PARQUET-1633: Fix integer overflow #902
Conversation
| @@ -1464,7 +1464,7 @@ protected PageHeader readPageHeader(BlockCipher.Decryptor blockDecryptor, byte[] | |||
| */ | |||
| private void verifyCrc(int referenceCrc, byte[] bytes, String exceptionMsg) { | |||
| crc.reset(); | |||
| crc.update(bytes); | |||
| crc.update(bytes, 0, bytes.length); | |||
There was a problem hiding this comment.
Changed to adopt a Java 8 API, to be consistent with the pom
There was a problem hiding this comment.
This is unrelated, I would prefer to update this in another PR.
There was a problem hiding this comment.
Agreed, committed to revert this change
|
Can you come up with a unit test? |
I want to, and I'm open to ideas. To re-create the problem you need a parquet file which has a full row group over 2GB in size followed by some more data, which translates to over 13GB+ of memory used. My concern is whether such a test would blow the constraints during CI or put an unreasonable memory burden on anyone wanting to build/test the project. What are reasonable limits there? I will add that no tests have found a regression with this change. |
|
Interesting to note |
|
I tried adapting |
|
I'll try to summarize the issue, please correct me if I'm wrong. Parquet-mr is not able to write such big row groups (>2GB) because of the The other option is to handle the too large row groups with a proper error message in parquet-mr without allowing silent overflows. This second option would be this effort. It is great to handle to potential int overflows but the main point, I think, would be at the footer conversion ( About the lack of the unit tests. I can accept in some cases where unit tests are not practically feasible to be implemented. In these cases I usually ask to validate the code offline. |
There was a problem hiding this comment.
I met a similar issue: https://issues.apache.org/jira/browse/PARQUET-2045, probably the same one.
I would like this fix got merged.
| @@ -1464,7 +1464,7 @@ protected PageHeader readPageHeader(BlockCipher.Decryptor blockDecryptor, byte[] | |||
| */ | |||
| private void verifyCrc(int referenceCrc, byte[] bytes, String exceptionMsg) { | |||
| crc.reset(); | |||
| crc.update(bytes); | |||
| crc.update(bytes, 0, bytes.length); | |||
There was a problem hiding this comment.
This is unrelated, I would prefer to update this in another PR.
| @@ -1763,8 +1763,8 @@ public void addChunk(ChunkDescriptor descriptor) { | |||
| public void readAll(SeekableInputStream f, ChunkListBuilder builder) throws IOException { | |||
| f.seek(offset); | |||
|
|
|||
| int fullAllocations = length / options.getMaxAllocationSize(); | |||
| int lastAllocationSize = length % options.getMaxAllocationSize(); | |||
| int fullAllocations = (int)(length / options.getMaxAllocationSize()); | |||
There was a problem hiding this comment.
(int)(length / options.getMaxAllocationSize()) -> Math.toIntExact(length / options.getMaxAllocationSize());
Hi @gszadovszky parquet-mr is able to produce big row groups. We found some files wrote by Spark(which uses parquet-mr) have this problem. See https://issues.apache.org/jira/browse/PARQUET-2045 for details. There are two options to fix this problem:
Either option is fine for me, WDYT? |
|
@advancedxy, thanks for explaining. |
@gszadovszky well understood. Hi @eadwright, is it possible for you to add the test case(tagged with @ignore) in your PR, so others like @gszadovszky or me can verify it offline? |
|
Not a unit test yet, but I have at least found a reliable way to create a parquet file in python which causes Java to break when reading it. For this we require a huge number of rows, and a string column with very high entropy to avoid the use dictionary lookup or compression. Not these conditions can be real-world - records containing long SHA3 hashes for example. This python code needs more than 16GB of RAM to execute. |
|
Screenshot from
|
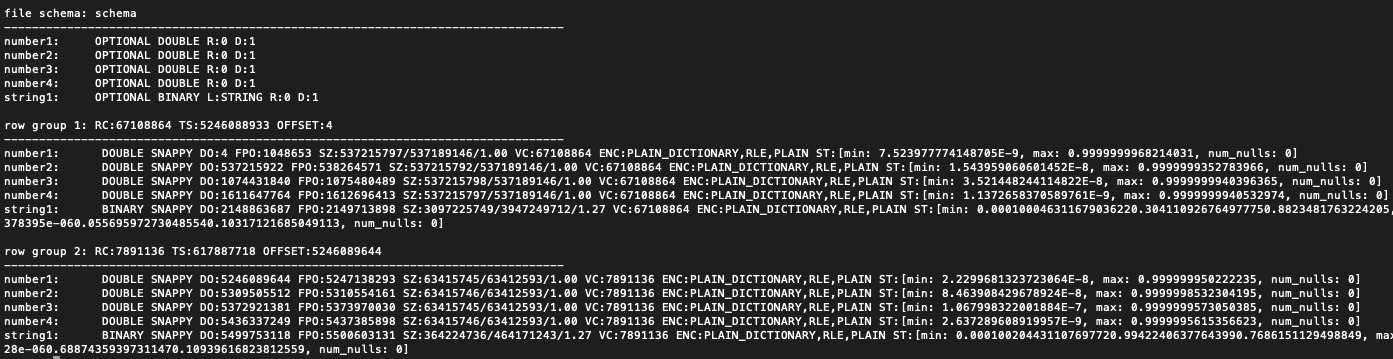
|
@eadwright, what do you mean by "necessary for the rows to spill over into a second row group."? It shall not be possible. Even the pages keep row boundaries but for row groups it is required by the specification. |
Sorry I probably didn't phrase that well. I mean, for this bug to occur, you need i) a row group which is taking more than 2GB of space, to get the 2^31 signed-int overflow, and ii) another subsequent row group (any size) so the code with the bug adds to a file offset using a corrupted value. In the example python code, if I asked it to produce 50M rows instead of 75M, you get a ~3.3GB row group, but no second row group. The file offset addition code path is not executed and the file gets read correctly, the bug is not triggered. |
|
Thanks, @eadwright for explaining. I get it now. |
|
Build failed due to some transient connectivity issue - builds fine for me, Java 8 and 11 |
|
Correction, we need a column within a row group to be over 2GB in size to cause the issue. It is not the row group size in total which counts. |
|
I've tweaked the python to create a test file which Java can't read. The python can now run fine on a 16GB machine. It creates 38M records, 37.8M of which are in the first row group, and the data for the |
|
@eadwright can you upload the corrupt parquet file to some public cloud service like google drive or s3? or is it possible for you to add a new test case(not run by default) in @gszadovszky do you have any other concerns about this pr? |
|
I've uploaded the python-generated file to my Google Drive: https://drive.google.com/file/d/1trWjeJaHpqbHlnipnDUrwlwYM-AKFNWg/view?usp=sharing Still working on a unit test. I'm used to working with Avro schema, but I'm trying to cut it back to bare-bones. |
|
Update - I've created some Java code which writes a parquet file nearly big enough to cause the issue, and can successfully read this file. However, two problems:
So... if any of you can reproduce the original error with the parquet file I posted above, and can validate this 7 line fix addresses it, that'd be great. Open to ideas of course. |
|
@eadwright, I'll try to look into this this week and produce a java code to reproduce the issue. |
|
@gszadovszky Awesome, appreciated. Also note the file uploaded isn't corrupt as such, it just goes beyond 32-bit limits. |
- Updated ParquetWriter to support setting row group size in long - Removed Xmx settings in the pom to allow more memory for the tests
|
@eadwright, I've implemented a unit test to reproduce the issue and test your solution. Feel free to use it in your PR. I've left some TODOs for you :) |
|
@eadwright, so the CI was executed somehow on my private repo and failed due to OoM. So, we may either investigate if we can tweak our configs/CI or disable this test by default. |
Parquet 1633
|
@gszadovszky I raised a PR to bring your changes in to my fork. Not had time yet alas to address the TODOs. I can say though that I believe to read that example file correctly with the fix requires 10GB of heap or so, probably similar with your test. Agree this test should be disabled by default, too heavy for CI. |
|
@eadwright, I've made some changes in the unit test (no more TODOs). See the update here. The idea is to not skip the tests in "normal" case but catch the OoM and skip. This way no tests should fail on any environments. Most of the modern laptops should have enough memory so this test will be executed on them. |
|
@gszadovszky I had a look at your changes. I feel uncomfortable relying on any behaviour at all after an OOM error. Are you sure this is the right approach? |
|
@gszadovszky Sorry, delay on my part. Have merged your changes in. Even in a testing pipeline I am uncomfortable with catching any kind of Love how the tests need ~3GB, not 10GB. |
|
@eadwright, I understand your concerns I don't really like it either. Meanwhile, I don't feel good having a test that is not executed automatically. Without regular executions there is no guarantee that this test would be executed ever again and even if someone would execute it it might fail because of the lack of maintenance. What do you think about the following options? @shangxinli, I'm also curious about your ideas.
|
|
Interesting options @gszadovszky , I have no strong opinion. I'd just like this fix merged once everyone is happy :) |
|
@eadwright, sorry, you're right. This is not tightly related to your PR. Please, remove the try-catch blocks for OOE and put an |
|
@gszadovszky done |
|
Pleasure @gszadovszky - thanks for yours! |
|
Note I don't have write access, so I guess someone needs to merge this at some point? Not sure of your workflow. |
|
Sure, @eadwright, I'm merging it. I just usually give another day after the approval so others have the chance to comment. |
|
@eadwright, do you have a jira account so I can assign this one to you? |
|
@gszadovszky Thanks - just created Jira account |
Unit test: - Updated ParquetWriter to support setting row group size in long - Removed Xmx settings in the pom to allow more memory for the tests Co-authored-by: Gabor Szadovszky <gabor@apache.org>
Unit test: - Updated ParquetWriter to support setting row group size in long - Removed Xmx settings in the pom to allow more memory for the tests Co-authored-by: Gabor Szadovszky <gabor@apache.org> Cherry-picked from apache#902 commit 98ddadf
Unit test: - Updated ParquetWriter to support setting row group size in long - Removed Xmx settings in the pom to allow more memory for the tests Co-authored-by: Gabor Szadovszky <gabor@apache.org> (cherry picked from commit aa132b3)
This PR addresses this issue: https://issues.apache.org/jira/browse/PARQUET-1633
I have not added unit tests, as to check overflow conditions I would need test data over 2GB in size (on disk, compressed), considerably larger in-memory and thus requiring significant CI resources.
The issue was using an
intfor length field, which for parquet files with very largerow_group_size(row groups over 2GB) would cause silent integer overflow, manifesting itself as negative length and an attempt to create an ArrayList with negative length.I have tested reading a 6.6GB parquet file with a huge row group size (works out at over 2GB) which recreated this problem, and with this modification can read the file without any issues.