Question about the weight for correction in the importance sampling #7
Comments
|
But I will consider changing it as you said. Probably that will be a better solution |
|
Alright, about to release a commit to this. The solution is simple: substitute the historical action with the one generated by the beta network.
I have addded a parameter called 'action_source' and so far I came up with: |
|
I have released a commit to this, you can look at it here Write me back if I can close the issue |
|
Actually, I do not know which one is correct or better. Maybe I can try both in my task. Thanks a lot. |
Hello. Thanks for your great work, from which I learned a lot about reinforcement learning. I am confused about the computation of the correction weight in the importance sampling.
According to the paper "Top-K Off-Policy Correction for a REINFORCE Recommender System", the correction weight is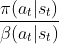 , in which, I think,
, in which, I think, 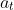 is an action sampled from the behavior policy, i.e.
is an action sampled from the behavior policy, i.e.  , and thus the reward of a sequence
, and thus the reward of a sequence  is corrected by dividing the likelihood of action
is corrected by dividing the likelihood of action 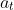 given
given 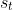 in the updated policy. i.e.
in the updated policy. i.e. 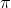 by the likelihood of the same action
by the likelihood of the same action 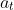 given
given 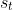 in
in  . Noted
. Noted 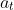 will be input into both
will be input into both 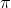 and
and  . However, in your implementation, I found that actions are not the same for
. However, in your implementation, I found that actions are not the same for 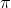 and
and  , seeing the function "pi_beta_sample" in here.
, seeing the function "pi_beta_sample" in here.
Am I wrong about this?
Thanks!
The text was updated successfully, but these errors were encountered: