Performance tuning #800
Comments
|
That job pretty much just writes out parquet (or versions parquet files if you have updates). From what I see single tasks are gc-ing for hours when though the input is more or less 7M records or so. I have seen similar issue (not this bad though) caused on yarn due to interference from other jobs or yarn not blacklisting a bad host.. As a next step, can we try configuring a larger heap (say double it) or obtain a heapdump of such a process and we can see whats going on (i.e if there is a leak) |
|
@n3nash any ideas? |
|
Sure, I can try that. Also, this job is not releasing executors when the tasks were finished. e.g. I gave this job 100 executors. Two tasks are running for 20 hours and others finished in minutes. This job will keep 100 executors for 20 hours. Is that possible to improve this?
|
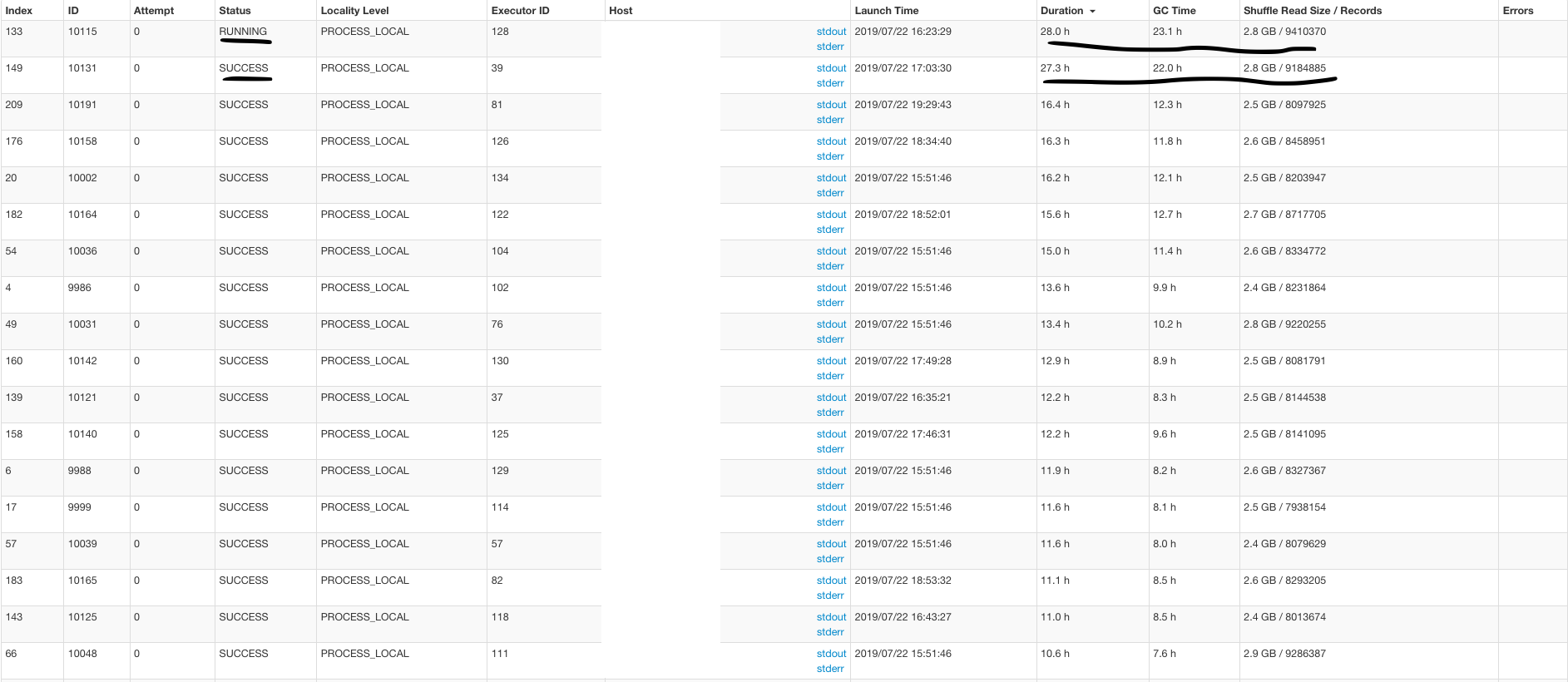
|
So, this seems more about the memory per executor rather than number of executors.. Not releasing the executors is very weird for a spark app to do tbh.. interesting.. You already have 12GB executor memory, which should be plenty .. All in all, its GC-ing constantly and if you let it run, as with any java app, it will keep GCing and chew up cpu .. Can you try to do a heapdump using |
|
Maybe this https://github.com/apache/incubator-hudi/blob/master/hoodie-common/src/main/java/com/uber/hoodie/common/util/SerializationUtils.java#L85 is too small? Seems like this is not related to Also could be https://github.com/apache/incubator-hudi/blob/master/hoodie-client/src/main/java/com/uber/hoodie/config/HoodieMemoryConfig.java#L119 is too small. |
|
Still think getting a heapdump is the best way, since that will tell us what’s actually held in memory. |
|
hi.. any updates? |
|
Hi, sorry been a little busy this week. I will write a summary once I get enough information. |
|
Few things I did to improve performance:
|
|
@garyli1019 thanks for the update! |
Hello, I am having a performance issue when I was upserting ~100GB data into a 700GB table already managed by Hudi in HDFS. The upsert part does have some duplicates with existing table because I am setting up a buffer to cover all the delta in case my spark job doesn't start on time.
spark config I used(external shuffle is true as default in my cluster):
Key Hudi Configs:
I am using Datasource Writer to append the delta data. I tried to use CMS garbage collector but it doesn't change too much. A 200MB parquet file has ~3-6 million records in my case. Do you have any idea how to make
count at HoodieSparkSqlWriterfaster?Thank you so much!
The text was updated successfully, but these errors were encountered: