A practical example of batch processing 50 * 100 Amazon reviews .csv chunks using the Go SDK for Apache Beam. 🔥
Be aware that the Go SDK is still in the experimental phase and may not be fully safe for production.
The data sample was retrieved from Kaggle and chunked into several .csv files.
The pipeline applies a set of transformation steps over 5000 amazon's reviews and builds and extract useful stats such as the top most helpful reviews, an overview of the rating, the recommendation ratio etc.
1/ Make sure you have properly installed Go and have added it to your $PATH.
go version2/ Install the project dependencies
go get -u -v3/ Run the pipeline locally (use the Direct Runner, reserved for testing/debugging)
go run main.go4/ (Optional) Deploy to Google Cloud Dataflow runner (requires a worker harness container image)
Open
deploy_job_to_dataflow.shfile and replace placeholders by your GCP project ID, your Cloud Storage bucket name and your worker harness container image (if you don't have one: see below).
chmod -X ./deploy_job_to_dataflow.sh
./deploy_job_to_dataflow.sh4 bis/ (Optional) Run the pipeline on a local Spark cluster
# cd to the beam source folder
cd ~/<GO_PATH>/github.com/apache/beam/
# build a docker image for the Go SDK
./gradlew :sdks:go:container:docker
# Run the spark job-server
./gradlew :runners:spark:job-server:runShadow
# When the server is running, execute the pipeline :
./run_with_apache_spark.shYou can monitor the running job via the Web Interface : http://[driverHostname]:4040.
This is the Docker image that Dataflow will use to host the binary that was uploaded to the staging location on GCS.
1/ Go to the apache-beam source folder
cd go/src/github.com/apache/beam2/ Run Gradle with the Docker target for Go
./gradlew -p sdks/go/container docker3/ Tag your image and push it to the repository
Bintray
docker tag <your_image> <your_repo>.bintray.io/beam/go:latest
docker push <your_repo>.bintray.io/beam/go:latestCloud Registry
docker tag <your_image> gcr.io/<your_project_id>/beam/go:latest
docker push gcr.io/<your_project_id>/beam/go:latest4/ Update the ./deploy_job_to_dataflow.sh file with the new Docker image and run it
./deploy_job_to_dataflow.sh
Click here to view a detailed guide.
Beam is a unified programming model that allow you to write data processing pipelines that can be run in a batch or a streaming mode on different runners such as Cloud Dataflow, Apache Spark, Apache Flink, Storm, Samza etc.
This is a great alternative to the Lambda Architecture as you have to write and maintain one single code (may slightly differ) to work with bounded or unbounded dataset.
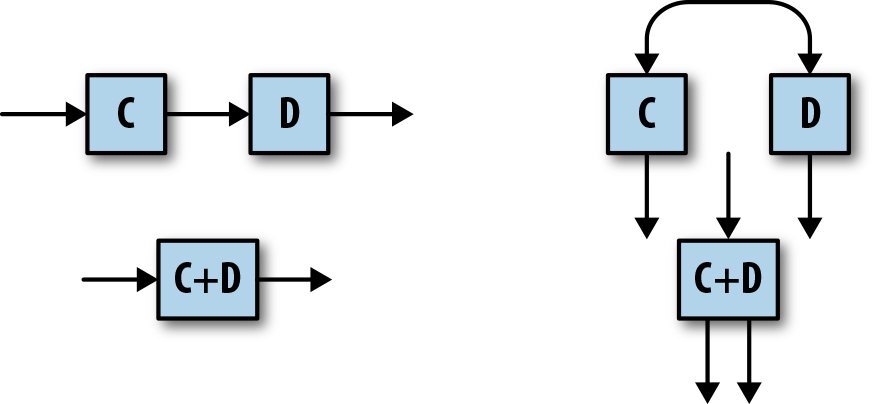
You have to define a Pipeline which is a function that contains several transformation steps. Each step is called a PTransform. A PTransform is a function that takes a PCollection as a main input (and eventually side input PCollections), then compute data and outputs 0, 1 or multiple PCollections. A PTransform can also be a composite transform which is a combination of multiple transformation steps. That's useful to write high level transformation steps and to structure your code to improve resuability and readability.
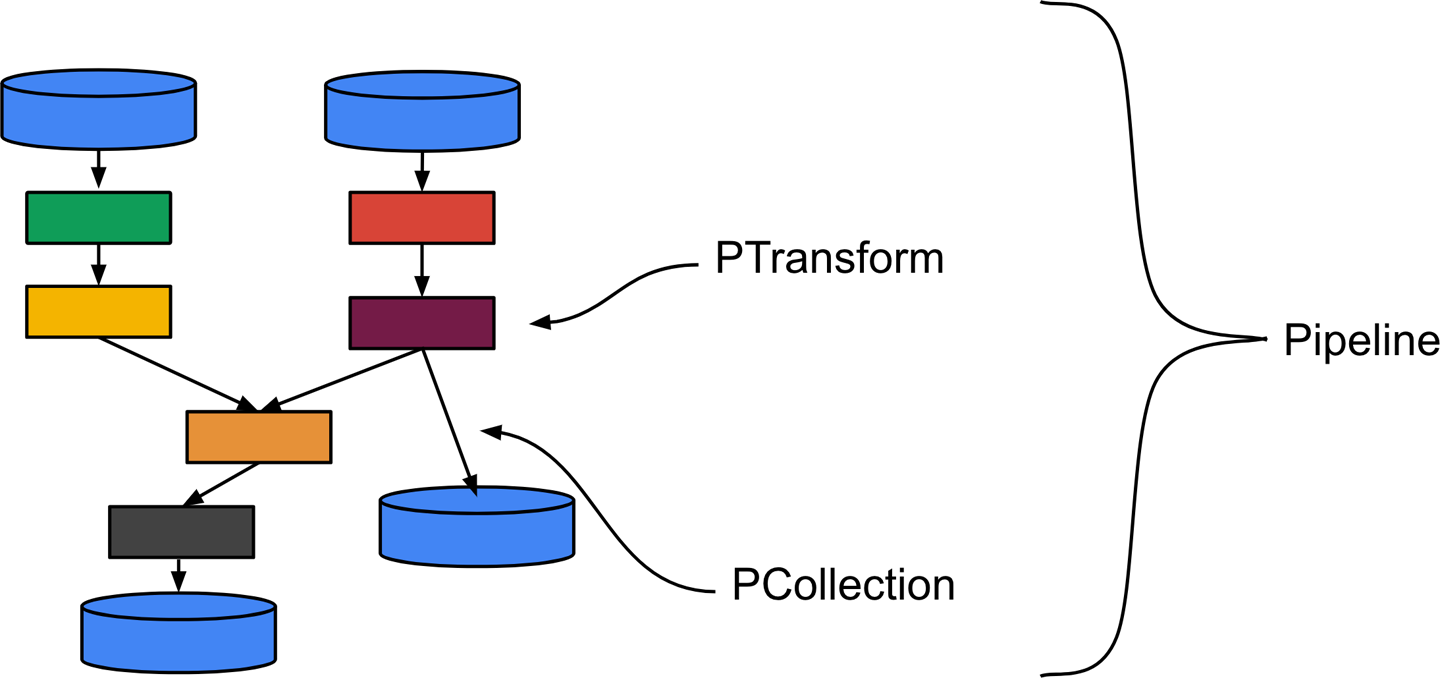
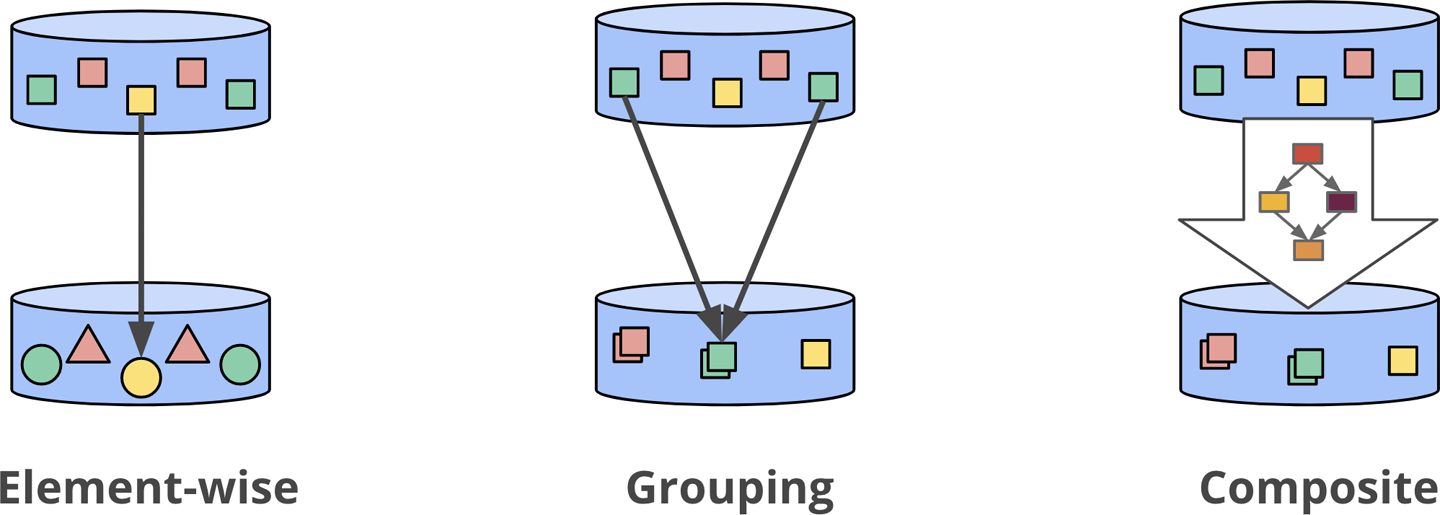
The SDK provides built-in element-wise/count/aggregate primitive transformations such as ParDo, Combine, Count, GroupByKey which can be composite transforms under the hood. Beam hides that to make it easier for developers.
A PCollection is like a box that will contain all the data that will pass through your pipeline. It's immutable (cannot be modified) and can be big, massive or unbounded. The nature of a PCollection depends on which source has created it. Most of the time, a fixed size PCollection is created by a text file or a database table and an infinite size PCollection is created by a streaming source such as Cloud Pub/Sub or Apache Kafka.
When you deploy the pipeline to a runner, it will generate an optimised Directed Acyclic Graph (or DAG) which is basically a combination of nodes and edges (nodes are going to be PCollections, edges gonna be PTransforms).
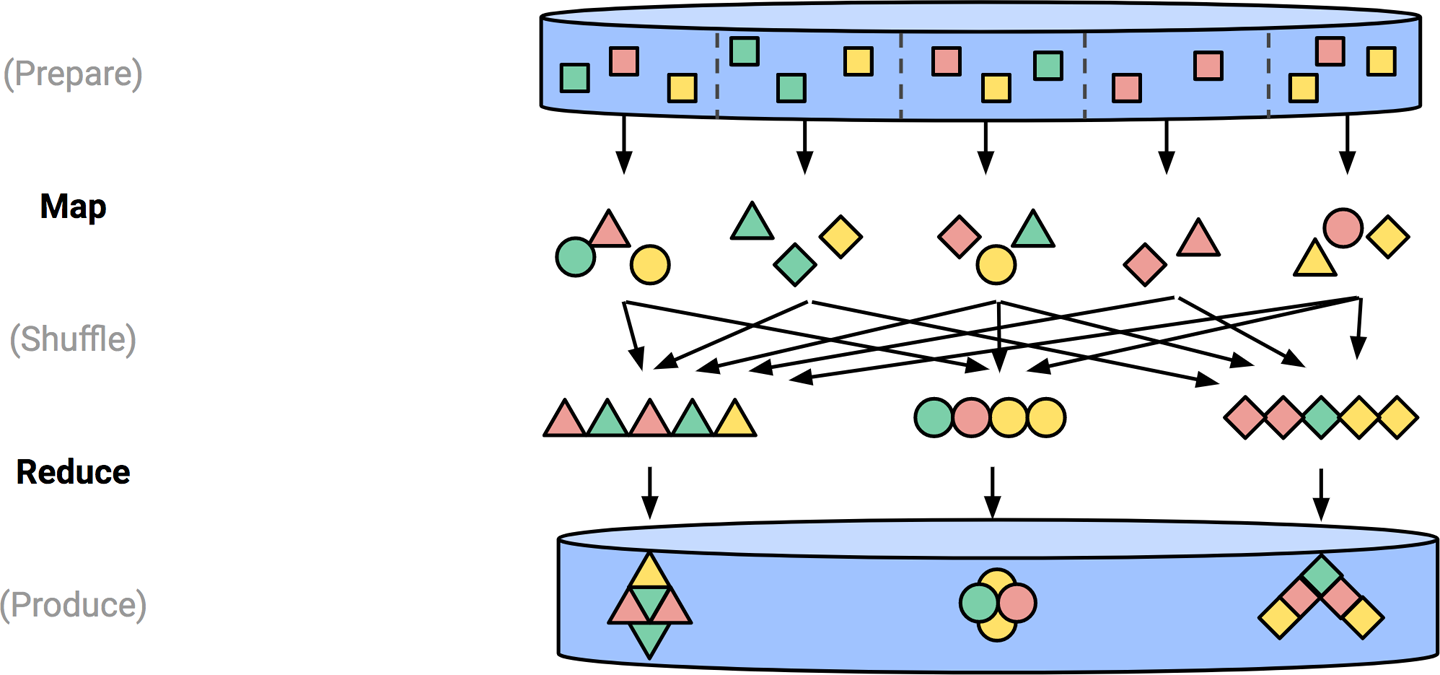
The targeted runner will next set up a cluster of workers and execute some of the transformation steps in parallel in a Map-Shuffle-Reduce style's algorithm.
Learn more about Apache Beam here.
The Go SDK is still experimental and doesnt provides features that makes streaming mode possible, such as advanced windowing strategies, watermarks, triggers and all of the tools to handle late data.
Images credits: Streaming Systems