An optimal algorithm for bounded random integers #39143
Conversation
Everyone knows that generating an unbiased random integer in a range 0 ..< upperBound, where upperBound is not a power of two, requires rejection sampling. What if I told you that Big Random Number has lied to us for decades, and we have been played for absolute fools? Previously Swift used Lemire's "nearly divisionless" method (https://arxiv.org/abs/1805.10941) for this operation. This PR introduces a novel algorithm that: - never divides - avoids rejection sampling entirely - achieves a theoretically optimal bound on the amount of randomness consumed to generate a sample - delivers actual performance improvements for most real cases Lemire interprets each word from the random source as a fixed-point number in [0, 1), multiplies by upperBound, and takes the floor. Up to this point, this is the algorithm suggested by Knuth in TAoCP vol 2, and as observed by Knuth, it is slightly biased. Lemire cleverly corrects this bias via rejection sampling, which requires one division in the general case (hence, "nearly divisionless"). Our new algorithm takes a different approach. Rather than using rejection sampling, we observe that the bias decreases exponentially in the number of bits used for the computation. In the limit we are interpreting the bitstream from the random source as a uniform real number r in [0, 1) and ⌊r * upperBound⌋ provides an unbiased sample in 0 ..< upperBound. The only challenge, then, is to know when we have computed enough bits of the product to know what the result is. Observe that we can split the random stream at any bit position i, yielding r = r₀ + r₁ with r₀ a fixed-point number in [0,1) and 0 ≤ r₁ < 2⁻ⁱ. Further observe that: result = ⌊r * upperBound⌋ = ⌊r₀ * upperBound⌋ + ⌊frac(r₀*upperBound) + r₁*upperBound⌋ The first term of this expression is just Knuth's biased sample, which is computed with just a full-width multiply. If i > log₂(upperBound), both summands in the second term are smaller than 1, so the second term is either 0 or 1. Applying the bound on r₁, we see that if frac(r₀ * upperBound) <= 1 - upperBound * 2⁻ⁱ, the second term is necessarily zero, and the first term is the unbiased result. Happily, this is _also_ a trivial computation on the low-order part of the full-width multiply. If the test fails, we do not reject the sample, throwing away the bits we have already consumed from the random source; instead we increase i by a convenient amount, computing more bits of the product. This is the criticial improvement; while Lemire has a probability of 1/2 to reject for each word consumed in the worst case, we have a probability of terminating of 1/2 for each _bit_ consumed. This reduces the worst-case expected number of random bits required from O(log₂(upperBound)) to log₂(upperBound) + O(1), which is optimal[1]. Of more practical interest, this new algorithm opens an intriguing possibility: we can compute just 64 extra bits, and have a probability of 1 - 2⁻⁶⁴ of terminating. This is so close to certainty that we can simply stop unconditionally without introducing any measurable bias (detecting any difference would require about 2¹²⁸ samples, which is prohibitive). This is a significant performance improvement for slow random generators, since it asymptotically reduces the number of bits required by a factor of two for bignums, while matching the expected number of bits required for smaller numbers. This is the algorithm implemented by this PR (the formally-uniform method is not much more complex to implement and is only a little bit slower, but there's no reason to do so). More intriguing still, this algorithm can be made unconditional by removing the early out, so that every value computed requires word size + 64 bits from the stream, which breaks the loop-carried dependency for fast generators, unlocking vectorization and parallelization where it was previously impossible. This is an especially powerful advantage when paired with bitstream generators that allow skip-ahead such as counter-based generators or PCG. Note that it is _possible_ to employ Lemire's tighter early-out check that involves a division with this algorithm as well; this is beneficial in some cases when upperBound is a constant and the generator is slow, but we do not think it necessary with the new algorithm and other planned improvements. [1] We can actually achieve log₂(upperBound) + ε for any ε > 0 by generating multiple random samples at once, but that is only of theoretical interest--it is still interesting, however, since I don't think anyone has described how to attain it previously.
|
Related idea at: https://github.com/KWillets/range_generator The approach is an application of the concept of short product. I recently made use of it for a fast number parser... see paper at https://arxiv.org/pdf/2101.11408.pdf (section 7) |
| /// | ||
| /// Requires T.bitWidth >= 64. | ||
| @_transparent @usableFromInline | ||
| internal func multiplyHigh<T:FixedWidthInteger & UnsignedInteger>( |
There was a problem hiding this comment.
Could delete the ABI footprint of this by making it @_alwaysEmitIntoClient, I think. (Would also underscore the name.)
|
Since this is "doing numbers" it's worth pointing out here that the versions of this algorithm with early-outs can leak timing information, even if implemented with constant-time primitives (because the distribution of values that require an additional word be computed is not uniform in the set of outputs). For Swift's standard library that's not a major issue, but it would be problematic for some other places such algorithms can be deployed. (This does not apply to the unconditional "just use 64 extra bits no matter what" version.) |
nb: isn't this the "Fast Dice Roller" presented in Lumbroso (2013) "Optimal discrete uniform generation from coin flips, and applications"? In any case, congrats on beating CPython, PHP, C stdlib, OpenSSL, OpenJDK, Node, Rust, and Go to the punch. This thread helped me find the existence of this algorithm far faster than I would have otherwise. |
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator Reviewed-by: Tom Cosgrove <tom.cosgrove@arm.com> Reviewed-by: Matthias St. Pierre <Matthias.St.Pierre@ncp-e.com> Reviewed-by: Tomas Mraz <tomas@openssl.org> (Merged from #22499)
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator Reviewed-by: Tom Cosgrove <tom.cosgrove@arm.com> Reviewed-by: Matthias St. Pierre <Matthias.St.Pierre@ncp-e.com> Reviewed-by: Tomas Mraz <tomas@openssl.org> (Merged from #22499) (cherry picked from commit 55755fb)
Refer: swiftlang/swift#39143 for a description of the algorithm. It is optimal in the sense of having: * no divisions * minimal number of blocks of random bits from the generator Reviewed-by: Tom Cosgrove <tom.cosgrove@arm.com> Reviewed-by: Matthias St. Pierre <Matthias.St.Pierre@ncp-e.com> Reviewed-by: Tomas Mraz <tomas@openssl.org> (Merged from openssl/openssl#22499) Signed-off-by: fly2x <fly2x@hitls.org>
…oposed in swiftlang/swift#39143 based on OpenSSL's implementation of it in https://github.com/openssl/openssl/blob/1d2cbd9b5a126189d5e9bc78a3bdb9709427d02b/crypto/rand/rand_uniform.c#L13-L99
…oposed in swiftlang/swift#39143 based on OpenSSL's implementation of it in https://github.com/openssl/openssl/blob/1d2cbd9b5a126189d5e9bc78a3bdb9709427d02b/crypto/rand/rand_uniform.c#L13-L99
Implement optimal uniform random number generator using the method proposed in swiftlang/swift#39143 based on OpenSSL's implementation of it in https://github.com/openssl/openssl/blob/1d2cbd9b5a126189d5e9bc78a3bdb9709427d02b/crypto/rand/rand_uniform.c#L13-L99 This PR also fixes some bugs found while developing it. This is a replacement for #50203 and fixes the issues found by @IanButterworth with both rngs C rng <img width="1011" alt="image" src="https://github.com/user-attachments/assets/0dd9d5f2-17ef-4a70-b275-1d12692be060"> New scheduler rng <img width="985" alt="image" src="https://github.com/user-attachments/assets/4abd0a57-a1d9-46ec-99a5-535f366ecafa"> ~On my benchmarks the julia implementation seems to be almost 50% faster than the current implementation.~ With oscars suggestion of removing the debiasing this is now almost 5x faster than the original implementation. And almost fully branchless We might want to backport the two previous commits since they technically fix bugs. --------- Co-authored-by: Valentin Churavy <vchuravy@users.noreply.github.com>
Implement optimal uniform random number generator using the method proposed in swiftlang/swift#39143 based on OpenSSL's implementation of it in https://github.com/openssl/openssl/blob/1d2cbd9b5a126189d5e9bc78a3bdb9709427d02b/crypto/rand/rand_uniform.c#L13-L99 This PR also fixes some bugs found while developing it. This is a replacement for #50203 and fixes the issues found by @IanButterworth with both rngs C rng <img width="1011" alt="image" src="https://github.com/user-attachments/assets/0dd9d5f2-17ef-4a70-b275-1d12692be060"> New scheduler rng <img width="985" alt="image" src="https://github.com/user-attachments/assets/4abd0a57-a1d9-46ec-99a5-535f366ecafa"> ~On my benchmarks the julia implementation seems to be almost 50% faster than the current implementation.~ With oscars suggestion of removing the debiasing this is now almost 5x faster than the original implementation. And almost fully branchless We might want to backport the two previous commits since they technically fix bugs. --------- Co-authored-by: Valentin Churavy <vchuravy@users.noreply.github.com>
* Improve type-stability in SymTridiagonal triu!/tril! (#55646)
Changing the final `elseif` branch to an `else` makes it clear that the
method definite returns a value, and the returned type is now a
`Tridiagonal` instead of a `Union{Nothing, Tridiagonal}`
* Reuse size-check function from `lacpy!` in `copytrito!` (#55664)
Since there is a size-check function in `lacpy!` that does the same
thing, we may reuse it instead of duplicating the check
* Update calling-c-and-fortran-code.md: fix ccall parameters (not a tuple) (#55665)
* Allow exact redefinition for types with recursive supertype reference (#55380)
This PR allows redefining a type when the new type is exactly identical
to the previous one (like #17618, #20592 and #21024), even if the type
has a reference to itself in its supertype. That particular case used to
error (issue #54757), whereas with this PR:
```julia
julia> struct Rec <: AbstractVector{Rec} end
julia> struct Rec <: AbstractVector{Rec} end # this used to error
julia>
```
Fix #54757 by implementing the solution proposed there. Hence, this
should also fix downstream Revise bug
https://github.com/timholy/Revise.jl/issues/813.
---------
Co-authored-by: N5N3 <2642243996@qq.com>
* Reroute Symmetric/Hermitian + Diagonal through triangular (#55605)
This should fix the `Diagonal`-related issue from
https://github.com/JuliaLang/julia/issues/55590, although the
`SymTridiagonal` one still remains.
```julia
julia> using LinearAlgebra
julia> a = Matrix{BigFloat}(undef, 2,2)
2×2 Matrix{BigFloat}:
#undef #undef
#undef #undef
julia> a[1] = 1; a[3] = 1; a[4] = 1
1
julia> a = Hermitian(a)
2×2 Hermitian{BigFloat, Matrix{BigFloat}}:
1.0 1.0
1.0 1.0
julia> b = Symmetric(a)
2×2 Symmetric{BigFloat, Matrix{BigFloat}}:
1.0 1.0
1.0 1.0
julia> c = Diagonal([1,1])
2×2 Diagonal{Int64, Vector{Int64}}:
1 ⋅
⋅ 1
julia> a+c
2×2 Hermitian{BigFloat, Matrix{BigFloat}}:
2.0 1.0
1.0 2.0
julia> b+c
2×2 Symmetric{BigFloat, Matrix{BigFloat}}:
2.0 1.0
1.0 2.0
```
* inference: check argtype compatibility in `abstract_call_opaque_closure` (#55672)
* Forward istriu/istril for triangular to parent (#55663)
* win: move stack_overflow_warning to the backtrace fiber (#55640)
There is not enough stack space remaining after a stack overflow on
Windows to allocate the 4k page used by `write` to call the WriteFile
syscall. This causes it to hard-crash. But we can simply run this on the
altstack implementation, where there is plenty of space.
* Check if ct is not null before doing is_addr_on_stack in the macos signal handler. (#55603)
Before the check we used to segfault while segfaulting and hang
---------
Co-authored-by: Jameson Nash <vtjnash@gmail.com>
* Profile.print: color Base/Core & packages. Make paths clickable (#55335)
Updated
## This PR

## master
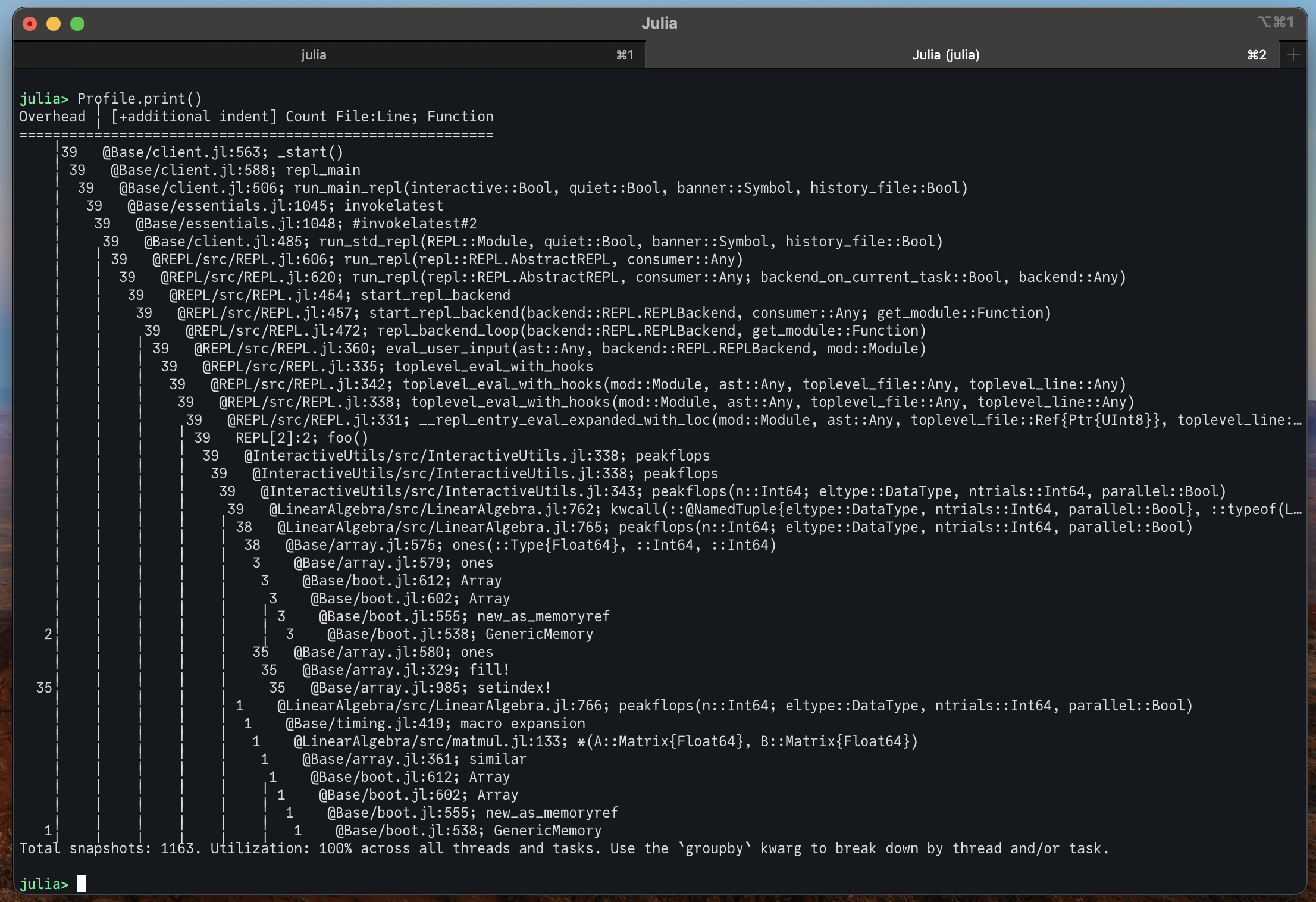
Todo:
- [ ] ~Maybe drop the `@` prefix when coloring it, given it's obviously
special when colored~ If someone copy-pasted the profile into an issue
this would make it confusing.
- [ ] Figure out why `Profile.print(format=:flat)` is truncating before
the terminal width is used up
- [x] Make filepaths terminal links (even if they're truncated)
* better signal handling (#55623)
Instead of relying on creating a fake stack frame, and having no signals
delivered, kernel bugs, accidentally gc_collect, or other issues occur
during the delivery and execution of these calls, use the ability we
added recently to emulate a longjmp into a unw_context to eliminate any
time where there would exist any invalid states.
Secondly, when calling jl_exit_thread0_cb, we used to end up completely
smashing the unwind info (with CFI_NOUNWIND), but this makes core files
from SIGQUIT much less helpful, so we now have a `fake_stack_pop`
function with contains the necessary CFI directives such that a minimal
unwind from the debugger will likely still succeed up into the frames
that were removed. We cannot do this perfectly on AArch64 since that
platform's DWARF spec lacks the ability to do so. On other platforms,
this should be possible to implement exactly (subject to libunwind
implementation quality). This is currently thus only fully implemented for
x86_64 on Darwin Apple.
* fix `exct` for mismatched opaque closure call
* improve `exct` modeling for opaque closure calls
* fix `nothrow` modeling for `invoke` calls
* improve `exct` modeling for `invoke` calls
* show a bit more detail when finished precompiling (#55660)
* subtype: minor clean up for fast path for lhs union and rhs typevar (#55645)
Follow up #55413.
The error pattern mentioned in
https://github.com/JuliaLang/julia/pull/55413#issuecomment-2288384468
care's `∃y`'s ub in env rather than its original ub.
So it seems more robust to check the bounds in env directly.
The equivalent typevar propagation is lifted from `subtype_var` for the
same reason.
* Adding `JL_DATA_TYPE` annotation to `_jl_globalref_t` (#55684)
`_jl_globalref_t` seems to be allocated in the heap, and there is an
object `jl_globalref_type` which indicates that it is in fact, a data
type, thus it should be annotated with `JL_DATA_TYPE`??
* Make GEP when loading the PTLS an inbounds one. (#55682)
Non inbounds GEPs should only be used when doing pointer arithmethic i.e
Ptr or MemoryRef boundscheck.
Found when auditing non inbounds GEPs for
https://github.com/JuliaLang/julia/pull/55681
* codegen: make boundscheck GEP not be inbounds while the load GEP is inbounds (#55681)
Avoids undefined behavior on the boundschecking arithmetic, which is
correct only assuming overflow follows unsigned arithmetic wrap around
rules.
Also add names to the Memory related LLVM instructions to aid debugging
Closes: https://github.com/JuliaLang/julia/pull/55674
* Make `rename` public (#55652)
Fixes #41584. Follow up of #55503
I think `rename` is a very useful low-level file system operation. Many
other programming languages have this function, so it is useful when
porting IO code to Julia.
One use case is to improve the Zarr.jl package to be more compatible
with zarr-python.
https://github.com/zarr-developers/zarr-python/blob/0b5483a7958e2ae5512a14eb424a84b2a75dd727/src/zarr/v2/storage.py#L994
uses the `os.replace` function. It would be nice to be able to directly
use `Base.rename` as a replacement for `os.replace` to ensure
compatibility.
Another use case is writing a safe zip file extractor in pure Julia.
https://github.com/madler/sunzip/blob/34107fa9e2a2e36e7e72725dc4c58c9ad6179898/sunzip.c#L365
uses the `rename` function to do this in C.
Lastly in
https://github.com/medyan-dev/MEDYANSimRunner.jl/blob/67d5b42cc599670486d5d640260a95e951091f7a/src/file-saving.jl#L83
I am using `ccall(:jl_fs_rename` to save files, because I have large
numbers of Julia processes creating and reading these files at the same
time on a distributed file system on a cluster, so I don't want data to
become corrupted if one of the nodes crashes (which happens fairly
regularly). However `jl_fs_rename` is not public, and might break in a
future release.
This PR also adds a note to `mv` comparing it to the `mv` command,
similar to the note on the `cp` function.
* contrib: include private libdir in `ldflags` on macOS (#55687)
The private libdir is used on macOS, so it needs to be included in our
`ldflags`
* Profile.print: Shorten C paths too (#55683)
* [LLVMLibUnwindJLL] Update llvmlibunwind to 14.0.6 (#48140)
* Add `JL_DATA_TYPE` for `jl_line_info_node_t` and `jl_code_info_t` (#55698)
* Canonicalize names of nested functions by keeping a more fine grained counter -- per (module, method name) pair (#53719)
As mentioned in https://github.com/JuliaLang/julia/pull/53716, we've
been noticing that `precompile` statements lists from one version of our
codebase often don't apply cleanly in a slightly different version.
That's because a lot of nested and anonymous function names have a
global numeric suffix which is incremented every time a new name is
generated, and these numeric suffixes are not very stable across
codebase changes.
To solve this, this PR makes the numeric suffixes a bit more fine
grained: every pair of (module, top-level/outermost function name) will
have its own counter, which should make nested function names a bit more
stable across different versions.
This PR applies @JeffBezanson's idea of making the symbol name changes
directly in `current-julia-module-counter`.
Here is an example:
```Julia
julia> function foo(x)
function bar(y)
return x + y
end
end
foo (generic function with 1 method)
julia> f = foo(42)
(::var"#bar#foo##0"{Int64}) (generic function with 1 method)
```
* Use `uv_available_parallelism` inside `jl_effective_threads` (#55592)
* [LinearAlgebra] Initialise number of BLAS threads with `jl_effective_threads` (#55574)
This is a safer estimate than `Sys.CPU_THREADS` to avoid oversubscribing
the machine when running distributed applications, or when the Julia
process is constrained by external controls (`taskset`, `cgroups`,
etc.).
Fix #55572
* Artifacts: Improve type-stability (#55707)
This improves Artifacts.jl to make `artifact"..."` fully type-stable, so
that it can be used with `--trim`.
This is a requirement for JLL support w/ trimmed executables.
Dependent on https://github.com/JuliaLang/julia/pull/55016
---------
Co-authored-by: Gabriel Baraldi <baraldigabriel@gmail.com>
* Remove redundant conversion in structured matrix broadcasting (#55695)
The additional construction is unnecessary, as we are already
constructing a `Matrix`.
Performance:
```julia
julia> using LinearAlgebra
julia> U = UpperTriangular(rand(1000,1000));
julia> L = LowerTriangular(rand(1000,1000));
julia> @btime $U .+ $L;
1.956 ms (6 allocations: 15.26 MiB) # nightly
1.421 ms (3 allocations: 7.63 MiB) # This PR
```
* [Profile] fix threading issue (#55704)
I forgot about the existence of threads, so had hard-coded this to only
support one thread. Clearly that is not sufficient though, so use the
semaphore here as it is intended to be used.
Fixes #55703
---------
Co-authored-by: Ian Butterworth <i.r.butterworth@gmail.com>
* delete flaky ranges/`TwicePrecision` test (#55712)
Fixes #55710
* Avoid stack overflow in triangular eigvecs (#55497)
This fixes a stack overflow in
```julia
julia> using LinearAlgebra, StaticArrays
julia> U = UpperTriangular(SMatrix{2,2}(1:4))
2×2 UpperTriangular{Int64, SMatrix{2, 2, Int64, 4}} with indices SOneTo(2)×SOneTo(2):
1 3
⋅ 4
julia> eigvecs(U)
Warning: detected a stack overflow; program state may be corrupted, so further execution might be unreliable.
ERROR: StackOverflowError:
Stacktrace:
[1] eigvecs(A::UpperTriangular{Float32, SMatrix{2, 2, Float32, 4}}) (repeats 79984 times)
@ LinearAlgebra ~/.julia/juliaup/julia-nightly/share/julia/stdlib/v1.12/LinearAlgebra/src/triangular.jl:2749
```
After this,
```julia
julia> eigvecs(U)
2×2 Matrix{Float32}:
1.0 1.0
0.0 1.0
```
* builtins: add `Core.throw_methoderror` (#55705)
This allows us to simulate/mark calls that are known-to-fail.
Required for https://github.com/JuliaLang/julia/pull/54972/
* Small missing tests for Irrationals (#55657)
Looks like a bunch of methods for `Irrational`s are tested but not
picked up by coverage...
* Implement faster thread local rng for scheduler (#55501)
Implement optimal uniform random number generator using the method
proposed in https://github.com/swiftlang/swift/pull/39143 based on
OpenSSL's implementation of it in
https://github.com/openssl/openssl/blob/1d2cbd9b5a126189d5e9bc78a3bdb9709427d02b/crypto/rand/rand_uniform.c#L13-L99
This PR also fixes some bugs found while developing it. This is a
replacement for https://github.com/JuliaLang/julia/pull/50203 and fixes
the issues found by @IanButterworth with both rngs
C rng
<img width="1011" alt="image"
src="https://github.com/user-attachments/assets/0dd9d5f2-17ef-4a70-b275-1d12692be060">
New scheduler rng
<img width="985" alt="image"
src="https://github.com/user-attachments/assets/4abd0a57-a1d9-46ec-99a5-535f366ecafa">
~On my benchmarks the julia implementation seems to be almost 50% faster
than the current implementation.~
With oscars suggestion of removing the debiasing this is now almost 5x
faster than the original implementation. And almost fully branchless
We might want to backport the two previous commits since they
technically fix bugs.
---------
Co-authored-by: Valentin Churavy <vchuravy@users.noreply.github.com>
* Add precompile signatures to Markdown to reduce latency. (#55715)
Fixes #55706 that is seemingly a 4472x regression, not just 16x (was my
first guess, based on CondaPkg, also fixes or greatly mitigates
https://github.com/JuliaPy/CondaPkg.jl/issues/145), and large part of 3x
regression for PythonCall.
---------
Co-authored-by: Kristoffer Carlsson <kcarlsson89@gmail.com>
* Fix invalidations for FileIO (#55593)
Fixes https://github.com/JuliaIO/FileIO.jl/issues/396
* Fix various issues with PGO+LTO makefile (#55581)
This fixes various issues with the PGO+LTO makefile
- `USECCACHE` doesn't work throwing an error at
https://github.com/JuliaLang/julia/blob/eb5587dac02d1f6edf486a71b95149139cc5d9f7/Make.inc#L734
This is because setting `CC` and `CCX` by passing them as arguments to
`make` prevents `Make.inc` from prepending these variables with `ccache`
as `Make.inc` doesn't use override. To workaround this I instead set
`USECLANG` and add the toolchain to the `PATH`.
- To deal with similar issues for the other make flags, I pass them as
environment variables which can be edited in `Make.inc`.
- I add a way to build in one go by creating the `all` target, now you
can just run `make` and a PGO+LTO build that profiles Julia's build will
be generated.
- I workaround `PROFRAW_FILES` not being reevaluated after `stage1`
builds, this caused the generation of `PROFILE_FILE` to run an outdated
command if `stage1` was built and affected the profraw files. This is
important when building in one go.
- I add a way to run rules like `binary-dist` which are not defined in
this makefile with the correct toolchain which for example prevents
`make binary-dist` from unnecessarily rebuilding `sys.ji`.
- Include `-Wl,--undefined-version` till
https://github.com/JuliaLang/julia/issues/54533 gets fixed.
These changes need to be copied to the PGO+LTO+BOLT makefile and some to
the BOLT makefile in a later pr.
---------
Co-authored-by: Zentrik <Zentrik@users.noreply.github.com>
* Fix `pkgdir` for extensions (#55720)
Fixes https://github.com/JuliaLang/julia/issues/55719
---------
Co-authored-by: Max Horn <241512+fingolfin@users.noreply.github.com>
* Avoid materializing arrays in bidiag matmul (#55450)
Currently, small `Bidiagonal`/`Tridiagonal` matrices are materialized in
matrix multiplications, but this is wasteful and unnecessary. This PR
changes this to use a naive matrix multiplication for small matrices,
and fall back to the banded multiplication for larger ones.
Multiplication by a `Bidiagonal` falls back to a banded matrix
multiplication for all sizes in the current implementation, and iterates
in a cache-friendly manner for the non-`Bidiagonal` matrix.
In certain cases, the matrices were being materialized if the
non-structured matrix was small, even if the structured matrix was
large. This is changed as well in this PR.
Some improvements in performance:
```julia
julia> B = Bidiagonal(rand(3), rand(2), :U); A = rand(size(B)...); C = similar(A);
julia> @btime mul!($C, $A, $B);
193.152 ns (6 allocations: 352 bytes) # nightly v"1.12.0-DEV.1034"
18.826 ns (0 allocations: 0 bytes) # This PR
julia> T = Tridiagonal(rand(99), rand(100), rand(99)); A = rand(2, size(T,2)); C = similar(A);
julia> @btime mul!($C, $A, $T);
9.398 μs (8 allocations: 79.94 KiB) # nightly
416.407 ns (0 allocations: 0 bytes) # This PR
julia> B = Bidiagonal(rand(300), rand(299), :U); A = rand(20000, size(B,2)); C = similar(A);
julia> @btime mul!($C, $A, $B);
33.395 ms (0 allocations: 0 bytes) # nightly
6.695 ms (0 allocations: 0 bytes) # This PR (cache-friendly)
```
Closes https://github.com/JuliaLang/julia/pull/55414
---------
Co-authored-by: Daniel Karrasch <daniel.karrasch@posteo.de>
* Fix `@time_imports` extension recognition (#55718)
* drop typed GEP calls (#55708)
Now that we use LLVM 18, and almost have LLVM 19 support, do cleanup to
remove LLVM 15/16 type pointer support. LLVM now slightly prefers that
we rewrite our complex GEP to use a simple emit_ptrgep call instead,
which is also much simpler for julia to emit also.
* minor fixup for JuliaLang/julia#55705 (#55726)
* [REPL] prevent silent hang if precompile script async blocks fail (#55685)
* Various fixes to byte / bytearray search (#54579)
This was originally intended as a targeted fix to #54578, but I ran into
a bunch of smaller issues with this code that also needed to be solved
and it turned out to be difficult to fix them with small, trivial PRs.
I would also like to refactor this whole file, but I want these
correctness fixes to be merged first, because a larger refactoring has
higher risk of getting stuck without getting reviewed and merged.
## Larger things that needs decisions
* The internal union `Base.ByteArray` has been deleted. Instead, the
unions `DenseInt8` and `DenseUInt8` have been added. These more
comprehensively cover the types that was meant, e.g. `Memory{UInt8}` was
incorrectly not covered by the former. As stated in the TODO, the
concept of a "memory backed dense byte array" is needed throughout
Julia, so this ideally needs to be implemented as a single type and used
throughout Base. The fix here is a decent temporary solution. See #53178
#54581
* The `findall` docstring between two arrays was incorrectly not
attached to the method - now it is. **Note that this change _changes_
the documentation** since it includes a docstring that was previously
missed. Hence, it's an API addition.
* Added a new minimal `testhelpers/OffsetDenseArrays.jl` which provide a
`DenseVector` with offset axes for testing purposes.
## Trivial fixes
* `findfirst(==(Int8(-1)), [0xff])` and similar findlast, findnext and
findprev is no longer buggy, see #54578
* `findfirst([0x0ff], Int8[-1])` is similarly no longer buggy, see
#54578
* `findnext(==('\xa6'), "æ", 1)` and `findprev(==('\xa6'), "æa", 2)` no
longer incorrectly throws an error
* The byte-oriented find* functions now work correctly with offset
arrays
* Fixed incorrect use of `GC.@preserve`, where the pointer was taken
before the preserve block.
* More of the optimised string methods now also apply to
`SubString{String}`
Closes #54578
Co-authored-by: Martin Holters <martin.holters@hsu-hh.de>
* codegen: deduplicate code for calling a specsig (#55728)
I am tired of having 3 gratuitously different versions of this code to
maintain.
* Fix "Various fixes to byte / bytearray search" (#55734)
Fixes the conflict between #54593 and #54579
`_search` returns `nothing` instead of zero as a sentinal in #54579
* Fix `make binary-dist` when using `USE_BINARYBUILDER_LLVM=0` (#55731)
`make binary-dist` expects lld to be in usr/tools but it ends up in
usr/bin so I copied it into usr/tools. Should fix the scheduled source
tests which currently fail at linking.
I think this is also broken with `USE_BINARYBUILDER_LLVM=0` and
`BUILD_LLD=0`, maybe
https://github.com/JuliaLang/julia/commit/ceaeb7b71bc76afaca2f3b80998164a47e30ce33
is the fix?
---------
Co-authored-by: Zentrik <Zentrik@users.noreply.github.com>
* Precompile the `@time_imports` printing so it doesn't confuse reports (#55729)
Makes functions for the report printing that can be precompiled into the
sysimage.
* codegen: some cleanup of layout computations (#55730)
Change Alloca to take an explicit alignment, rather than relying on LLVM
to guess our intended alignment from the DataLayout.
Eventually we should try to change this code to just get all layout data
from julia queries (jl_field_offset, julia_alignment, etc.) instead of
relying on creating an LLVM element type for memory and inspecting it
(CountTrackedPointers, DataLayout, and so on).
* Add some loading / LazyArtifacts precompiles to the sysimage (#55740)
Fixes https://github.com/JuliaLang/julia/issues/55725
These help LazyArtifacts mainly but seem beneficial for the sysimage.
* Update stable version number in readme to v1.10.5 (#55742)
* Add `invokelatest` barrier to `string(...)` in `@assert` (#55739)
This change protects `@assert` from invalidations to `Base.string(...)`
by adding an `invokelatest` barrier.
A common source of invalidations right now is `print(io,
join(args...))`. The problem is:
1. Inference concludes that `join(::Any...)` returns
`Union{String,AnnotatedString}`
2. The `print` call is union-split to `String` and `AnnotatedString`
3. This code is now invalidated when StyledStrings defines `print(io,
::AnnotatedString)`
The invalidation chain for `@assert` is similar: ` @assert 1 == 1` calls
into `string(::Expr)` which calls into `print(io, join(args::Any...))`.
Unfortunately that leads to the invalidation of almost all `@assert`s
without an explicit error message
Similar to
https://github.com/JuliaLang/julia/pull/55583#issuecomment-2308969806
* Don't show string concatenation error hint with zero arg `+` (#55749)
Closes #55745
* Don't leave trailing whitespace when printing do-block expr (#55738)
Before, when printing a `do`-block, we'd print a white-space after `do`
even if no arguments follow. Now we don't print that space.
---------
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
* Don't pass lSystem to the linker since macos always links it (#55722)
This stops it complaing about duplicated libs.
For libunwind there isn't much we can do because it's part of lsystem
and we also need out own.
* define `numerator` and `denominator` for `Complex` (#55694)
Fixes #55693
* More testsets for SubString and a few missing tests (#55656)
Co-authored-by: Simeon David Schaub <simeon@schaub.rocks>
* Reorganize search tests into testsets (#55658)
Some of these tests are nearly 10 years old! Organized some of them into
testsets just in case one breaks in the future, should make it easier to
find the problem.
---------
Co-authored-by: Simeon David Schaub <simeon@schaub.rocks>
* fix #45494, error in ssa conversion with complex type decl (#55744)
We were missing a call to `renumber-assigned-ssavalues` in the case
where the declared type is used to assert the type of a value taken from
a closure box.
* Revert "Avoid materializing arrays in bidiag matmul" (#55737)
Reverts JuliaLang/julia#55450. @jishnub suggested reverting this PR to
fix #55727.
* Add a docs section about loading/precomp/ttfx time tuning (#55569)
* Add compat entry for `Base.donotdelete` (#55773)
* REPL: precompile in its own module because Main is closed. Add check for unexpected errors. (#55759)
* Try to put back previously flakey addmul tests (#55775)
Partial revert of #50071, inspired by conversation in
https://github.com/JuliaLang/julia/issues/49966#issuecomment-2350935477
Ran the tests 100 times to make sure we're not putting back
something that's still flaky.
Closes #49966
* Print results of `runtests` with `printstyled` (#55780)
This ensures escape characters are used only if `stdout` can accept
them.
* move null check in `unsafe_convert` of RefValue (#55766)
LLVM can optimize out this check but our optimizer can't, so this leads
to smaller IR in most cases.
* Fix hang in tmerge_types_slow (#55757)
Fixes https://github.com/JuliaLang/julia/issues/55751
Co-authored-by: Jameson Nash <jameson@juliacomputing.com>
* trace-compile: color recompilation yellow (#55763)
Marks recompilation of a method that produced a `precompile` statement
as yellow, or if color isn't supported adds a trailing comment: `#
recompilation`.
The coloring matches the `@time_imports` coloring. i.e. an excerpt of
```
% ./julia --start=no --trace-compile=stderr --trace-compile-timing -e "using InteractiveUtils; @time @time_imports using Plots"
```

* Use PrecompileTools mechanics to compile REPL (#55782)
Fixes https://github.com/JuliaLang/julia/issues/55778
Based on discussion here
https://github.com/JuliaLang/julia/issues/55778#issuecomment-2352428043
With this `?reinterpret` feels instant, with only these precompiles at
the start.
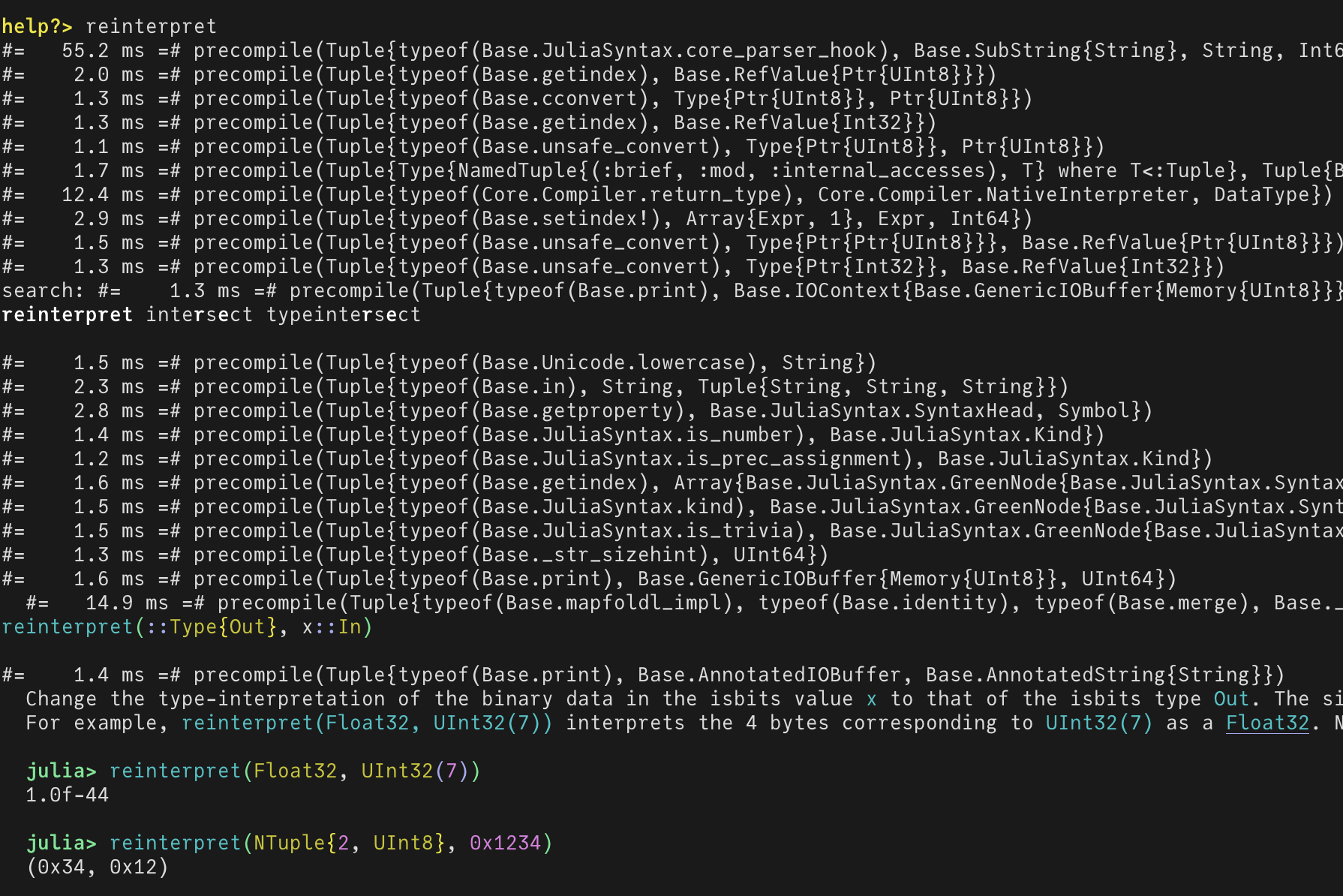
* use `inferencebarrier` instead of `invokelatest` for 1-arg `@assert` (#55783)
This version would be better as per this comment:
<https://github.com/JuliaLang/julia/pull/55739#pullrequestreview-2304360447>
I confirmed this still allows us to avoid invalidations reported at
JuliaLang/julia#55583.
* Inline statically known method errors. (#54972)
This replaces the `Expr(:call, ...)` with a call of a new builtin
`Core.throw_methoderror`
This is useful because it makes very clear if something is a static
method error or a plain dynamic dispatch that always errors.
Tools such as AllocCheck or juliac can notice that this is not a genuine
dynamic dispatch, and prevent it from becoming a false positive
compile-time error.
Dependent on https://github.com/JuliaLang/julia/pull/55705
---------
Co-authored-by: Cody Tapscott <topolarity@tapscott.me>
* Fix shell `cd` error when working dir has been deleted (#41244)
root cause:
if current dir has been deleted, then pwd() will throw an IOError:
pwd(): no such file or directory (ENOENT)
---------
Co-authored-by: Ian Butterworth <i.r.butterworth@gmail.com>
* codegen: fix bits compare for UnionAll (#55770)
Fixes #55768 in two parts: one is making the type computation in
emit_bits_compare agree with the parent function and two is not using
the optimized egal code for UnionAll kinds, which is different from how
the egal code itself works for kinds.
* use libuv to measure maxrss (#55806)
Libuv has a wrapper around rusage on Unix (and its equivalent on
Windows).
We should probably use it.
* REPL: use atreplinit to change the active module during precompilation (#55805)
* 🤖 [master] Bump the Pkg stdlib from 299a35610 to 308f9d32f (#55808)
* Improve codegen for `Core.throw_methoderror` and `Core.current_scope` (#55803)
This slightly improves our (LLVM) codegen for `Core.throw_methoderror`
and `Core.current_scope`
```julia
julia> foo() = Core.current_scope()
julia> bar() = Core.throw_methoderror(+, nothing)
```
Before:
```llvm
; Function Signature: foo()
define nonnull ptr @julia_foo_2488() #0 {
top:
%0 = call ptr @jl_get_builtin_fptr(ptr nonnull @"+Core.#current_scope#2491.jit")
%Builtin_ret = call nonnull ptr %0(ptr nonnull @"jl_global#2492.jit", ptr null, i32 0)
ret ptr %Builtin_ret
}
; Function Signature: bar()
define void @julia_bar_589() #0 {
top:
%jlcallframe1 = alloca [2 x ptr], align 8
%0 = call ptr @jl_get_builtin_fptr(ptr nonnull @"+Core.#throw_methoderror#591.jit")
%jl_nothing = load ptr, ptr @jl_nothing, align 8
store ptr @"jl_global#593.jit", ptr %jlcallframe1, align 8
%1 = getelementptr inbounds ptr, ptr %jlcallframe1, i64 1
store ptr %jl_nothing, ptr %1, align 8
%Builtin_ret = call nonnull ptr %0(ptr nonnull @"jl_global#592.jit", ptr nonnull %jlcallframe1, i32 2)
call void @llvm.trap()
unreachable
}
```
After:
```llvm
; Function Signature: foo()
define nonnull ptr @julia_foo_713() #0 {
top:
%thread_ptr = call ptr asm "movq %fs:0, $0", "=r"() #5
%tls_ppgcstack = getelementptr inbounds i8, ptr %thread_ptr, i64 -8
%tls_pgcstack = load ptr, ptr %tls_ppgcstack, align 8
%current_scope = getelementptr inbounds i8, ptr %tls_pgcstack, i64 -72
%0 = load ptr, ptr %current_scope, align 8
ret ptr %0
}
; Function Signature: bar()
define void @julia_bar_1581() #0 {
top:
%jlcallframe1 = alloca [2 x ptr], align 8
%jl_nothing = load ptr, ptr @jl_nothing, align 8
store ptr @"jl_global#1583.jit", ptr %jlcallframe1, align 8
%0 = getelementptr inbounds ptr, ptr %jlcallframe1, i64 1
store ptr %jl_nothing, ptr %0, align 8
%jl_f_throw_methoderror_ret = call nonnull ptr @jl_f_throw_methoderror(ptr null, ptr nonnull %jlcallframe1, i32 2)
call void @llvm.trap()
unreachable
}
```
* a minor improvement for EA-based `:effect_free`-ness refinement (#55796)
* fix #52986, regression in `@doc` of macro without REPL loaded (#55795)
fix #52986
* Assume that docstring code with no lang is julia (#55465)
* Broadcast binary ops involving strided triangular (#55798)
Currently, we evaluate expressions like `(A::UpperTriangular) +
(B::UpperTriangular)` using broadcasting if both `A` and `B` have
strided parents, and forward the summation to the parents otherwise.
This PR changes this to use broadcasting if either of the two has a
strided parent. This avoids accessing the parent corresponding to the
structural zero elements, as the index might not be initialized.
Fixes https://github.com/JuliaLang/julia/issues/55590
This isn't a general fix, as we still sum the parents if neither is
strided. However, it will address common cases.
This also improves performance, as we only need to loop over one half:
```julia
julia> using LinearAlgebra
julia> U = UpperTriangular(zeros(100,100));
julia> B = Bidiagonal(zeros(100), zeros(99), :U);
julia> @btime $U + $B;
35.530 μs (4 allocations: 78.22 KiB) # nightly
13.441 μs (4 allocations: 78.22 KiB) # This PR
```
* Reland " Avoid materializing arrays in bidiag matmul #55450" (#55777)
This relands #55450 and adds tests for the failing case noted in
https://github.com/JuliaLang/julia/issues/55727. The `addmul` tests that
were failing earlier pass with this change.
The issue in the earlier PR was that we were not exiting quickly for
`iszero(alpha)` in `_bibimul!` for small matrices, and were computing
the result as `C .= A * B * alpha + C * beta`. The problem with this is
that if `A * B` contains `NaN`s, this propagates to `C` even if `alpha
=== 0.0`. This is fixed now, and the result is only computed if
`!iszero(alpha)`.
* move the test case added in #50174 to test/core.jl (#55811)
Also renames the name of the test function to avoid name collision.
* [Random] Avoid conversion to `Float32` in `Float16` sampler (#55819)
* simplify the fields of `UnionSplitInfo` (#55815)
xref:
<https://github.com/JuliaLang/julia/pull/54972#discussion_r1766187771>
* Add errorhint for nonexisting fields and properties (#55165)
I played a bit with error hints and crafted this:
```julia
julia> (1+2im).real
ERROR: FieldError: type Complex has no field real, available fields: `re`, `im`
julia> nothing.xy
ERROR: FieldError: type Nothing has no field xy; Nothing has no fields at all.
julia> svd(rand(2,2)).VV
ERROR: FieldError: type SVD has no field VV, available fields: `U`, `S`, `Vt`
Available properties: `V`
```
---------
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
* Improve printing of several arguments (#55754)
Following a discussion on
[Discourse](https://discourse.julialang.org/t/string-optimisation-in-julia/119301/10?u=gdalle),
this PR tries to improve `print` (and variants) for more than one
argument.
The idea is that `for` is type-unstable over the tuple `args`, while
`foreach` unrolls.
---------
Co-authored-by: Steven G. Johnson <stevenj@mit.edu>
* Markdown: support `parse(::AbstractString)` (#55747)
`Markdown.parse` is documented to accept `AbstractString` but it was
implemented by calling `IOBuffer` on the string argument. `IOBuffer`,
however, is documented only for `String` arguments.
This commit changes the current `parse(::AbstractString)` to
`parse(::String)` and implements `parse(::AbstractString)` by converting
the argument to `String`.
Now, even `LazyString`s can be parsed to Markdown representation.
Fixes #55732
* better error for esc outside of macro expansion (#55797)
fixes #55788
---------
Co-authored-by: Jeff Bezanson <jeff.bezanson@gmail.com>
* allow kronecker product between recursive triangular matrices (#55527)
Using the recently introduced recursive `zero` I can remove the
specialization to `<:Number` as @dkarrasch wanted to do in #54413.
---------
Co-authored-by: Jishnu Bhattacharya <jishnub.github@gmail.com>
* [Dates] Make test more robust against non-UTC timezones (#55829)
`%M` is the format specifier for the minutes, not the month (which
should be `%m`), and it was used twice.
Also, on macOS `Libc.strptime` internally calls `mktime` which depends
on the local timezone. We now temporarily set `TZ=UTC` to avoid
depending on the local timezone.
Fix #55827.
* 🤖 [master] Bump the Pkg stdlib from 308f9d32f to ef9f76c17 (#55838)
* lmul!/rmul! for banded matrices (#55823)
This adds fast methods for `lmul!` and `rmul!` between banded matrices
and numbers.
Performance impact:
```julia
julia> T = Tridiagonal(rand(999), rand(1000), rand(999));
julia> @btime rmul!($T, 0.2);
4.686 ms (0 allocations: 0 bytes) # nightly v"1.12.0-DEV.1225"
669.355 ns (0 allocations: 0 bytes) # this PR
```
* Specialize indexing triangular matrices with BandIndex (#55644)
With this, certain indexing operations involving a `BandIndex` may be
evaluated as constants. This isn't used directly presently, but might
allow for more performant broadcasting in the future.
With this,
```julia
julia> n = 3; T = Tridiagonal(rand(n-1), rand(n), rand(n-1));
julia> @code_warntype ((T,j) -> UpperTriangular(T)[LinearAlgebra.BandIndex(2,j)])(T, 1)
MethodInstance for (::var"#17#18")(::Tridiagonal{Float64, Vector{Float64}}, ::Int64)
from (::var"#17#18")(T, j) @ Main REPL[12]:1
Arguments
#self#::Core.Const(var"#17#18"())
T::Tridiagonal{Float64, Vector{Float64}}
j::Int64
Body::Float64
1 ─ %1 = Main.UpperTriangular(T)::UpperTriangular{Float64, Tridiagonal{Float64, Vector{Float64}}}
│ %2 = LinearAlgebra.BandIndex::Core.Const(LinearAlgebra.BandIndex)
│ %3 = (%2)(2, j)::Core.PartialStruct(LinearAlgebra.BandIndex, Any[Core.Const(2), Int64])
│ %4 = Base.getindex(%1, %3)::Core.Const(0.0)
└── return %4
```
The indexing operation may be evaluated at compile-time, as the band
index is constant-propagated.
* Replace regex package module checks with actual code checks (#55824)
Fixes https://github.com/JuliaLang/julia/issues/55792
Replaces https://github.com/JuliaLang/julia/pull/55822
Improves what https://github.com/JuliaLang/julia/pull/51635 was trying
to do
i.e.
```
ERROR: LoadError: `using/import Printf` outside of a Module detected. Importing a package outside of a module is not allowed during package precompilation.
```
* fall back to slower stat filesize if optimized filesize fails (#55641)
* Use "index" instead of "subscript" to refer to indexing in performance tips (#55846)
* privatize annotated string API, take two (#55845)
https://github.com/JuliaLang/julia/pull/55453 is stuck on StyledStrings
and Base documentation being entangled and there isn't a good way to
have the documentation of Base types / methods live in an stdlib. This
is a stop gap solution to finally be able to move forwards with 1.11.
* 🤖 [master] Bump the Downloads stdlib from 1061ecc to 89d3c7d (#55854)
Stdlib: Downloads
URL: https://github.com/JuliaLang/Downloads.jl.git
Stdlib branch: master
Julia branch: master
Old commit: 1061ecc
New commit: 89d3c7d
Julia version: 1.12.0-DEV
Downloads version: 1.6.0(It's okay that it doesn't match)
Bump invoked by: @KristofferC
Powered by:
[BumpStdlibs.jl](https://github.com/JuliaLang/BumpStdlibs.jl)
Diff:
https://github.com/JuliaLang/Downloads.jl/compare/1061ecc377a053fce0df94e1a19e5260f7c030f5...89d3c7dded535a77551e763a437a6d31e4d9bf84
```
$ git log --oneline 1061ecc..89d3c7d
89d3c7d fix cancelling upload requests (#259)
df33406 gracefully cancel a request (#256)
```
Co-authored-by: Dilum Aluthge <dilum@aluthge.com>
* docs: Small edits to noteworthy differences (#55852)
- The first line edit changes it so that the Julia example goes first,
not the Python example, keeping with the general flow of the lines
above.
- The second adds a "the" that is missing.
* Add filesystem func to transform a path to a URI (#55454)
In a few places across Base and the stdlib, we emit paths that we like
people to be able to click on in their terminal and editor. Up to this
point, we have relied on auto-filepath detection, but this does not
allow for alternative link text, such as contracted paths.
Doing so (via OSC 8 terminal links for example) requires filepath URI
encoding.
This functionality was previously part of a PR modifying stacktrace
printing (#51816), but after that became held up for unrelated reasons
and another PR appeared that would benefit from this utility (#55335),
I've split out this functionality so it can be used before the
stacktrace printing PR is resolved.
* constrain the path argument of `include` functions to `AbstractString` (#55466)
Each `Module` defined with `module` automatically gets an `include`
function with two methods. Each of those two methods takes a file path
as its last argument. Even though the path argument is unconstrained by
dispatch, it's documented as constrained with `::AbstractString`:
https://docs.julialang.org/en/v1.11-dev/base/base/#include
Furthermore, I think that any invocation of `include` with a
non-`AbstractString` path will necessarily throw a `MethodError`
eventually. Thus this change should be harmless.
Adding the type constraint to the path argument is an improvement
because any possible exception would be thrown earlier than before.
Apart from modules defined with `module`, the same issue is present with
the anonymous modules created by `evalfile`, which is also addressed.
Sidenote: `evalfile` seems to be completely untested apart from the test
added here.
Co-authored-by: Florian <florian.atteneder@gmail.com>
* Mmap: fix grow! for non file IOs (#55849)
Fixes https://github.com/JuliaLang/julia/issues/54203
Requires #55641
Based on
https://github.com/JuliaLang/julia/pull/55641#issuecomment-2334162489
cc. @JakeZw @ronisbr
---------
Co-authored-by: Jameson Nash <vtjnash@gmail.com>
* codegen: split gc roots from other bits on stack (#55767)
In order to help avoid memory provenance issues, and better utilize
stack space (somewhat), and use FCA less, change the preferred
representation of an immutable object to be a pair of
`<packed-data,roots>` values. This packing requires some care at the
boundaries and if the expected field alignment exceeds that of a
pointer. The change is expected to eventually make codegen more flexible
at representing unions of values with both bits and pointer regions.
Eventually we can also have someone improve the late-gc-lowering pass to
take advantage of this increased information accuracy, but currently it
will not be any better than before at laying out the frame.
* Refactoring to be considered before adding MMTk
* Removing jl_gc_notify_image_load, since it's a new function and not part of the refactoring
* Moving gc_enable code to gc-common.c
* Addressing PR comments
* Push resolution of merge conflict
* Removing jl_gc_mark_queue_obj_explicit extern definition from scheduler.c
* Don't need the getter function since it's possible to use jl_small_typeof directly
* WIP: Adding support for MMTk/Immix
* Refactoring to be considered before adding MMTk
* Adding fastpath allocation
* Fixing removed newlines
* Refactoring to be considered before adding MMTk
* Adding a few comments; Moving some functions to be closer together
* Fixing merge conflicts
* Applying changes from refactoring before adding MMTk
* Update TaskLocalRNG docstring according to #49110 (#55863)
Since #49110, which is included in 1.10 and 1.11, spawning a task no
longer advances the parent task's RNG state, so this statement in the
docs was incorrect.
* Root globals in toplevel exprs (#54433)
This fixes #54422, the code here assumes that top level exprs are always
rooted, but I don't see that referenced anywhere else, or guaranteed, so
conservatively always root objects that show up in code.
* codegen: fix alignment typos (#55880)
So easy to type jl_datatype_align to get the natural alignment instead
of julia_alignment to get the actual alignment. This should fix the
Revise workload.
Change is visible with
```
julia> code_llvm(Random.XoshiroSimd.forkRand, (Random.TaskLocalRNG, Base.Val{8}))
```
* Fix some corner cases of `isapprox` with unsigned integers (#55828)
* 🤖 [master] Bump the Pkg stdlib from ef9f76c17 to 51d4910c1 (#55896)
* Profile: fix order of fields in heapsnapshot & improve formatting (#55890)
* Profile: Improve generation of clickable terminal links (#55857)
* inference: add missing `TypeVar` handling for `instanceof_tfunc` (#55884)
I thought these sort of problems had been addressed by d60f92c, but it
seems some were missed. Specifically, `t.a` and `t.b` from `t::Union`
could be `TypeVar`, and if they are passed to a subroutine or recursed
without being unwrapped or rewrapped, errors like JuliaLang/julia#55882
could occur.
This commit resolves the issue by calling `unwraptv` in the `Union`
handling within `instanceof_tfunc`. I also found a similar issue inside
`nfields_tfunc`, so that has also been fixed, and test cases have been
added. While I haven't been able to make up a test case specifically for
the fix in `instanceof_tfunc`, I have confirmed that this commit
certainly fixes the issue reported in JuliaLang/julia#55882.
- fixes JuliaLang/julia#55882
* Install terminfo data under /usr/share/julia (#55881)
Just like all other libraries, we don't want internal Julia files to
mess with system files.
Introduced by https://github.com/JuliaLang/julia/pull/55411.
* expose metric to report reasons why full GCs were triggered (#55826)
Additional GC observability tool.
This will help us to diagnose why some of our servers are triggering so
many full GCs in certain circumstances.
* Revert "Improve printing of several arguments" (#55894)
Reverts JuliaLang/julia#55754 as it overrode some performance heuristics
which appeared to be giving a significant gain/loss in performance:
Closes https://github.com/JuliaLang/julia/issues/55893
* Do not trigger deprecation warnings in `Test.detect_ambiguities` and `Test.detect_unbound_args` (#55869)
#55868
* do not intentionally suppress errors in precompile script from being reported or failing the result (#55909)
I was slightly annoying that the build was set up to succeed if this
step failed, so I removed the error suppression and fixed up the script
slightly
* Remove eigvecs method for SymTridiagonal (#55903)
The fallback method does the same, so this specialized method isn't
necessary
* add --trim option for generating smaller binaries (#55047)
This adds a command line option `--trim` that builds images where code
is only included if it is statically reachable from methods marked using
the new function `entrypoint`. Compile-time errors are given for call
sites that are too dynamic to allow trimming the call graph (however
there is an `unsafe` option if you want to try building anyway to see
what happens).
The PR has two other components. One is changes to Base that generally
allow more code to be compiled in this mode. These changes will either
be merged in separate PRs or moved to a separate part of the workflow
(where we will build a custom system image for this purpose). The branch
is set up this way to make it easy to check out and try the
functionality.
The other component is everything in the `juliac/` directory, which
implements a compiler driver script based on this new option, along with
some examples and tests. This will eventually become a package "app"
that depends on PackageCompiler and provides a CLI for all of this
stuff, so it will not be merged here. To try an example:
```
julia contrib/juliac.jl --output-exe hello --trim test/trimming/hello.jl
```
When stripped the resulting executable is currently about 900kb on my
machine.
Also includes a lot of work by @topolarity
---------
Co-authored-by: Gabriel Baraldi <baraldigabriel@gmail.com>
Co-authored-by: Tim Holy <tim.holy@gmail.com>
Co-authored-by: Cody Tapscott <topolarity@tapscott.me>
* fix rawbigints OOB issues (#55917)
Fixes issues introduced in #50691 and found in #55906:
* use `@inbounds` and `@boundscheck` macros in rawbigints, for catching
OOB with `--check-bounds=yes`
* fix OOB in `truncate`
* prevent loading other extensions when precompiling an extension (#55589)
The current way of loading extensions when precompiling an extension
very easily leads to cycles. For example, if you have more than one
extension and you happen to transitively depend on the triggers of one
of your extensions you will immediately hit a cycle where the extensions
will try to load each other indefinitely. This is an issue because you
cannot directly influence your transitive dependency graph so from this
p.o.v the current system of loading extension is "unsound".
The test added here checks this scenario and we can now precompile and
load it without any warnings or issues.
Would have made https://github.com/JuliaLang/julia/issues/55517 a non
issue.
Fixes https://github.com/JuliaLang/julia/issues/55557
---------
Co-authored-by: KristofferC <kristoffer.carlsson@juliacomputing.com>
* TOML: Avoid type-pirating `Base.TOML.Parser` (#55892)
Since stdlibs can be duplicated but Base never is, `Base.require_stdlib`
makes type piracy even more complicated than it normally would be.
To adapt, this changes `TOML.Parser` to be a type defined by the TOML
stdlib, so that we can define methods on it without committing
type-piracy and avoid problems like Pkg.jl#4017
Resolves
https://github.com/JuliaLang/Pkg.jl/issues/4017#issuecomment-2377589989
* [FileWatching] fix PollingFileWatcher design and add workaround for a stat bug
What started as an innocent fix for a stat bug on Apple (#48667) turned
into a full blown investigation into the design problems with the libuv
backend for PollingFileWatcher, and writing my own implementation of it
instead which could avoid those singled-threaded concurrency bugs.
* [FileWatching] fix FileMonitor similarly and improve pidfile reliability
Previously pidfile used the same poll_interval as sleep to detect if
this code made any concurrency mistakes, but we do not really need to do
that once FileMonitor is fixed to be reliable in the presence of
parallel concurrency (instead of using watch_file).
* [FileWatching] reorganize file and add docs
* Add `--trace-dispatch` (#55848)
* relocation: account for trailing path separator in depot paths (#55355)
Fixes #55340
* change compiler to be stackless (#55575)
This change ensures the compiler uses very little stack, making it
compatible with running on any arbitrary system stack size and depths
much more reliably. It also could be further modified now to easily add
various forms of pause-able/resumable inference, since there is no
implicit state on the stack--everything is local and explicit now.
Whereas before, less than 900 frames would crash in less than a second:
```
$ time ./julia -e 'f(::Val{N}) where {N} = N <= 0 ? 0 : f(Val(N - 1)); f(Val(1000))'
Warning: detected a stack overflow; program state may be corrupted, so further execution might be unreliable.
Internal error: during type inference of
f(Base.Val{1000})
Encountered stack overflow.
This might be caused by recursion over very long tuples or argument lists.
[23763] signal 6: Abort trap: 6
in expression starting at none:1
__pthread_kill at /usr/lib/system/libsystem_kernel.dylib (unknown line)
Allocations: 1 (Pool: 1; Big: 0); GC: 0
Abort trap: 6
real 0m0.233s
user 0m0.165s
sys 0m0.049s
````
Now: it is effectively unlimited, as long as you are willing to wait for
it:
```
$ time ./julia -e 'f(::Val{N}) where {N} = N <= 0 ? 0 : f(Val(N - 1)); f(Val(50000))'
info: inference of f(Base.Val{50000}) from f(Base.Val{N}) where {N} exceeding 2500 frames (may be slow).
info: inference of f(Base.Val{50000}) from f(Base.Val{N}) where {N} exceeding 5000 frames (may be slow).
info: inference of f(Base.Val{50000}) from f(Base.Val{N}) where {N} exceeding 10000 frames (may be slow).
info: inference of f(Base.Val{50000}) from f(Base.Val{N}) where {N} exceeding 20000 frames (may be slow).
info: inference of f(Base.Val{50000}) from f(Base.Val{N}) where {N} exceeding 40000 frames (may be slow).
real 7m4.988s
$ time ./julia -e 'f(::Val{N}) where {N} = N <= 0 ? 0 : f(Val(N - 1)); f(Val(1000))'
real 0m0.214s
user 0m0.164s
sys 0m0.044s
$ time ./julia -e '@noinline f(::Val{N}) where {N} = N <= 0 ? GC.safepoint() : f(Val(N - 1)); f(Val(5000))'
info: inference of f(Base.Val{5000}) from f(Base.Val{N}) where {N} exceeding 2500 frames (may be slow).
info: inference of f(Base.Val{5000}) from f(Base.Val{N}) where {N} exceeding 5000 frames (may be slow).
real 0m8.609s
user 0m8.358s
sys 0m0.240s
```
* optimizer: simplify the finalizer inlining pass a bit (#55934)
Minor adjustments have been made to the algorithm of the finalizer
inlining pass. Previously, it required that the finalizer registration
dominate all uses, but this is not always necessary as far as the
finalizer inlining point dominates all the uses. So the check has been
relaxed. Other minor fixes have been made as well, but their importance
is low.
* Limit `@inbounds` to indexing in the dual-iterator branch in `copyto_unaliased!` (#55919)
This simplifies the `copyto_unalised!` implementation where the source
and destination have different `IndexStyle`s, and limits the `@inbounds`
to only the indexing operation. In particular, the iteration over
`eachindex(dest)` is not marked as `@inbounds` anymore. This seems to
help with performance when the destination uses Cartesian indexing.
Reduced implementation of the branch:
```julia
function copyto_proposed!(dest, src)
axes(dest) == axes(src) || throw(ArgumentError("incompatible sizes"))
iterdest, itersrc = eachindex(dest), eachindex(src)
for (destind, srcind) in zip(iterdest, itersrc)
@inbounds dest[destind] = src[srcind]
end
dest
end
function copyto_current!(dest, src)
axes(dest) == axes(src) || throw(ArgumentError("incompatible sizes"))
iterdest, itersrc = eachindex(dest), eachindex(src)
ret = iterate(iterdest)
@inbounds for a in src
idx, state = ret::NTuple{2,Any}
dest[idx] = a
ret = iterate(iterdest, state)
end
dest
end
function copyto_current_limitinbounds!(dest, src)
axes(dest) == axes(src) || throw(ArgumentError("incompatible sizes"))
iterdest, itersrc = eachindex(dest), eachindex(src)
ret = iterate(iterdest)
for isrc in itersrc
idx, state = ret::NTuple{2,Any}
@inbounds dest[idx] = src[isrc]
ret = iterate(iterdest, state)
end
dest
end
```
```julia
julia> a = zeros(40000,4000); b = rand(size(a)...);
julia> av = view(a, UnitRange.(axes(a))...);
julia> @btime copyto_current!($av, $b);
617.704 ms (0 allocations: 0 bytes)
julia> @btime copyto_current_limitinbounds!($av, $b);
304.146 ms (0 allocations: 0 bytes)
julia> @btime copyto_proposed!($av, $b);
240.217 ms (0 allocations: 0 bytes)
julia> versioninfo()
Julia Version 1.12.0-DEV.1260
Commit 4a4ca9c8152 (2024-09-28 01:49 UTC)
Build Info:
Official https://julialang.org release
Platform Info:
OS: Linux (x86_64-linux-gnu)
CPU: 8 × Intel(R) Core(TM) i5-10310U CPU @ 1.70GHz
WORD_SIZE: 64
LLVM: libLLVM-18.1.7 (ORCJIT, skylake)
Threads: 1 default, 0 interactive, 1 GC (on 8 virtual cores)
Environment:
JULIA_EDITOR = subl
```
I'm not quite certain why the proposed implementation here
(`copyto_proposed!`) is even faster than
`copyto_current_limitinbounds!`. In any case, `copyto_proposed!` is
easier to read, so I'm not complaining.
This fixes https://github.com/JuliaLang/julia/issues/53158
* Strong zero in Diagonal triple multiplication (#55927)
Currently, triple multiplication with a `LinearAlgebra.BandedMatrix`
sandwiched between two `Diagonal`s isn't associative, as this is
implemented using broadcasting, which doesn't assume a strong zero,
whereas the two-term matrix multiplication does.
```julia
julia> D = Diagonal(StepRangeLen(NaN, 0, 3));
julia> B = Bidiagonal(1:3, 1:2, :U);
julia> D * B * D
3×3 Matrix{Float64}:
NaN NaN NaN
NaN NaN NaN
NaN NaN NaN
julia> (D * B) * D
3×3 Bidiagonal{Float64, Vector{Float64}}:
NaN NaN ⋅
⋅ NaN NaN
⋅ ⋅ NaN
julia> D * (B * D)
3×3 Bidiagonal{Float64, Vector{Float64}}:
NaN NaN ⋅
⋅ NaN NaN
⋅ ⋅ NaN
```
This PR ensures that the 3-term multiplication is evaluated as a
sequence of two-term multiplications, which fixes this issue. This also
improves performance, as only the bands need to be evaluated now.
```julia
julia> D = Diagonal(1:1000); B = Bidiagonal(1:1000, 1:999, :U);
julia> @btime $D * $B * $D;
656.364 μs (11 allocations: 7.63 MiB) # v"1.12.0-DEV.1262"
2.483 μs (12 allocations: 31.50 KiB) # This PR
```
* Fix dispatch on `alg` in Float16 Hermitian eigen (#55928)
Currently,
```julia
julia> using LinearAlgebra
julia> A = Hermitian(reshape(Float16[1:16;], 4, 4));
julia> eigen(A).values |> typeof
Vector{Float16} (alias for Array{Float16, 1})
julia> eigen(A, LinearAlgebra.QRIteration()).values |> typeof
Vector{Float32} (alias for Array{Float32, 1})
```
This PR moves the specialization on the `eltype` to an internal method,
so that firstly all `alg`s dispatch to that method, and secondly, there
are no ambiguities introduce by specializing the top-level `eigen`. The
latter currently causes test failures in `StaticArrays`
(https://github.com/JuliaArrays/StaticArrays.jl/actions/runs/11092206012/job/30816955210?pr=1279),
and should be fixed by this PR.
* Remove specialized `ishermitian` method for `Diagonal{<:Real}` (#55948)
The fallback method for `Diagonal{<:Number}` handles this already by
checking that the `diag` is real, so we don't need this additional
specialization.
* Fix logic in `?` docstring example (#55945)
* fix `unwrap_macrocalls` (#55950)
The implementation of `unwrap_macrocalls` has assumed that what
`:macrocall` wraps is always an `Expr` object, but that is not
necessarily correct:
```julia
julia> Base.@assume_effects :nothrow @show 42
ERROR: LoadError: TypeError: in typeassert, expected Expr, got a value of type Int64
Stacktrace:
[1] unwrap_macrocalls(ex::Expr)
@ Base ./expr.jl:906
[2] var"@assume_effects"(__source__::LineNumberNode, __module__::Module, args::Vararg{Any})
@ Base ./expr.jl:756
in expression starting at REPL[1]:1
```
This commit addresses this issue.
* make faster BigFloats (#55906)
We can coalesce the two required allocations for the MFPR BigFloat API
design into one allocation, hopefully giving a easy performance boost.
It would have been slightly easier and more efficient if MPFR BigFloat
was already a VLA instead of containing a pointer here, but that does
not prevent the optimization.
* Add propagate_inbounds_meta to atomic genericmemory ops (#55902)
`memoryref(mem, i)` will otherwise emit a boundscheck.
```
; │ @ /home/vchuravy/WorkstealingQueues/src/CLL.jl:53 within `setindex_atomic!` @ genericmemory.jl:329
; │┌ @ boot.jl:545 within `memoryref`
%ptls_field = getelementptr inbounds i8, ptr %tls_pgcstack, i64 16
%ptls_load = load ptr, ptr %ptls_field, align 8
%"box::GenericMemoryRef" = call noalias nonnull align 8 dereferenceable(32) ptr @ijl_gc_small_alloc(ptr %ptls_load, i32 552, i32 32, i64 23456076646928) #9
%"box::GenericMemoryRef.tag_addr" = getelementptr inbounds i64, ptr %"box::GenericMemoryRef", i64 -1
store atomic i64 23456076646928, ptr %"box::GenericMemoryRef.tag_addr" unordered, align 8
store ptr %memoryref_data, ptr %"box::GenericMemoryRef", align 8
%.repack8 = getelementptr inbounds { ptr, ptr }, ptr %"box::GenericMemoryRef", i64 0, i32 1
store ptr %memoryref_mem, ptr %.repack8, align 8
call void @ijl_bounds_error_int(ptr nonnull %"box::GenericMemoryRef", i64 %7)
unreachable
```
For the Julia code:
```julia
function Base.setindex_atomic!(buf::WSBuffer{T}, order::Symbol, val::T, idx::Int64) where T
@inbounds Base.setindex_atomic!(buf.buffer, order, val,((idx - 1) & buf.mask) + 1)
end
```
from
https://github.com/gbaraldi/WorkstealingQueues.jl/blob/0ebc57237cf0c90feedf99e4338577d04b67805b/src/CLL.jl#L41
* fix rounding mode in construction of `BigFloat` from pi (#55911)
The default argument of the method was outdated, reading the global
default rounding directly, bypassing the `ScopedValue` stuff.
* fix `nonsetable_type_hint_handler` (#55962)
The current implementation is wrong, causing it to display inappropriate
hints like the following:
```julia
julia> s = Some("foo");
julia> s[] = "bar"
ERROR: MethodError: no method matching setindex!(::Some{String}, ::String)
The function `setindex!` exists, but no method is defined for this combination of argument types.
You attempted to index the type String, rather than an instance of the type. Make sure you create the type using its constructor: d = String([...]) rather than d = String
Stacktrace:
[1] top-level scope
@ REPL[2]:1
```
* REPL: make UndefVarError aware of imported modules (#55932)
* fix test/staged.jl (#55967)
In particular, the implementation of `overdub_generator54341` was
dangerous. This fixes it up.
* Explicitly store a module's location (#55963)
Revise wants to know what file a module's `module` definition is in.
Currently it does this by looking at the source location for the
implicitly generated `eval` method. This is terrible for two reasons:
1. The method may not exist if the module is a baremodule (which is not
particularly common, which is probably why we haven't seen it).
2. The fact that the implicitly generated `eval` method has this
location information is an implementation detail that I'd like to get
rid of (#55949).
This PR adds explicit file/line info to `Module`, so that Revise doesn't
have to use the hack anymore.
* mergewith: add single argument example to docstring (#55964)
I ran into this edge case. I though it should be documented.
---------
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
* [build] avoid libedit linkage and align libccalllazy* SONAMEs (#55968)
While building the 1.11.0-rc4 in Homebrew[^1] in preparation for 1.11.0
release (and to confirm Sequoia successfully builds) I noticed some odd
linkage for our Linux builds, which included of:
1. LLVM libraries were linking to `libedit.so`, e.g.
```
Dynamic Section:
NEEDED libedit.so.0
NEEDED libz.so.1
NEEDED libzstd.so.1
NEEDED libstdc++.so.6
NEEDED libm.so.6
NEEDED libgcc_s.so.1
NEEDED libc.so.6
NEEDED ld-linux-x86-64.so.2
SONAME libLLVM-16jl.so
```
CMakeCache.txt showed
```
//Use libedit if available.
LLVM_ENABLE_LIBEDIT:BOOL=ON
```
Which might be overriding `HAVE_LIBEDIT` at
https://github.com/JuliaLang/llvm-project/blob/julia-release/16.x/llvm/cmake/config-ix.cmake#L222-L225.
So just added `LLVM_ENABLE_LIBEDIT`
2. Wasn't sure if there was a reason for this but `libccalllazy*` had
mismatched SONAME:
```console
❯ objdump -p lib/julia/libccalllazy* | rg '\.so'
lib/julia/libccalllazybar.so: file format elf64-x86-64
NEEDED ccalllazyfoo.so
SONAME ccalllazybar.so
lib/julia/libccalllazyfoo.so: file format elf64-x86-64
SONAME ccalllazyfoo.so
```
Modifying this, but can drop if intentional.
---
[^1]: https://github.com/Homebrew/homebrew-core/pull/192116
* Add missing `copy!(::AbstractMatrix, ::UniformScaling)` method (#55970)
Hi everyone! First PR to Julia here.
It was noticed in a Slack thread yesterday
that `copy!(A, I)` doesn't work, but `copyto!(A, I)` does. This PR adds
the missing method for `copy!(::AbstractMatrix, ::UniformScaling)`,
which simply defers to `copyto!`, and corresponding tests.
I added a `compat` notice for Julia 1.12.
---------
Co-authored-by: Lilith Orion Hafner <lilithhafner@gmail.com>
* Add forward progress update to NEWS.md (#54089)
Closes #40009 which was left open because of the needs news tag.
---------
Co-authored-by: Ian Butterworth <i.r.butterworth@gmail.com>
* Fix an intermittent test failure in `core` test (#55973)
The test wants to assert that `Module` is not resolved in `Main`, but
other tests do resolve this identifier, so the test can fail depending
on test order (and I've been seeing such failures on CI recently). Fix
that by running the test in a fresh subprocess.
* fix comma logic in time_print (#55977)
Minor formatting fix
* optimizer: fix up the inlining algorithm to use correct `nargs`/`isva` (#55976)
It appears that inlining.jl was not updated in JuliaLang/julia#54341.
Specifically, using `nargs`/`isva` from `mi.def::Method` in
`ir_prepare_inlining!` causes the following error to occur:
```julia
function generate_lambda_ex(world::UInt, source::LineNumberNode,
argnames, spnames, @nospecialize body)
stub = Core.GeneratedFunctionStub(identity, Core.svec(argnames...), Core.svec(spnames...))
return stub(world, source, body)
end
function overdubbee54341(a, b)
return a + b
end
const overdubee_codeinfo54341 = code_lowered(overdubbee54341, Tuple{Any, Any})[1]
function overdub_generator54341(world::UInt, source::LineNumberNode, selftype, fargtypes)
if length(fargtypes) != 2
return generate_lambda_ex(world, source,
(:overdub54341, :args), (), :(error("Wrong number of arguments")))
else
return copy(overdubee_codeinfo54341)
end
end
@eval function overdub54341(args...)
$(Expr(:meta, :generated, overdub_generator54341))
$(Expr(:meta, :generated_only))
end
topfunc(x) = overdub54341(x, 2)
```
```julia
julia> topfunc(1)
Internal error: during type inference of
topfunc(Int64)
Encountered unexpected error in runtime:
BoundsError(a=Array{Any, 1}(dims=(2,), mem=Memory{Any}(8, 0x10632e780)[SSAValue(2), SSAValue(3), #<null>, #<null>, #<null>, #<null>, #<null>, #<null>]), i=(3,))
throw_boundserror at ./essentials.jl:14
getindex at ./essentials.jl:909 [inlined]
ssa_substitute_op! at ./compiler/ssair/inlining.jl:1798
ssa_substitute_op! at ./compiler/ssair/inlining.jl:1852
ir_inline_item! at ./compiler/ssair/inlining.jl:386
...
```
This commit updates the abstract interpretation and inlining algorithm
to use the `nargs`/`isva` values held by `CodeInfo`. Similar
modifications have also been made to EscapeAnalysis.jl.
@nanosoldier `runbenchmarks("inference", vs=":master")`
* Add `.zed` directory to `.gitignore` (#55974)
Similar to the `vscode` config directory, we may ignore the `zed`
directory as well.
* typeintersect: reduce unneeded allocations from `merge_env`
`merge_env` and `final_merge_env` could be skipped
for emptiness test or if we know there's only 1 valid Union state.
* typeintersect: trunc env before nested `intersect_all` if valid.
This only covers the simplest cases. We might want a full dependence analysis and keep env length minimum in the future.
* `@time` actually fix time report commas & add tests (#55982)
https://github.com/JuliaLang/julia/pull/55977 looked simple but wasn't
quite right because of a bad pattern in the lock conflicts report
sect…
this replaces the previously remainder-based limiting of the random number which caused bias toward small numbers and excluded zero altogether by simple filtering as proposed frequently in kjur#221 and because the performance in most cases is actually faster than in the present implementation; also, an adaptation of swiftlang/swift#39143 has been considered but it performed significantly slower for large integers;
It's a while since I looked into this, but from what I recall the whole premise is to reduce bias below some threshold of insignificance, not to eliminate it completely. The description above could be clearer in this respect. The |
|
People need to realize that LLMs are not logic engines, they have no fact model, they just regurgitate information that has been fed to them. One can, at best, use them to determine whether you need to do further analysis to identify a bug. An LLM can not be used to identify a bug directly. One should also not be using an LLM to write a comment reviewing a pull request, as has clearly happened here. Furthermore, Daniel Lemire himself okayed this algorithm earlier in this pull request:
|
Two variants of the algorithm are described in the PR comment; one eliminates bias completely without rejection, but requiring a variable number of bits from the random source. The second variant reduces bias below a tunable significance threshold, in exchange for which we get to consume a fixed number of bits from the random source--this is highly desirable because it breaks any value dependency on the random stream, and allows vectorization and parallelization of bounded generation when using random sources that permit skipping (such as counter-based RNGs) |
Everyone knows that generating an unbiased random integer in a range 0 ..< upperBound, where upperBound is not a power of two, requires rejection sampling. What if I told you that Big Random Number has lied to us for decades, and we have been played for absolute fools?
Previously Swift used Lemire's "nearly divisionless" method (https://arxiv.org/abs/1805.10941) for this operation. This PR introduces a novel algorithm that:
Lemire interprets each word from the random source as a fixed-point number in [0, 1), multiplies by upperBound, and takes the floor. Up to this point, this is the algorithm suggested by Knuth in TAoCP vol 2, and as observed by Knuth, it is slightly biased. Lemire cleverly corrects this bias via rejection sampling, which requires one division in the general case (hence, "nearly divisionless").
Our new algorithm takes a different approach. Rather than using rejection sampling, we observe that the bias decreases exponentially in the number of bits used for the computation. In the limit we are interpreting the bitstream from the random source as a uniform real number r in [0, 1) and ⌊r * upperBound⌋ provides an unbiased sample in 0 ..< upperBound. The only challenge, then, is to know when we have computed enough bits of the product to know what the result is.
Observe that we can split the random stream at any bit position i, yielding r = r₀ + r₁ with r₀ a fixed-point number in [0,1) and 0 ≤ r₁ < 2⁻ⁱ. Further observe that:
The first term of this expression is just Knuth's biased sample, which is computed with just a full-width multiply.
If i > log₂(upperBound), both summands in the second term are smaller than 1, so the second term is either 0 or 1. Applying the bound on r₁, we see that if frac(r₀ * upperBound) <= 1 - upperBound * 2⁻ⁱ, the second term is necessarily zero, and the first term is the unbiased result. Happily, this is also a trivial computation on the low-order part of the full-width multiply.
If the test fails, we do not reject the sample, throwing away the bits we have already consumed from the random source; instead we increase i by a convenient amount, computing more bits of the product. This is the criticial improvement; while Lemire has a probability of 1/2 to reject for each word consumed in the worst case, we have a probability of terminating of 1/2 for each bit consumed. This reduces the worst-case expected number of random bits required from O(log₂(upperBound)) to log₂(upperBound) + O(1), which is optimal[1].
Of more practical interest, this new algorithm opens an intriguing possibility: we can compute just 64 extra bits, and have a probability of 1 - 2⁻⁶⁴ of terminating. This is so close to certainty that we can simply stop unconditionally without introducing any measurable bias (detecting any difference would require about 2¹²⁸ samples, which is prohibitive). This is a significant performance improvement for slow random generators, since it asymptotically reduces the number of bits required by a factor of two for bignums, while matching the expected number of bits required for smaller numbers. This is the algorithm implemented by this PR (the formally-uniform method is not much more complex to implement and is only a little bit slower, but there's no reason to do so).
More intriguing still, this algorithm can be made unconditional by removing the early out, so that every value computed requires word size + 64 bits from the stream, which breaks the loop-carried dependency for fast generators, unlocking vectorization and parallelization where it was previously impossible. This is an especially powerful advantage when paired with bitstream generators that allow skip-ahead such as counter-based generators or PCG.
Note that it is possible to employ Lemire's tighter early-out check that involves a division with this algorithm as well; this is beneficial in some cases when upperBound is a constant and the generator is slow, but we do not think it necessary with the new algorithm and other planned improvements.
[1] We can actually achieve log₂(upperBound) + ε for any ε > 0 by generating multiple random samples at once, but that is only of theoretical interest--it is still interesting, however, since I don't think anyone has described how to attain it previously.