Check padding size for global pooling #9730
Conversation
* Check padding size for global pooling * Check padding size for global pooing in cudnn impl * Check padding size for global pooling in pooling_v1 * add test case for global pooling * fix compiling issue in CI * Check padding size for global pooling in mkl2017 impl * Fix indent
* Check padding size for global pooling * Check padding size for global pooing in cudnn impl * Check padding size for global pooling in pooling_v1 * add test case for global pooling * fix compiling issue in CI * Check padding size for global pooling in mkl2017 impl * Fix indent
|
This makes no sense to me. If padding is specified why ignore it? It makes sense to have the default set to 0, but if padding is specified the expected result is to use that value, no? @TaoLv @piiswrong @Piyush3dB @andrewfayres |
|
Hi @jmerkow What's your expectation for global pooling when padding is specified? What's the kernel size and output size then? Do you know what's the behavior in other frameworks? At least I find in keras, there is no padding parameter in the API: https://keras.io/layers/pooling/. |
|
What was wrong with it before? The output size should be 1, the kernel size would be the spatial size of the input. Isn't the default padding 0 anyway? why force it to 0 if its set? I have thousands and thousands of models that depend on the layer being set up the way it was. This effectively breaks those and prevents me from upgrading. |
|
Not sure I understand. If padding has values given and it's not ignored, the output size will be > 1 if kernel size is the spatial size of the input, right? Otherwise, kernel size should be input spatial size + padding size. Padding was not checked in previous version. We took it as a mistake in MXNet and this PR fixed that (see discussion in #9714). If you think it's an important feature for you, would you mind submitting a feature request for it? Please also provide information about how it's defined and supported in other frameworks. |
|
The major issue is that it needlessly breaks backward compatibility. Why force it to zero? Perhaps a warning if padding is set to non-zero? |
|
Because padding size will be used in the pooling implementation. For example, see https://github.com/apache/incubator-mxnet/blob/master/src/operator/nn/pool.h#L162 If global pooling, we set kernel size to input spatial size, padding to zero, and stride to 1 and send them to the implementation function. |
|
It worked fine before, it was still sent to the pooling function: outputs:
It worked fine, used the same pool function here: |
|
Why do you think this result is correct? It looks to me your global pooling is applied in the way as following:
So the result of pooling is 16/25=0.64. But to me the correct result should be 25/25=1.0
|
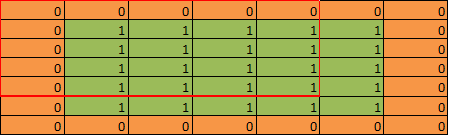
|
I’m not saying it’s correct or incorrect. I’m saying backwards compatibility is broken with no work around. What about adding a warning message instead of taking out the bug/feature out? |
|
Sorry, why we need be backward compatible for a bug? What's the bug you're facing now? Do you think the global pooling is generating wrong results after the fix? |
|
So these networks are trained. Anything following this layer is not going to work correctly for networks trained in previous versions. Any model with global pooling and padding is broken because all the layers after this one now are going to get different input |
|
I would say these layers finally get the correct input now. :) For your case, if you want to get the same results as before, please try below changes: import mxnet as mx
class Batch(object):
def __init__(self, data):
self.data = data
def get_batch_shape(self):
return tuple(self.data[0].shape)
data = mx.sym.Variable('data')
gpool = mx.sym.Pooling(data,
name='gpooling',
global_pool=False, # <--- remove global pooling
pad=(1,1), pool_type='avg',
stride=(5,5), # <--- add stride
kernel=(5,5),) # <--- change kernel size to input size
mod = mx.mod.Module(gpool, context=mx.cpu(0), label_names=[])
data = Batch([mx.ndarray.ones((1, 3, 5, 5))])
mod.bind(for_training=True, force_rebind=True, data_shapes=[('data', data.get_batch_shape())],)
mod.init_params()
mod.forward(data)
print(mx.__version__)
print(mod.get_outputs()[0].asnumpy()) |
|
Unfortunately, that doesn't guarantee NCx1 output for variable size inputs, which could cause new issues. |
|
Thank you for pinging @piyushghai . It seems @jmerkow has already figured out how to unblock that. Now he need make his PR passing CI and get approval. |
|
That's great. Thanks @TaoLv |
Description
Check padding size for global pooling. #9714
Checklist
Essentials
make lint)Changes
Comments