Enable both Pytorch native AMP and Nvidia APEX AMP for SRU #158
Conversation
|
cc @hpasapp Hi @visionscaper , thank you so much for contributing to the repo. We set the Does the |
|
|
Thanks for your replies! I'm still trying to figure out what precisely is going on and what the reasoning is behind some choices.
Inside the In this case So now I also better understand why originally I had the issue with Nvidia APEX AMP. Looking at the original code ... ... I'm wondering, could this be because you use a custom C/C++ implementation that AMP stops working in the recurrence kernel? Do you agree that this causes the error? In the code in my pull request this is remedied by simply ensuring we cast to Now the last point is, do we need the In conclusion, cases can occur where arguments with mixed precision are used to call the recurrence kernel. PS 1 : @hpasapp I understand that casting is just an identity function if the input tensor is already in the right type. And yes, it creates a decoupling, but this decoupling should also be applied for any AMP method, not just PyTorch native AMP, right? PS 2 : I would be happy to place the |
|
Ok, so:
|
…CUDA kernel either needs all Float32 or all Float16 tensors. Disabled AMP block is back because AMO is moot for the recurrence kernel
Aha! This is new information to me (I haven't written any custom CUDA kernels myself yet). This is also why we need to cast all the Tensors either to Float32 or Float16. So do I now understand correctly that we need the Bringing this all together, we could update the code as follows: The Further, we (again), disable Pytorch native AMP when it is used by the user, because it is moot when calling te recurrence kernel. Because I think this fix update makes a lot of sense, I committed it to my fork. I also checked if it still works with PyTorch AMP and Nvidia APEX AMP (with Deepspeed). @hpasapp @taolei87 please let me know what you think of this new fix and if we need to do more testing. |
|
Per my understanding from https://pytorch.org/docs/stable/notes/amp_examples.html#autocast-and-custom-autograd functions we should first disable autocast, and then do any casts we would like. I'm not sure what happens if we do the cast first, but I worry we might then be "out of spec", and things might fail under some circumstances. Googling briefly for using custom cuda functions with apex, https://github.com/NVIDIA/apex/tree/master/apex/amp#annotating-user-functions appears to describe what to do. We can either add annotations to the function to say that it should be used with half, or should be used with float32. Or we can call a registration function directly. Given that we have a runtime parameter to decide whether the recurrence should be float32 or float16, it might not make sense to use the annotations, and so calling the registration function might be the way to go. What do you think? |
|
Hi @hpasapp, I adapted the implementation as follows:
In my opinion the code is more complex now, I liked my previous fix, and am not sure if the changes are really required. But if you want to be sure to do it the right way, I guess this is better. For now I put my changes in a separate branch, and can be found here: Let me know what you think. |
|
I did some more experiments, concerning the use of Deepspeed, APEX AMP and Pytorch AMP on a system with 3x 1080 Ti and on an AWS instance with 4x T4 (also scroll to the right). Here I'm training a seq2seq conversational model, with customizations to make it multi-turn. The model uses SRUs (with the latest fix). CUDA version is 11.00. Some conclusions:
Any idea why the memory usage increases? |
|
^ Could the higher memory usage be because of the casting from FP32 => FP16? |
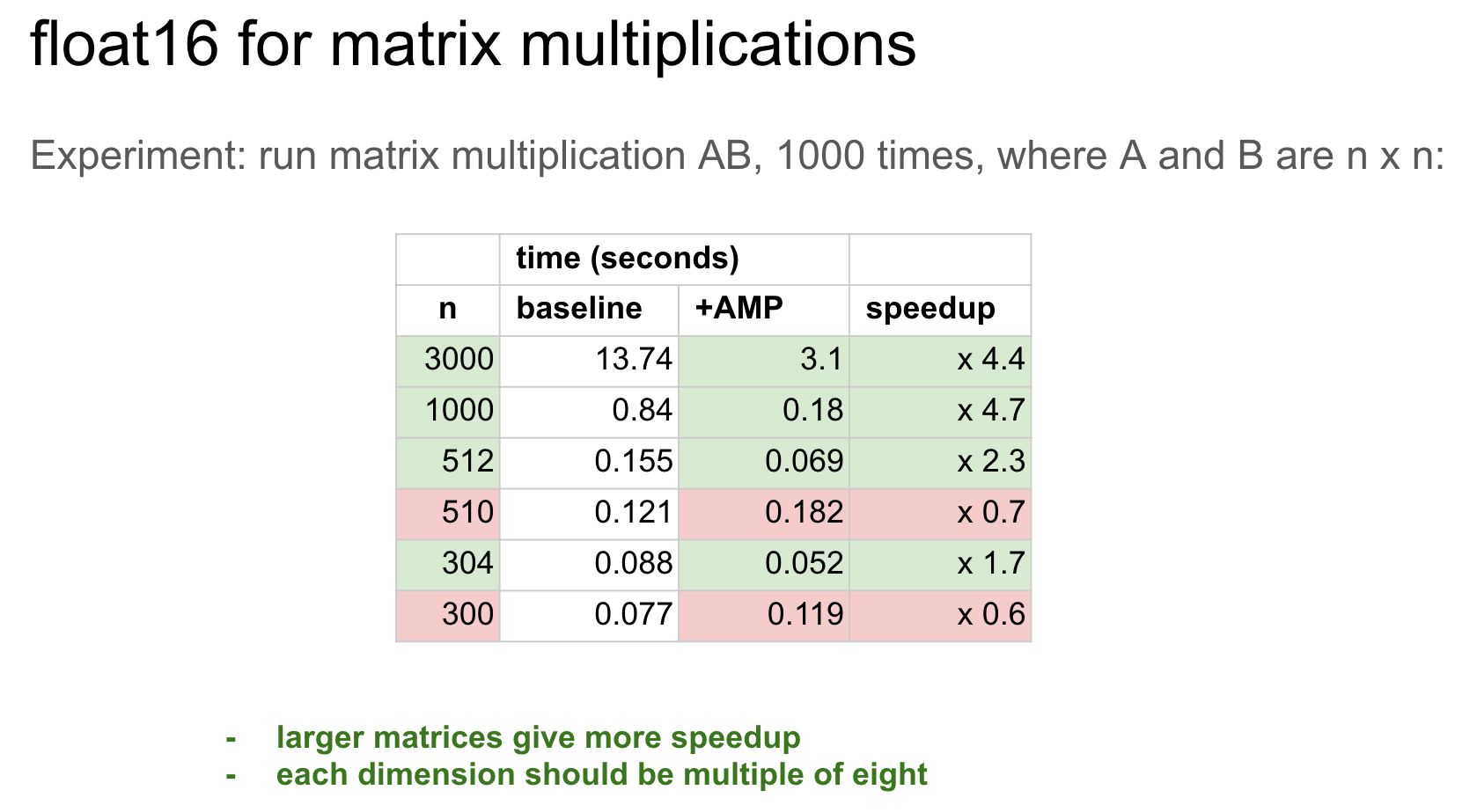
As far as execution speed, note that AMP is strongly is affected by whether all dimensions are a multiple of 8. I'm not saying this is the cause of some of your results, but it could be. Attached, screenshot of results of some experiments where we multiple two matrices A and B, of dimension n x n, and vary n:
You can see that changing from n=512 to n=510 decreases execution time without AMP, but with AMP enabled, reducing n from 512 to 510 actually increases the execution time by nearly 3 :O For SRU, the simplest way to ensure this is that one makes all dimensions of each tensor a multiple of 8: sequence length, batch size, embedding size. In practice, the matrix multiplication is the one that generates U, Line 376 in 7c27bea
Yes, older gpus didn't have the specialized tensor cores. v100 and t4 both work ok using amp.
That AMP increases memory usage is actually new information to me. I don't know if the casting operation itself increases memory usage, but perhaps some buffers are in memory twice: once as fp32 and once as fp16?
|
|
Closing this PR. This is addressed in the dev branch and will be merged in later: |
|
You're welcome. |
|
hi @visionscaper , Seems you explicitly register the recurrence operators for apex. So it will enable autocasting of the tensors into the appropriate types? I noticed that in this PR you don't have the registrations. Would not registering the operators break the apex amp training? |
Hi!
I was happily using SRUs with Pytorch native AMP, however I started experimenting with training using Microsoft DeepSpeed and bumped in to an issue.
Basically the issues is that I observed that FP16 training using DeepSpeed doesn't work for both GRUs and SRUs. However when using Nvidia APEX AMP, DeepSpeed training using GRUs does work.
So, based on the tips in one of your issues, I started looking in to how I could enable Pytorch native AMP and Nvidia APEX AMP for SRUs, so I could train models based on SRUs using DeepSpeed.
That is why I created this pull request. Basically, I found that by making the code simpler, I can make SRUs work with both methods of AMP.
Now
amp_recurrence_fp16can be used for both types of AMP. Whenamp_recurrence_fp16=True, the tensor's are cast tofloat16, otherwise nothing special happens. So, I also removed thetorch.cuda.amp.autocast(enabled=False)region; I might be wrong, but it seems that we don't need it.I did some tests with my own code and it works in the different scenarios of interest:
It would be beneficial if we can test this with an official SRU repo test, maybe repurposing the
language_model/train_lm.py?