语义表示应用介绍
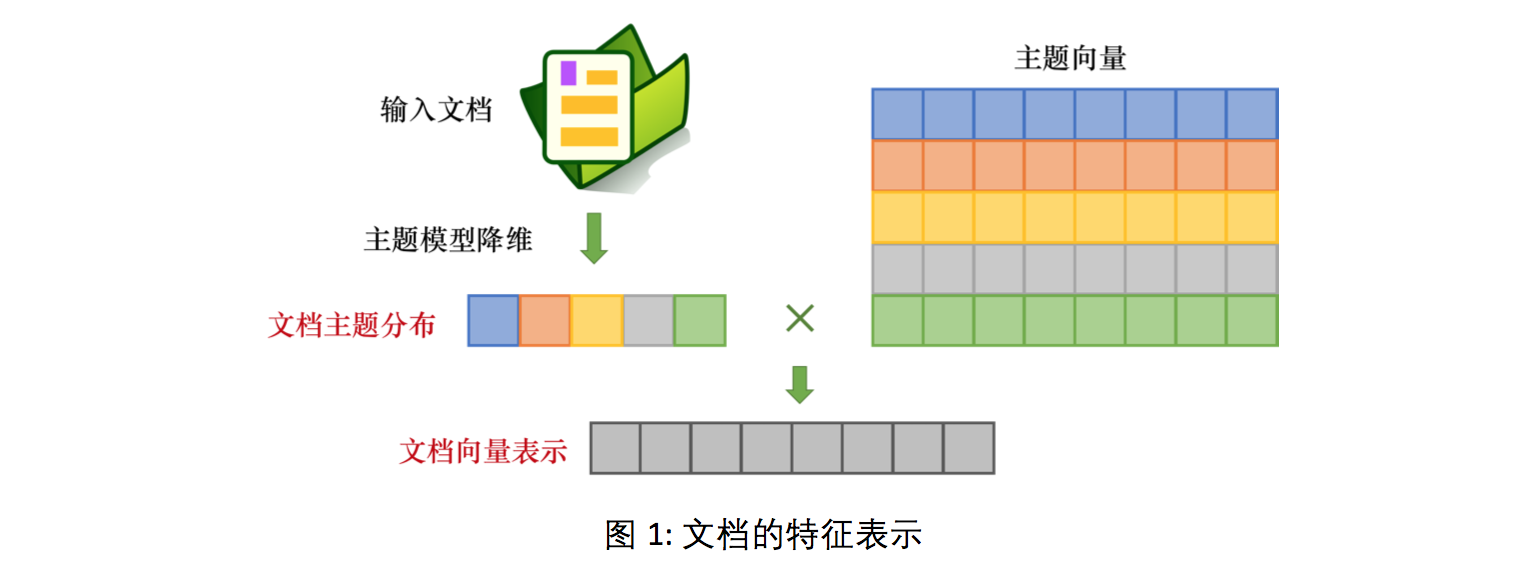
主题模型产生的主题表示可看做文档的特征信息,能够用于文档分类、聚类、内容分析等多种任务。基于主题模型的文档特征表示可以分为两类,如图1所示:一类是经过主题模型降维,得到文档在主题上的多项分布,LDA、Sentence LDA等模型支持这一类的文档特征表示;另一类是联合使用主题向量和文档主题分布,生成的文档向量表示,TWE等融合了词向量的主题模型可以支持这一类的文档特征表示。相对于多项分布表示,向量表示较为灵活,维度不受限于主题的数目。
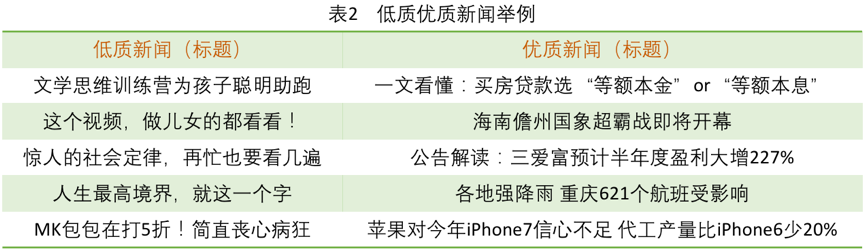
对于新闻APP,其通过各种来源获得到的新闻,质量通常良莠不齐。在表2中列出了一些低质新闻与优质新闻的标题,可以看出低质新闻大多是软文和广告类文章,而优质新闻则是包含了具体实事信息的文章。
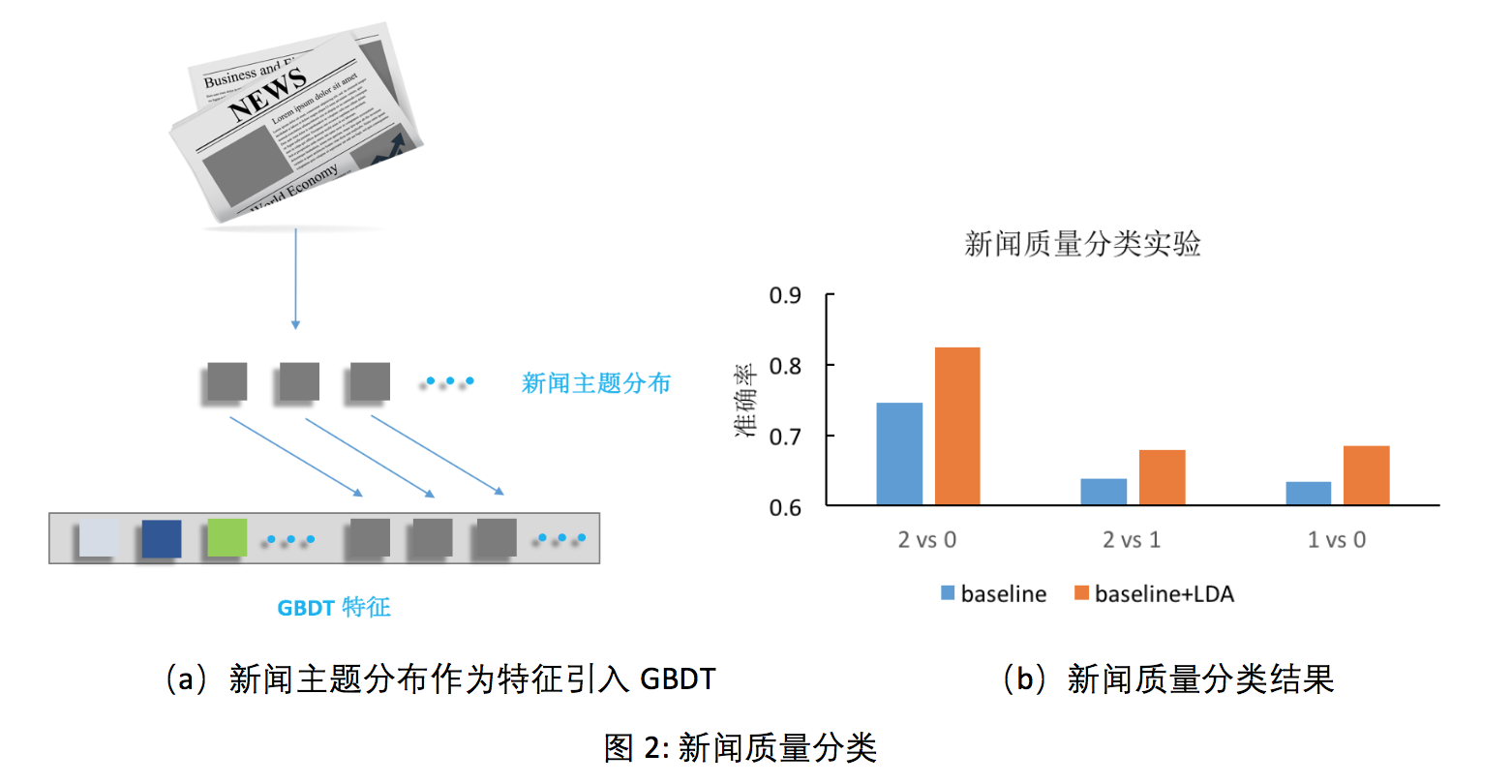
为了提升用户体验,我们通常会基于新闻特征,构建一个分类器来自动过滤低质量的新闻。从每篇新闻中,可提取一些传统特征:包括新闻来源站点、新闻内容长度、图片数量、新闻热度等其他人工设计的特征,这些特征组成了基础特征集合。除了这些传统特征,也可利用主题模型 (LDA 或 Supervised LDA) 来计算每篇新闻的主题分布,作为附加特征与基础特征一起组成新特征集合(图2(a))。我们的新闻质量数据集,包含了7000篇经过人工标注的新闻,质量共划分为3个档位,其中0档表示质量最差,2档表示质量最优。我们采用Gradient Boost Decision Tree (GBDT),基于5000篇已标注的新闻数据,分别利用基础特征集合和主题扩充后的特征集合 (经 LDA 或 Supervised LDA主题扩充) 进行训练,并在另外2000篇标注新闻数据上做验证实验。图2(b)展示了使用不同特征集合的三个分类器,在测试数据上的分类准确度:使用基础特征的baseline,以及进行了主题扩充的baseline+LDA和baseline+Supervised LDA。从这些实验结果可以看出,利用主题作为特征扩充可以有效提升分类器的效果。
文档的特征表示可看做是包含语义信息的一个降维过程,这些低维特征可以用来对文档进行聚类。我们使用LDA计算了1000篇新闻的主题分布,通过K-Means将文章聚类成10个簇,表3中展示了其中两个簇的部分结果。从表中可以看出,基于新闻的主题分布,可以很好的完成聚类,在簇1中显示的是与房子装修相关的新闻,簇2中则是聚集了与股票相关的新闻。

在一些文本挖掘工作中,我们需要衡量网页内容的丰富度,这时可以使用网页的主题分布来进行评估。通过计算网页的主题分布,进一步得到该分布的信息熵,作为衡量网页内容丰富度的指标。信息熵可衡量变量的确定性程度,若一个变量不确定性越大,其相应的信息熵会越大。基于主题模型,计算得到的网页主题分布,若概率平均分配到各个主题上,那么其信息熵最大,也就表示网页内容最丰富。若主题分布中,只有一个主题概率为1,其余主题的概率为0,那么得到的信息熵最低, 表示网页内容丰富度较低。基于文档特征表示,计算得到的网页内容丰富度,也可以作为一维特征引入到更为复杂的排序函数中。