基于 badger
v4.0.1进行源码分析
在看 badger 代码之前,需要对 lsm tree 有一定的理解,不然无法理解 wal, memtable, immutable memtable,sstable,compact 的组件设计. 众多基于 lsm tree 的 kv 存储在实现上有些不同, 像 leveldb, rocksdb, badgerDB, pebbleDB 等存储引擎在 lsm tree 设计上大同小异.
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
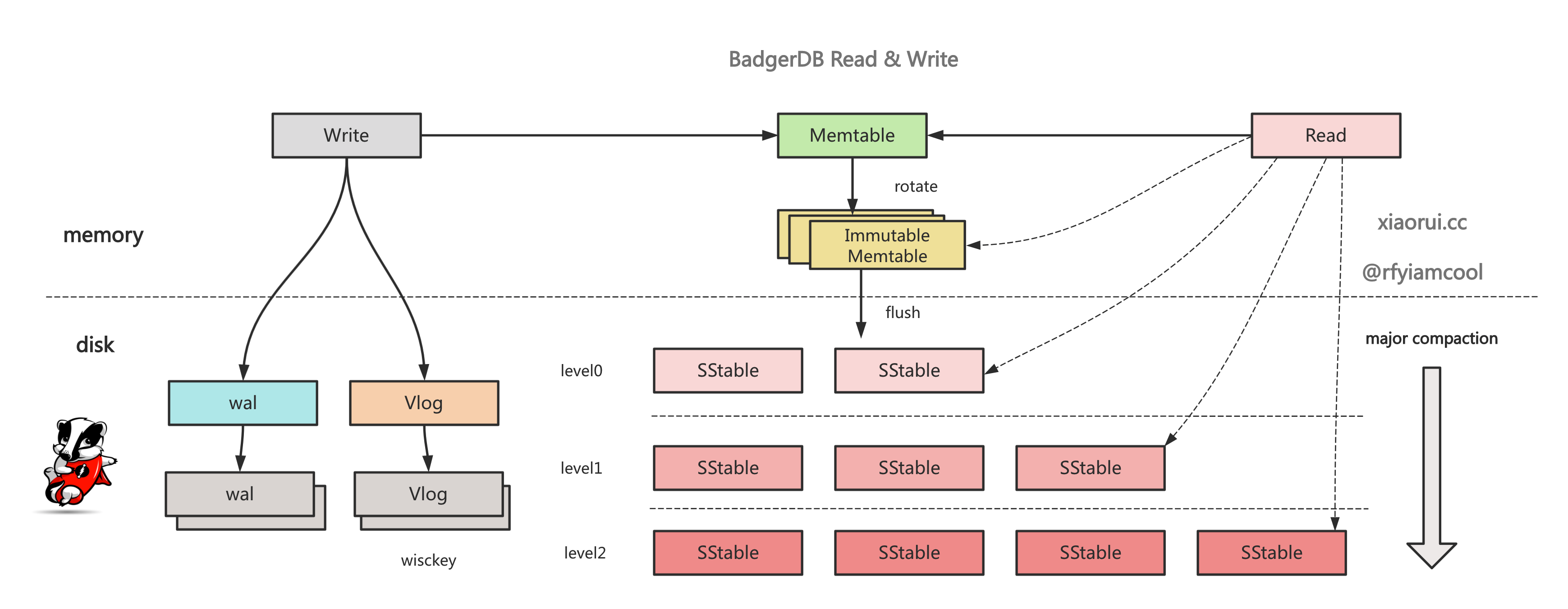
写流程的调用顺序:
vlog -> wal -> memtable -> immutable memtable list -> ssts in Level0 -> major compact ...
读流程的调用顺序:
memtable -> immutable memtable list -> ssts in Level0 -> ssts in Level1 -> ssts in LevelN
golang badger 写流程的函数调用过程
golang badger 写流程的函数调用过程大概是这样.
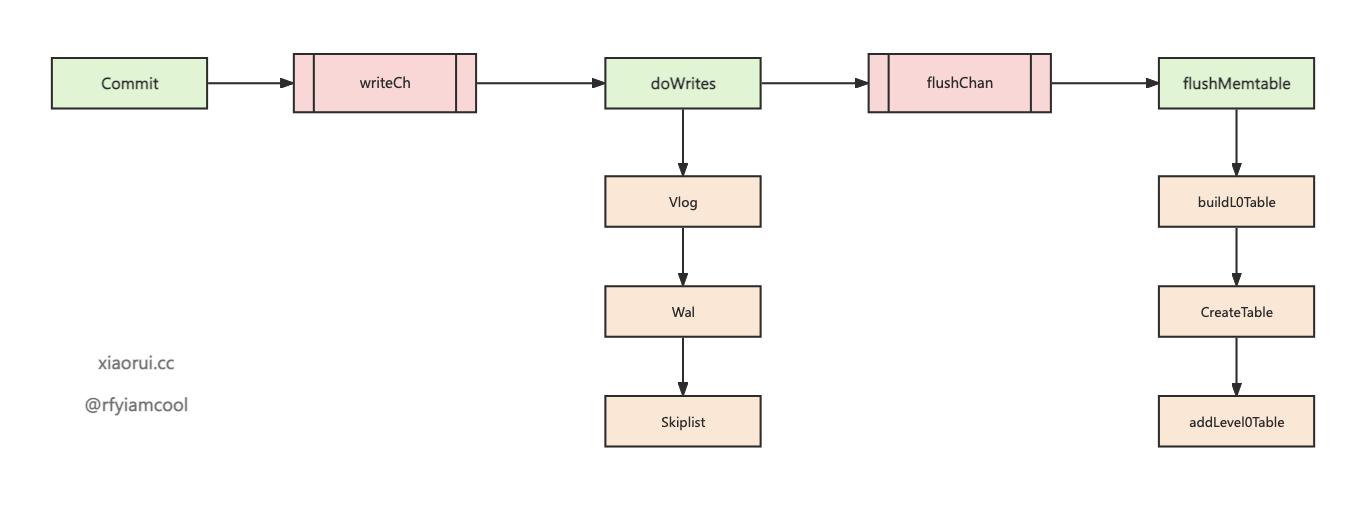
上次分析了 badger 事务的实现原理, badger 中的读写操作都是在事务中进行的, 事务 Commit 提交会对 keys 进行冲突检测, 通过检测的 keys 才会被写入.
在事务提交后, 所有的写请求都会推到 writeCh 管道上, 由 doWrites 协程来处理写请求.
先判断 entry 的 value 是否属于大 value, 如果符合则需要把 value 写到 vlog 文件里, 然后把 entry 写到 wal 日志里, 接着再写到 memtable 里. 在处理写请求时, memtable 会转换为 immutable memtable, 然后经由 flushMemtable 把 memtable 构建为 sstable 对象, 最后经过数据经过加工和布局调整后进行持久化.
badger 在 Open 时会启动一个 doWrites 写协程. doWrites 协程会一直监听 writeCh 队列, 当收到已提交事务 entry 时, 先尝试暂存 request 到 reqs, 在满足写要求时, 调用 writeRequests 执行进一步操作.
pendingCh 的目的其实是为了控制并发, 首先让 writeRequests 异步去执行, 但 writeRequests 的协程不会超过 1 个, 另外因为耗时 writeRequests 异步志新, 不会阻塞 doWrites 监听暂存 reqeust 的逻辑.
func (db *DB) doWrites(lc *z.Closer) {
defer lc.Done()
pendingCh := make(chan struct{}, 1)
writeRequests := func(reqs []*request) {
// 调用 writeRequests 进一步写操作.
if err := db.writeRequests(reqs); err != nil {
db.opt.Errorf("writeRequests: %v", err)
}
// 进行排空
<-pendingCh
}
// 缓冲, 尽量批量操作
reqs := make([]*request, 0, 10)
for {
var r *request
select {
case r = <-db.writeCh:
// 收到 reqeust
case <-lc.HasBeenClosed():
// 退出操作
goto closedCase
}
for {
// 放到 reqs 进行写缓冲
reqs = append(reqs, r)
// 当 reqs 大于等于 3000 时, 跳到 writeCase 进行写操作.
if len(reqs) >= 3*kvWriteChCapacity {
// 通知事件
pendingCh <- struct{}{} // blocking.
goto writeCase
}
select {
case r = <-db.writeCh:
// 再次尝试监听新 request, 并暂存到 reqs.
case pendingCh <- struct{}{}:
// 主动通知, 并提到 writeCase 逻辑.
goto writeCase
case <-lc.HasBeenClosed():
goto closedCase
}
}
closedCase:
for {
select {
case r = <-db.writeCh:
// 监听新 request, 并暂存到 reqs 里.
reqs = append(reqs, r)
default:
// 如果没拿到新 request, 则通知事件.
pendingCh <- struct{}{}
// 执行写操作.
writeRequests(reqs)
return
}
}
writeCase:
// 开协程异步的去处理写请求
go writeRequests(reqs)
// 重置 reqs 缓冲
reqs = make([]*request, 0, 10)
}
}writeRequests 需要串行化同步执行, 只能由一个协程去执行写操作, writeRequests 会对大 value 的 entry 写 vlog, 把 entry 写到 wal 预写日志里, 并在 skiplist 跳表中构建 node 节点.
func (db *DB) writeRequests(reqs []*request) error {
// 当退出时, 对 wg 执行 done 操作, 毕竟 wg 一直 wait 阻塞.
done := func(err error) {
for _, r := range reqs {
r.Err = err
r.Wg.Done()
}
}
// 尝试把大 value 的数据写到 vlog 里, 用以实现 kv 分离.
err := db.vlog.write(reqs)
if err != nil {
done(err)
return err
}
// 遍历传入的 request 集合.
for _, b := range reqs {
if len(b.Entries) == 0 {
continue
}
// 传递 flush 事件, 把当前的 memtable 加到 immutable memtable 集合里.
// 并创建一个新的 memtable 赋值到 db.memtable.
for err = db.ensureRoomForWrite(); err == errNoRoom; err = db.ensureRoomForWrite() {
time.Sleep(10 * time.Millisecond)
}
if err != nil {
done(err)
return y.Wrap(err, "writeRequests")
}
// 把 entry 写到 wal 预写日志里, 并在 skiplist 构建节点.
if err := db.writeToLSM(b); err != nil {
done(err)
return y.Wrap(err, "writeRequests")
}
}
done(nil)
return nil
}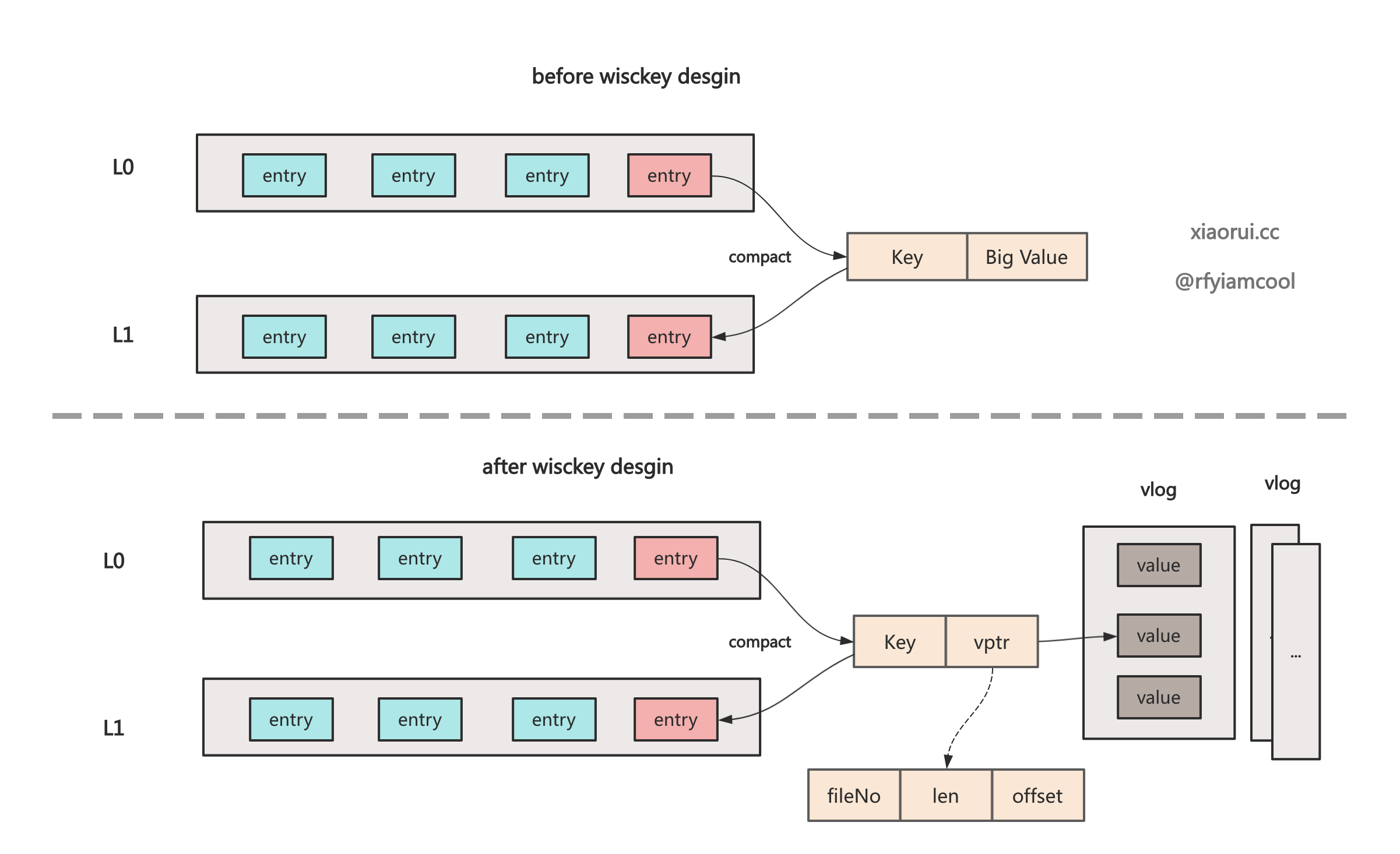
badger 的 wisckey vlog 的设计还是很复杂的, 其设计目的是为了避免大 value 在 sstable compact 合并时带来的写放大问题.
wisckey kv 单纯写的话好理解, 把大于 1MB 的 value 写到活动的 vlog 里, 在 memtable 和 sstable 只需要存 vptr (fid, len, offset) 就可以了. 查询也好理解, 直接按照 vptr 的 fid 定位文件, len + offset 找到对应的 value. 但更新和删除操作就显得繁琐了, 因为后面还涉及到 vlog 空间整理和 gc 回收.
leveldb, rocksdb 本身是没有实现 wisckey kv 分离, 但不少公司基于 rocksdb 开发了含有 wisckey 的存储引擎, 比如 pingcap 的 titan 和字节的 TerarkDB, 但跟 badgerDB 实现上都有些不同, 篇幅有限, 按下不表.
wisckey kv 分离的论文. https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
ensureRoomForWrite 内部会传递 flush 事件, 把当前的 memtable 加到 immutable memtable 集合里. 还有创建一个新的 memtable 赋值到 db.memtable.
// ensureRoomForWrite is always called serially.
func (db *DB) ensureRoomForWrite() error {
var err error
db.lock.Lock()
defer db.lock.Unlock()
y.AssertTrue(db.mt != nil)
// 当 memtable 空间大于 64MB, 或者关联的 wal 超过了 64MB, 则需要持久化.
if !db.mt.isFull() {
return nil
}
select {
case db.flushChan <- flushTask{mt: db.mt}:
// 把当前的可写的 memtable 追加到 immutable memtable 集合里.
db.imm = append(db.imm, db.mt)
// 构建一个新的 memtable 对象到 db.mt
db.mt, err = db.newMemTable()
if err != nil {
return y.Wrapf(err, "cannot create new mem table")
}
return nil
default:
return errNoRoom
}
}isFull() 会通过判断当前 memtable skiplist Arena 空间或者 wal 空间是否超过了 64MB, 如超过阈值, 则需要进行刷盘操作. badger 默认的 opt.MemTableSize 为 64MB.
func (mt *memTable) isFull() bool {
if mt.sl.MemSize() >= mt.opt.MemTableSize {
return true
}
if mt.opt.InMemory {
return false
}
return int64(mt.wal.writeAt) >= mt.opt.MemTableSize
}writeToLSM 会判定 entry 是否满足大 value 条件, 如果是大 value 的 entry 无需把 value 写到 wal 里, 不满足, 则需要把 value 写入到 wal 里. 最后还需要把 entry 写入到 skiplist 跳表里.
代码位置: badger/blob/main/db.go:writeToLSM
// 当 value 大于 1MB, 进行 wisckey kv 分离.
const (
maxValueThreshold = (1 << 20) // 1 MB
)
func (db *DB) writeToLSM(b *request) error {
if !db.opt.InMemory && len(b.Ptrs) != len(b.Entries) {
return errors.Errorf("Ptrs and Entries don't match: %+v", b)
}
// 遍历需要写入的 entries
for i, entry := range b.Entries {
var err error
// 判断当前的 entry 是否满足大 value 的条件.
if entry.skipVlogAndSetThreshold(db.valueThreshold()) {
// 后面有 put 分析
err = db.mt.Put(entry.Key,
y.ValueStruct{
Value: entry.Value,
Meta: entry.meta &^ bitValuePointer,
UserMeta: entry.UserMeta,
ExpiresAt: entry.ExpiresAt,
})
} else {
// 当判定 entry 为大 value 时, 只需要写入 ptr 即可
// ptr 结构体含有文件id, offset, len 三个字段.
err = db.mt.Put(entry.Key,
y.ValueStruct{
Value: b.Ptrs[i].Encode(),
Meta: entry.meta | bitValuePointer,
UserMeta: entry.UserMeta,
ExpiresAt: entry.ExpiresAt,
})
}
if err != nil {
return y.Wrapf(err, "while writing to memTable")
}
}
// 开启同步选项, 每次写完 log 都需要同步刷盘.
if db.opt.SyncWrites {
// 底层调用 unix.Msync 进行 mmap 同步.
return db.mt.SyncWAL()
}
return nil
}把 entry 写到 wal 里, 并在 skiplist 跳表中插入数据, 用以构建索引.
func (mt *memTable) Put(key []byte, value y.ValueStruct) error {
entry := &Entry{
Key: key,
Value: value.Value,
UserMeta: value.UserMeta,
meta: value.Meta,
ExpiresAt: value.ExpiresAt,
}
// 只有使用内存模式才不需要 wal.
if mt.wal != nil {
// 写 wal 日志, 如果超过阈值则进行强制同步刷盘.
if err := mt.wal.writeEntry(mt.buf, entry, mt.opt); err != nil {
return y.Wrapf(err, "cannot write entry to WAL file")
}
}
if entry.meta&bitFinTxn > 0 {
return nil
}
// 把数据写到 skiplist 里, 另外更新 maxVersion 最大事务版本.
mt.sl.Put(key, value)
if ts := y.ParseTs(entry.Key); ts > mt.maxVersion {
mt.maxVersion = ts
}
return nil
}writeEntry 把数据写到 logfile 的 data 数组里, 这里的 lgofile 其实就是 wal 预写日志, wal 内的 Data []byte 字节数组已经做了 mmap 文件映射. 这里只是把编码后的数据写到 mmap 映射的空间里, 本质还在 page cache 里, 在 writeToLSM 结束时会调用 mmap sync 来同步刷盘.
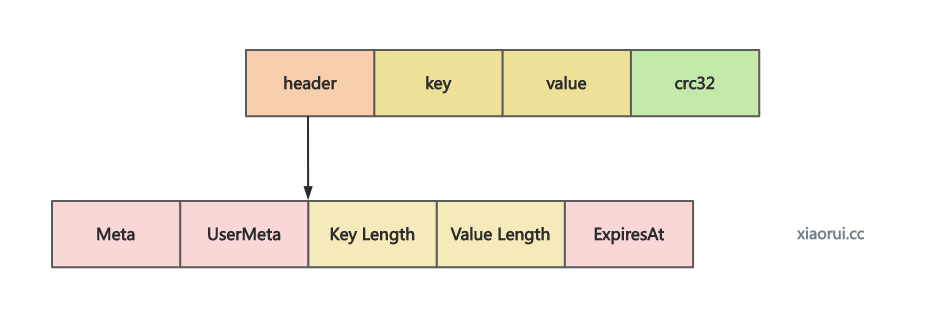
func (lf *logFile) writeEntry(buf *bytes.Buffer, e *Entry, opt Options) error {
buf.Reset()
plen, err := lf.encodeEntry(buf, e, lf.writeAt)
if err != nil {
return err
}
y.AssertTrue(plen == copy(lf.Data[lf.writeAt:], buf.Bytes()))
lf.writeAt += uint32(plen)
lf.zeroNextEntry()
return nil
}这里的 mmap 文件的映射使用了 github.com/dgraph-io/ristretto 的库包. mmap 的优点在于 zero copy, 避免了数据在内核态和用户态的来回拷贝.
Put() 会把 kv 结构插入到 skiplist 跳表里. 其目的是通过构建跳表来实现数据的快速查询.
// Put inserts the key-value pair.
func (s *Skiplist) Put(key []byte, v y.ValueStruct) {
// ...
}badger 在进行 writeRequests 写操作时, 当前的 memtable 追加到 immutable memtable 集合里, 然后实例化一个新的 memtable, 然后会把要写的数据写到 wal 日志里, 在开启 sync 选项时, 每次写完 wal 日志后都会对 mmap 调用 unix.Msync 进行数据同步.
immutable memtable 为不可变更的 memtable, 如何进行持久化落盘 ?
badgerDB 在执行 Open 时会启动一个 flushMemtable 协程来执行刷盘操作.
func (db *DB) flushMemtable(lc *z.Closer) error {
defer lc.Done()
// 监听 flushChan 通道
for ft := range db.flushChan {
if ft.mt == nil {
continue
}
for {
// 执行刷盘操作
err := db.handleFlushTask(ft)
if err == nil {
db.lock.Lock()
y.AssertTrue(ft.mt == db.imm[0])
db.imm = db.imm[1:]
ft.mt.DecrRef() // Return memory.
db.lock.Unlock()
break
}
time.Sleep(time.Second)
}
}
return nil
}handleFlushTask 用来执行 SStable 的刷盘操作, 遍历 memtable 的 skiplist 来构建一个 SStable 表对象, 创建一个 SStable 对象, 然后把数据写到 SStable 文件里, 把 sstable 对象加到 levelsController 控制器里.
// handleFlushTask must be run serially.
func (db *DB) handleFlushTask(ft flushTask) error {
// 已经被刷盘
if ft.mt.sl.Empty() {
return nil
}
bopts := buildTableOptions(db)
// 遍历 memtable 的 skiplist 来构建一个 SStable 表对象.
builder := buildL0Table(ft, bopts)
defer builder.Close()
if builder.Empty() {
builder.Finish()
return nil
}
// 获取一个递增的 fileID
fileID := db.lc.reserveFileID()
var tbl *table.Table
var err error
if db.opt.InMemory {
data := builder.Finish()
tbl, err = table.OpenInMemoryTable(data, fileID, &bopts)
} else {
// 创建一个 sstable 对象, 然后把数据写到 sstable 里.
tbl, err = table.CreateTable(table.NewFilename(fileID, db.opt.Dir), builder)
}
if err != nil {
return y.Wrap(err, "error while creating table")
}
// 把 sstable 加到 levelsController 控制器里.
err = db.lc.addLevel0Table(tbl)
_ = tbl.DecrRef()
return err
}buildL0Table 遍历 memtable 中 skiplist 跳表里的数据来构建 sstable 对象.
// buildL0Table builds a new table from the memtable.
func buildL0Table(ft flushTask, bopts table.Options) *table.Builder {
iter := ft.mt.sl.NewIterator()
defer iter.Close()
b := table.NewTableBuilder(bopts)
// 从头到位进行遍历
for iter.SeekToFirst(); iter.Valid(); iter.Next() {
if len(ft.dropPrefixes) > 0 && hasAnyPrefixes(iter.Key(), ft.dropPrefixes) {
continue
}
vs := iter.Value()
var vp valuePointer
if vs.Meta&bitValuePointer > 0 {
vp.Decode(vs.Value)
}
// 写到 sstable 对象里.
b.Add(iter.Key(), iter.Value(), vp.Len)
}
return b
}CreateTable 把 sstable 对象生成的 buildData 的数据写到 sstable 文件里, 生成 sstable 的过程有些复杂, 限于篇幅原因, 后面会专门来分析下它的实现原理.
func CreateTable(fname string, builder *Builder) (*Table, error) {
// 生成 buildData 对象
bd := builder.Done()
mf, err := z.OpenMmapFile(fname, os.O_CREATE|os.O_RDWR|os.O_EXCL, bd.Size)
if err == z.NewFile {
// Expected.
} else if err != nil {
return nil, y.Wrapf(err, "while creating table: %s", fname)
} else {
return nil, errors.Errorf("file already exists: %s", fname)
}
// 把 sstable 内存对象的数据写到 sstable 文件里.
written := bd.Copy(mf.Data)
y.AssertTrue(written == len(mf.Data))
// 执行同步落盘操作.
if err := z.Msync(mf.Data); err != nil {
return nil, y.Wrapf(err, "while calling msync on %s", fname)
}
return OpenTable(mf, *builder.opts)
}代码位置: badger/builder.go
结合下图方便的理解 badger sstable 中 index、block 的数据布局.
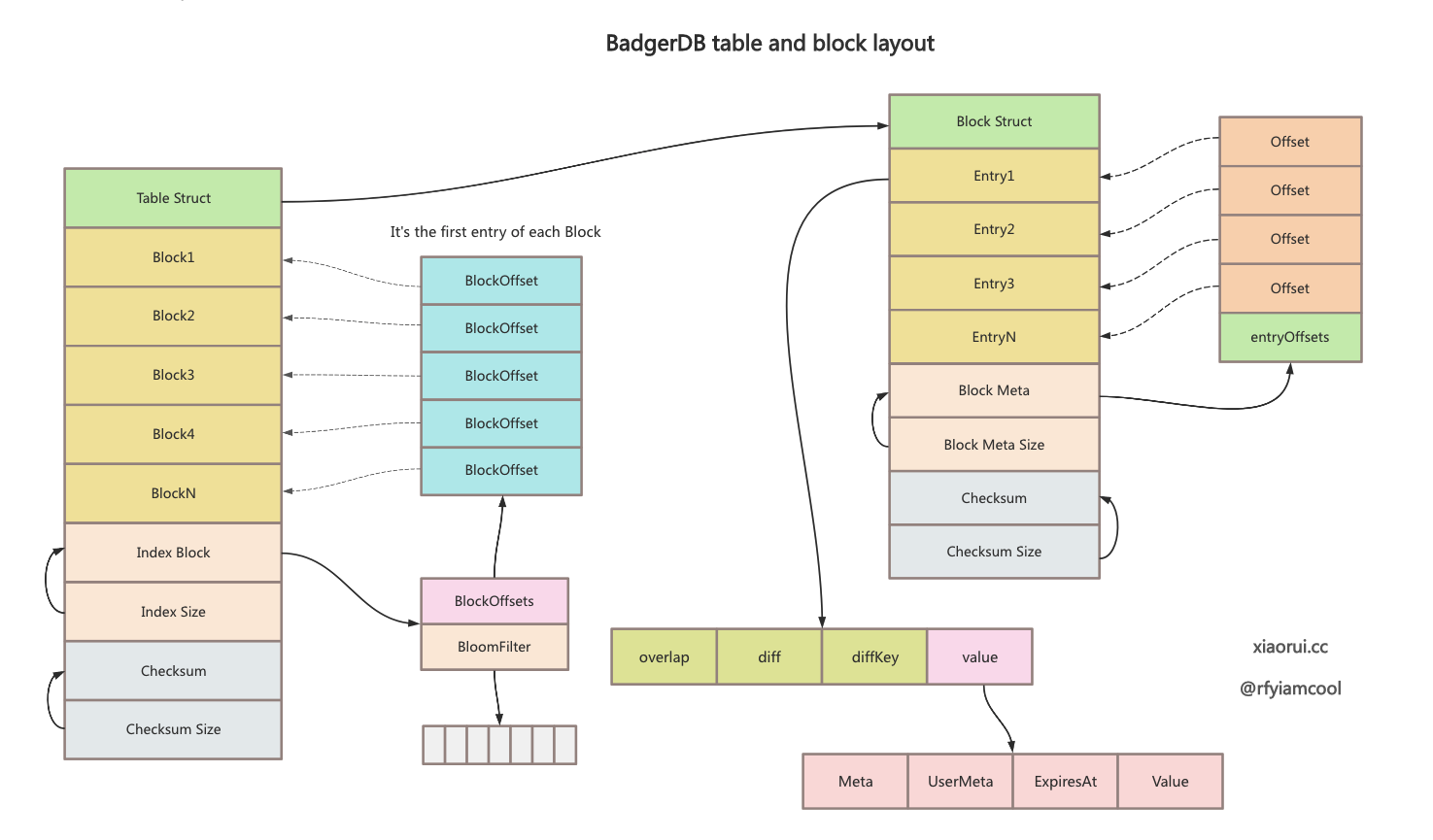
badgerDB sstable 文件的数据布局. 先排列 block 数据块, 接着排列 index 索引, 这里的索引为 bloomfilter 布隆过滤器, 后面开始排列 index 的 size, checksum 校验码, 最后为 checksum 校验码的 size.
// Finish finishes the table by appending the index.
/*
The table structure looks like
+---------+------------+-----------+---------------+
| Block 1 | Block 2 | Block 3 | Block 4 |
+---------+------------+-----------+---------------+
| Block 5 | Block 6 | Block ... | Block N |
+---------+------------+-----------+---------------+
| Index | Index Size | Checksum | Checksum Size |
+---------+------------+-----------+---------------+
*/下面为 block 的布局, 先排列 entry, 接着排列索引, 这里的索引是由 entry offset 组成的二分查找数组, 后面排列 block meta size, block checksum 和 checksum size.
/*
Structure of Block.
+-------------------+---------------------+--------------------+--------------+------------------+
| Entry1 | Entry2 | Entry3 | Entry4 | Entry5 |
+-------------------+---------------------+--------------------+--------------+------------------+
| Entry6 | ... | ... | ... | EntryN |
+-------------------+---------------------+--------------------+--------------+------------------+
| Block Meta(contains list of offsets used| Block Meta Size | Block | Checksum Size |
| to perform binary search in the block) | (4 Bytes) | Checksum | (4 Bytes) |
+-----------------------------------------+--------------------+--------------+------------------+
*/值得一说的是, badger block 的设计跟 rocskdb 是有区别的, badger block 中的 block meta 里存放了 entryOffets uint32 数组, 该数组中的元素指向了每一个 entry. 当查询具体的 key 时, 通过 entryOffsets 数组做二分查找来定位 entry.
另外 badger 的 block 中有设计前缀压缩. lsm tree 的 sstable 是 key 值有序的, 那么这一组的 key 会有一样的前缀字符. block entry 结构的首字段为 header, 这个 header 主要有连个字段 overlap 和 diff, overlap 为重叠的字节数, diff 为差异的字节数, block entry 列表都跟第一个 entry 做对比来构建这个 header. 第一个 block entry 的 overlap 为 0, diff 为完整 key 的长度.
而 rocksdb 在 block 中设计了有前缀压缩功能的 restart points 启动点, 默认 16 个 entry 为一个启动点, 每个启动点保存了这一组 entry 的 key 完整信息, 后面的 entry 则跟对应的启动点计算前缀重叠的部分. rocksdb 的 restart points 不仅实现了压缩功能, 也实现了类似稀疏索引的二分查找. 通过 restart points 数组找到对应的启动点后, 尝试往后进行遍历查找数据, 直到找到或者下一个启动点为止.
下图为 rocksdb sstable 和 block 的数据结构关联图.
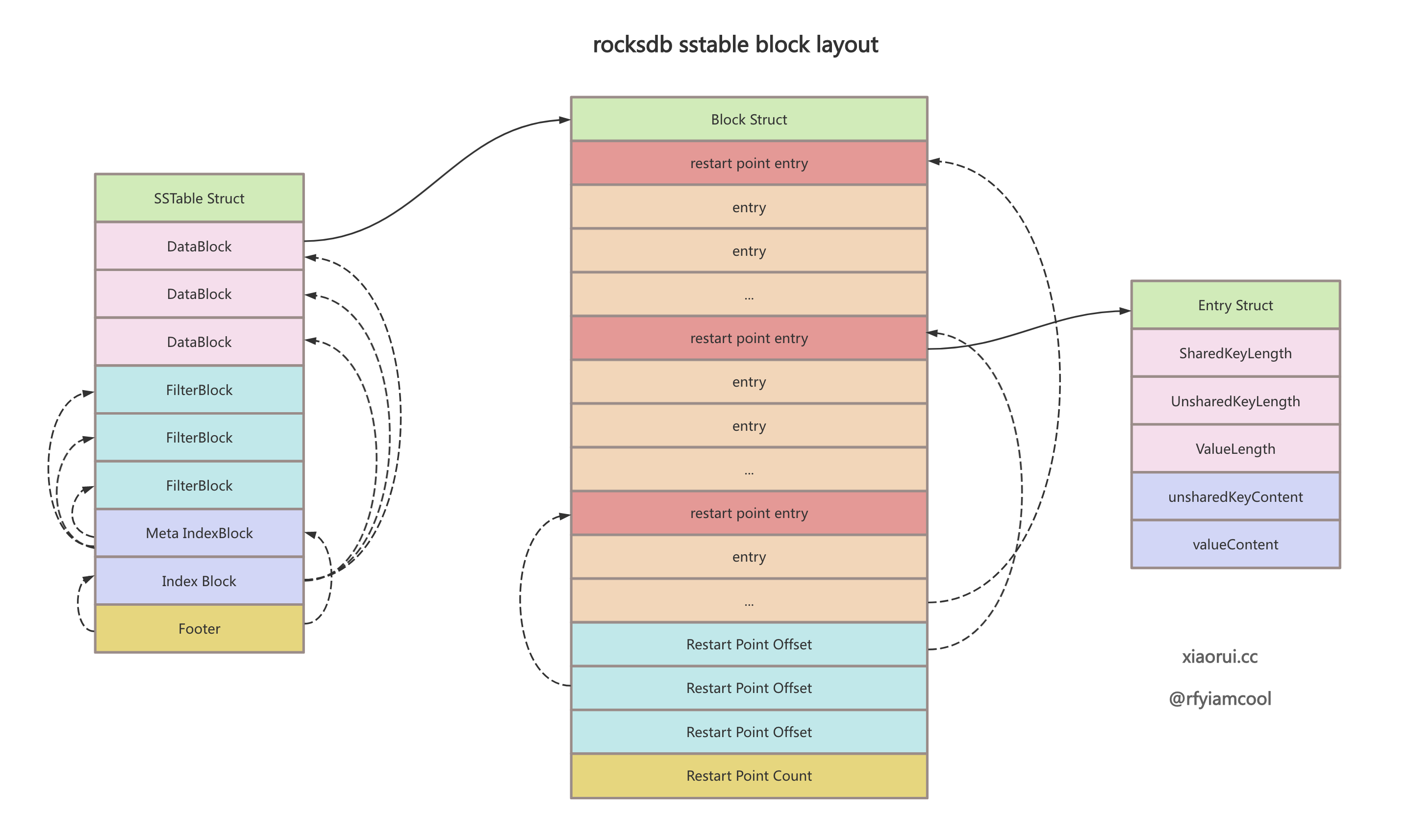
对于 badger 的 table、index、block 结构体的编码和解码, 读写的具体操作流程及设计原理, 可直接看代码, 篇幅原因不展开写了.
golang badger 写流程的函数调用过程大概是这样.
在事务提交后, 所有的写请求都会推到 writeCh 管道上, 由 doWrites 协程来处理写请求.
先判断 entry 的 value 是否属于大 value, 如果符合则需要把 value 写到 vlog 文件里, 然后把 entry 写到 wal 日志里, 接着再写到 memtable 里. 在处理写请求时, memtable 会转换为 immutable memtable, 然后经由 flushMemtable 把 memtable 构建为 sstable 对象, 最后经过数据经过加工和布局调整后进行持久化.