Trying to read a 14GB table fails without reading any rows. It seems to time out after 5 minutes while waiting for query results #8890
Comments
0.5.x) or sync (0.4.13) data0.5.x) or sync (0.4.13) data
0.5.x) or sync (0.4.13) data|
The |
|
@DoNotPanicUA @davinchia @evantahler I think this is a perfect use case for a perf test that should be run periodically to catch regressions. I think the right approach here would be to:
I am open to suggestions though and if you think we should have a quick call to lay out the solution - lets do that |
|
@grishick P.S. we have plans to handle dataset management by the E2E tool in the roadmap, but there is a lot of stuff that needs to be done before :) |
|
@grishick Approach sounds sane to me. Some thoughts:
Sounds like we should wait for the E2E testing tool to be ready as per @DoNotPanicUA's comment to leverage that work. |
|
@DoNotPanicUA that's great. @davinchia I agree that Slack is better. Yes, I think we should let the GL team make the E2E tool into a docker container, create a GH action, figure out how to spin up a external resources, such as a source or a destination database instance, figure out how to load test datasets and then we can have repeatable runs for data sets of various sizes and complexities. |
|
Great! Very excited! @supertopher @git-phu @cpdeethree are around for any infra/tooling requests! |
|
@DoNotPanicUA @grishick, I think I'll open a sub tickets for a part which is related to the testing tool. Regarding the issue itself I'm on it. Found that if I use local Mysql DB with a table size 16GB the sync passed successfully. So the issue happen only with Amazon RDS instance. My assumption is that something to do with RDS configs. Investigating it... |
Makes sense. There is also networking and RDS-special configs involved. |
|
Some new inputs from my side. I was able to pass sync with RDS MySql and S3 by changing PreparedStatement fetch size:
I have some idea to check Local sync with resources similar to Airbyte Cloud. In case if it is the resource issue then we can solve this issue by increasing connectors resource |
|
@tuliren @suhomud my understanding is that fetch size is set dynamically based on the estimation of an average row size. So, what I wonder is"
|
|
@grishick Is it right value for prod env? Do we have a separate memory quota for Mysql? The local sync failed. It looks like fetch size has been ignored and select query trying to fetch all in memory.
|
|
@grishick @tuliren , MySQL JDBC driver does not respect fetch size ⛔️ This part is ignored by mysql driver: Increasing Mysql connector memory does not solve the issue ⛔️ Destination S3 connector is fail with OutOfMemoryError ⛔️ I changed fetch size to fetch_size_Integer.MIN_VALUE_500MB.txt Working sync ✅🥇 fetch_size_Integer.MIN_VALUE_700MB.txt My proposal will be:
Please let me know you thoughts/ideas 🤔 |
|
Please note that |
@DoNotPanicUA I'm not sure about previous metrics The one which I found is this. |
|
If we stop using caching somewhere, it will work less efficiently. The question is how dramatic it will be. |
I run it first without any connectors limitation so it was docker limitation in my case 8 GB for each connectors. Also the DB was local which CPU much better then on RDS. I noticed that when I use default fetch size (10) it stress CPU much because of |
Benchmark
Database: Local MySql DB instance Note: This approach does not load DB CPU and disk memory
Database: MySql RDS instance
Summary
I think we should definitely go with |





|
@suhomud, thank you for such a stunning report 👍 |
|
These are interesting findings. Most of the time Airbyte will not be colocated with the database and it is never colocated in case of Airbyte Cloud, so the defaults should optimize for remote DB. I would like understand more about the failure in the 4th scenario (remote DB and FetchSize = 10).
cc @davinchia @evantahler @bleonard tagging you here, because you expressed interest in the project |
Before the sync:After the sync:CPU:
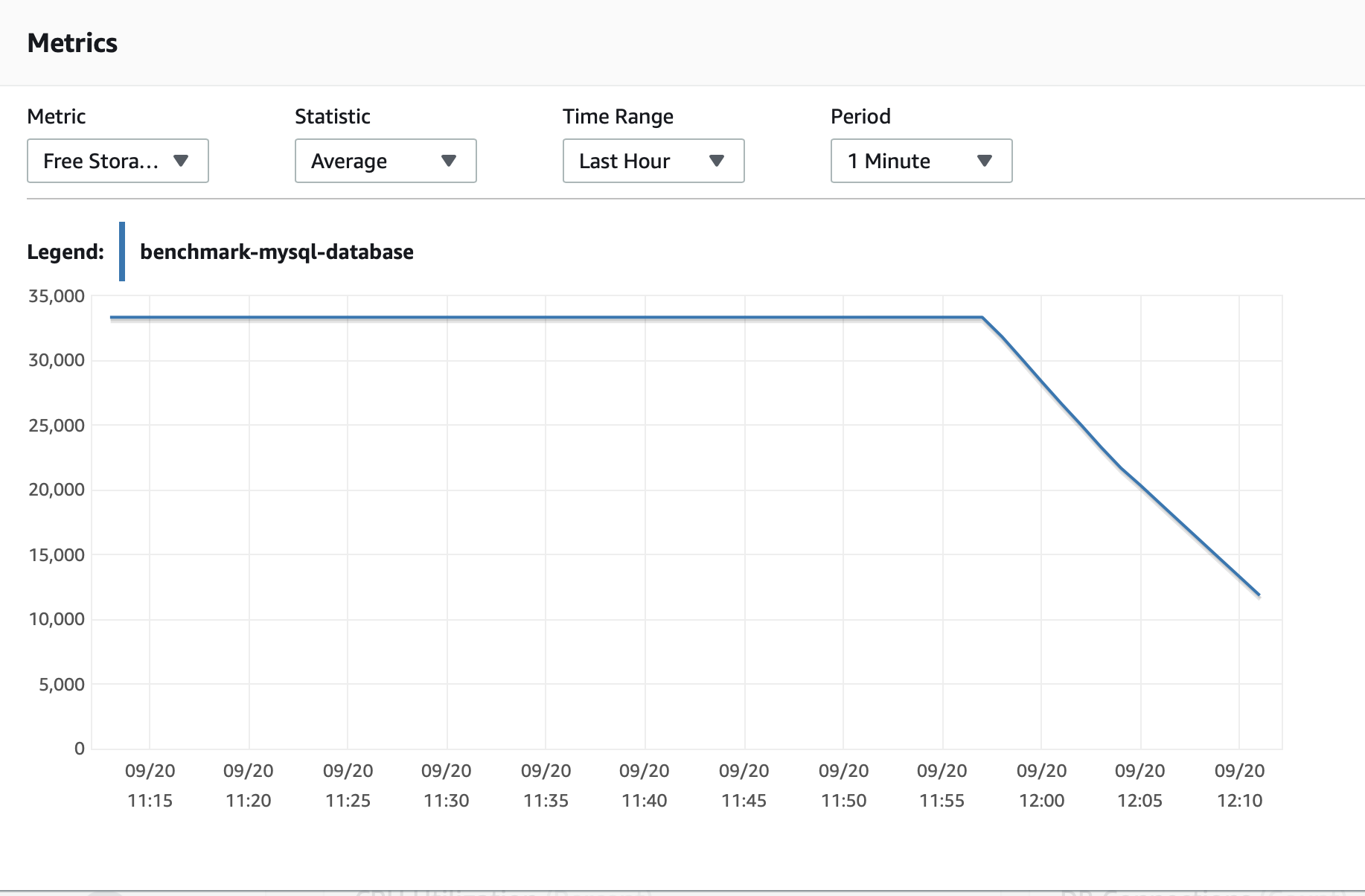
And RDS Instance is: Do you have an idea what else can be changed for RDS? |






|
Update. I was able to start sync successfully with fetch size 10 by increasing RDS instance Memory HD from |
|
So it seems like extra disc memory solved issue particularly. The sync is still in progress. For 5 hours it fetch 2 GB only. |
|
@suhomud nevermind my question - I see you have already answered it previously with a quote from MySQL docs |
|
Looking at the test results above, I am leaning towards agreeing with the conclusion that we have to set fetch size to |
|
@grishick I made a Draft PR with required change #17236 |
|
Hi @grishick, the PR is ready for review. |
Environment
Problems
There are two issues:
0.5.x, the connection check fails:0.4.13, the connection check passes. However, when the database is relatively large, data sync fails before any row is read.Expected Behavior
Tell us what should happen.
Logs
Slack thread.
The text was updated successfully, but these errors were encountered: