介绍了 线性 的数据结构:
ArrayList、LinkedList及其组合HashMap。从 线性 数据结构到 非线性 数据结构,就像 树干 发叉一样:
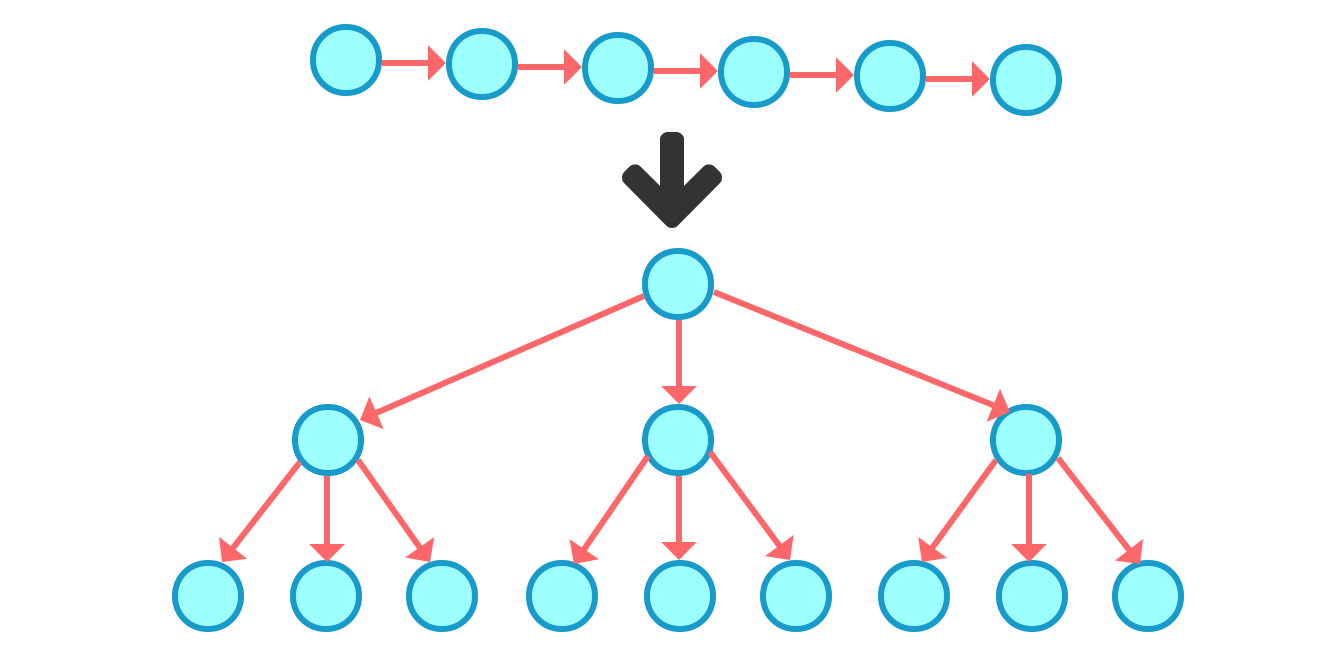
从数据结构进化的角度来看,:palm_tree:树(tree) 的生成是 链表 进化而来。链(Linked) 每个节点最多只有一个 前驱节点 ,那么可以称这个 链 为 🌴树(tree) 。数据结构中的树就像一颗倒挂的树。
链表 只不过是特殊的树,就像树没有树枝只有树干一样。
- 节点(Node):树中的每个元素称为 节点(Node);
- 根节点(Root Node):树最顶端的节点被称为根节点(树根),根节点无父节点;
- 父节点(Parent Node):节点的(上面的)前驱节点在树中被称为父节点;
- 子节点(Child Node):(下面的)后继节点被称为子节点;
- 子树(Subtree):子节点及其下面的节点组成的树称为子树 ;
- 一棵树最多只有一个根节点,树中的每个子节点最多只有一个父节点;
- 节点的度:一个节点含有的子树的个数称为该节点的度(叶子节点的度为0);
- 🍃叶节点(Leaf Node)(叶子节点或终端节点):度为0的节点称为叶节点(也就是没有子节点的节点称为叶子节点);
- 非终端节点 或分支节点:度不为0的节点(拥有子节点的节点);
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 树的度:一棵树中,节点中最大的度称为树的度;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;
- 节点的祖先:从该节点上溯至根节点,所经分支上的所有节点;
- 子孙节点:该节点下面所有所有的节点称为该节点的子孙节点;
- 空树:没有节点的树称为空树;
- 森林:由多棵互不相交(没有重叠节点)的树组成的集合称为森林(单棵树可以认为是特殊的森林);
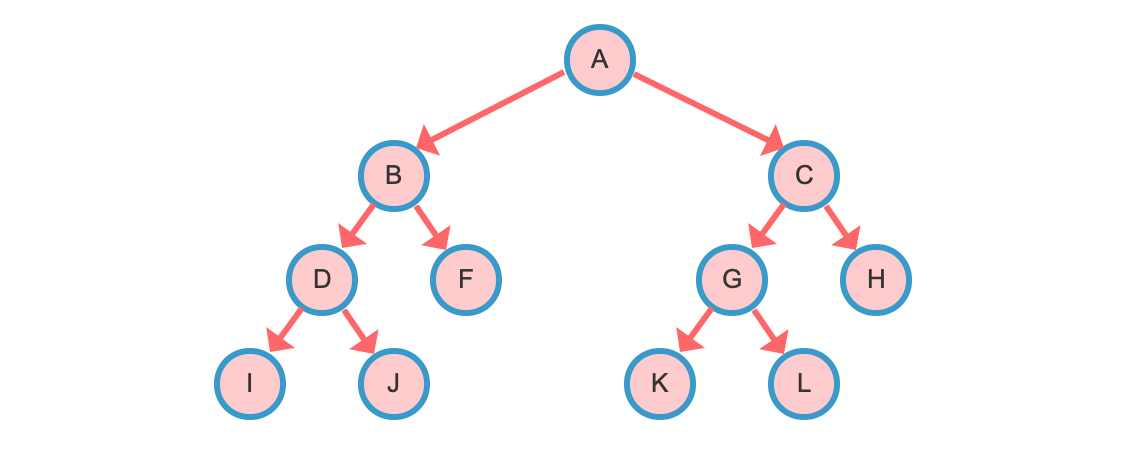
二叉树是每个节点最多只有两个子树的树。子树通常被称为左子树(Left subtree)和右子树(Right subtree)。
- 在非空二叉树的
i层上,至多有 **$$2^{i-1}$$**个节点(i>=1); - 在深度为
d的二叉树上最多有2d-1个结点(d>=1); - 对于任何一棵非空的二叉树,如果叶节点个数为
n0,度数为2的节点个数为n2,则有:n0 = n2 + 1。
二叉树遍历:从树的根节点出发,按照某种 次序 依次访问二叉树中所有的节点,使得每个节点被访问仅且一次。
这里有两个关键词:访问 和 次序。访问 包括 增删改查, 次序 包括 前序、中序、后序,前中后是以树的根节点作为参照物:triangular_flag_on_post:,又规定不管如何遍历 左子树 的访问顺序要排在 右子树 前面(左边)。
遍历步骤:先访问根节点,然后再先序遍历左子树,最后再先序遍历右子树即 根—左—右。
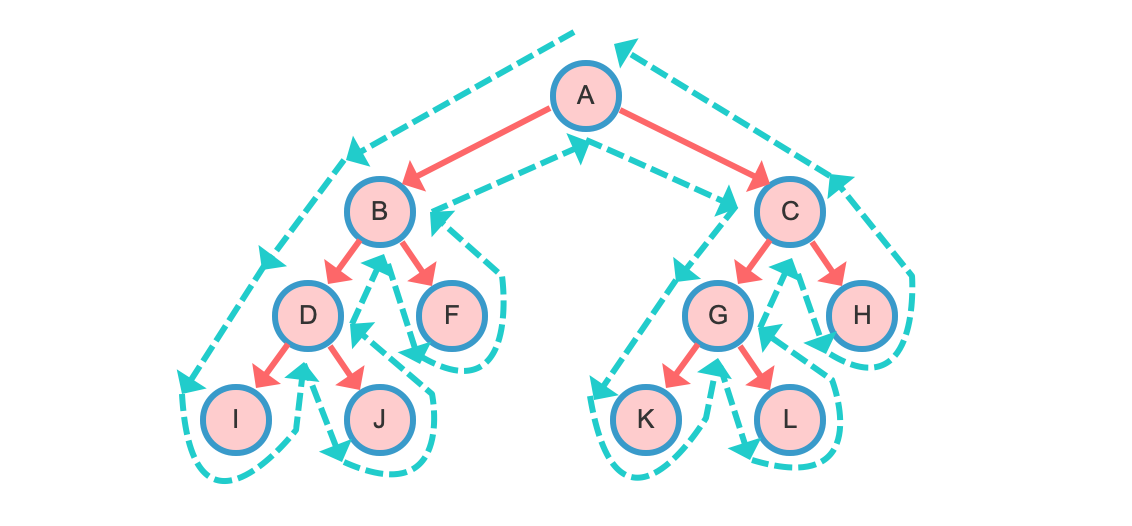
上图先序遍历的结果:
遍历步骤:先中序遍历左子树,然后再访问根节点,最后再中序遍历右子树即 左—根—右。
上图中序遍历的结果:
遍历步骤:先后序遍历左子树,再后序遍历右子树,最后再访问根节点,即 左—右—根。
上图后序遍历的结果:
平衡二叉树(Balanced Binary Tree)的 平衡性 体现在以下几点:
- 树的左、右子树的 高度差 的绝对值不超过1;
- 任意节点左、右子树也分别平衡二叉树;
一棵数频繁的删除和插入节点都有可能使数发生旋转。平衡二叉树中访问节点的操作(插入、查找、删除)的时间复杂度维持在一个“平衡”的水准,既最坏情况和最好情况的时间复杂度维持在 O(logN)。
二叉查找树(二叉搜索树 Binary Search Tree)的 查找 特性体现在以下几点:
- 如果它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 如果它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点左、右子树也分别为二叉查找树。
- 从树的根节点开始查找,并沿着这棵树中的一条简单路径向下进行;
- 若树为空树,则查找失败,返回
null; - 对于访问的每个节点
x,若指定的值k等于结点x的值,返回该节点x并结束查找; - 若指定的值
k小于节点x的值,则在节点x的左子树中查找(根据上面二叉查找树的性质判断); - 相反,若指定的值
k大于节点x的值,则查找在节点x的右子树中继续; - 若查找至 叶子节点 后仍未匹配到相等值,则表示不存在指定值的节点,返回null。
AVL树 得名于它的两位发明者G. M. Adelson-Velsky和E. M. Landis的名字,树的特性是:
- 😉本身首先是一棵二叉查找树;
- 每个节点的左右子树的高度之差的绝对值(平衡因子)最多为
1;
ALV追求极限的平衡性,优点是在查找元素时,时间复杂度低,查找元素快。那么问题来了,在添加/删除元素时,AVL树为了追求“绝对的平衡性”,不断的通过循环来达到自平衡,增加时间复杂度。适所以AVL树适用于添加/删除元素少、查找操作多的环境下。
红黑树(Red Black Tree) 也是一种 平衡二叉树(而平衡二叉树又是一种二叉查找树,所以红黑树也是一种二叉查找树),但它不像 AVL树 那样追求绝对的平衡,它这种于查找和添加/删除之间。特性是:
- 树中所有节点都被染成红色🔴或黑色⚫️(官方话语:节点是红色或黑色);
- 根节点和叶子节点都是黑色⚫️
- 每个红色节点🔴的两个子节点都是黑色⚫️(从每个叶子到根的所有路径上不能有两个连续的红色节点🔴);
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点⚫️。
上述特性构成了一个最关键的约束:从根节点到叶子节点的最长路径不大于最短路径的两倍长。
所以红黑树可以不是那么绝对的高度平衡。对于在树中添加/删除元素,红黑树也不像AVL树那样,为了达到绝对的自平衡而“使劲费力”地旋转整颗树了。
最差平衡二叉树即树退化成链表(可以看成特殊的树、没有叉的树),这样的树添加/删除元素快,不需要自平衡,但是查找慢,最坏情况要遍历整棵树。而从增删改查的时间复杂度来讲,红黑树 介于 二叉查找树 和 链表 之间,这是在添加/删除和查找之间一个折中的选择。
链表:适用于添加/删除多、查找少的场景;
二叉查找树:适用于查找多、添加/删除少的场景;
红黑树:适用于查找、添加、删除都多的场景。
这种和MySQL的InnoDB索引息息相关,单独拿出一个章节去讲解,详见: