Organisasi Kesehatan Dunia (WHO) memperkirakan 12 juta kematian terjadi di seluruh dunia, setiap tahun karena penyakit jantung [1]. Setengah dari kematian di Amerika Serikat dan negara maju lainnya disebabkan oleh penyakit kardiovaskular [2]. Prognosis awal penyakit kardiovaskular dapat membantu dalam membuat keputusan tentang perubahan gaya hidup pada pasien berisiko tinggi dan pada gilirannya mengurangi komplikasi [3]. Penelitian ini bertujuan untuk menunjukkan dengan tepat faktor - faktor risiko penyakit jantung yang paling relevan, serta memprediksi risiko secara keseluruhan menggunakan Logistic Regression.
Pada proyek ini, dataset berasal dari situs web Kaggle, dan bersumber dari studi kardiovaskular yang berlangsung pada penduduk kota Framingham, Massachusetts. Tujuannya adalah untuk memprediksi apakah pasien memiliki risiko penyakit jantung koroner (PJK) dalam 10 tahun mendatang. Dataset ini menyediakan informasi pasien yang mencakup lebih dari 4.000 catatan dan 15 atribut.
- Bagaimana cara prediksi apakah seseorang beresiko menderita penyakit jantung atau tidak dalam beberapa tahun kedepan dari statistik kesehatannya?
- Memprediksi apakah seseorang memiliki resiko menderita penyakit jantung atau tidak dalam beberapa tahun kedepan dari statistik kesehatannya.
-
Menggunakan metode Logistic Regression, dimana metode ini merupakan metode yang efektif untuk melakukan klasifikasi yang outputnya hanya 0 dan 1 atau True/False.
-
Menggunakan metode Random Forest, dimana metode ini simpel untuk diimplementasikan, namun powerful. Maka dari itu, Random Forest digunakan sebagai pembanding dari Logistic Regression.
-
Sebagai pembanding, menggunakan dua metrik antara lain Nilai Akurasi dan Mean Squared Error.
Dataset yang digunakan adalah Heart Diseases yang bersumber dari Kaggle. Dikutip dari algorit.ma, Analisis Data Eksplorasi mencakup proses kritis uji investigasi pendahuluan pada data untuk mengidentifikasi pola, menemukan anomali, menguji hipotesis, dan memeriksa asumsi melalui statistik ringkasan dan representasi visual.
-
Dataset ini terdiri dari 4238 baris data, dan memiliki 16 kolom data. Berikut adalah pengecekan jumlah baris dan kolom pada dataset dengan menggunakan memanggil variabel data yang telah dideklarasikan.
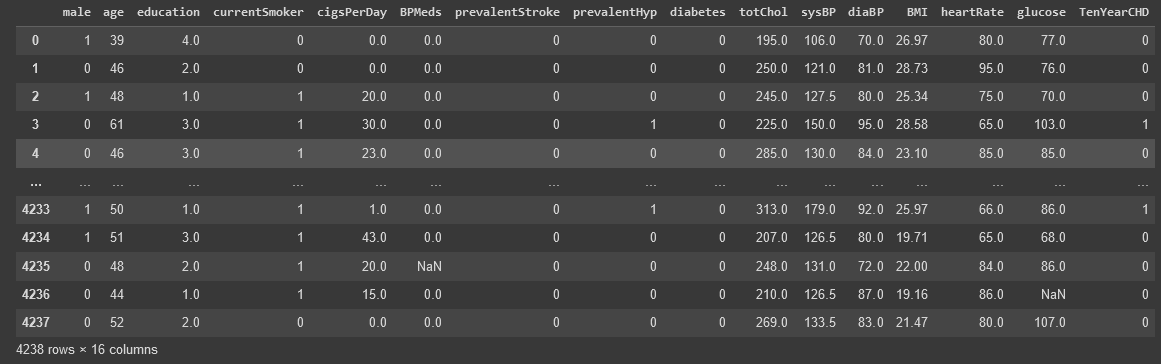
-
Dataset memiliki beberapa nilai kosong atau NaN yang perlu dilakukan penanganan.
Kolom Jumlah NaN male 0 age 0 currentSmoker 0 cigsPerDay 29 BPMeds 53 prevalentStroke 0 prevalentHyp 0 diabetes 0 totChol 50 sysBP 0 diaBP 0 BMI 19 heartRate 1 glucose 388 TenYearCHD 0
Dataset ini, ada 10 variabel dengan 9 fitur dan 1 label sebagai berikut.
-
Berdasarkan Demografi:
Fitur Penjelasan Sex Jenis kelamin Age usia -
Berdasarkan Perilaku Responden:
Fitur Penjelasan Current Smoker Perokok atau bukan Cigs Per Day Konsumsi batang rokok perhari BP Meds Apakah mengambil Blood Pressure Medication atau tidak Prevalent Stroke Pernah stroke atau tidak Prevalent Hyp Pernah hipertensi atau tidak Diabetes Pernah diabetes atau tidak -
Berdasarkan Statistika:
Fitur Penjelasan Tot Chol Total level kolesterol Sys BP Tekanan darah systolic Dia BP tekanan darah diastolic BMI Body Mass Index atau indeks massa tubuh Heart Rate Heart rate atau detak jantung Glucose Level gula darah (Continuous) -
Berdasarkan Variabel prediksi:
Fitur Penjelasan TenYearCHD 10 tahun risiko penyakit jantung koroner
Untuk menjelaskan korelasi fitur – fitur pada dataset, diperlukan visualisasi data yang terdiri sebagai berikut. Namun, ada baiknya untuk melihat NaN values yang dimiliki oleh dataset dan dilakukan penanganan. Menurut DQLab.id, nilai NaN akan membuat data tidak dapat digunakan, dan sayang untuk dibuang begitu saja. Informasi penting di banyak baris hanya karena 1-2 nilai yang hilang, jadi salah satu langkah yang tepat adalah mengisi nilai yang hilang. Pengisian data menggunakan median akan membantu “menetralisir” data yang hilang, karena pengisian median tidak akan menggeser atau menambah varians data.
| Kolom | Jumlah NaN |
|---|---|
| male | 0 |
| age | 0 |
| currentSmoker | 0 |
| cigsPerDay | 29 |
| BPMeds | 53 |
| prevalentStroke | 0 |
| prevalentHyp | 0 |
| diabetes | 0 |
| totChol | 50 |
| sysBP | 0 |
| diaBP | 0 |
| BMI | 19 |
| heartRate | 1 |
| glucose | 388 |
| TenYearCHD | 0 |
-
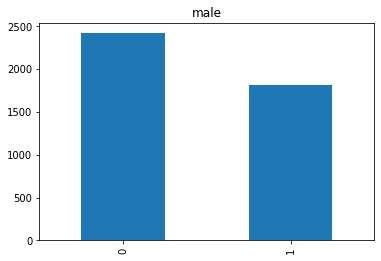
Barplot Pertama
Pada barplot pertama yang ada pada notebook, dapat disimpulkan bahwa lebih sedikit responden yang berjenis kelamin male.
-
Barplot Kedua
Pada barplot kedua yang ada pada notebook, dapat disimpulkan bahwa responden yang bukan perokok sedikit lebih tinggi dibandingkan responden yang merupakan perokok.
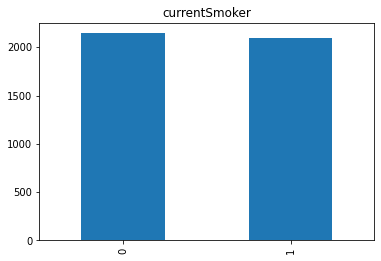
-
Barplot Ketiga
Pada barplot ketiga, dapat disimpulkan bahwa responden yang tidak memiliki riwayat stroke lebih tinggi dibandingkan responden yang memiliki riwayat stroke.

-
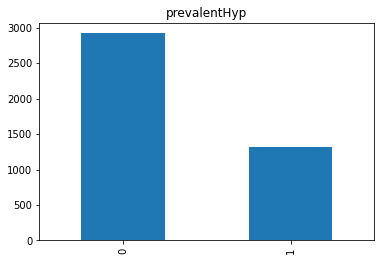
Barplot Keempat
Pada barplot keempat, dapat disimpulkan bahwa responden yang tidak memiliki riwayat hipertensi lebih tinggi dibandingkan responden yang memiliki riwayat hipertensi.
-
Barplot Kelima
Pada barplot kelima, dapat disimpulkan bahwa responden yang tidak memiliki riwayat diabetes lebih tinggi dibandingkan responden yang memiliki riwayat diabetes.
-
Barplot Keenam
Pada barplot kelima, dapat disimpulkan bahwa responden yang tidak memiliki resiko penyakit jantung dalam kurun 10 tahun kedepan lebih tinggi dibandingkan responden yang memiliki resiko penyakit jantung dalam kurun 10 tahun kedepan.
-
Barplot Ketujuh
Pada barplot keenam, dapat diketahui fitur numerical responden yang memiliki resiko penyakit jantung.S
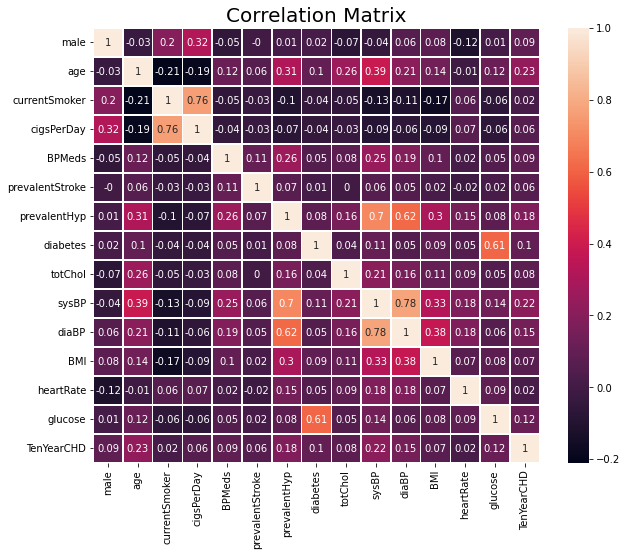
Dari heatmap pada notebook berikut ini, dapat terlihat bahwa semua fitur berkorelasi.
Dalam data preparation, dilakukan beberapa hal berikut sebelum memasukkan data ke model latih:
-
Drop column yang kurang relevan
Drop column yang kurang relevan. Hal ini akan membantu efektivitas dalam fitting model yang dilakukan. Pada dataset ini, seperti yang ditunjukkan pada gambar dbawah, kolom "education" tidak memiliki pengaruh pada hasil prediksi kasus penyakit jantung sehingga perlu dilakukan proses drop pada kolom tersebut.
-
Mengisi missing value dengan median
Pengisian data dengan menggunakan median akan membantu "menetralkan" data yang hilang, karena pengisian median tidak akan menggeser atau menambah varians dari data. Pada tabel berikut ini adalah beberapa kolom pada dataset yang memiliki missing value.
Kolom Jumlah NaN cigsPerDay 29 BPMeds 53 totChol 50 BMI 19 heartRate 1 glucose 388 Pada proyek ini, dataset akan di isi menggunakan fungsi "fillna()" dengan nilai median, dimana nilai median dapat dipanggil menggunakan fungsi "median()".
-
Train-Test-Split
Membagi dataset menjadi data train dan data test dilakukan supaya kita dapat melakukan validasi dengan benar tanpa bias dari model. Pada proyek ini proses pembagian antara data train dan data test menggunakan teknik pengambilan sampel secara acak (Random Sampling) dengan rasio data test sebesar 25% dari jumlah data bersih atau data yang telah dilakukan proses cleaning sebelumnya.
Data Jumlah Data bersih 4238 Data training 3178 Data testing 1060 -
Standarisasi
Scaling ini dilaksanakan untuk membantu model machine learning yang akan dipakai lebih mudah diolah. Pada proyek ini, digunakanlah StandardScaler sebagai fitur standarisasi. Proses standarisasi ini dilakukan pada kolom-kolom berfitur numerical seperti cigsPerDay, totChol, sysBP, diaBP, BMI, heartRate, dan glucose.
Model – model yang saya pakai dalam projek ini adalah:
-
Logistic Regression
Logistic Regression adalah sebuah algoritma klasifikasi di mana algoritma ini mencari hubungan antar fitur diskrit atau kontinu dengan probabilitias hasil output diskrit tertentu. Pada proyek ini, data training digunakan sebagai parameter dan nilai max_iter nya adalah 1000.
-
Random Forest
Random Forest merupakan algoritma yang menggabungkan keluaran dari beberapa pohon keputusan untuk mencapai satu hasil dengan dibentuk dari banyak pohon (tree) yang diperoleh melalui proses bagging atau bootstrap aggregating. Pada proyek ini, data training digunakan sebagai parameter dan nilai n_estimators nya adalah 1000, max_depth nya adalah 16, random_state nya adalah 55, n_jobs nya adalah 1.
Berikut adalah hasil akurasi dari kedua model:
| Model | Accuracy |
|---|---|
| Logistic Regression | 0.864 |
| Random Forest | 0.028 |
Penggunaan Logistic Regression dalam data terbukti lebih baik berdasarkan metrik akurasi yang diberikan. Namun terdapat anomali berupa MSE dari Logistic Regression yang lebih tinggi dari Random Forest. Dari hasil pemodelan ini, Logistic Regression dipilih sebagai model yang akan digunakan dalam prediksi PJK.
Sebelum ke metrik evaluasi, ada istilah confusion matrix dimana di dalam confusion matrix, terdapat 4 kesimpulan yang dapat di ambil sebagai berikut.
| Confusion Matrix | Penjelasan |
|---|---|
| True Positive (TP) | Jumlah prediksi positif yang benar terhadap jumlah positif yang sebenarnya |
| False Positive (FP) | Jumlah prediksi positif yang salah |
| True Negative (TN) | Jumlah prediksi negatif yang benar terhadap jumlah negatif yang sebenarnya |
| False Negative (FN) | Jumlah prediksi negatif yang salah |
Dalam projek ini, metrik evaluasi yang idgunakan adalah sebagai berikut.
-
Accuracy
Akurasi adalah metrik yang paling umum dalam pemodelan klasifikasi. Ini adalah persentase jumlah data yang diprediksi dengan benar terhadap jumlah total data. -
MSE
Mean Squared Error (MSE) adalah rata-rata kesalahan kuadrat diantara nilai aktual dan nilai prediksi. Metode Mean Squared Error secara umum digunakan untuk mengecek estimasi berapa nilai kesalahan pada predoksi.
Berikut adalah hasil akurasi model:
| Model | Accuracy |
|---|---|
| Logistic Regression | 0.864 |
| Random Forest | 0.028 |
Berikut adalah hasil MSE model:
| Model | Train | Test |
|---|---|---|
| Logistic Regression | 0.000148 | 0.000136 |
| Random Forest | 0.000025 | 0.000119 |
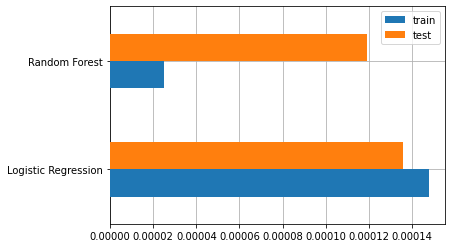
Kesimpulan dari hasil proyek predictive analytic Heart Diseases ini adalah sebagai berikut.
- Pria lebih rentan terhadap penyakit jantung daripada wanita. Peningkatan Usia, jumlah rokok yang dihisap per hari dan Tekanan Darah systolic juga menunjukkan peningkatan kemungkinan terkena penyakit jantung.
- Model terbaik, yaitu Logistic Regression memprediksi dengan akurasi 86,4%.
- Hasil prediksi mungkin akan lebih baik apabila data lebih banyak.
[1] T. Suryadi, “KEMATIAN MENDADAK KARDIOVASKULER,” Jurnal Kedokteran Syiah Kuala, vol. 17, no. 2, 2017, doi: 10.24815/jks.v17i2.8990.
[2] F. A. Gobel dan R. Mahkota, “Faktor-faktor yang Mempengaruhi Kematian Pasien Penyakit Jantung Koroner di Pusat Jantung Nasional Harapan Kita Tahun 2004,” Kesmas: National Public Health Journal, vol. 1, no. 3, 2006, doi: 10.21109/kesmas.v1i3.303.
[3] KEMENTRIAN KESEHATAN RI, “Penyakit Jantung Penyebab Kematian Tertinggi, Kemenkes Ingatkan Cerdik,” Kementrian Kesehatan Republik Indonesia, 2017.