We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
业内常说数据决定了模型效果上限,而机器学习算法是通过数据特征做出预测的,好的特征可以显著地提升模型效果。这意味着通过特征生成(即从数据设计加工出模型可用特征),是特征工程相当关键的一步。本文从特征生成作用、特征生成的方法(人工设计、自动化特征生成)展开阐述并附上代码。
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。 ——Andrew Ng
特征生成是特征提取中的重要一步,作用在于:
本文示例的数据集是客户的资金变动情况,如下数据字典:
cust_no:客户编号;I1 :性别;I2:年龄 ;E1:开户日期; B6 :近期转账日期;C1 (后缀_fir表示上个月):存款;C2:存款产品数; X1:理财存款; X2:结构性存款; label:资金情况上升下降情况。
这里安利一个超实用Python库,可以一键数据分析(数据概况、缺失、相关性、异常值等等),方便结合数据分析报告做特征生成。
# 一键数据分析 import pandas_profiling pandas_profiling.ProfileReport(df)
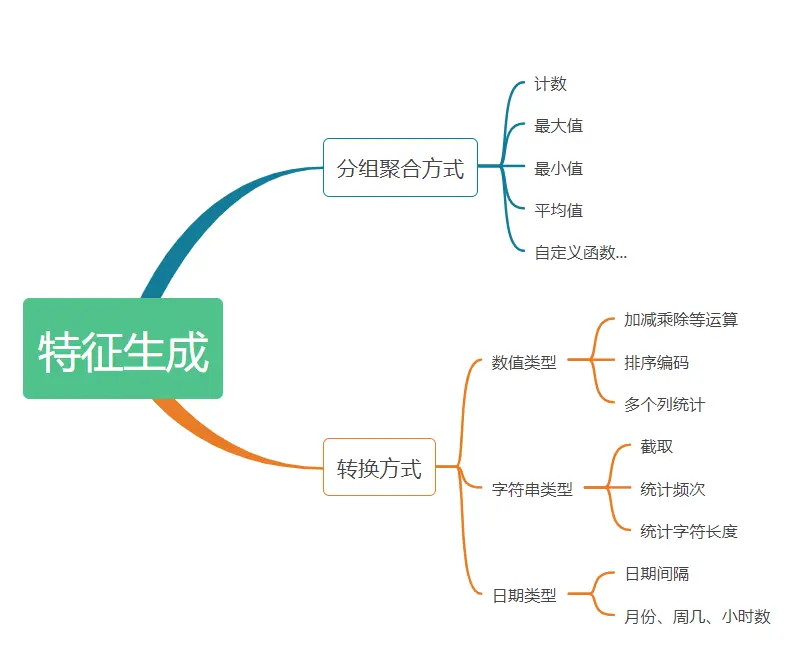
特征生成方法可以分为两类:聚合方式、转换方式。
聚合方式是指对存在一对多的字段,将其对应多条记录分组聚合后统计平均值、计数、最大值等数据特征。 如以上述数据集,同一cust_no对应多条记录,通过对cust_no(客户编号)做分组聚合,统计C1字段个数、唯一数、平均值、中位数、标准差、总和、最大、最小值,最终得到按每个cust_no统计的C1平均值、最大值等特征。
# 以cust_no做聚合,C1字段统计个数、唯一数、平均值、中位数、标准差、总和、最大、最小值 df.groupby('cust_no').C1.agg(['count','nunique','mean','median','std','sum','max','min'])
此外还可以pandas自定义聚合函数生成特征,比如加工聚合元素的平方和:
# 自定义分组聚合统计函数 def x2_sum(group): return sum(group**2) df.groupby('cust_no').C1.apply(x2_sum)
转换方式是指对字段间做加减乘除等运算生成数据特征的过程,对不同字段类型有不同转换方式。
import numpy as np # 前后两个月资金和 df['C1+C1_fir'] = df['C1']+df['C1_fir'] # 前后两个月资金差异 df['C1-C1_fir'] = df['C1']-df['C1_fir'] # 产品数*资金 df['C1*C2'] = df['C1']*df['C2'] # 前后两个月资金变化率 df['C1/C1_fir'] = df['C1']/df['C1_fir'] - 1 df.head()
import numpy as np df['C1_sum'] = np.sum(df[['C1_fir','C1']], axis = 1) df['C1_var'] = np.var(df[['C1_fir','C1']], axis = 1) df['C1_max'] = np.max(df[['C1_fir','C1']], axis = 1) df['C1_min'] = np.min(df[['C1_fir','C1']], axis = 1) df['C1-C1_fir_abs'] = np.abs(df['C1-C1_fir']) df.head()
# 排序特征 df['C1_rank'] = df['C1'].rank(ascending=0, method='dense') df.head()
截取 当字符类型的值过多,通常可对字符类型变量做截取,以减少模型过拟合。如具体的家庭住址,可以截取字符串到城市级的粒度。
字符长度 统计字符串长度。如转账场景中,转账留言的字数某些程度可以刻画这笔转账的类型。
频次 通过统计字符出现频次。如欺诈场景中地址出现次数越多,越有可能是团伙欺诈。
# 字符特征 # 由于没有合适的例子,这边只是用代码实现逻辑,加工的字段并无含义。 #截取第一位字符串 df['I1_0'] = df['I1'].map(lambda x:str(x)[:1]) # 字符长度 df['I1_len'] = df['I1'].apply(lambda x:len(str(x))) display(df.head()) # 字符串频次 df['I1'].value_counts()
常用的有计算日期间隔、周几、几点等等。
# 日期类型 df['E1_B6_interval'] = (df.E1.astype('datetime64[ns]') - df.B6.astype('datetime64[ns]')).map(lambda x:x.days) df['E1_is_month_end'] = pd.to_datetime(df.E1).map(lambda x :x.is_month_end) df['E1_dayofweek'] = df.E1.astype('datetime64[ns]').dt.dayofweek df['B6_hour'] = df.B6.astype('datetime64[ns]').dt.hour df.head()
传统的特征工程方法通过人工构建特征,这是一个繁琐、耗时且容易出错的过程。自动化特征工程是通过Fearturetools等工具,从一组相关数据表中自动生成有用的特征的过程。对比人工生成特征会更为高效,可重复性更高,能够更快地构建模型。
Featuretools是一个用于执行自动化特征工程的开源库,它有基本的3个概念: 1)Feature Primitives(特征基元):生成特征的常用方法,分为聚合(agg_primitives)、转换(trans_primitives)的方式。可通过如下代码列出featuretools的特征加工方法及简介。
import featuretools as ft ft.list_primitives()
2)Entity(实体) 可以被看作类似Pandas DataFrame, 多个实体的集合称为Entityset。实体间可以根据关联键添加关联关系Relationship。
# df1为原始的特征数据 df1 = df.drop('label',axis=1) # df2为客户清单(cust_no唯一值) df2 = df[['cust_no']].drop_duplicates() df2.head() # 定义数据集 es = ft.EntitySet(id='dfs') # 增加一个df1数据框实体 es.entity_from_dataframe(entity_id='df1', dataframe=df1, index='id', make_index=True) # 增加一个df2数据实体 es.entity_from_dataframe(entity_id='df2', dataframe=df2, index='cust_no') # 添加实体间关系:通过 cust_no键关联 df_1 和 df 2实体 relation1 = ft.Relationship(es['df2']['cust_no'], es['df1']['cust_no']) es = es.add_relationship(relation1)
3)dfs(深度特征合成) : 是从多个数据集创建新特征的过程,可以通过设置搜索的最大深度(max_depth)来控制所特征生成的复杂性
## 运行DFS特征衍生 features_matrix,feature_names = ft.dfs(entityset=es, target_entity='df2', relationships = [relation1], trans_primitives=['divide_numeric','multiply_numeric','subtract_numeric'], agg_primitives=['sum'], max_depth=2,n_jobs=1,verbose=-1)
4.2.1 内存溢出问题 Fearturetools是通过工程层面暴力生成所有特征的过程,当数据量大的时候,容易造成内存溢出。解决这个问题除了升级服务器内存,减少njobs,还有一个常用的是通过只选择重要的特征进行暴力衍生特征。
4.2.2 特征维度爆炸 当原始特征数量多,或max_depth、特征基元的种类设定较大,Fearturetools生成的特征数量巨大,容易维度爆炸。这是就需要考虑到特征选择、特征降维,常用的特征选择方法可以参考上一篇文章: Python特征选择
注:本文源码链接:Github。(公众号阅读原文可访问链接)
The text was updated successfully, but these errors were encountered:
No branches or pull requests
业内常说数据决定了模型效果上限,而机器学习算法是通过数据特征做出预测的,好的特征可以显著地提升模型效果。这意味着通过特征生成(即从数据设计加工出模型可用特征),是特征工程相当关键的一步。本文从特征生成作用、特征生成的方法(人工设计、自动化特征生成)展开阐述并附上代码。
1 特征生成的作用
特征生成是特征提取中的重要一步,作用在于:
2 数据情况分析
本文示例的数据集是客户的资金变动情况,如下数据字典:
这里安利一个超实用Python库,可以一键数据分析(数据概况、缺失、相关性、异常值等等),方便结合数据分析报告做特征生成。
3 特征生成的方法
特征生成方法可以分为两类:聚合方式、转换方式。
3.1 聚合方式
聚合方式是指对存在一对多的字段,将其对应多条记录分组聚合后统计平均值、计数、最大值等数据特征。
如以上述数据集,同一cust_no对应多条记录,通过对cust_no(客户编号)做分组聚合,统计C1字段个数、唯一数、平均值、中位数、标准差、总和、最大、最小值,最终得到按每个cust_no统计的C1平均值、最大值等特征。
此外还可以pandas自定义聚合函数生成特征,比如加工聚合元素的平方和:
3.2 转换方式
转换方式是指对字段间做加减乘除等运算生成数据特征的过程,对不同字段类型有不同转换方式。
3.2.1 数值类型
多个字段做运算生成新的特征,这通常需要结合业务层面的理解以及数据分布的情况,以生成较优的特征集。
直接用聚合函数统计多列的方差、均值等
按特征值对全体样本进行排序,以排序序号作为特征值。这种特征对异常点不敏感,也不容易导致特征值冲突。
3.2.2 字符类型
截取
当字符类型的值过多,通常可对字符类型变量做截取,以减少模型过拟合。如具体的家庭住址,可以截取字符串到城市级的粒度。
字符长度
统计字符串长度。如转账场景中,转账留言的字数某些程度可以刻画这笔转账的类型。
频次
通过统计字符出现频次。如欺诈场景中地址出现次数越多,越有可能是团伙欺诈。
3.2.3 日期类型
常用的有计算日期间隔、周几、几点等等。
4 自动化特征生成
传统的特征工程方法通过人工构建特征,这是一个繁琐、耗时且容易出错的过程。自动化特征工程是通过Fearturetools等工具,从一组相关数据表中自动生成有用的特征的过程。对比人工生成特征会更为高效,可重复性更高,能够更快地构建模型。
4.1 FeatureTools上手
Featuretools是一个用于执行自动化特征工程的开源库,它有基本的3个概念:
1)Feature Primitives(特征基元):生成特征的常用方法,分为聚合(agg_primitives)、转换(trans_primitives)的方式。可通过如下代码列出featuretools的特征加工方法及简介。
2)Entity(实体) 可以被看作类似Pandas DataFrame, 多个实体的集合称为Entityset。实体间可以根据关联键添加关联关系Relationship。
3)dfs(深度特征合成) : 是从多个数据集创建新特征的过程,可以通过设置搜索的最大深度(max_depth)来控制所特征生成的复杂性
4.2 FeatureTools问题点
4.2.1 内存溢出问题
Fearturetools是通过工程层面暴力生成所有特征的过程,当数据量大的时候,容易造成内存溢出。解决这个问题除了升级服务器内存,减少njobs,还有一个常用的是通过只选择重要的特征进行暴力衍生特征。
4.2.2 特征维度爆炸
当原始特征数量多,或max_depth、特征基元的种类设定较大,Fearturetools生成的特征数量巨大,容易维度爆炸。这是就需要考虑到特征选择、特征降维,常用的特征选择方法可以参考上一篇文章: Python特征选择
注:本文源码链接:Github。(公众号阅读原文可访问链接)
The text was updated successfully, but these errors were encountered: