[docs]ASoC 2020 中期总结(自适应流控) #1641
Labels
ASoC2020
Issue or PR related to Alibaba Summer of Code 2020
Comments
This was referenced Aug 17, 2020
|
May I ask these codes in which branch, thanks. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
阿里巴巴编程之夏中期总结
本issue旨在向社区成员汇报进展、讨论完善设计方案,欢迎各位指正。
自适应流控
在服务数量多,拓扑复杂,处理能力逐渐变化的情况下,使用固定的最大并发会带来巨大的测试工作量,并且用户需要手动地设置很多流控规则。自适应限流就是为了解决这个问题。我们希望使用Q-Learning算法,引入智能的自适应流控策略进行限流,在最大化吞吐量的同时保障系统服务的稳定。相关issue可见#748
进展与成果
总体进展
创建了QLearningSlot,在里面实现了Q-Learning算法,能够根据CPU密集型和慢调用这两种使用场景使用不同的状态指标,批量处理请求,实现了Q-table的更新和存储,并且能在多种流量场景下进行训练更新。初步搭建了Deep Q-Learning模型的框架。
算法思路
模型中的智能体 (Agent)根据当前所处的状态(State),随机地执行一种动作(Action),从而获得对应的奖励(Reward)。通过试错学习,对当前系统状态和流量情况,能够学习最优的决策。模型的学习成果是一个Q-table,它记录了每种状态下, 执行不同的动作得到的Q值 Q(s,a),Q值反映了奖励的期望值。当Qtable构建完成后,模型执行当前状态下最大Q值所对应的动作。
State
根据CPU密集型和慢调用两种使用场景使用不同的状态变量。对于CPU密集型,CPU使用率较高,需要根据变化的CPU使用率进行动态的限流,因此考虑CPU usage,total QPS,RT,线程数作为状态的指标。对于慢调用的场景,即便在接近性能极限时,CPU usage仍然相对较低,因此主要考虑total QPS,RT,线程数这三个指标。
RT是反应系统状态的重要指标,理论上,当服务处于低负载时,RT通常较低并且保持稳定,当逐渐达到高负载时,RT会逐渐增加。
Action
Action有两种,block和accept,代表对下一批请求采取的流控决策。
Reward
若效用增加,则给予奖励(+10),否则给予惩罚(-1)。根据自适应流控的优化目标,将效用定义为
目的是最大化success QPS,最小化RT。计算效用在处理请求前后的增量,并设置一个容错值,给予对应的奖励。

Q-Table使用线程安全的
ConcurrentHashMap。key为state,value为两种action对应的Q值,是长度为2的double数组。每次训练前载入Q-Table,训练更新后使用txt文件进行存储。 这里有待优化。更新Q值:
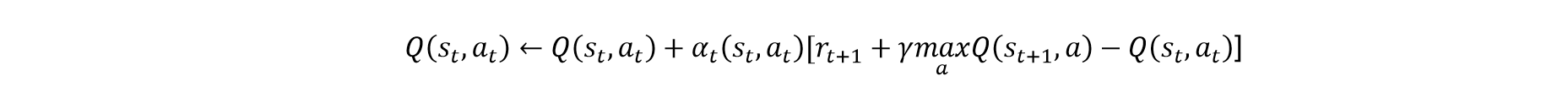

算法实现(伪代码)
训练Demo
训练过程

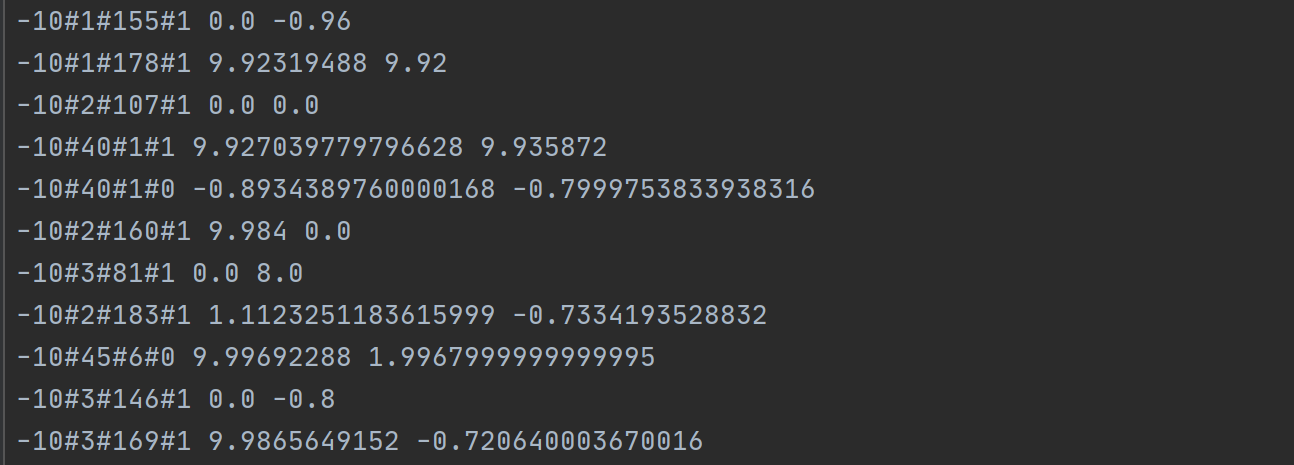
Q-table(部分):
问题与解决方法
State的维度爆炸问题
理论上来讲,我们可以把4种状态变量的组合划分为成千上万种状态。状态空间势必会很大。在这种维度爆炸的情况下,模型难以收敛,需要存储的Qtable数据量太大,训练成本太高,并且影响模型的使用效率。
首先,为了缓解这个问题,可以区分CPU密集型和慢调用的场景,由于慢调用场景下不用考虑CPU Usage,可以减少state变量的数量。
其次,理论上,可以将四种state变量组合为成千上万种状态,这就需要进行连续数值的离散化,为了缓解维度爆炸,使用较大的划分区间。CPU Usage取小数点后一位,QPS每100划分一次状态,threadNum每50划分一次,RT每5ms划分一次。
最后,为了节省训练成本,在训练过程中,实时地生成state,这样也可以避免由于大部分状态未经训练,使得Q-Table过大且多数为0,从而浪费存储空间的情况。
后续使用deep Q-learning算法无需离散化state数值,通过function approximation解决该问题。
批量执行决策
为了提升决策速度,采用批量处理请求的方法,设置10个请求为一组,但是这样可能会出现一些问题。由于在一定时间内请求的数目是不确定的,若一批请求的持续时间很长,状态已经发生了较大的变化,则无法保证批量处理的时效性,此时需要判断状态的变更,并且改变对应的最佳决策。
每次为下一批请求作出决策的时候开启一个计时器,在下一次决策之前,设置一个允许的最大时间间隔。如果在指定的时间间隔内一批请求未被处理完,可能意味着状态已经改变,我们将根据当前的状态重新选择决策;反之,如果在指定的时间内能够执行完决策,可能意味着请求比较密集,这时决策的时效性较高。
下一步计划
The text was updated successfully, but these errors were encountered: