regexp_like fusing #8818
regexp_like fusing #8818
Conversation
Codecov Report
@@ Coverage Diff @@
## master #8818 +/- ##
============================================
- Coverage 69.82% 63.05% -6.78%
- Complexity 4658 4666 +8
============================================
Files 1741 1760 +19
Lines 91474 92058 +584
Branches 13674 13777 +103
============================================
- Hits 63875 58048 -5827
- Misses 23172 29846 +6674
+ Partials 4427 4164 -263
Flags with carried forward coverage won't be shown. Click here to find out more.
Continue to review full report at Codecov.
|
|
Wondering how much performance gain are we expecting here? |
|
I thought this was supposed to be targeting regexp_like |
My bad. I looked for regexp in the docs and given that only found regexpExact, I thought it was text_match the operation we want to optimize. Anyway, the idea is the same, so most of the code can be reused |
| @@ -255,6 +255,9 @@ private BaseFilterOperator constructPhysicalOperator(FilterContext filter, int n | |||
| || textIndexReader instanceof NativeMutableTextIndex) { | |||
| throw new UnsupportedOperationException("TEXT_MATCH is not supported on native text index"); | |||
| } | |||
| if (textIndexReader == null) { | |||
| throw new UnsupportedOperationException("TEXT_MATCH is not supported when there is no text index"); | |||
There was a problem hiding this comment.
This moves the correctness check from execution to parsing time, which should be better, but makes ExplainPlanQueriesTest fail.
As indicated by its name, this tests does execute explain plan instead of the actual query. This is why the test didn't fail before. As this PR shouldn't be related to text_match but regexp_like, I'm going to remove this change for simplicity
|
I don’t think it’s possible to express backreferences in a LIKE statement, this optimisation would target long unions of LIKE statements generated by ORMs, and should be most effective in reducing the impact on a cluster when there is no text or FST index in place. I expect this would also help FST based regular expression evaluation, so getting some numbers to justify extending to FST regex evaluators would be great. |
|
ORMs are not going to generate them, but a user may try to do something like What I'm going to do is to try to detect the usage of backreferences in the regexp. To do so, I'm going to discard any |
|
I've changed the implementation and the description of the PR to be focused on Anyway, I would like to have some benchmarks before this feature is merged. |
|
I don’t believe the native FST supports backreferences, and I don’t think it would be easy to add support either. Not sure about the lucene FST index. As mentioned above, LIKE statements (e.g. LIKE ‘%foo%’) can’t express all regular expression features, which should reduce the scope of the edge cases to be considered. This definitely needs benchmarking for at least the following scenarios;
for each of:
|
|
I didn't know LIKE expressions were evaluated as REGEX_LIKE. Reading the code, it seems that the transformation is made in I can modify the optimizer to add the ability to transform LIKE expressions into REGEX_LIKE the same way |
|
My last commit includes a JMH benchmark. I found several interesting things. Please take a look, some of my conclusions are so shocking that it wouldn't surprise me if another pair of eyes discovered that I did something wrong. TL;DR: I think we should apply this optimization only when executed in columns without indexes. This may make the implementation more difficult, but the performance gain may be very large. Benchmarks are:
Last results I´ve got were: After analyzing it, there are some points that are quite clear: We cannot use this optimization with LuceneThe cost is too high when the expression gets complex. It even with In general
|
|
@gortiz Thanks for the detailed analysis. This is awesome, and very interesting!
Curious how native FST handles it, and why is it so much faster than the Lucene FST. cc @atris
I think the reason is that it is not apple-to-apple comparison.
Let's re-do the benchmark. I don't believe there can be 2000x difference. Also, this is very counter-intuitive, so I'd suggest let's figure out if it is actually from the java regex engine, or because of our code.
I feel the inefficiency is from |
|
Yeah, the REGEXP_LIKE translation from LIKE is not equivalent. Also, remember that any FST traversal will benefit most from a selective expression rather than a full term match. Lastly, why do you say that indices don't help for single regexes? Unless I am misreading the benchmark result, even for a single regex case, native index is pretty fast? |
|
Thanks @atris for taking a look. I also have a question around how Lucene and native FST handle the query, specifically for these results: We can see that Lucene FST is very slow in this case, but native is still performing okay. Trying to understand what is causing this difference. |
|
I will check out the branch and give some comments tomorrow |
The difference will be due to determinization of the automaton, which the native implementation doesn’t do. |
I doubt determinization alone can cause such a massive difference. |
|
@Jackie-Jiang one thing is that the native index aggressively tries to prune branches, both while building the query automaton and during the traversal. That is also what causes general suffix and prefix queries to be much faster. |
Well, it’s an exponential time algorithm and Lucene refuses to even attempt to determinize some of the automata in the benchmark because they are too large. For an apples to apples comparison, native determinization should be re-enabled (by temporarily reverting/reversing #8237) |
I am still failing to understand what the concern is. Even if its plain determinization that causes native to be significantly faster, is that not a good thing? |
@Jackie-Jiang was asking about the root cause of the difference. I suggested that the root cause is likely to be determinization, but it needs to be investigated. Where has concern been expressed? |
|
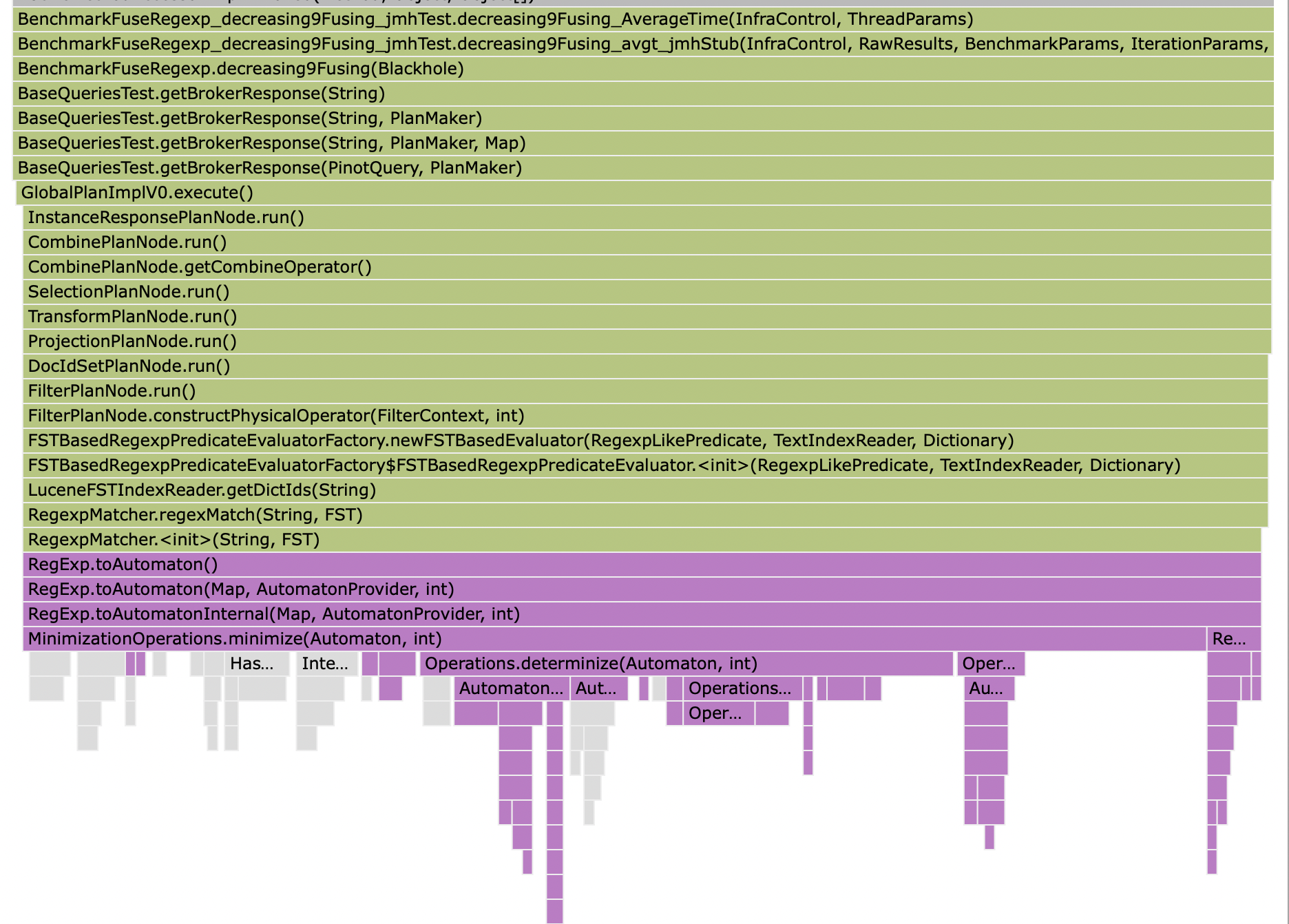
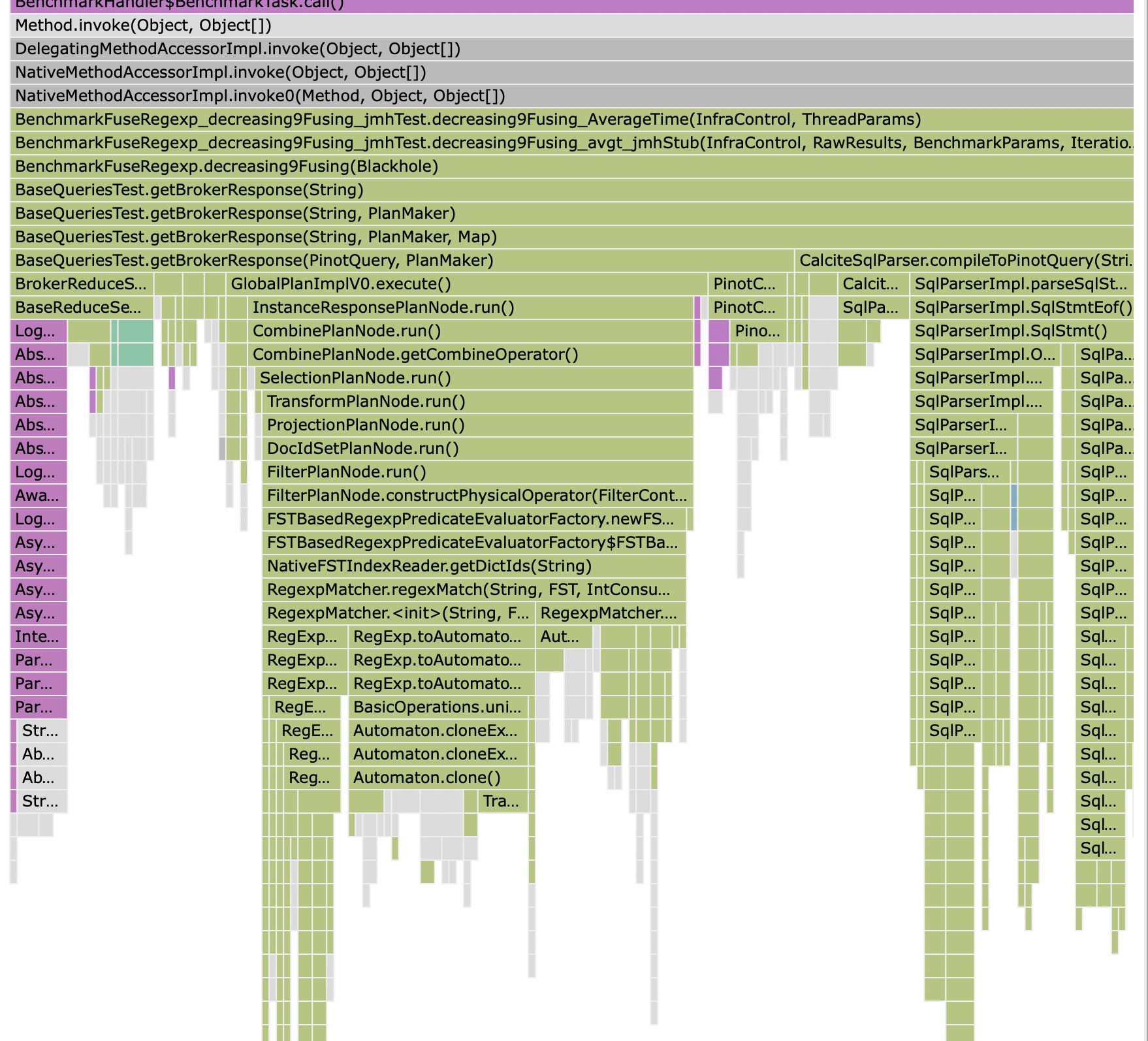
Just circling back here having taken a quick look at Lucene spends virtually all of its time in minimization (which I mistakenly referred to as determinization earlier, but actually entails determinization):
Now if I enable minimization in the native implementation by reverting #8237, the scores change drastically: As do the profiles. Without minimization, there is no clear single bottleneck: With minimization, there is a single bottleneck, and it's in minimization :
As to whether this is cause for concern is beside the point; this is the root cause of the difference observed, rather than a quirk of the benchmark which needs to be analysed and removed. |

My benchmark may not be the best and it is only measuring a few regexp cases, but I wouldn't say that native gives us a significant advantage: So we have one case where native is 1.8x faster and some others were it is equivalent to the java regex engine, which is known by its lack of performance. I mean, it is not like the native index is atrocious, but I would expect more from an index than a situational 1.8x performance increase. To be clear, as I already said, this is not a benchmark on the FST itself and it is very narrow, so I don't want to get conclusions about whether we should or we should not use these indexes. I think this benchmark proves that there are very specific cases where these indexes are not very useful and therefore it would be nice to invest time to design proper tests with different kind of regex to verify whether FST indexes are in general useful evaluating regex or not. |
|
I was able to invest more time in this topic today and I have to say that my initial benchmark was completely useless. Apart from some typos in the queries (which may have some impact), there were two problems that completely fooled me:
Therefore I've changed all the tests to return a count and each iteration is actually verifying whether the expected value is returned or not, in which case the benchmark is stopped. As a result, all fusing tests fail whenever there is an index. I hope it is something related to my test (ie I didn't configure the index properly) and not some semantic discrepancy these indexes have in relation how each engine evaluates regexp, as that could mean that there are customers receiving false results. These are the results I've got. Note that some combinations are not shown. For example, decreasing9Fusing and LUCENE or NATIVE. That means that these combinations did not return what it was expected (in all these particular cases it means that they return 0 rows). Note that apart from the fusing case, benchmarks like I've also changed With this results, the optimization introduced in this PR doesn't seem to be amazing, but to be honest I'm quite worried about what is going on with regexp and Lucene/Native indexes. As said above, I hope that the benchmark is not correctly configuring the indexes, but even with that, it seems very dangerous that an index can be configured in such a way that it affects the semantics of the queries. @Jackie-Jiang @atris I would really appreciate if any of you can take a look at the benchmark trying to find what is going on. |
|
@gortiz are you creating a FST index or a text index? |
|
@gortiz another thing to remember is that neither Lucene nor native FST index follow the java regex pattern language. If you look up the Lucene regex documentation, and look at the FST index and LIKE tests in Pinot, you will notice the difference. Unfortunately, since we do not actually parse the regex engine until deep inside the FST territory, we have no way of reporting unknown characters. That may be a factor leading to 0 results for your queries |
Wow, that is shocking and I would see that as a huge problem to use Pinot in a big team. In cases like that I would expect to have a new operation that does the search using the Lucene expression language or whatever we want to use and fail if there is no index. What you are saying is that if I have a column that is not indexed and suddenly a colleague of mine decides to index that column, queries I had will start to return different (and incorrect) results. Anyway, if that is what was decided, that is what we have. I'm going to close this PR, as it doesn't make sense to apply this optimization if it can be produce false results when someone adds an index. |
|
@gortiz There has been a long comment trail on this PR so I am summarising my responses in this comment:
In this case, the query you tried had an abnormally large number of branches, to the extent that Lucene decided to not even try and process the query. The average user rarely fires such queries, and in the corner cases where they do, they should be ok with a brute force latency, as long as their 99th percentile queries keep performing significantly better, which is the case as is evident from the benchmarks that test the FST index.
It is arguable whether this is correct or not, but we have to keep historical perspective in mind, since many Pinot users migrate from one of these engines. Please note that, from native FST index's perspective, it is pretty simple to support java regex language. The reason I did not do that was because the existing FST index was based on Lucene and thus supported Lucene's regex dialect. For back compatibility, native FST index supports the same dialect.
|
|
Yeah, I completely understand that we should maintain the Lucene language when Natife FST was created. My concern is with the fact that when Lucene index was added, we decided to accept a different language in IMHO a better solution would be to do not optimize It is too late to do that, so let's focus on useful things. This PR is closed, but I'm going to cherry pick the like to regex optimization to add it in another PR. |
|
@gortiz @atris Thanks for taking time looking into this issue. Even though we might not move forward with the query rewrite, we got several valuable insights from the benchmark. With regard to the query syntax, +100 on we should keep the query behavior consistent with or without the FST index. Currently we try to convert java regex to Lucene search query using We want to utilize the FST to accelerate the regex matching (
I personally prefer the second approach because it can improve the existing query performance, but it requires changes to the native FST, and we cannot support Lucene FST anymore. Or we can support both, and make the |
When executing queries like:
Pinot has to scan the referred column twice. This PR creates an optimization that tries to fuse boolean algebra and
regexp_likepredicates. Specifically, as indicated in the Javadoc:where regexp_like(col1, 'r1') and regexp_like(col1, '/r2/')will be translated towhere regexp_like(col1, '(?=r1)(?=r2)')where regexp_like(col1, 'r1') or regexp_like(col1, '/r2/')will be translated towhere regexp_like(col1, '(?:r1)|(?:r2)')where not regexp_like(col1, 'r1')will be translated towhere regexp_like(col1, '(?!r1)')There are some tests that apply the optimization to more advanced cases.
Regex can be quite complex. By doing some analysis I'm sure that this optimization will break some regex. For example, predicates that use backrefences may change the semantics when this optimization is applied.
To know if the optimization can be applied or not, it would be necessary to analyze the regex, which would require to parse the regex into a AST. As far as I know Pinot doesn't have that, so this optimization is disabled by default and can be enabled by activating a new query option. There is an heuristic that applies a basic analysis to try to find incompatible expressions like backreferences. Even when the query option is enabled, the regexp that are detected as not optimizable by the heuristic will not be optimized.
Future improvements may include to translate some
text_match, where this optimization may be useful.PD: Originally this PR was focused on optimizing
text_matchinstead ofregexp_like. Some comments may still be referred to the original version