Batch.Field.token_weight is indeed a single-precision float point number. This field should be use instead of a deprecated field Batch.Field.token_count, which was an integer field. The reason to represent token frequency by a float is because this data can be generated by certain algorithms, not necessary by parsing a plain text and counting occurrences. One example would be future hierarchical models that we hope to introduce in future versions of BigARTM.
The advice from #503 is not to call
tokens = model.score_tracker['Top100Tokens'].last_tokens[topic_name]
for each topic, instead call it once
tokens_for_topics = model.score_tracker['Top100Tokens'].last_tokens
and then work with the local copy.
This is a tricky question.
It is very good and useful feature for analysis of internal structure of documents (in JGibbsLDA library user can print the number of most probable topic and its probability).
p(t|w,d) are currently available via ARTM.transform(batch_vectorizer, theta_matrix_type='dense_ptdw') . You get back a flat theta matrix (no 3D) where each item has multiple columns - as many as the number of tokens in that document. These columns will have the same item_id . The order of columns with equal item_id is the same as the order of tokens in the input data ( batch.item.token_id ). In the future we will consider adding a separate API for this, for instance, to make function ARTM.detailed_decomposition(batch_vectorizer=None, theta_matrix_type='dense_theta', predict_class_id=None).
In the core of the library there is also a 'sparse_ptdw' mode which retrieves only the p(t|w,d') elements above certain threshold. However, this option is not exposed in python API yet. In the core the call with sparse_ptdw option should return a protobuf message ThetaMatrix containing topic_index field, described here: http://docs.bigartm.org/en/stable/ref/messages.html#ThetaMatrix.topic_index
Yes, it is. In the core it is exposed in FitOnlineMasterModelArgs.batch_weight field. In the python it goes to data_weightargument of theBatchVectorizer` constructor.
On Windows log files are written to you working folder (for example, the one where you launched ipython notebook). A straightforward way to find this out is to install free procmon utility from Sysinternals suite, and monitor process activity.
On Linux logs are also written to you working folder, perhaps to ~ or ~/..
It is possible to configure logging behaviour by calling ArtmConfigureLogging API with ConfigureLoggingArgs message.
This call must happen before any other calls to the other APIs, because some of the APIs will initialize logging by themselves. Only the first call to ArtmConfigureLogging can set logging directory. After that log dir remains unchanged. Any other parameter of the logging system can be changed at any point at runtime.
From Python you may configure logging as follows (require BigARTM v0.8.0)
# To configure logging folder
import artm
lc = artm.messages.ConfigureLoggingArgs()
lc.log_dir=r'C:\bigartm_log'
lib = artm.wrapper.LibArtm(logging_config=lc)
# To change any other logging parameters at runtime (except logging folder)
lc.minloglevel=2 # 0 = INFO, 1 = WARNING, 2 = ERROR, 3 = FATAL
lib.ArtmConfigureLogging(lc)
Why do I need to specify InitializeModelArgs.model_name even though I set MasterModelConfig.pwt_name?
In fact you don't have to do this -- BigARTM will fall back to MasterModelConfig.pwt_name if InitializeModelArgs.model_name is not set. Same logic applies to many other places where you find model_name argument (ex: ArtmOverwriteTopicModel, ScoreConfig.model_name). InitializeModelArgs.topic_name will default to MasterModelConfig.topic_name. Also, an empty FitOfflineMasterModelArgs.batch imply that the processing will be done across all in-memory batches imported via ArtmImportBatches call.
Overwrite.model_name
Currently there are two ways of custom initialization for Phi matrix.
Both methods are internal, but we encourage everyone to try them and report any issues.
First option is to initialize Phi matrix as usual, and then attach it to a numpy matrix via a special API (see below). This means that BigARTM will copy all values into the numpy matrix, and dispose the internal data structure responsible for Phi matrix. During ARTM.fit_offline or ARTM.fit_online BigARTM will read values from the numpy matrix. You may provide custom initial values by writing them directly into the numpy matrix.
The API to attach matrix is ARTM.master.attach_model. Normally you should pass in the ARTM.model_pwt (which gives the internal name of the p(w|t) matrix). As a result the API returns a pair of messages_pb2.TopicModel (protobuf message) and the numpy matrix. The TopicModel message is defined in messages.proto, and it returns meta-information about the Phi matrix (particularly it lists all tokens, their class_ids, and the names of the topics). The second value gives the attached numpy matrix.
Note that current implementation has certain issues, related to what operations can break the attachment. Some operations like ArtmMergeTopicModel may change the list of topics or the list of tokens. This naturally breaks the attachment, and restores the internal data structure that holds p(w|t) values. Most operations, however, does not change the layout of the matrix. Nevertheless such operations can still break the attachment. You may use ARTM.info call to verify whether the matrix is attached or not.
Second option is to use ARTM._lib.ArtmOverwriteTopicModel. This method may be called instead of ARTM.initialize. In this case it ArtmOverwriteTopicModel will create a new p(w|t) matrix instead of overwriting values in the existing matrix.
The method accepts an instance of messages_pb2.TopicModel protobuf message that contains all the values. See here for a somewhat obsolete but still relevant description of the TopicModel protobuf message.
Note that protobuf messages are limited to 2 GB. If you initialize large dense matrices then the first option (attach to numpy matrix) may be a better solution. For small matrices the second option might be more straightforward.
Refer to #520 if you get the following warning message (or similar).
I0408 00:41:54.154950 5248 perplexity.cc:124] Error in perplexity dictionary for token CHRYSLER, class @default_class. Verify that that token exists in the dictionary and it's value > 0. Document unigram model will be used for this token.
Use the following code:
# create score if you haven't do so yet
model.scores.add(artm.PerplexityScore(name='perplexity'))
# apply `transform` to process the held-out sample;
# don't create theta matrix to save memory
model.transform(batch_vectorizer=your_heldout_sample, theta_matrix_type=None)
# retrieve score with get_score(score_name)
perplexity = model.get_score('perplexity')
If the code above looks like magic, remember the following rules:
- Each ARTM model has its three separate caches: one for cumulative scores, another for scores history (aka
score_tracker) and a third one for caching theta matrix. - The cache for scores only store cumulative scores (e.g. only scores that depend on theta matrix). Examples are: perplexity or ThetaMatrixSparsity.
-
score_trackercontains the history for all scores (including non-cumulative scores). - Scores can be retrieved from the cache by
ARTM.get_score(). This method can be also used to calculate a non-cumulative score for the current version of the Phi matrix. - Score cache is reset at the beginning of
fit_offline,fit_onlineandtransformmethods. As a result,get_scorewill always return the score calculated during the last call tofit_offline,fit_onlineortransform. Forfit_onlinethe score produced byget_scorewill be accumulated across all batches passed tofit_online. - Score tracker is updated by
fit_offline(adds one extra point) andfit_online(adds multiple points - as many as there were synchronizations).transformnever adds points toscore_tracker. - Score tracker is never reset automatically. To reset the cache manually call
ARTM.master.clear_score_array_cache. - Theta matrix cache is updated by
fit_offline,fit_onlineandtransformmethods. The cache contains one entry per batch. If batch with the samebatch.idalready exist in the cache the entry will be overwritten by a new theta matrix (for that batch). - Theta matrix cache is reset at the beginning of
transformmethod whentransformis called withtheta_matrix_type=Cache. This is the only case when theta cache is reset --- all othertransformcalls, as well as calls tofit_offline/fit_onlinedo not reset theta matrix cache. - User may reset theta matrix cache by calling
ARTM.remove_theta(). - User may also reset score cache by calling
ARTM.master.clear_score_cache(however I can't see any scenario when this can be useful)
BigARTM hasn't fully establish its terminology. For example:
-
cumulative scoresandphi scoresrefers to the same thing;non-cumulative scoresandtheta scores -
modalityvsnamespacevsclass_id -
score_trackervsscore tracking functionalityvsscore array
========================
import artm
batch_vectorizer = artm.BatchVectorizer(data_path=r'D:\Datasets\kos',
data_format='batches')
dictionary = artm.Dictionary(data_path=r'D:\Datasets\kos')
model = artm.ARTM(num_topics=15,
num_document_passes=5,
dictionary=dictionary,
scores=[artm.PerplexityScore(name='s1')],
regularizers=[artm.SmoothSparseThetaRegularizer(name='r1', tau=-0.15)])
model.fit_offline(batch_vectorizer=batch_vectorizer,
num_collection_passes=3)
print(model.score_tracker['s1'].value)========================
batch = artm.messages.Batch()
batch_name = '3fd660d9-75e8-48fb-9410-20d734e4235a.batch'
train_folder = 'D:\Datasets\kos'
test_folder = 'D:\Datasets\kos_test'
with open(os.path.join(train_folder, batch_name), "rb") as f:
batch.ParseFromString(f.read())
# Delete all items except the first one
del batch.item[1:]
with open (os.path.join(test_folder, batch_name), "wb") as f:
f.write(batch.SerializeToString())========================
See here for further description of the batch format.
for item in batch.item:
for (token_id, token_weight) in zip(item.token_id, item.token_weight):
token = batch.token(token_id)
class_id = batch.class_id(token_id) # if you need the modality of the token
# now (token, class_id, token_weight)
# gives you everything you need to know about tokens of the item========================
# Simple, but wrong approach
model.class_ids['class_id'] = new_class_weight
# Right approach
temp_class_weights = model.class_ids
temp_class_weights['class_id'] = new_class_weight
model.class_ids = temp_class_weights========================
test_batch_vectorizer = artm.BatchVectorizer(data_path=r'D:\Datasets\kos_test')
model.transform(test_batch_vectorizer)========================
import numpy as np
def find_and_print_theta(batch, phi):
for item in batch.item:
field = item.field[0]
theta = np.ones((1, topic_size)) / topic_size
for i in xrange(iterationForDocument):
ntd = np.zeros((1, topic_size))
# use field.token_count for old batches (if token_weight is empty)
for token_id, token_weight in zip(field.token_id, field.token_weight):
token = batch.token[token_id]
if token not in phi.index:
continue
pwt = phi[token:token].values[0,:]
zw = sum(sum(theta * pwt))
if zw == 0:
continue
a = token_weight / zw
ntd = ntd + a * pwt
theta = theta * ntd
theta = theta + alpha
theta = np.maximum(theta, 0)
theta = theta / sum(sum(theta))
print theta- Батчи загружаются в библиотеку с помощью метода
ImportBatches. Он принимает сообщениеImprotBatchesArgs, которое просто перечисляет все батчи, которые нужно загрузить. Можно загружать батчи по одному или по несколько штук за раз - в моем примере они загружаются по одному. - Батчи идентифицируются своими
batch.id. Их нужно передать методуARTM.fit_offlineкак будто бы этиid--- это пути к батчам. В python-интерфейсе это не предусмотрено, но можно обманутьBatchVectorizer-- т.е. очистить его_batch_list, и руками указать там нужный нам список идентификаторов батчей. Заодно нужно очиститьbatch_vectorizer._weights, или указать там вектор весов батчей.
model = artm.ARTM(...)
// use whatever settings for batch vectorizer - we'll hack it later
batch_vectorizer = artm.BatchVectorizer(...)
batch_vectorizer._batches_list = []
batch_vectorizer._weights = None
for my_batch in my_batches:
import_batches_args = artm.messages_pb2.ImportBatchesArgs
import_batches_args.batch.append(my_batch)
batch_vectorizer._batches_list += my_batch.id()
#model.master.ImportBatches(import_batches_args) - use next line if this doesn't work
model._lib.ArtmImportBatches(artm_model.master.master_id, import_batches_args)
model.fit_offline(batch_vectorizer)from artm.batches_utils import Batch
class MyBatchVectorizer(object):
def __init__(self, batch_filename, data_path, batch_size):
self.data_path = data_path
self.batch_size = batch_size
self._batch_filename = [Batch(batch_filename)]
self._batches_list = [Batch(batch_filename)]
self._weights = [1.0]
@property
def batches_list(self):
return self._batches_list
@property
def weights(self):
return self._weights
@property
def num_batches(self):
return len(self._batches_list)
data_path = ...
batch_size = ...
batch_filenames = glob.glob(os.path.join(data_path, '*.batch'))
model_artm = artm.ARTM(...)
for batch in batch_filenames:
model_artm.fit_online(MyBatchVectorizer(batch, data_path, batch_size))==================================
Batch is an internal BigARTM's representation of the input data. Each batch contains one or more documents (Items), typically between 100 and 10000 items per batch. An easy way to create batches is to prepare a textual input in one of BigARTM formats, and then use an ArtmParseCollection to convert it into batches. Input formats assume that the original collection is already tokenized, lemmatized, cleaned from non-textual artifacts, etc. A good examples of the input data can be found on Downloads page.
It is also possible to generate batches manually, save and load them from disk. The batch is defined by the following Protobuf message:
message Batch {
repeated Item item = 1;
optional string id = 2;
repeated string token = 3;
repeated string class_id = 4;
optional string description = 5;
}
message Item {
optional int32 id = 1;
optional string title = 2;
repeated int32 token_id = 3;
repeated float token_weight = 4;
}Item.id is an optional identifier of an item, Item.title is an optional title of an item (optional field).
Item.token_id and Item.token_weight are repeated fields of the same length that give the number of occurrences of all terms in the item. Item.token_id must be zero-based.
The input data typically comes in Bag-of-word representation, for example as a set of triples doc_id, word_id, tf, where doc_id is an ID of the document, word_id is an id of a term from the document, and tf is the number of occurrences of the term in the document. Such triples assume that there is a global dictionary, which is not always the case - for example when crawling web content or when doing a map-reduce job to process a set of text files it might be necessary to generate a batch just based on a set of documents. To achieve this (and also for performance reasons) each Batch allows user to specify a list of all distinct words (Tokens) that occur across all items from the batch. Then in the item it is enough to enumerate the indices from Batch.token field.
There are APIs that allow BigARTM to stream batches from disk, and also APIs that can load batches into memory once to perform multiple scans.
However, in some scenarios users indeed have a global dictionary at the point where they generate batches. The don't want to replicate the global dictionary across all batches, nor they would like to write code that find a set of all distinct tokens present in the batch and re-index them according to batch dictionary. Ideally the users would like to put token IDs from the global dictionary into Batch.Item.Field.token_id , and keep field Batch.token empty. Then the global dictionary can be deployed via ArtmCreateDictionary / ArtmInitializeModel, and BigARTM should treat all batches as if their Batch.token field matches with DictionaryData.token .
Such batches will have limited usage (for example they must be rejected in ArtmGatherDictionary operation). The fix does some cheating - whenever it sees an empty Batch.token it populates it with the entire dictionary. This is not good for performance, but we will improve this later after cleaning up the code in processor.cc .
==================================
You may use Process Explorer tool to verify that your python script loads BigARTM from the expected location:
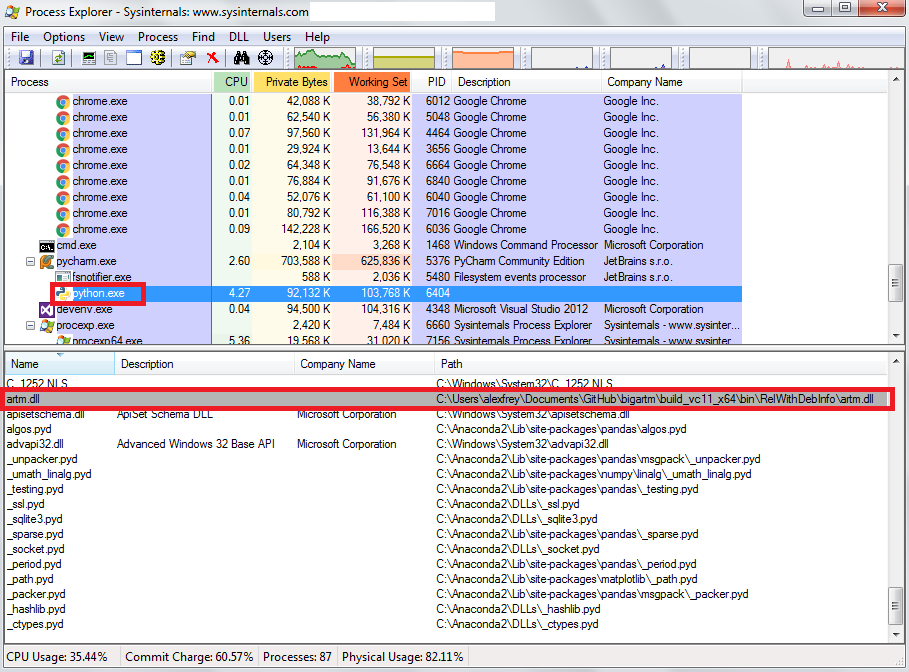 Typically the expected location is the one where you extracted BigARTM release package.
Typically the expected location is the one where you extracted BigARTM release package.
Yes, as long as your language has an implementation of Google Protocol Buffers (the list can be found [here] (https://code.google.com/p/protobuf/wiki/ThirdPartyAddOns)). Note that Google officially supports C++, Python and Java.
The following figure shows how to call BigARTM methods directly
on artm.dll (Windows) or artm.so (Linux).

To write your API please refer to C interface
Theta matrix is a matrix that contains the distribution of several items (columns of the matrix) into topics (rows of the matrix). There are three ways to retrieve such information from BigARTM, and the correct way depends on your scenario.
-
You want to get Theta matrix for the same collection as you have used to infer the topic model.
Set
MasterComponentConfig.cache_thetato true prior to the last iteration, and after the iteration useMasterComponent::GetThetaMatrix(in C++). -
You want to repeatedly monitor a small portion of the Theta matrix during ongoing iterations.
In this case you should create Theta Snippet score, defined via
ThetaSnippetScoreConfig, and then useMasterComponent::GetScoreAsto retrieve the resultingThetaSnippetScoremessage.This configuration of Theta Snippet score require you to provide
ThetaSnippetScoreConfig.item_idlisting all IDs of the items that should have Theta's collected. If you created the batches manually you should have specified such IDs inItem.idfield. If you used other methods to parse the collection from disk then you shouldn't try using sequential IDs, starting with 1.Remember that Theta snippet score is designed to handle only a small number of items. Attemp to retrieve 100+ items will have a negative effect on performance.
-
You want to classify a new set of items with an existing model.
In this case you need to create a
Batch, containing your new items. Then copy this batch toGetThetaMatrixArgs.batchmessage, specifyGetThetaMatrixArgs.model_name, and useMasterComponent::GetThetaMatrix(in C++) to retrieve Theta matrix. In this case there is no need setMasterComponentConfig.cache_thetato true.
You start as usual by fitting the model:
import artm
from pandas import DataFrame
batch_vectorizer = artm.BatchVectorizer(data_path=r'C:\bigartm\data',
data_format='bow_uci',
collection_name='kos')
model = artm.ARTM(num_topics=15,
num_document_passes=5,
dictionary=batch_vectorizer.dictionary,
scores=[artm.PerplexityScore(name='s1')],
regularizers=[artm.SmoothSparsePhiRegularizer(name='r1', tau=-0.05)])
model.fit_offline(batch_vectorizer=batch_vectorizer,
num_collection_passes=3)
print model.score_tracker['s1'].value
Now we assume that you are familiar with the main regularizaiton formula pwt = norm(nwt + rwt).
We should define a name for the matrix with regularization coefficients
rwt_name = 'rwt'
As an optional step - retrieve pwt matrix and look at (0, 0) element. In the following code we are going to calculate pwt from "pwt = norm(nwt + rwt)" formula. This is done by BigARTM methods "master.regularize_model" and "master.normalize_model". Nice to double-check that these methods reproduce the same pwt.iloc[0, 0] as you get from model.fit_offline
pwt = model.get_phi(model_name=model.model_pwt) # this is the same as model.get_phi()
print pwt.iloc[0, 0]
Calculate "rwt" matrix with the same weights as you put in the model (this is done internally in fit_offline, however it removes rwt matrix in v0.8.2 we will give you an option to preserve rwt matrix after fit_offline, and then regularize_model step will be redundant)
model.master.regularize_model(pwt=model.model_pwt, nwt=model.model_nwt, rwt=rwt_name,
regularizer_name=['r1'], regularizer_tau=[-0.05])
At this point 'rwt' model is not exposed to python, its internaltype is DensePhiMatrix - as you may check like this:
print [x.type for x in model.info.model if x.name == 'rwt']
You may attach the 'rwt' model to data frame as follows, which switches its internal type to AttachedPhiMatrix
After that you may edit it.
(meta, nd_array) = model.master.attach_model('rwt')
attached_rwt = DataFrame(data=nd_array, columns=meta.topic_name, index=meta.token)
# Edit the rwt matrix
attached_rwt.iloc[0, 0] = 1000
# Calculate pwt = norm(nwt + rwt)
model.master.normalize_model(pwt=model.model_pwt, nwt=model.model_nwt, rwt=rwt_name)
Now you are done --- the pwt matrix should include your custom regularization.
To double-check, look once again at pwt.iloc[0, 0].
If you didn't edit attached_rwt then it will be consistent with the original pwt, calculated by fit_offline
But if you did edit rwt matrix then it will be different -- because it incorporates your custom regularization coefficients.
Use ARTM.transform_sparse() method.
Q: How to get rid of these warnings?
C:\Program Files\Anaconda3\lib\site-packages\tqdm\_tqdm.py:65: DeprecationWarning: sys.getcheckinterval() and sys.setcheckinterval() are deprecated. Use sys.setswitchinterval() instead.
sys.setcheckinterval(100)
A: Thie warnings are due to tqdm library. To filter them out you may run you code under warnigns filter:
import warnings
with warnings.catch_warnings():
warnings.filterwarnings("ignore",category=DeprecationWarning)
<your code>
The steps below assume that BigARTM release package for windows is unpacked into C:\BigARTM.
- Copy
C:\BigARTM\bin\protoc.exefile intoC:\BigARTM\protobuf\srcfolder - Run the following commands from command prompt
cd C:\BigARTM\protobuf\Python
python setup.py build
python setup.py install
Avoid python setup.py test step, as it produces several confusing errors. Those errors are harmless.
For further details about protobuf installation refer to protobuf/python/README.
Basically, you could use ARTM.reshape() operation,
and pass a new dictionary that contains tokens you want to have in the model.
The only trick is, you have to call ARTM.fit_offline() after changing the set of tokens,
because new tokens needs to be initialized based on the collection.
import artm
import os
batches = r'H:\datasets\nytimes_batches'
if not os.path.exists(batches):
batch_vectorizer = artm.BatchVectorizer(data_path=r'H:\datasets', collection_name='nytimes', data_format='bow_uci',
target_folder=batches, batch_size=1000)
dictionary = artm.Dictionary(data_path=batches)
dictionary.save(dictionary_path=os.path.join(batches, 'dict.dict'))
batch_vectorizer = artm.BatchVectorizer(data_path=batches, data_format='batches')
dictionary = artm.Dictionary(dictionary_path=os.path.join(batches, 'dict.dict'))
d1 = artm.messages.DictionaryData(name="dict1") # start from z
d2 = artm.messages.DictionaryData(name="dict2")
dictionary_data = dictionary._master.get_dictionary(dictionary._name)
for (token, class_id) in zip(dictionary_data.token, dictionary_data.class_id):
if token.startswith('zzz_'):
d1.token.append(token); d1.class_id.append(class_id)
else:
d2.token.append(token); d2.class_id.append(class_id)
print('First dictionary: {} tokens, second dictionary: {} tokens'.format(len(d1.token), len(d2.token)))
d1_dict = artm.Dictionary()
d1_dict.create(d1)
d2_dict = artm.Dictionary()
d2_dict.create(d2)
def show_top_tokens(model, num_tokens=10):
model.scores.add(artm.TopTokensScore(name='top_tokens_score', num_tokens=num_tokens), overwrite=True)
tts = model.get_score('top_tokens_score')
tts_map = {t : [] for t in model.topic_names}
for (topic_name, topic_index, token, weight) in zip (tts.topic_name, tts.topic_index, tts.token, tts.weight):
tts_map[topic_name].append(token.replace('zzz_', ''))
for topic in model.topic_names:
print('{}: {}'.format(topic, ', '.join(tts_map[topic])))
model=artm.ARTM(num_topics=7, dictionary=d1_dict,
scores=[artm.PerplexityScore(name='PerplexityScore')],
regularizers=[artm.DecorrelatorPhiRegularizer(name='DecorrelatorPhi', tau=1000)] )
for i in range(5):
model.fit_offline(batch_vectorizer=batch_vectorizer)
print('Perplexity on {} iteration: {}'.format(i+1, model.score_tracker['PerplexityScore'].last_value))
print('Before reshape:')
show_top_tokens(model)
model.reshape(dictionary=d2_dict)
model.fit_offline(batch_vectorizer=batch_vectorizer)
print('\nAfter reshape:')
show_top_tokens(model)
Result:
First dictionary: 57216 tokens, second dictionary: 44420 tokens
Perplexity on 1 iteration: 466.70635986328125
Perplexity on 2 iteration: 357.28851318359375
Perplexity on 3 iteration: 345.752197265625
Perplexity on 4 iteration: 337.7331237792969
Perplexity on 5 iteration: 332.9988098144531
Before reshape:
topic_0: laker, dodger, met, red_sox, nba, texas, new_york, arizona, houston, kobe_bryant
topic_1: new_york, tiger_wood, manhattan, london, hollywood, american, los_angeles, new_york_city, america, chicago
topic_2: united_states, u_s, china, american, enron, russia, japan, russian, america, bush
topic_3: bush, al_gore, george_bush, texas, white_house, senate, congress, republican, florida, washington
topic_4: internet, microsoft, black, mexico, washington, eastern, congress, social_security, medicare, vicente_fox
topic_5: israel, israeli, yasser_arafat, united_states, fbi, palestinian, nbc, nfl, west_bank, iraq
topic_6: afghanistan, taliban, u_s, american, united_states, bush, new_york, pakistan, washington, america
After reshape:
topic_0: team, season, game, player, play, run, games, point, right, hit
topic_1: show, company, million, percent, film, play, part, school, home, look
topic_2: company, percent, million, official, government, market, companies, country, right, group
topic_3: president, campaign, percent, election, right, political, million, republican, official, law
topic_4: company, percent, com, million, companies, computer, business, web, market, need
topic_5: palestinian, official, team, show, season, right, game, million, attack, play
topic_6: official, percent, government, attack, million, group, military, war, country, american
# Create model and initialize/fit or load previously saved model from disk
model = artm.ARTM(..)
model.load(...)
# Create a batch with new items
batch = artm.messages.Batch()
batch.id = str(uuid.uuid4())
# add all unique tokens (and their class_id) to batch.token and batch.class_id
for token, class_id in ...
batch.token.append(token)
batch.class_id.append(class_id)
# Create an item (multiple items per batch is also OK)
item = batch.item.add()
item.title = "item's title"
for token_id, token_weight in ....
item.token_id.append(token_id) # token_id refers to an index in batch.token
item.token_weight.append(token_weight)
# Now batch is ready. Create batch vectorizer that will store it in the memory of the model.
batch_vectorizer = BatchVectorizer(batches=[batch], process_in_memory_model=model)
model.transform(batch_vectorizer=batch_vectorizer)
# Batches format are briefly described here.
# http://bigartm.readthedocs.io/en/stable/tutorials/datasets.html
# For an example, look here:
# https://github.com/bigartm/bigartm/blob/master/python/artm/hierarchy_utils.py#L568