[Proposal] Support Bucket Shuffle Join for Doris #4394
Labels
Comments
HappenLee
added a commit
to HappenLee/incubator-doris
that referenced
this issue
Sep 27, 2020
HappenLee
added a commit
to HappenLee/incubator-doris
that referenced
this issue
Sep 27, 2020
morningman
pushed a commit
that referenced
this issue
Oct 11, 2020
Support Bucket Shuffle Join issue:#4394
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Motivation
At present, Doris support 3 type join: shuffle join, broadcast join, colocate join.
Except colocate join,another join will lead to a lot of network consumption.
For example, there a SQL A join B, the cost of network.
3BA + B.These network consumption not only leads to slow query, but also leads to extra memory consumption during join.
Each Doris table have disrtribute info, if the join expr hit the distribute info, we should use the distribute info to reduce the network consumption.
What is bucket shuffle join
just like Hive's bucket map join, the picture show how it work. if there a SQL A join B, and the join expr hit the distribute info of A. Bucket shuffle join only need distribute table B, sent the data to proper table A part. So the network cost is always
B.So compared with the original join, obviously bucket shuffle join lead to less network cost:
It can bring us the following benefits:
First, Bucket Shuffle Join reduce the network cost and lead to a better performance for some join. Especially when the bucket is cropped.
It does not strongly rely on the mechanism of collocate, so it is transparent to users. There is no mandatory requirement for data distribution, which will not lead to data skew.
It can provide more query optimization space for join reorder.
How Bucket Shffle Join For Doris
The key idea and challenge
1. Now the data distribute in left table when data load into doris
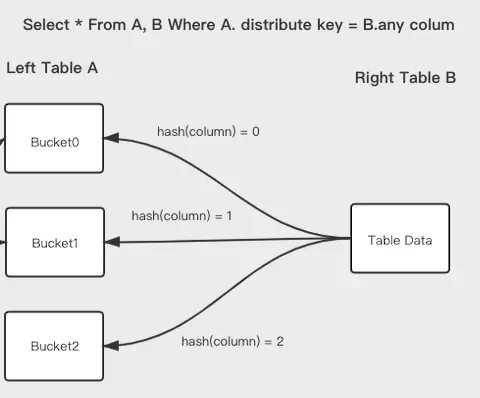
Firstly, we get the hash value by distributed column of left table, and mod by bucket num. like the pic below:

Secondy, we data distributed column of left table, send the data distribute of left table to right table。Right table do the same hash way to distribute data, so we only send one copy right table data when we do join compute.
2 Bucket Shuffle Join query plan
For the Bucket Shuffle Join, we change the DataStreamSend Partition way to
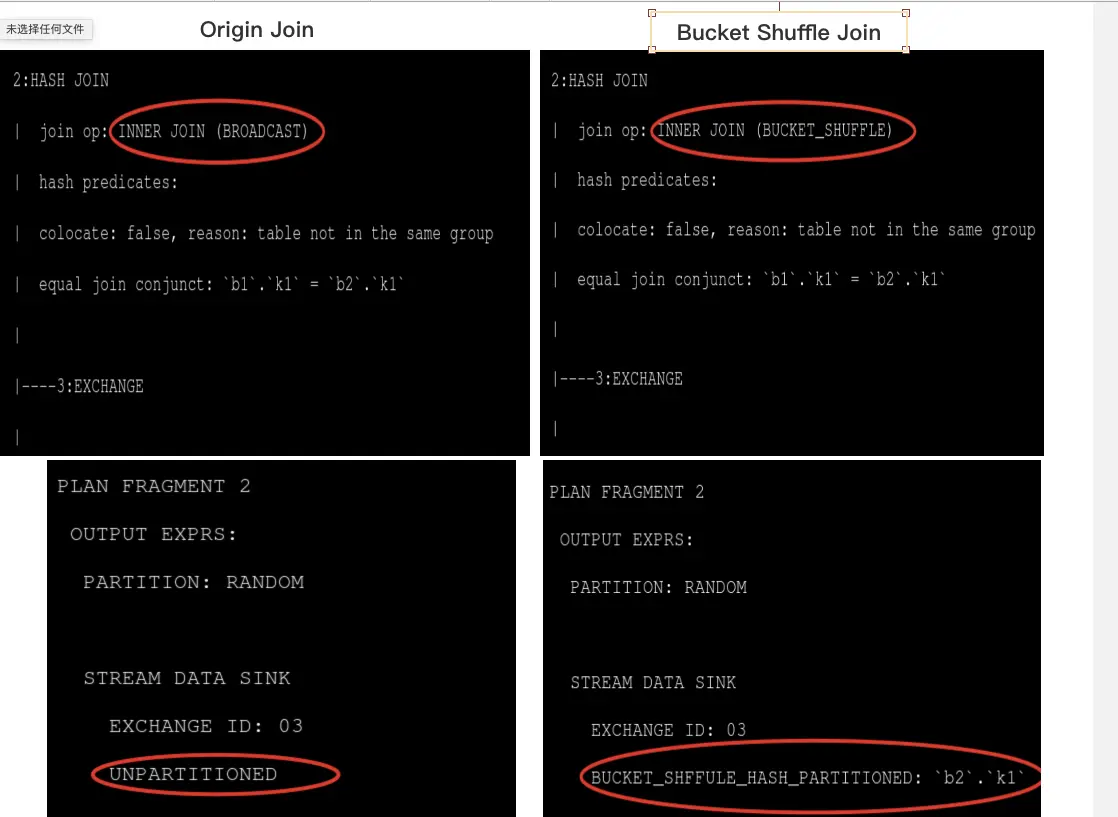
BUCKET_SHFFULE_HASH_PARTITIONED, the right table will distribute data by distribution of left table.3 Bucket Shuffle Join query schedule
The schedule goal: the DataStreamSender Should know of the bucket that left table distribute and send the proper data to the proper instance.
The schedule strategy: the left table ScanNode chose which bucket seqs it should own and need to keep each Instance of ScanNode have same count of bucket seqs. The FE Send how bucket seqs distribute in BE to that DataStream Sender know how to send data.
FragmentId4 How to decide a query can be Bucket Shuffle Join
5 Others
Add a session variable
enable_bucket_shuffle_join, the default value istrue.The limit for curren bucket shuffle join
Origin Join VS Bucket Shuffle Join
Test Data:
TPC-DS 1TB Data
Cluser Info:
10 BEs, each BE is Physical Machine and has 48CPU, 96GMEM.
Test Result of TPC-DS
If pic do not show time which means query failed since mem limit exceed.
The text was updated successfully, but these errors were encountered: