init dummyIndex after restart cluster #3939
Conversation
There was a problem hiding this comment.
To solve these problems completely, I think raftLogManager needs a complete refactoring, including but not limited to better concurrency control, better persistence strategy, etc.
When I first joined the community in my senior year, the first thing I did was to implement raftLogManager with reference to storage and unstable interfaces in etcd. Because I didn't have a very deep understanding of raft and etcd at that time, after a long period, I finally realized that this was probably an awful implementation and I apologize for that. There are two main reasons:
- For
raft, uncommitted logs also need to be persisted (i.e., logs on disk may also need to be truncated) in order to ensure correctness after reboot. etcdis an event-driven architecture, so its interior is all unlocked. However, in our architecture,raftLogManagercan be accessed concurrently by multiple threads. So we've added a lot of patches for concurrency control right now, but this is actually an area we can think about implementing better.
Thank you very much for your great contributions. This week I will focus on the PR you raised about cluster- branch and a bug at hand. After that, I would like to discuss the refactoring of raftLogManager with you guys and community. And of course you're welcome to start to design the new raftLogManager with us right now if you are free.
...r/src/main/java/org/apache/iotdb/cluster/log/manage/serializable/SyncLogDequeSerializer.java
Outdated
Show resolved
Hide resolved
cluster/src/main/java/org/apache/iotdb/cluster/log/manage/RaftLogManager.java
Show resolved
Hide resolved
IMO,we need the following two approaches in parallel:
I'd be happy to do it together : ) |
OK, then that's my reviews~At current, it seems that the |
see #3930 |
cluster/src/main/java/org/apache/iotdb/cluster/log/manage/RaftLogManager.java
Show resolved
Hide resolved
| /** | ||
| * When raft log files flushed,meta would not be flushed synchronously.So data has flushed to disk | ||
| * is uncommitted for persistent LogManagerMeta(meta's info is stale).We need to recover these | ||
| * already persistent logs. | ||
| * | ||
| * <p>For example,commitIndex is 5 in persistent LogManagerMeta,But the log file has actually been | ||
| * flushed to 7,when we restart cluster,we need to recover 6 and 7. | ||
| * | ||
| * <p>Maybe,we can extract getAllEntriesAfterAppliedIndex and getAllEntriesAfterCommittedIndex | ||
| * into getAllEntriesByIndex,but now there are too many test cases using it. | ||
| */ |
There was a problem hiding this comment.
In this comment, it seems due to that the log's meta file does not flush synchronously with the raft log, however, the persistent commit raft log maybe has been applied.
We should not commit the entry again when restart.
There was a problem hiding this comment.
The problem here is that we don't know the actual applyIndex.
Fortunately, in IOTDB, repeating apply operation doesn't matter too much, but losing data can be unacceptable.
That is only my views.
There was a problem hiding this comment.
As we have so many plans, I am not sure all the plan is idempotent.
There was a problem hiding this comment.
According to my understanding, re-apply the same sequence(guaranteed by log index) of the plans won't break the correctness of IoTDB. And looks like we don't have a better choice.
Thanks for your implementation so that we can enjoy the first cluster version of IoTDB :). Raft algorithm is really hard to implementation, there are too many corner cases to consideration. We could make the algorithm work correct in most of cases in a short time which is terrific. In my opinion, we need to spend too much effort to guarantee the correctness of Raft if we want to keep working on the current cluster implementation. Cluster module lack a whole system design according to my feeling. Another my suggestion is we can gradually separate raft implementation and raft client(application) just like what |
Actually, I have the same idea as you, I think we can integrate |
Very glad to work together. As I will work on prometheus integration in the later of this month, I only have small bandwidth for this. But I'd like to propose some design sooner or later to discuss together after investigation. |
In fact, In the last few months I have studied Raft algorithm carefully and completed 6.824 lab. This is just an instructional Raft implementation, which makes me deeply appreciate how difficult it is to implement a correct consensus algorithm, while Raft algorithm at production level requires much more. So I think maybe it's time for us to weigh in and make a decision. Choosing a mature implementation of the raft algorithm liberates our productivity, which may take a long time at first, but can be hugely beneficial once implemented. But I also want to list two concerns:
Any discussions are welcomed~ |
As I see the raft is one consensus algorithm, which may do not have many relations with the linearizability, just put the post[1] for reference.
As far as I know, the apply function is user-defined, we can still implement a parallel apply function according to different storage groups in the one raft log. What is certain is that using a raft library will definitely limit our optimization work compared with the current implementation (mixing the raft framework and business logic), but I think the availability and correctness are far greater than the performance for now. |
Let's move Ratis related discussion to #3954 so that more people could join. |
This may not seem like a problem.I tried to calculate that it would handle 100 million requests per second and the cluster would run for 2924 years. Sorry, I closed this PR due to my misoperation. I have reopened it. |
...r/src/main/java/org/apache/iotdb/cluster/log/manage/serializable/SyncLogDequeSerializer.java
Outdated
Show resolved
Hide resolved
…alizable/SyncLogDequeSerializer.java
|
Any problems with this PR? if not, I think we can merge this PR. |
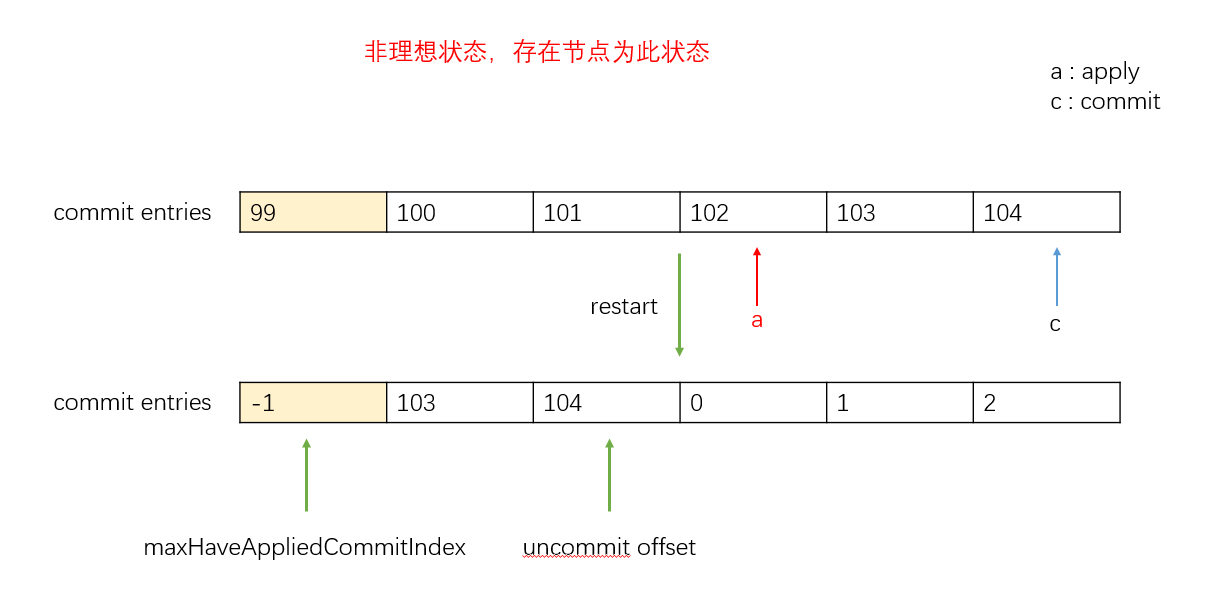
In current logic, if we restart cluster, and
applyIndexis smaller thancommitIndex,here are three problems occur.commitManager.Like 103 and 104 in the picture,they can not be appended tocommitEntriesincommitManager.unCommitEntriesinunCommitManager.This is all because
dummyIndexis initialized to the default value,it cannot return to its pre-reboot state.ps.The information in the picture assumes none of these questions exist
This PR try to resolve this problem,but we may also need a processor to avoid logIndex is too big, dunmmyIndex need to re-initialize if logIndex will be bigger than our expect.