arangoexport issues with exporting 25.6GB Database #3808
Comments
|
Just downloading it and taking a look. Will also have a look on the other questions you've posted on SO. |
|
First result of this effort: #3828 fix arangoimp. |
|
hm, Creating the authors collection with the limited resources of my workstation is taking a while now. db._query("FOR item IN RawSubReddits INSERT {_key: item.author, test: 'abc123' } INTO authors OPTIONS { ignoreErrors: true }") |
|
this is related to #3437 - I will close this as duplicate once the other questions have been solved. |
|
OK, Please note that the webinterface will be very resource intense to browse parts of this graph, until the release of ArangoDB 3.2.10, alternatively you can download: Please note that the following queries take a while to complete on this huge dataset, however they should complete sucessfully after some hours. We start the arangoimp to import our base dataset: We use arangosh to create the collections where our final data is going to live in: We fill the authors collection by simply ignoring any subsequently occuring duplicate authors; After the we have filled the second vertex collection (we will keep the imported collection as the first vertex collection) we have to calculate the edges. After the edge collection is filled (which may again take a while - we're talking about 40 million edges herer, right? - we create the graph description: We now can use the UI to browse the graphs, or use AQL queries to browse the graph. Lets pick the sort of random first author from that list: We identified an author, and now run a graph query for him: One of the resulting paths looks like that: |
|
Thank you so much for that explanation and for the help! I copied over the js file and started the import (--threads 5). The first 20% finished in about 5 mins. The next 20% finished 10mins later and the last 60% took over two hours. So there seems to be some slight exponential slow down. But that might be normal, idk. Something I noticed is that all of my physical RAM was used (32g) during the import (which makes sense) But hardly any of my virtual RAM was used.
|

|
Hi, |
|
@dothebart - The fact that your solution incurs the potential disadvantages here of md5 seems to point to an easily-fixed omission from AQL: support for base64 encoding. The main potential disadvantage of md5 here is that it is, by design, not readily invertible. Also, a fast implementation of base64 should be faster. Please note that I am not suggesting that using md5 here is wrong or necessarily ill-advised. Indeed, there may be some circumstances where it is entirely appropriate. However, if a user wanted ._key values to be “transparent” or “invertible”, it seems that the existing repertoire of AQL functions is inadequate. base64 is by all accounts the way to go, and of course one would also want a companion function to perform the inversion when possible. If you agree, what would be the best way to ensure the enhancement is “fast-tracked”? |
|
Hi, However, If you now get an en/decode of arbitrary (possibly broken or invalid) data, imagine a string containing a \0 halft ways through, then you have put something into the database (saving it in client encoded hex strings) where you don't know how to handle - i.e. compare it to another similar looking string with a blank or just another string part after the \0 - and So, while implementation of such a function would be fairly easy, the implications it brings are very far reaching and have to be well thought - so in any case this could be fast-tracked. The simple and not to complicated thing is to keep the original author in a second field (as I did in my examples) next to its checksum. If you want to, open a feature request github issue, so once all these thoughts have been thought, we may remember to implement them. |
More specifically, valid and normalized UTF-8 strings. Which normalization form is it though? |
|
@dothebart - Thanks for your detailed explanation. I had certainly overlooked the prohibition against "/", and I also understand that the restriction about key-length would require some care. Now that I've looked more closely, I see also that keys cannot contain "~", so that rules out However, apart from the length restriction, the combination of base64 and encodeURIComponent should work, shouldn't it? In any case, since arangosh already has Which leads to the question: is there any compelling reason why all strictly-deterministic functions provided by arangosh at the top-level couldn't be made available in AQL? Regarding the issue you raised about the inverse of base64, please note that I was careful to say: p.s. |
|
AQL could be extended rather easily with JS implementations, but all such functions should also have a C++ implementation for performance reasons - which is quite a lot more work. If performance isn't much a concern, user-defined functions may do the job just fine and can be created by the user without building custom binaries. Not wanting to pollute AQL with too many functions might be another reason. Namespaces could help to mitigate this, e.g. |
|
@Simran-B - Thanks for your observations. UDFs are fine for true "customization" but it should not be necessary to use them for standard functions. There are (depending on the user) a variety of potentially large costs associated with the care and maintenance of anything that is "customized". I don't know enough about ArangoDB internals to know exactly when C++ implementations would be required, but the argument from cost or lack-of-resources (to implement the functions in C++) seems to me to be completely invalid: users who use UDFs already incur a performance penalty. Perhaps I'm wrong, but it looks as though there should be a path forward that at every step improves things, from both the user's and the vendor's points of view:
Regarding your point about pollution -- since users must currently provide a namespace, I am not quite sure what the issue here is; indeed, adding "ENCODE::BASE64" would run the risk of a collision with a UDF, wouldn't it? But if the path forward requires some kind of additional namespace, then so be it! |
|
The following seems to fill the bill: Example: Output: |
It is not required. If there is one, it will be prefered, unless the data is already in V8 - it's more efficient to use a JS implementation than to convert from V8 to native data structures to perform the operation. Most operations are carried out in native code. If a JS implementation is used, you will see
Processing speed would be more or less on par with an integrated JS implementation. Cluster behavior would be different to my knowledge: UDFs require intermediate data to be sent to the coordinator to execute UDF code there and the result needs to be sent back to the DB servers. With normal AQL functions, the processing happens on the DB servers AFAIK.
That is always the goal. Community contributions would be more than welcome for both, JS implementations as well as C++ implementations. It would be a nice challenge for a new contributor in fact. The relevant source code:
True. Only the What would be your recommendation to call these functions? ENCODE_BASE64, ENCODE_URI_COMPONENT etc.? Or maybe TO_BASE64 (in the style of existing type casting functions), FROM_BASE64 etc.? BTW: I remember that there are inconsistencies between how PHP encodes URI Components and how JS does it... I believe they differ for a certain character. Was it |
Currently, AQL has Regarding URI encoding and decoding: since JS prescribes a carefully-defined As for PHP's "urlencode" -- here is its specification:
I think that answers your question about "+". If AQL had functions with the same names and semantics of either of these PHP functions, that would seem to me to be eminently sensible, but I am sure there are sensible alternatives as well. All of this unfortunately still fails to provide a single function for mapping strings to keys in a more transparent manner than MD5. One possibility would be to piggy-back off the fact that MD5 only chews up 32 bytes, and to define a function, say, TO_KEY, as follows: given a UTF-8 string, s, beginning with a character suitable for a document key, and a function that returns strings with characters suitable for ArangoDB keys such as urlencode, let t=urlencode(s); if length(t)<=222 then return t; otherwise return LEFT(t,222) + MD5(s). |
|
There are also base58 and base62, which only use 0-9, A-Z and a-z. They are not that common, but wouldn't that be a solution for document keys? For collection names, we would need a base52 however (A-Z, a-z), because leading numbers are not allowed (internally, collections have number-based identifiers and a check of the first character can determine whether a collection identifier is a collection number or a collection name). Encoding spaces as |
None of the base* family solve the problem of key-length by themselves, so for TO_KEY I much prefer the transparency and popularity of something in the "urlencode" family. Regarding TO_KEY(s), I've updated my proposal, making it a requirement that the first character of s be a admissible as the first character of a key. (The user can easily enough add a dummy character if need be.) base62 might be handy, but seems to be relatively unpopular (no wikipedia article). Regarding base58, my understanding is that it's quite unlike the others, in that it covers a family of encodings. It all seems rather complex, unless you're into cryptocurrencies. See e.g. https://en.bitcoin.it/wiki/Base58Check_encoding |
|
Doesn't look too complex and supports arbitrary alphabets (base58, base62 etc.): https://github.com/cryptocoinjs/base-x Downside: the algorithm produces non-standard outputs for hex and base64, apparently. No encoding scheme can solve the key-length problem if I'm not mistaken. You either use a reversible algorithm / lossless compression where input length and output length correlate in some way, or you use a hash algorithm which is a one way street (kind of a lossy compression) but can make guarantees about the output length. If you combine both, you effectively end up with the latter, don't you (not fully reversible)? Question is, if there are any benefits with the combined approach. The only advantage that comes to my mind for something like encodeURIComponent is that humans would be able to interpret it, because it partially contained the verbatim input. So you might wanna add "human readability" to the requirements. |
|
@pkoppstein how is this related to importing the reddit dataset in first place? |
|
@dothebart - I am not sure what the referent of “this” is. I agree that the discussion has become a bit convoluted, but if it would help if I created a separate “ enhancement request” regarding the availability in AQL of deterministic functions that are already available in arangosh without any further “require”s, please say so. |
|
@pkoppstein whatever you're talking about - does it have any connection with the originaly (closed - because solved) issue? If not, please open a new one, add all relevant information, and let this one rest in peace. |
my environment running ArangoDB
I'm using the latest ArangoDB of the respective release series:
Mode:
Storage-Engine:
On this operating system:
AMD FX-6300 Six-Core Processor 3.50GHz
I'm issuing AQL via:
The issue can be reproduced using this dataset:
Go to http://files.pushshift.io/reddit/comments/ and download the 2017-01 tar. Exact file here. http://files.pushshift.io/reddit/comments/RC_2017-01.bz2
Import to Arangodb:
arangoimp --threads 6 --file "RC_2017-01" --type json --collection seventeen --server.database reddit --progress true --create-collection true --overwrite true-- You might get this issue.
Create an index on "author"
Once done, restart your computer for good measure.
Export the database:
arangoexport --server.database reddit --collection seventeenNotice how much memory the export takes. The export consumes more than twice the amount of RAM than the size of the database. While I was exporting I saw it consume all 32GB of my Physical RAM and about 58GB of Virtual Swap RAM.
The following problem occurs:
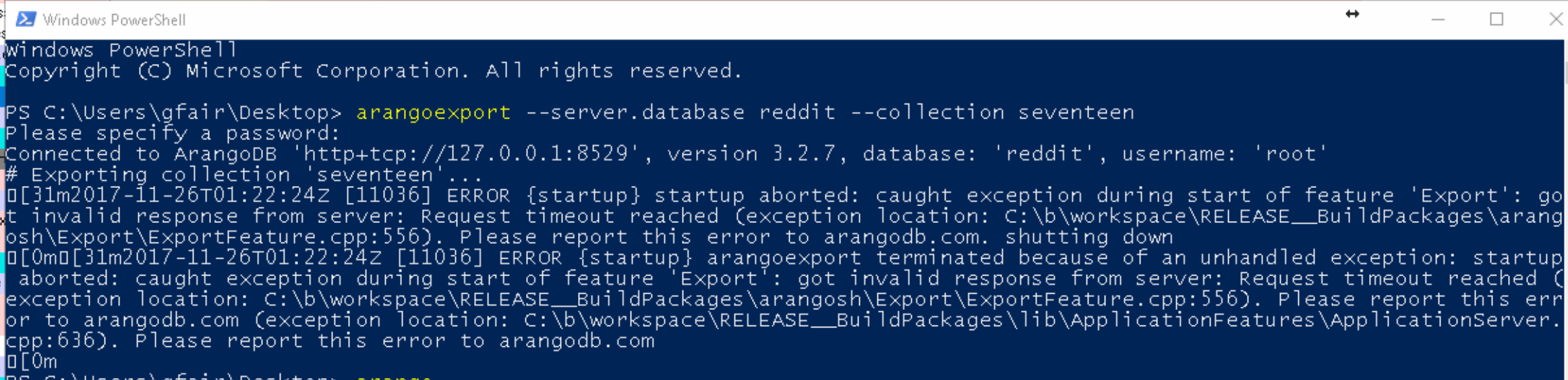
Also while exporting there is a memory leak somewhere.
Also you can expect the web interface's "Download documents as JSON file" feature not to work either. Your browser will just freeze no matter which one you use.
Instead I would be expecting:
A successful clean export
The text was updated successfully, but these errors were encountered: