other chapters that should have been read before or content you should be familiar with before you read this
| Prerequisite | Importance | Notes |
|---|---|---|
| Reproducible Environments | Useful | Any notes |
easy to understand summary - a bit like tl;dr
This chapter presents the best practices for reproducible machine learning. It will include examples of workflows with test data as well as tips and tricks for machine learning pipelines and Python modules to help with reproducibility.
- Introduction to Machine Learning
- Popular Resources
- Retrieving and versioning input data
- Tracking input parameters
- Pipeline diagnostics, visualisation and deployment
Arthur Samuel (1959):
"[Machine learning is the] field of study that gives computers the ability to learn without being explicitly programmed."
Tom Mitchell (1997):
"A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E."
Performance depends on the representation of the given data. Data is represented to a learning algorithm as "features". Traditional approaches to machine learning involved "feature engineering", where a researcher with domain expertise would develop techniques to extract informative features from the raw data.
Examples of features can include:
- Computer Vision: Edges, number of pixels in a certain colour
- Natural Language Processing: Number of a particular token
- ...
- Supervised: Learn to predict output from a given input (labelled training data).
- Unsupervised: Discover internal representation of input data.
- Reinforcement: Learn actions that maximise a reward function.
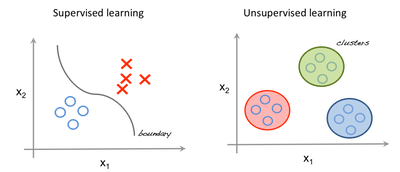
Supervised machine learning algorithms use a set of labeled data in order to learn how features can be used to predict class labels. Once the algorithm has been trained and validated, it can be applied to new unlabeled sources in order to classify them.
Un-supervised machine learning algorithms have no prior knowledge of class labels. They try to separate the data into classes based on having similar features.
Here we point out some popular go to places for machine learning algorithms and libraries. We make no attempt to explain how to use them, but simply point towards documentation.
Listed below is a small selection of software libraries that can be used for machine learning. They contain implementations of many useful algorithms, allowing the researcher to leveage powerful tools for data science whilst still focusing on experimentation and building on the existing state of the art.
As mentioned in Pete Warden's blog post, Machine Learning is going through a reproducibilty crisis at the moment; but why does this matter?
I’ve had several friends contact me about their struggles reproducing published models as baselines for their own papers. If they can’t get the same accuracy that the original authors did, how can they tell if their new approach is an improvement?
If one is unable to reproduce the state of the art results, one can not be sure that these results are in fact the state of the start! Furthermore, as more models are developed that rely on other models, reproducitbily at all levels is key for transparecy and trust.
At present, it is impractical to binderise or use Jupyter notebooks for complete reproduceability of Machine Learning pipelines, and so researchers need additional workflows specific to the data analysis and machine learning. In the remainder of this chapter these workflows are describes along with best practises for maintaining a reproducible machine learning pipeline.
This section will cover the problems associated with retrieving data from remote repositories
Having a reproducible way to gather a data set forms the basis for obtaining a consistent result. Whilst providing the data alongside the scripts allows a user to obtain the same result, it does not guarantee the data is reproduceible, and thus casts doubt over the consistency of the result. Therefore, the best way to ensure reproducibility is to document exactly how you obtained your data and what those data contain.
In practise, the data in a remote repository can change over time. Furthermore, the same data could be available from various locations (some which you may not be aware of), but with subtle differences between them. So in practise it is often advantageous to provide a copy of the data packaged with the scripts and workflow used to collate it.
In many machine learning scenarios the data sets are extremely large and cannot be practically packaged or containerised with the scripts. This makes it especially important to document the retrieval of data, and provide a detailed recipe (in the form of scripts) to follow to obtain the exact data set that was used to obtain a result.
Documenting any pre-processing steps applied to your data is essential. Data retrieved from web services can have some level of user-requested processing applied to it on their side prior to a user downloading it. Documenting this can easily be overlooked since it is not an intrinsic part of the scripts on your system, but is an important part of ensuring a data set is reproducible.
Once you have data on your own system, you will most likely want to apply your own pre-processing steps such as cleaning or filtering of the data. These steps are usually only run once, and a good practise is to have these steps outlined in a script that is separate to subsequent analysis scripts.
Some guidelines for retrieving data from a remote repository:
- If possible, use the 'config_file' approach for generating REST API requests (i.e. version the requests you make to the server in the same way that you would with parameters in your model)
- When webscraping data, store as much information about the scraped dataset as possible.
The python standard library includes the logging module that implements a flexible event logging system. It can easily be set to log different levels of information (debug, info, warnings, errors, critical) with flexible formats. Because the log is managed by a standard library module, your application log can include own messages integrated with messages from third-party modules.
Basic usage to generate a file log, from official docs:
import logging
logging.basicConfig(filename='example.log', level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')We can restrict which messages are logged by changing the level parameter. For example we can set the level=log.INFO to skip the debug messages.
We will see now a more complete example to setup a log where we change the log format and the time zone. The log will be streamed to the console and to mylog.log file. Additionally, errors will also be logged into a separate file errors.log. Entries to the log can be managed using the instance logger. In this case mode='a' means to append to any previous existing log file.
import time
import logging
def get_logger(
LOG_FORMAT = '%(asctime)s | %(levelname)s | %(message)s',
DATE_FORMAT = '%Y-%m-%d %H:%M:%S',
LOG_NAME = 'logger',
LOG_FILE_INFO = 'mylog.log',
LOG_FILE_ERROR = 'errors.log'):
logger = logging.getLogger(LOG_NAME)
log_formatter = logging.Formatter(fmt=LOG_FORMAT, datefmt=DATE_FORMAT)
logging.Formatter.converter = time.gmtime
# comment this to suppress console output
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(log_formatter)
logger.addHandler(stream_handler)
# File mylog.log with all information
file_handler_info = logging.FileHandler(LOG_FILE_INFO, mode='a')
file_handler_info.setFormatter(log_formatter)
file_handler_info.setLevel(logging.INFO)
logger.addHandler(file_handler_info)
# File errors.log containing only warnings or worse
file_handler_error = logging.FileHandler(LOG_FILE_ERROR, mode='a')
file_handler_error.setFormatter(log_formatter)
file_handler_error.setLevel(logging.ERROR)
logger.addHandler(file_handler_error)
logger.setLevel(logging.INFO)
return logger
logger = get_logger() # Set up your logger
# Now you can send informative messages to the log
logger.info('Starting pipeline')
example_parameter = 33
logger.info('Running something using parameter value {0}'.format(example_parameter))
logger.warning('This does not look right')
#...
if 2 > 3:
logger.critical('There is a problem')
logger.critical('I will stop execution now')
#...
logger.info('My program ends here')And this is the output sent to the console and mylog.log file:
2019-05-17 15:10:35 | INFO | Starting pipeline
2019-05-17 15:10:35 | INFO | Running something using parameter value 33
2019-05-17 15:10:35 | WARNING | This does not look right
2019-05-17 15:10:35 | INFO | My program ends here
In summary, logging is an easy tool to keep track of everything that happens during execution, including which parameters were used and storing some relevant outputs, file locations, etc. It can also be used to yield informative context if an error happens.
Machine learning algorithms require a number of input parameters, model hyperparameters, that need to be optimized to solve a particular problem. Those parameters will depend on your specific problem, data set, implementation and objectives, so it is a good idea to work with code flexible enough to work with a range of possible parameters that can be passed to the algorithm without needing to modify the actual code. A particular code will produce different results depending on which parameters are used, which can be provided by an external file, also known as configuration file.
It is a good practice to separate your stable and immutable code from all those parameters that are susceptible to change.
It is often the case that several iterations are needed to find the optimal set of parameters, so it is important to keep track of which values are used at different stages and which ones were used to produce the current output of a particular execution of the code.
Generally you want your input parameters to be stored in a human-readable file that is also easy to modify and update. There are different types of general-purpose serialization format that can be useful to store parameters.
- JSON.
- XML
- YAML
- TOML
- Scripting language
- Plain text decoded manually
TODO: Maybe add some description, like this from wikipedia (https://en.wikipedia.org/wiki/Serialization): JSON. Plain-text file commonly used for client-server communication in web applications. Good human readability and easy to decode to be used in your program.
Some discussion on pros and cons on the different formats can be found here
Some of this formats accept nested structures. Different programming languages will have modules to read and decode configuration files into easy-to-use structures like dictionaries in python.
Example yaml file (config_file.yml):
function1:
parameter1: 10.0
parameter2: 20.0
parameter3: 30.0
useoption: True
function2:
name1: example
parameter2: 1.0
parameter3: 2.0
useoption: False
How to read the file in Python:
import yaml
with open('./config_file.yml', 'r') as stream:
try:
inputs = yaml.safe_load(stream)
except yaml.YAMLError as exc:
print(exc)That will generate a python dictionary with the same key:value structure of the yaml file. It accepts different variable types like strings, floats, lists, dictionaries, booleans, etc.
[sklearn.pipeline etc]
(sklearn.pipeline) TODO:
- pipeline code example (particularly showing how to retrieve all parameter values)
Running complex, parallel and computationally-intensive pipelines is a necessary part of data science, however these can be slow to run and difficult to debug when they go wrong. Whilst we all strive for good code design, your pipeline will probably involve some level of error handling that may affect the validity of the output. It is therefore good practice to record as much output as possible from the functions that are called in the pipeline. This may include:
- error messages that are explicitly handled by your code
- warnings that are generated by functions within the pipeline.
If your code breaks in the future, having a record of the warnings associated with that attempt could save a lot of time during debugging. A Python approach for recording and writing to file the different types of error, warning is described here.
TODO:
- code example of how to log warnings and errors
Your pipeline may output diagnostic plots. These are to help you and your close collaborators make operational decisions about your pipeline and are for internal use only. Often the code and parameters for generating these kinds of plot are hard-coded into your pipeline and you aren't likely to change these very much.
Figures are the plots that you make for your next high impact publication or to show your clients. These should be generated separately from your core pipeline and appropriately annotated with metadata if they are for public release (see the next section). In order to generate these figures, it is important to plan these in advance and make sure you output the right data from your pipeline.
Making your data FAIR is well documented in this chapter. Whilst you are desigining your pipeline, consider how you will generate the metadata for your published datasets.
TODO:
- Give an example of how to convert a logfile to metadata
TODO:
- Describe how to tag dockerfiles with metadata
this can be done at the end or maybe as a separate checklist exercise, but please do note things down here as you go
recommended next chapters that are a good next step up
top 3/5 resources to read on this topic (if they weren't licensed so we could include them above already) at the top, maybe in their own box/in bold. less relevant/favourite resources in case someone wants to dig into this in detail
Link to the glossary here or copy in key concepts/definitions that readers should be aware of to get the most out of this chapter
Credit/urls for any materials that form part of the chapter's text.