
在一间教室里有一排座椅,这一排座椅线性排列对应的数据结构是 数组,数组的特点是可以根据下标(索引)快速🔜访问,通过下标(索引)访问的位置
table[i]称为 槽(slot),在伴随着哈希算法计算的槽称为 哈希槽。假设这排座椅共16个座位💺,编号从0,1,2…开始直到15。学校有很多学生,他们的编号也是从0,1,2…起始,有很多同学喜欢坐在一起,学校🏫为了让他们散列分开坐,采用模运算的方式。比如 1号同学的对座椅长度16模运算得1,那么你坐在1号位置,5号同学对座椅长度16模运算得5,那么他坐在5号位置,以此类推。1号座位已经被1号同学占用,新来的17号同学对16作模运算也得1,按照原来的算法,他也应该坐在1号,此时17号同学和1号同学的座位💺就 冲突。
实际上 “编号” 多种多样,如果它们共有某种特性、聚集密度增加,冲突 概率就有可能增大,为了防止这些 项(元素) 过于集中,而将它们按照某种算法 散列 分布,这种算法称为 Hash算法,翻译成散列算法,根据音译常翻译成哈希算法,通过 哈希算法 计算后的值称为哈希码或 散列码(HashCode)。假如
1.1中学生的编号不是数字,而是其他字符组合,比如学生周星星的编号是ZXX9573,非Number类型的字符串是不能进行数学模运算的,即使能使用模运算也不能最大化的将他们散列开。所以使用 哈希算法 计算出 哈希码,然后根据模运算来决定它们该进入哪个 槽,这里的槽也称为 哈希槽。这个通过 散列 方式存储元素的阵列容器称为 散列表 (hashtable),不过大多数人喜欢叫它哈希表。
如果跟据 哈希算法 计算得到的 哈希码 有多个相同的,那么模运算后得到的 哈希槽 也一定相同,也就产生了新的冲突,这种冲突称为 哈希冲突(哈希碰撞💥)。

一个元素与另一个元素关于某个地址(或槽)发生了冲突,将开放其他地址给此元素使用,这种算法称开放定址法 或 开放地址法。如何寻找适合的开放地址给此元素使用,这种寻找的过程或者技术称为探测技术。常见的 “寻找技术” 有如下几种:
接上面的故事,假设 1号座位已经有人,然后根据哈希算法计算出
周星星应该落到 1号 座位,这时出现哈希冲突,然后按照线性方式探测下 1 个座位(哈希槽),如果2号座位(哈希槽)也有人,然后再按照线性方式探测下 1 个座位(哈希槽)... 以此类推。此种方式就是 线性探测。其中 “下 1 个” 指的是 步长(也称为增量),你也可以将步长定为2,那就是下2个。实际上根据步长计算出的一批地址,这批地址称为地址序列。
将步长(增量)改为
这种增量序列。从 增量i 可以看出正负交替,特点是在探测时左右
↔️ 跳跃式探测。
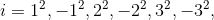
原来线性探测的步长都是已知数,现在将每个步长改为随机获取。实际过程也是随机产生一批随机数,也就是 随机序列。
再哈希法是有多个哈希函数(算法),当第一次产生哈希冲突时,就使用第二个哈希函数,如果还产生哈希冲突就使用第三个,以此类推,再次哈希,直达无冲突,这样的做法会增加哈希计算时间。
当多个元素产生哈希冲突时,它们的哈希码是一定相同,落脚的哈希槽也相同。将它们通过地址引用一一相连,也就是形成 链表 的形式。这样它们既可以存储,又不会占用其他哈希槽的位置。这种通过链表形式解决哈希冲突的算法称为链表法。由不同元素、相同哈希码经过组织形成的数据结构称为 哈希桶Bucket,或者说这个容器是 哈希桶。哈希槽的位置也就是哈希桶号 。
为所有产生哈希冲突的元素建立一个公共溢出区域来存放溢出的元素。在查找时,如果通过计算发现对应的哈希槽处没该元素,则进入公共溢出区 进行查找,溢出的元素相对于 散列表 来说是比较小的。原来的表称为基本表,公共溢出区又称溢出表。