Allow targets that depend on test results #11240
Comments
|
Test results and metadata (logs, undeclared outputs) are recorded in the build event output stream. Build event protocol is the API for observing events that happened during a build or test. https://docs.bazel.build/versions/master/build-event-protocol.html |
|
I was aware of the BEP, but I took a closer look just in case. However, I still don't see how it solves my problem. It may be a more reliable way for a |
|
We also have a similar request/need. Our specific use case/problem:
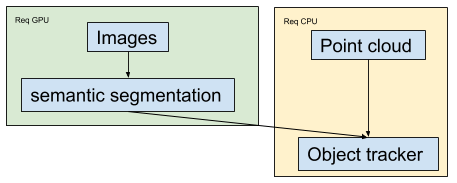
Detailed example: A second section of code runs that needs this metadata from the model output but also other data from test input data and combines them together. This part of the code only needs CPU and is quite expensive and uses also ~50% of total time. Example: There are other examples where we could use this kind of ability, like if a test takes a very long time to execute, we could potentially run two parts of the test independently of each other but not required to run in sequence (eg: if Semantic Segmentation has no state between frames, you could run one video file sharded across N nodes then combine them back together to perform aggregated statistics across all frames). This example is almost achievable using bazel's sharding, but since it cannot collect all the results and process them all at once it's not useful. One way we can make this work is to make a custom bazel rule that runs these steps as genrules or bzl rules then combine them together with a final |
|
Thank you for contributing to the Bazel repository! This issue has been marked as stale since it has not had any activity in the last 2+ years. It will be closed in the next 14 days unless any other activity occurs or one of the following labels is added: "not stale", "awaiting-bazeler". Please reach out to the triage team ( |
|
@bazelbuild/triage Not stale. |
|
Is there any progress on this? Especially the caching of long-running tests would help us save a lot of compute resources in such a divide-and-conquer scenario. |
|
Another use case I have.
2 depends on 1 So if on the first run 1 succeeds but 2 fails, I rerun it in canonize mode and 1 is cached, 2 updates the results. |
Description of the feature request:
We want to write a rule that consumes test results. Depending on a test target only gives access to the test executable and whatever other providers we implement, but there is no way to depend on the results of running the test.
Feature requests: what underlying problem are you trying to solve with this feature?
We have custom reporting and metrics that we want to extract from completed tests.
What operating system are you running Bazel on?
macOS and linux.
What's the output of
bazel info release?release 3.0.0Have you found anything relevant by searching the web?
No.
I have seen the built-in
bazel coveragesupport which generates a post-test action all within the Java, but it is not configurable enough to hijack for our needs. Side note: a design to provide generic support for post-test actions would remove the need for a baked-in special-case coverage action and open the door for community support for coverage that meets the needs of the diverse languages and targets that the community supports -- as well as supporting generic post-test reporting like what we require.The closest thing that I can come up with is to make a
bazel runtarget that pulls in the metadata for the tests from providers and adds them as rundata then looks in the testlogs location to extract the data from the test run, but this is extremely error prone since we either need to:bazel runscript which then needs to know all the correct options to pass along to thebazel testinvocation for the users setup.The text was updated successfully, but these errors were encountered: