loss doesn't decrease and keep on 40 in my dataset #24
Comments
|
it would be appreciated if you give some advise on this issue |
|
Can you detect anything in the testset?if not,what is your learning rate,lr decay pacience? |
|
I am sorry, it seems to my mistakes. |
|
correct |
|
I got a lower loss than 40, but it still is 38 |
|
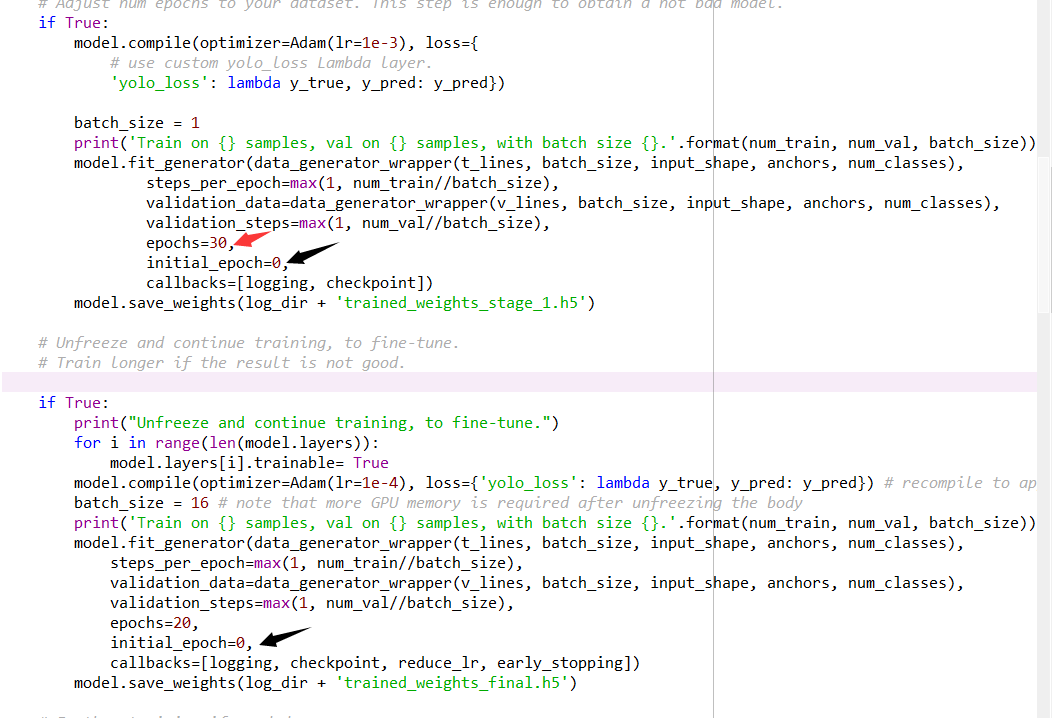
And why is it divided into step-by-step training?the first training? the second training ?What is their role? |
|
The first training part is for finetuning a model quickly. It freezes most layers, only to train on the last few layers. We can get an acceptable model for detection in a short period of time The second training part is for getting a complete model. All the layers can be trained through this process. Under most occasions, I only use the second part. Epoch under is not important here. |
After model training, I have a model with size of 277M. It is bigger than YOLO-v3,Why?
|
I train with my own dataset with the default script
my dataset has three types of objection with 40000 train sample and 6000 validation sample
the batch_size is 4, my loss decrease to 49 in the first epoch, but loss keep on 40 in the 13th epoch, the loss doesn't decrease anymore.
how should i change my learning rate and others parameter
The text was updated successfully, but these errors were encountered: