HA for Management Server - roundrobin: Certificate ownership #2930
Comments
|
@DennisKonrad are you also able to reproduce this for 4.11? |
|
@DennisKonrad can you also describe your setup, is it kvm/xenserver/vmware etc? |
|
@DennisKonrad did you deploy multiple management servers concurrently? Ideally you should wait for the first management server to fully start before starting secondary management server. From the screenshot tthe certificate was generated without IPs of the mgmt server, therefore the certificate validation logic failed the SSL connection (as the certificate's alt name/ip should match the connecting agent/mgmt server's address). For example the following is a valid mgmt server cert that has ipv4/v6 address in its alt name: I could not reproduce this with 4.11 branch, so will move to milestone 4.12.0.0/master. Please re-test and keep us posted, thanks. |
|
@rhtyd The setup is kvm. Anything more you want to know? It is possible that we deployed our management servers at the same time. I will try to give the first management server the time to start before starting the secondary one. I will try this and report the results. A question: When are those certificates generated? Is it sufficient to restart the management server to newly generate the certificates? |
|
@DennisKonrad thanks. When a new management server starts, it first upgrades the DB and then various managers/components start. During this start stage, first the For an existing env, to force re-kick of cert generation, shutdown all mgmt servers, then in the db and set these global settings in cloud.configurations table to null:
And start first mgmt server, let it complete initialization and start other mgmt servers. |
|
@rhtyd So can we do the cert re-kick safely even when we have already added multiple hosts? When we leave the CN at Can you also tell me which script is doing the issuing of the certificates? Then I would be able to check what it's doing. |
|
@DennisKonrad I've already replied to you how cert generation works, tl;dr - each mgmt server generates its own cert on startup based on keypair/ca-cert from the db, the alt names are obtained by mgmt server by reading ips on network interfaces. The certs of mgmt server are only used when they peer/cluster with other mgmt servers, if you re-generated core keypair/ca-cert then kvm hosts certs will need to be re-provisioned. Please go figure: https://github.com/apache/cloudstack/blob/master/plugins/ca/root-ca/src/main/java/org/apache/cloudstack/ca/provider/RootCAProvider.java#L409 |
|
Given this is a setup /env issue, if the advise process fixes your issue and you're unable to reproduce the errors please close this issue @DennisKonrad |
|
Hi @rhtyd, so I don't really get where this issue comes from. Some questions:
I did some research in our logfiles and do not fully understand why we have this problem. The following happens: Second management server starts, is detected and joins the high availability cluster: Static Loadbalancing is starting and assigning hosts to the second management server: After that the hosts try to connect to the second managementserver and fail??? Is this assertion right? |


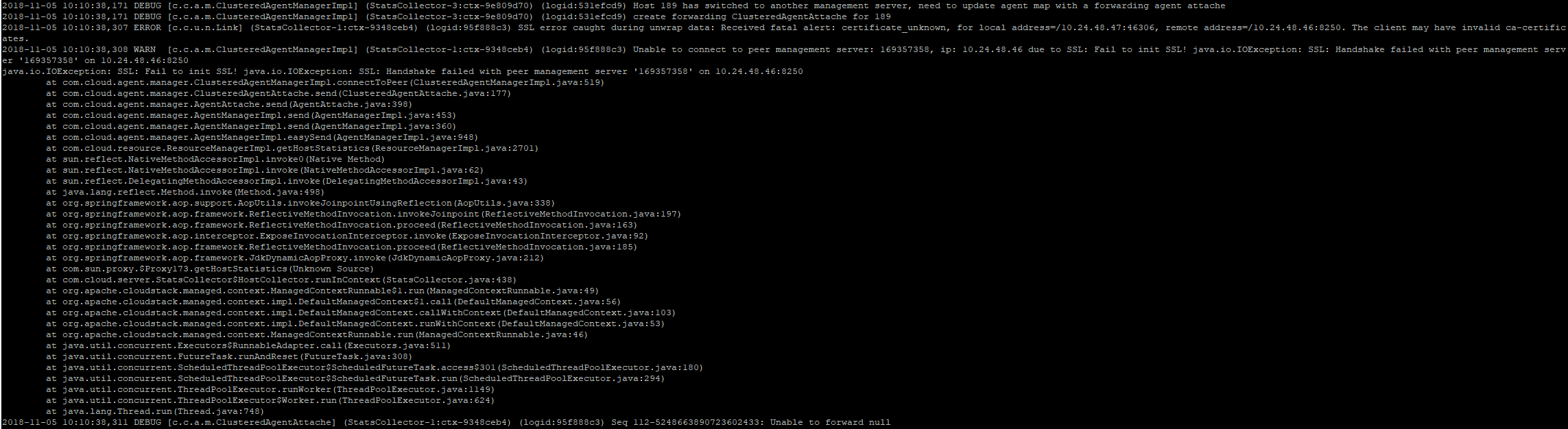
|
@DennisKonrad alright let me ask some questions:
|
I'm wondering how it is possible to introduce such a problem. In the beginning there can only exists one management server as you stated. It would start up with only it's IP in the global variable (hosts). After that the only way to add a second management is to change the variable and delete root private/public/certs global settings? If that is the case is that documented somewhere? |
|
@DennisKonrad can you at least stop all your mgmt servers and start one by one? It's possible that you had a conflict b/w root ca cert/priv/pub keys, you can temporarily disable auth strictness, then remove the global settings and use provisionCertificate API to re-provision certificate with a new keypair/cert. You're currently using a messed up (sounds like) unstable/master branch and we cannot help once you fix your env. Also, please re-read my comments I'm not going to restate the same things again and again. About IPs, mgmt server when it starts discovers the IPs it needs to use to create a self-signed cert, and NO you don't need to delete the certs/keypair every time you add a new mgmt server. I advised that because you may have a case where you started multiple mgmt server during time of install/setup at once which stepped on each other and wrote incorrect ca keypair/cert in db (i.e. conflict+concurrent issue). |
|
@rhtyd Starting one management up and later adding the second one did not work. So I tried the following with one of two management server running:
After that I could not use the "provisionCertificate" api call because all hosts were disconnected. Your help is very appreciated and rephrasing (or restating how you call it) helps to figure out what could be wrong here. A thorough investigation will also help others with similar problems. Thanks for that |
|
@DennisKonrad can you check in the logs if your kvm hosts are trying connect at all? You can try to delete the old keystore file at /etc/cloudstack/agent/cloud.jks and restart agent, then try the provision API. |
|
Hi @rhtyd, I have three question left before I can try this on our cluster. To get the hosts to try to connect (your last question) it works to delete/move the cloud.jks. It's not even needed to restart the agent as far as I could tell. After that it worked to reprovision the kvm-host with the "provisionCertificate" api call. When creating new CA/private/public I can now reprovision the hosts. I would also like to leave the systemvm's in place. I'm aiming for a process that leaves everything except the management-server running without any interruption. My process looks as following: Downtime: backup and NULL the following db keys: backup and delete per Host & SystemVM: /etc/cloudstack/agent/cloud.jks start first mgmt-server and wait for completion |
|
|
Hi @DennisKonrad I'm closing the issue as it could not reproduced. If you're able to consistently reproduce the error, please re-open the ticket with details and steps. Thanks. |
|
@rhtyd Yes. |
ISSUE TYPE
COMPONENT NAME
Management Server HA
CLOUDSTACK VERSION
master
CONFIGURATION
indirect.agent.lb.algorithm = roundrobin
host = 10.24.48.46,10.24.48.47
SUMMARY
When trying to use the CS Management in roundrobin loadbalanced mode we get errors creating a
VPC for example.
If we use
indirect.agent.lb.algorithm = staticit works like a charm for both managementservers.The log states it has something todo with the certificates issued:
It's not really clear what the error message itself is trying to say or how I can debug this further.
STEPS TO REPRODUCE
as stated above
EXPECTED RESULTS
ACTUAL RESULTS
The text was updated successfully, but these errors were encountered: