[WIP][HUDI-686] Implement BloomIndexV2 that does not depend on memory caching #1469
Conversation
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Outdated
Show resolved
Hide resolved
Thanks for reviewing this pr, I'll ping you later when finished : ) |
|
Hi @vinothchandar base on your branch, there are mainly the following updates:
Bug fix Previous Changes |
|
Also, index performance has been greatly improved, your idea and design is amazing 👍 👍 👍 @vinothchandar I tested
Performance comparison
|
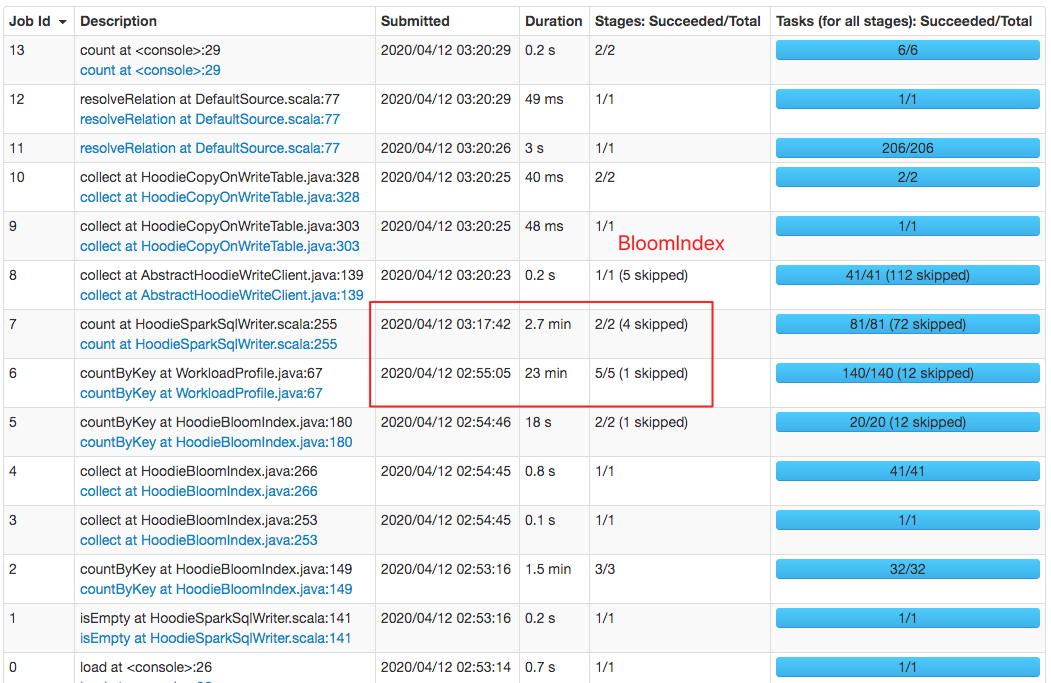
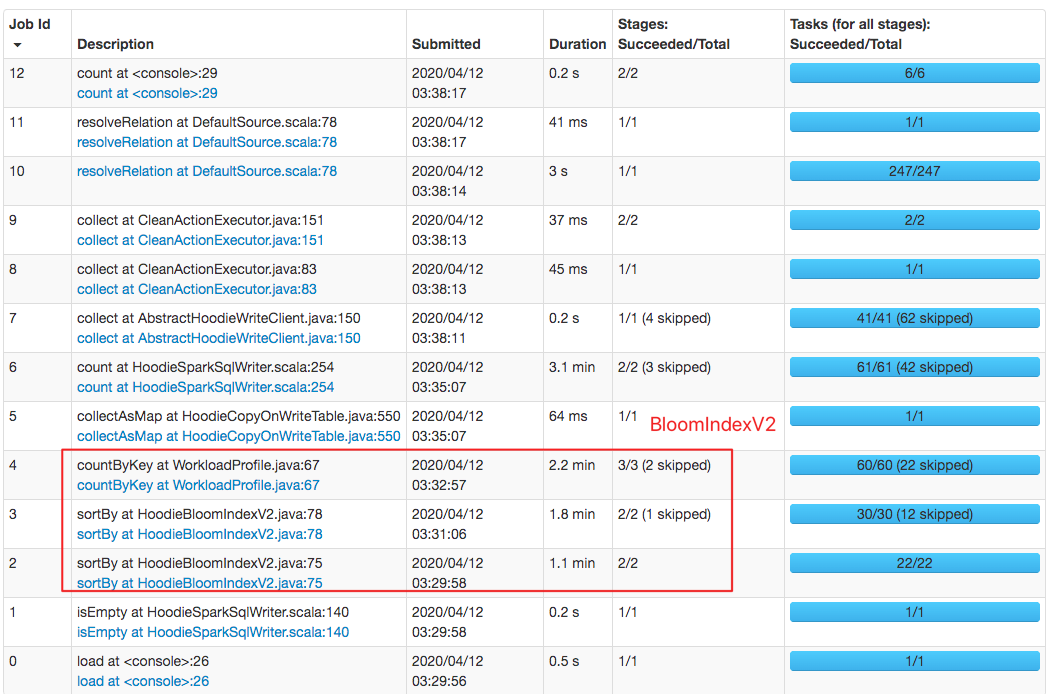
|
@lamber-ken thanks for the update.. from the UI, it seems like the difference was only in |
The above shows the spark job page, a job is a sequence of stages which triggered by an action such as .count(), collect(), read() and etc. |
|
understood :).. but I am saying the difference you see is outside the indexing piece.. Can you post the stages UI? |
|
Once taggedRecords are returned from index.tagLocation(), next step is to build the workload which actually triggers the execution of actual tagging. Hence the first job in workloadprofile is actually referring to index. Let me know if my understanding is wrong. |
Got, let me show you the spark stage page, amazing 👍. BTW, env: 4core, 6GB driver, local mode, don't forget
|
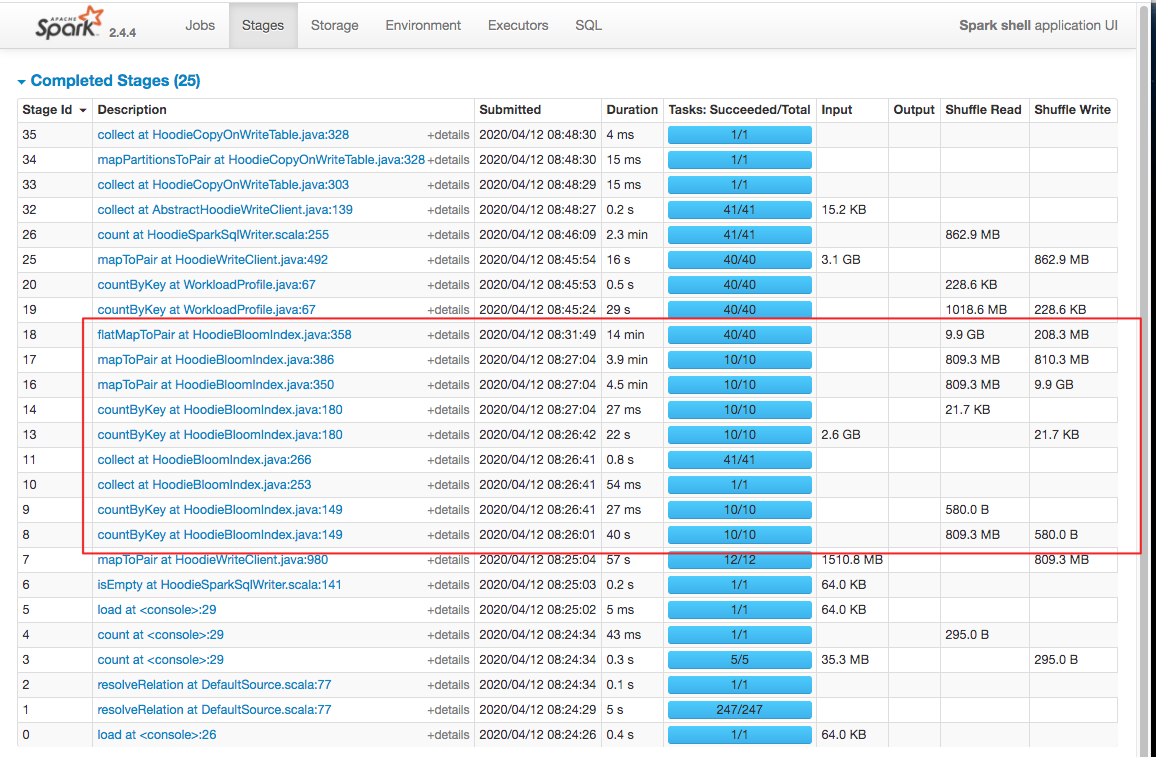
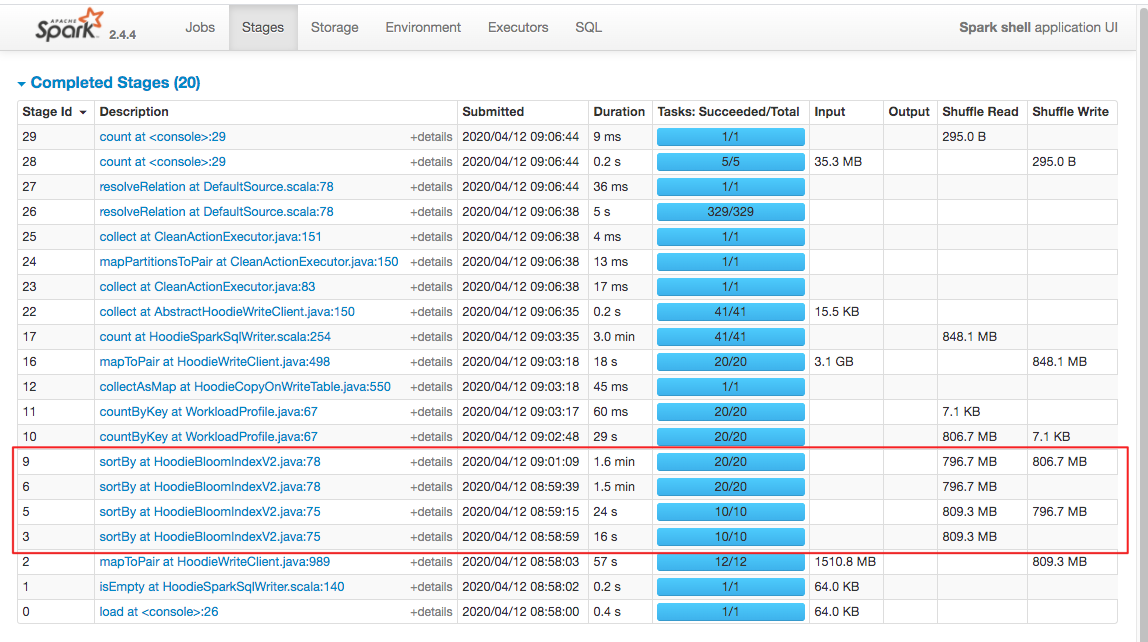
You're right. 💯 |
There was a problem hiding this comment.
Okay ... my bad.. misread .. So it seems like the main thing is that we shuffle 9GB with current bloom index.. on a workload where it explodes the input RDD such that each 5M records are checked against all files you have... Just curious how many files did your bulk_insert create..
@nsivabalan can review this and land.. :) I will make a final pass once he approves..
@lamber-ken given that all this is fresh in your mind, can you help review the SimpleIndex and once you approve that, I will do one place..
(We can scale better this way)...
hudi-common/src/main/java/org/apache/hudi/common/util/DeltaTimer.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Show resolved
Hide resolved
Actually, I did There are about
Sure, will review that pr, : ) |
hudi-client/src/main/java/org/apache/hudi/config/HoodieIndexConfig.java
Outdated
Show resolved
Hide resolved
| @@ -69,4 +76,13 @@ public long endTimer() { | |||
| } | |||
| return timeInfoDeque.pop().stop(); | |||
| } | |||
|
|
|||
| public long deltaTime() { | |||
There was a problem hiding this comment.
endTimer() already gives you a delta time right? why do we need this new method? We should consolidate this more.. right now, this feels like two timer classes within one..
There was a problem hiding this comment.
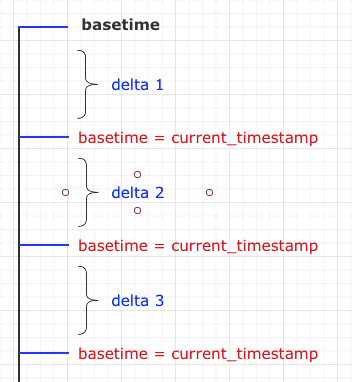
endTimer can only support 1 v 1, what we need here is delta characteristics.
if use endTimer, we must create many instances, only one instance is enough when we use delta.
There was a problem hiding this comment.
yeah, looks like HoodieTimer already gives you the delta. So, don't really understand why we need the changes.
T0: HoodieTimer timer = new HoodieTimer();
T1: timer.startTimer();
T4: timer.endTimer(); // T4 - T1
T4: timer.startTimer();
T6: timer.endTimer(); // T6 - T4
T8: timer.startTimer();
T9: timer.startTimer();
T12: timer.endTimer(); // T12 - T9
T15: timer.endTimer(); // T15 - t8
There was a problem hiding this comment.
hi @nsivabalan, as follown, we need call startTimer() and endTimer().
// HoodieTimer
T0: HoodieTimer timer = new HoodieTimer(); timer.startTimer();
T1: timer.endTimer(); timer.startTimer();
T2: timer.endTimer(); timer.startTimer();
T3: timer.endTimer(); timer.startTimer();
T4: timer.endTimer(); timer.startTimer();
// Delta
T0: HoodieTimer timer = new HoodieTimer();
T1: timer.deltaTime();
T2: timer.deltaTime();
T3: timer.deltaTime();
T4: timer.deltaTime();
There was a problem hiding this comment.
let's just reuse the timer class as is and move on? :) I'd actually encourage explicit start and end calls so its clear what is being measured? In any case, the current way of overloading HoodieTimer does not seem maintainable IMO
There was a problem hiding this comment.
hi @vinothchandar @nsivabalan, you're all think it's unnecessary, willing to take your suggestion. But from my side, it's better to use deltaTime(), will address it : )
| @Override | ||
| public JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(JavaRDD<HoodieKey> hoodieKeys, | ||
| JavaSparkContext jsc, HoodieTable<T> hoodieTable) { | ||
| throw new UnsupportedOperationException("Not yet implemented"); |
There was a problem hiding this comment.
we need to implement this as well?
| */ | ||
| @Override | ||
| public boolean isGlobal() { | ||
| return false; |
There was a problem hiding this comment.
Also a HoodieGlobalBloomIndexV2 ?
| @Override | ||
| protected void end() { | ||
| totalTimeMs = hoodieTimer.endTimer(); | ||
| String rangeCheckInfo = "LazyRangeBloomChecker: " |
There was a problem hiding this comment.
I added these for debugging purposes.. We need not really have these checked in per se?
There was a problem hiding this comment.
yep, please remove an debugging statements and any other metrics that was added for perf tuning.
There was a problem hiding this comment.
right, we need this. It'll help us to debug index performance issues if someone met in the future, and print only once per partition.
There was a problem hiding this comment.
metrics are not easy to use, each partition just only print one log, keep it as it is :)
| import org.apache.hudi.index.bloom.BloomIndexFileInfo; | ||
| import org.apache.hudi.table.HoodieTable; | ||
|
|
||
| public class HoodieBloomRangeInfoHandle<T extends HoodieRecordPayload> extends HoodieReadHandle<T> { |
There was a problem hiding this comment.
Let's add unit tests for these two handles?
There was a problem hiding this comment.
Done, TestHoodieBloomRangeInfoHandle
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Outdated
Show resolved
Hide resolved
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Outdated
Show resolved
Hide resolved
| @Override | ||
| protected void end() { | ||
| totalTimeMs = hoodieTimer.endTimer(); | ||
| String rangeCheckInfo = "LazyRangeBloomChecker: " |
There was a problem hiding this comment.
yep, please remove an debugging statements and any other metrics that was added for perf tuning.
hudi-client/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndexV2.java
Outdated
Show resolved
Hide resolved
| @@ -69,4 +76,13 @@ public long endTimer() { | |||
| } | |||
| return timeInfoDeque.pop().stop(); | |||
| } | |||
|
|
|||
| public long deltaTime() { | |||
There was a problem hiding this comment.
yeah, looks like HoodieTimer already gives you the delta. So, don't really understand why we need the changes.
T0: HoodieTimer timer = new HoodieTimer();
T1: timer.startTimer();
T4: timer.endTimer(); // T4 - T1
T4: timer.startTimer();
T6: timer.endTimer(); // T6 - T4
T8: timer.startTimer();
T9: timer.startTimer();
T12: timer.endTimer(); // T12 - T9
T15: timer.endTimer(); // T15 - t8
| import static org.junit.Assert.fail; | ||
|
|
||
| @RunWith(Parameterized.class) | ||
| public class TestHoodieBloomIndexV2 extends HoodieClientTestHarness { |
There was a problem hiding this comment.
once you have fixed fetchRecordLocation, do write tests for the same.
|
@lamber-ken we are hoping to get this into the next release as well . any etas on final review? :) |
|
@lamber-ken the fetchRecordLocation() API and global indexing is not implemented..Do you plan to work on them as well? |
|
@vinothchandar I think the work can be finished this week, will ping you when finished : )
|
@lamber-ken : Just to confirm we are in same page. We wanted a Global index version for HoodieBloomIndexV2. The global simple index you quoted is the global version for SimpleIndex. |
|
Codecov Report
@@ Coverage Diff @@
## master #1469 +/- ##
============================================
- Coverage 71.77% 71.58% -0.19%
Complexity 1087 1087
============================================
Files 385 389 +4
Lines 16575 16813 +238
Branches 1668 1685 +17
============================================
+ Hits 11896 12035 +139
- Misses 3951 4041 +90
- Partials 728 737 +9
Continue to review full report at Codecov.
|

|
Hi @vinothchandar @nsivabalan thanks for you review, all review comments are addressed. SYNC
Test |
| @@ -68,6 +68,13 @@ | |||
| public static final String BLOOM_INDEX_KEYS_PER_BUCKET_PROP = "hoodie.bloom.index.keys.per.bucket"; | |||
| public static final String DEFAULT_BLOOM_INDEX_KEYS_PER_BUCKET = "10000000"; | |||
|
|
|||
| public static final String BLOOM_INDEX_V2_PARALLELISM_PROP = "hoodie.bloom.index.v2.parallelism"; | |||
| public static final String DEFAULT_BLOOM_V2_INDEX_PARALLELISM = "80"; | |||
There was a problem hiding this comment.
may I know why 80 rather than 100 or some round number ?
| @@ -441,6 +441,14 @@ public boolean getBloomIndexUpdatePartitionPath() { | |||
| return Boolean.parseBoolean(props.getProperty(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH)); | |||
| } | |||
|
|
|||
| public int getBloomIndexV2Parallelism() { | |||
There was a problem hiding this comment.
guess we also need to add all these props as methods to HoodieIndexConfig (builder pattern)
| * optional is empty, then the key is not found. | ||
| */ | ||
| @Override | ||
| public JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(JavaRDD<HoodieKey> hoodieKeys, |
There was a problem hiding this comment.
not required in this patch. But I feel like we should have a class for PartitionPathandFileIdPair. Having it as Pair<String, String> sometimes is confusing or I had to trace back to see whether left is partitionpath or the right entry.
|
|
||
| /** | ||
| * Checks if the given [Keys] exists in the hoodie table and returns [Key, Option[partitionPath, fileID]] If the | ||
| * optional is empty, then the key is not found. |
There was a problem hiding this comment.
minor. Its Option.empty and not Optional.empty
| super(config); | ||
| } | ||
|
|
||
| @Override |
There was a problem hiding this comment.
jus curious why no java docs. You have added java docs for fetchRecordLocations though.
| .sortBy((record) -> String.format("%s-%s", record.getPartitionPath(), record.getRecordKey()), | ||
| true, config.getBloomIndexV2Parallelism()) | ||
| .mapPartitions((itr) -> new LazyRangeAndBloomChecker(itr, hoodieTable)).flatMap(List::iterator) | ||
| .sortBy(Pair::getRight, true, config.getBloomIndexV2Parallelism()) |
|
|
||
| // <Partition path, file name> | ||
| hoodieTimer.startTimer(); | ||
| Set<Pair<String, String>> matchingFiles = indexFileFilter |
There was a problem hiding this comment.
correct me if I am wrong. in global index, there are chances that incoming record key is updated to a different partition path compared to existing record. For example, existing record in hoodie could be <rec_key1, partitionPath1>, and incoming record could be <rec_key1, partitionPath2>. We have to find such locations as well in global.
if we call indexFileFilter only for the partitionpath and recordkey from incoming record, then we might miss this case.
There was a problem hiding this comment.
Guess, you missed the config.getBloomIndexUpdatePartitionPath(). Check what HoodieGlobalBloomIndex does for this config. if need be, I can explain too.
There was a problem hiding this comment.
bottom line, we need to consider all partitions, not just the ones where incoming records are tagged with.
| BloomFilter filter = fileIDToBloomFilter.get(partitionFileIdPair.getRight()); | ||
| if (filter.mightContain(record.getRecordKey())) { | ||
| totalMatches++; | ||
| candidates.add(Pair.of(updatePartition(record, partitionFileIdPair.getLeft()), partitionFileIdPair.getRight())); |
There was a problem hiding this comment.
sorry, this is confusing to me as to why we update the path. Once you fix my previous comment, I will take a look at this code block.
| return new HoodieRecord<>(hoodieKey, record.getData()); | ||
| } | ||
|
|
||
| private void populateFileIDs() { |
There was a problem hiding this comment.
is there any difference between regular bloom IndexV2 and global version for this method?
| } | ||
| } | ||
|
|
||
| private void populateRangeAndBloomFilters() { |
There was a problem hiding this comment.
is there any difference between regular bloom IndexV2 and global version for this method? If most of the code base is similar, why can't we create a separate file for LazyRangeAndBloomChecker and introduce a global version(by extending from the same) and override only those required.
|
Fixing conflicts, wait |
Codecov Report
@@ Coverage Diff @@
## master #1469 +/- ##
============================================
- Coverage 18.21% 17.93% -0.28%
Complexity 856 856
============================================
Files 348 352 +4
Lines 15332 15570 +238
Branches 1523 1540 +17
============================================
Hits 2792 2792
- Misses 12183 12419 +236
- Partials 357 359 +2
Continue to review full report at Codecov.
|

|
@lamber-ken : LMK once the patch is ready to be reviewed again. |
Big thanks for reviewing this pr very much. Sorry for the delay, I'm working on something else, when I'm ready, will ping you 👍 |
|
@lamber-ken @vinothchandar : I took a stab at the global bloom index V2. I don't have permissions to lamberken's repo and hence couldn't update his branch. Here is my branch and commit link. And here is the link to the GlobalBloomIndexV2. Please check it out. Have added and fixed tests for the same. Also, I have two questions/clarifications. If this is a feasible case, then the fix I could think of is. Similar fix needs to be done with global version as well. |
| .mapPartitions((itr) -> new LazyRangeAndBloomChecker(itr, hoodieTable)).flatMap(List::iterator) | ||
| .sortBy(Pair::getRight, true, config.getBloomIndexV2Parallelism()) | ||
| .mapPartitions((itr) -> new LazyKeyChecker(itr, hoodieTable)) | ||
| .filter(Option::isPresent) |
There was a problem hiding this comment.
@vinothchandar : guess there could a bug here. If for a record, few files were matched from range and bloom lookup, but in LazyKeyChecker none of the files had the record, current code may not have this record in the final JavaRDD<HoodieRecord> returned. But we have to return this record w/ empty cur location.
|
We are plannign to reimplement indexing as a new "HoodieMetadataIndex", now that the metadata table is there. Closing this. but I expect we would use/share some ideas from this PR there |
What is the purpose of the pull request
Main goals here is to provide a much simpler index, without advanced optimizations like auto tuned parallelism/skew handling but a better out-of-experience for small workloads.
Brief change log
This is an initial version, will update it step by step.
Verify this pull request
will improve test.
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.