Router management Proxy routing should have a way to route to any node in the cluster #8686
Comments
|
This sounds like an open proxy and therefore I am scared of it. In the context of the Druid Doctor I think it would be better to put the checks into the Router itself, and have it contact other nodes on the caller's behalf if necessary, rather than run an open proxy. But even then, the issue implies you are thinking about contacting all servers in a cluster as part of a health check. For large clusters this has potential scalability problems. It might be better for the servers to all self-check themselves, and report the results of the self-check to a central location. Maybe they can report a hash of the important properties, and if the hashes differ we know there is a proxy. |
Of course this has scalability problems too 🙂 I thought it might be worth considering, though, because I am worried that since the Doctor is user-driven, it could cause stampedes of broadcast blasts to all servers in the cluster if too many users use it at once. |
|
The proxy could only forward to Druid nodes themselves so it is not open to everything. Also there is already an open proxy in the sampler (http firehose). I tried to implement it that way and it works for non TLS clusters, (for TLS clusters we would need to address: #8668 From a security perspective my model is that if you have admin access to the management proxy enabled router you can pretty much do anything anyway at that point. From a scalability perspective I do not think it is a problem if this is a user initiated action (with a warning in the UI). Also remember that it would be OK for this to be slow, taking a 100ms pause between every request. People would be fine with it as long as there is visual feedback with a ticking |
I think it's different, because the http firehose at least can't be used unless you are an authenticated user and have write access to some datasource. (Not ideal but there is at least something that protects it.) The proxy route IIRC would be open to anyone anywhere. I believe it relies on the target server to do authentication. Limiting it to just Druid servers could lower the scariness levels enough.
I think with the pause, the scalability issue is less scary, so that sounds good. Or, we could also limit it to a certain number of servers. Probably if someone has, like, 100 servers, then they have figured out how to set their properties properly by then. |
|
Yeah just to be clear I never pictured it to be a proxy to an arbitrary destination only to other Druid servers. If there was some server uuid we could use that instead of a host port combo but right now from the sys table the best server id I can see is host:port
The issue with having this check be encapsulated by a single backend API is that it might give someone the idea to hit it as part of a routine health monitoring which limits how heavy these tests might should be. I am very much picturing a 'deep' test suite (that can take its sweet time) and might be intensive on the cluster. Something you run a handful of times in the clusters lifetime (in leu of posting to the user-group). Something to catch issues like: https://groups.google.com/forum/#!topic/druid-user/w3Uy-dXZSII |
|
Something like that could be implemented by making the request async: when
a check request is sent, servers return immediately with "Started". If
tests are already running, and more requests come in, we continue to return
"started". Then the healthcheck result is cached for a few minutes or
whatever the right time is, during which the servers return the last
healthcheck result.
…On Wed, Oct 16, 2019 at 7:25 PM Vadim Ogievetsky ***@***.***> wrote:
Yeah just to be clear I never pictured it to be a proxy to an arbitrary
destination only to other Druid servers. If there was some server uuid we
could use that instead of a host port combo but right now from the sys
table the best server id I can see is host:port
[image: image]
<https://user-images.githubusercontent.com/177816/66972578-dba7d900-f049-11e9-9424-8d5514db4ffd.png>
The issue with having this check be encapsulated by a single backend API
is that it might give someone the idea to hit it as part of a routine
health monitoring which limits how heavy these tests might should be. I am
very much picturing a 'deep' test suite (that can take its sweet time) and
might be intensive on the cluster. Something you run a handful of times in
the clusters lifetime (in leu of posting to the user-group). Something to
catch issues like:
https://groups.google.com/forum/#!topic/druid-user/w3Uy-dXZSII
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#8686>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAPSYCR3L5NPD55LK3DQ3QLQO7EK5ANCNFSM4JBQKNMQ>
.
--
Jad Naous
Imply | VP R&D
650-521-3425
jad.naous@imply.io
|
to achieve above you would have to check if "node-host,port" received in request is indeed a druid process which requires that particular process successfully registered itself in zookeeper and discovered by router. so the two requirements above depend on each other. I would agree with @jnaous on the async philosophy in general for this kind of use case. #8672 (comment) applies too :) OTOH I think you want the proxy because it is doable quickly and would give you a lot of freedom as to try things in web console, gather feed back, iterate more and when we know the concrete useful use cases, they could be implemented in router for efficiency (and/or proactive checkups ) . If intention is to allow quick experimentation really then I think it is ok to setup the proxy mechanism at router but with a configuration that enables such proxy and set to |
|
This issue has been marked as stale due to 280 days of inactivity. It will be closed in 4 weeks if no further activity occurs. If this issue is still relevant, please simply write any comment. Even if closed, you can still revive the issue at any time or discuss it on the dev@druid.apache.org list. Thank you for your contributions. |
|
This issue has been closed due to lack of activity. If you think that is incorrect, or the issue requires additional review, you can revive the issue at any time. |
Description
It would be amazing if the router's management proxy could proxy to any node in the cluster
Right now the router can proxy to the overlord and coordinator leaders (see https://druid.apache.org/docs/latest/design/router.html#management-proxy-routing ) via:
/proxy/coordinator/*and/proxy/overlord/*I would like tp propose adding a route like:
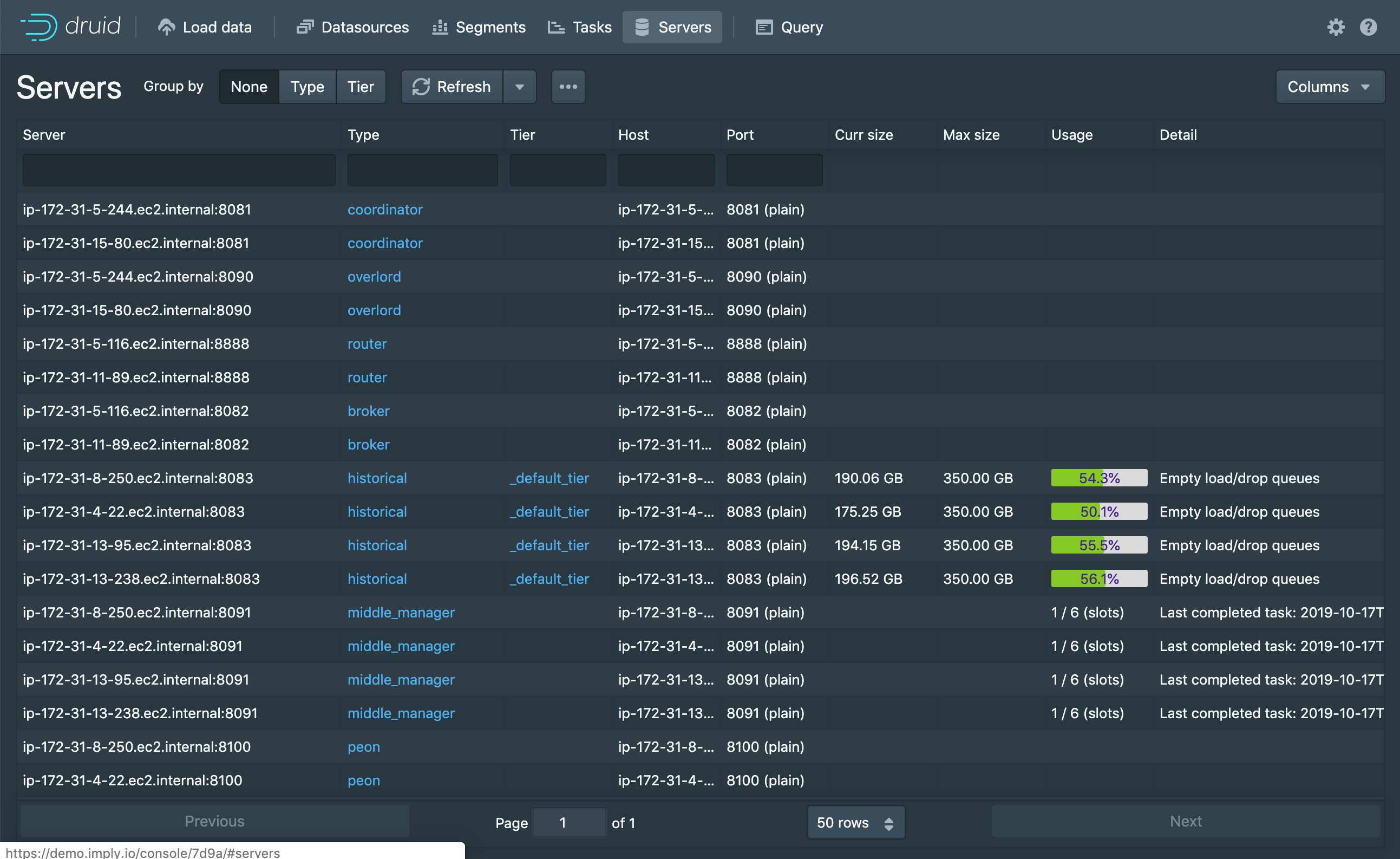
/proxy/node/<node-host>/<node-port>/*that would proxy*to the node at<node-host>:<node-port>where<node-host>and<node-port>would correspond to the host and port columns as reported by thesys.serverstable.Motivation
This would enable a host of cool status and diagnostic checks from the router web console. In particular it would turbo charge what can be done in the Druid Doctor ( #8672 ) allowing the creation of a check that would make sure all runtime props are set correctly and that all nodes are reachable.
The text was updated successfully, but these errors were encountered: