Training spec #6
Comments
|
I'm sorry but I cannot remember the detailed training configurations for the example loss figure described in README:
But I can share the other training result with its configurations. It should be helpful! Dataset
Model
Environment
Result
|
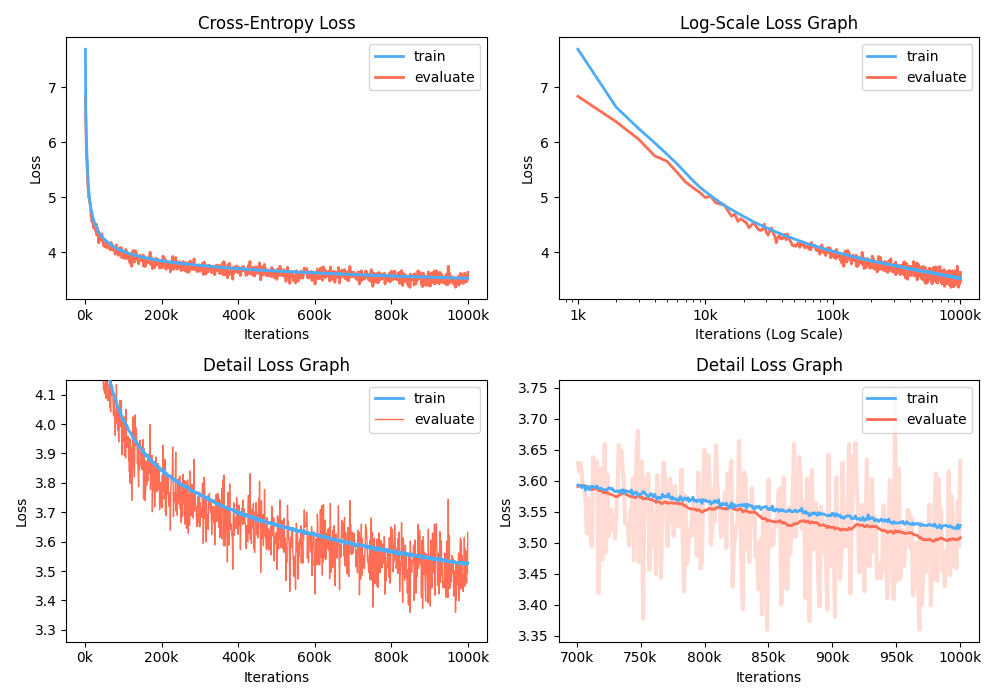
|
Thank you! |
Closed
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I have question about training spec of your model. I want to know about sequence length, batch size, training time, GPU type, # of GPU, # of training samples, and loss
You looks like acquire 3.7 loss. Could you describe the parameter of training to acquire those performance?
GPT2/src/gpt2/train_model.py
Line 93 in 71ebf91
Are these parameters used to get the loss ?
The text was updated successfully, but these errors were encountered: