Channel Pruning via Automatic Structure Search (Link)
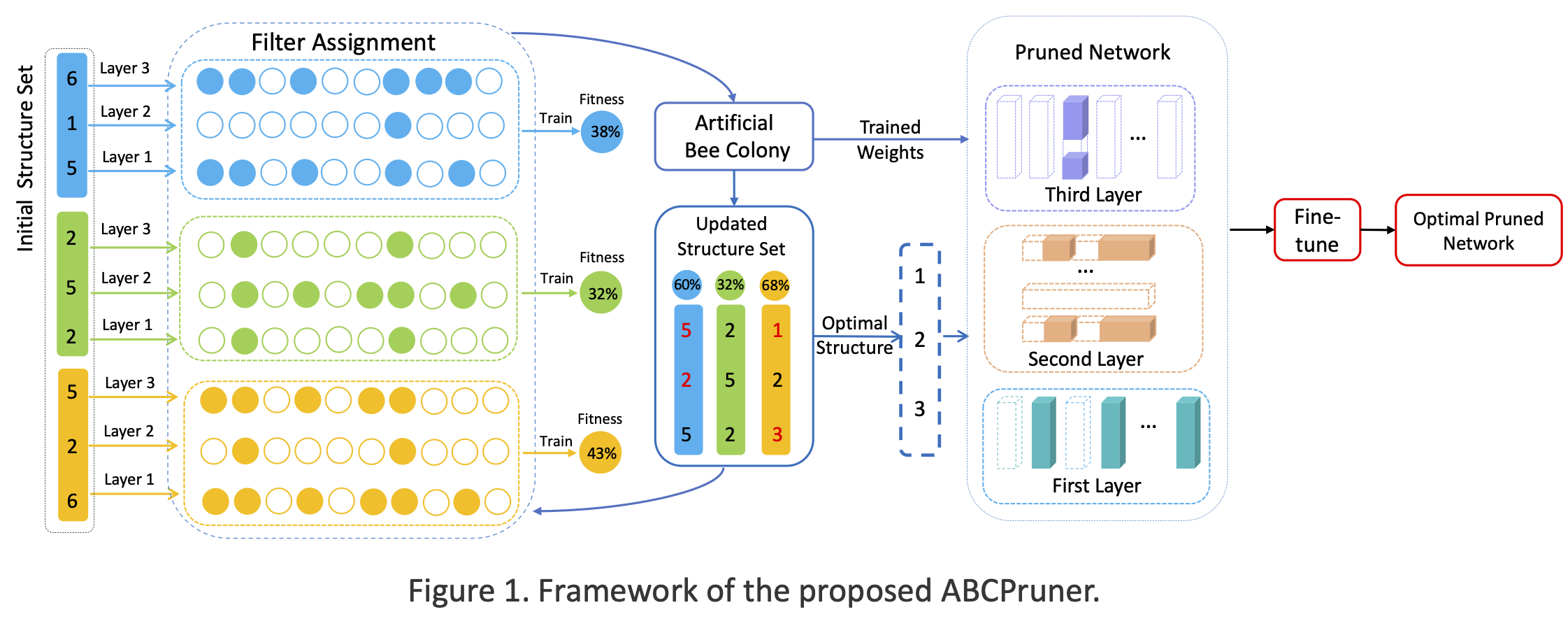
Channel pruning via artificial bee colony (ABC) in an automatic manner.
Any problem, free to contact the authors via emails: lmbxmu@stu.xmu.edu.cn or yxzhangxmu@163.com, or adding the first author's wechat as friends (id: lmbcxy if you are using wechat) for convenient communications. Do not post issues with github as much as possible, just in case that I could not receive the emails from github thus ignore the posted issues.
If you find ABCPruner useful in your research, please consider citing:
@article{lin2020channel,
title={Channel Pruning via Automatic Structure Search},
author={Lin, Mingbao and Ji, Rongrong and Zhang, Yuxin and Zhang, Baochang and Wu, Yongjian and Tian, Yonghong},
journal={arXiv preprint arXiv:2001.08565},
year={2020}
}
We provide our pruned models in the paper and their training loggers and configuration files below.
(The percentages in parentheses indicate the pruned proportion)
| Full Model | Params | Flops | Channels | Accuracy | Pruned Model |
|---|---|---|---|---|---|
| VGG16 | 1.67M(88.68%) | 82.81M(73.68%) | 1639(61.20%) | 93.08% | ABCPruner-80% |
| ResNet56 | 0.39M(54.20%) | 58.54M(54.13%) | 1482(27.07%) | 93.23% | ABCPruner-70% |
| ResNet110 | 0.56M(67.41%) | 89.87M(65.04%) | 2701(33.28%) | 93.58% | ABCPruner-60% |
| GoogLeNet | 2.46M(60.14%) | 513.19M(66.56) | 6150(22.19%) | 94.84% | ABCPruner-30% |
| Full Model | Params | Flops | Channels | Acc Top1 | Acc Top5 | Pruned Model |
|---|---|---|---|---|---|---|
| ResNet18 | 6.6M(43.55%) | 1005.71M(44.88%) | 3894(18.88%) | 67.28% | 87.28% | ABCPruner-70% |
| ResNet18 | 9.5M(18.72%) | 968.13M(46.94%) | 4220(12%) | 67.80% | 88.00% | ABCPruner-100% |
| ResNet34 | 10.52M(51.76%) | 1509.76M(58.97%) | 5376(25.09%) | 70.45% | 89.688% | ABCPruner-50% |
| ResNet34 | 10.12M(53.58%) | 2170.77M(41%) | 6655(21.82%) | 70.98% | 90.053% | ABCPruner-90% |
| ResNet50 | 7.35M(71.24%) | 944.85M(68.68%) | 20576(25.53%) | 70.289% | 89.631% | ABCPruner-30% |
| ResNet50 | 9.1M(64.38%) | 1295.4M(68.68%) | 21426(19.33%) | 72.582% | 90.19% | ABCPruner-50% |
| ResNet50 | 11.24M(56.01%) | 1794.45M(56.61%) | 22348(15.86%) | 73.516% | 91.512% | ABCPruner-70% |
| ResNet50 | 11.75(54.02%) | 1890.6M(54.29%) | 22518(15.22%) | 73.864% | 91.687% | ABCPruner-80% |
| ResNet50 | 18.02(29.5%) | 2555.55M(38.21%) | 24040(9.5%) | 74.843% | 92.272% | ABCPruner-100% |
| ResNet101 | 12.94M(70.94%) | 1975.61M(74.89%) | 41316(21.56%) | 74.76% | 92.08% | ABCPruner-50% |
| ResNet101 | 17.72M(60.21%) | 3164.91M(59.78%) | 43168(17.19%) | 75.823% | 92.736% | ABCPruner-80% |
| ResNet152 | 15.62M(74.06%) | 2719.47M(76.57%) | 58750(22.4%) | 76.004% | 92.901% | ABCPruner-50% |
| ResNet152 | 24.07M(60.01%) | 4309.52M(62.87%) | 62368(17.62%) | 77.115% | 93.481% | ABCPruner-70% |
- Pytorch >= 1.0.1
- CUDA = 10.0.0
Additionally, we provide several pre-trained models used in our experiments.
| VGG16 | ResNet56 | ResNet110 |GoogLeNet |
|ResNet18 | ResNet34 | ResNet50 |ResNet101 | ResNet152|
python bee_imagenet.py
--data_path ../data/ImageNet2012
--honey_model ./pretrain/resnet18.pth
--job_dir ./experiment/resnet_imagenet
--arch resnet
--cfg resnet18
--lr 0.01
--lr_decay_step 75 112
--num_epochs 150
--gpus 0
--calfitness_epoch 2
--max_cycle 50
--max_preserve 9
--food_number 10
--food_limit 5
--random_rule random_pretrainpython get_flops_params.py
--data_set cifar10
--arch resnet_cifar
--cfg resnet56
--honey 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 # honey is the optimal pruned structure and can be found in the training logger.python bee_imagenet.py
--data_path ../data/ImageNet2012
--job_dir ./experiment/resnet_imagenet
--arch resnet
--cfg resnet18
--test_only
-- gpus 0
--honey_model ./pretrain/resnet18.pth #path of the pre-trained model.
--best_honey 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 # honey is the optimal pruned structure and can be found in the training logger.
--best_honey_s ./pruned/resnet18_pruned.pth # path of the pruned model. optional arguments:
-h, --help show this help message and exit
--gpus GPUS [GPUS ...]
Select gpu_id to use. default:[0]
--data_set DATA_SET Select dataset to train. default:cifar10
--data_path DATA_PATH
The dictionary where the input is stored.
default:/home/lishaojie/data/cifar10/
--job_dir JOB_DIR The directory where the summaries will be stored.
default:./experiments
--reset Reset the directory?
--resume RESUME Load the model from the specified checkpoint.
--refine REFINE Path to the model to be fine tuned.
--arch ARCH Architecture of model. default:vgg,resnet,googlenet,densenet
--cfg CFG Detail architecuture of model. default:vgg16, resnet18/34/50(imagenet),resnet56/110(cifar),googlenet,densenet
--num_epochs NUM_EPOCHS
The num of epochs to train. default:150
--train_batch_size TRAIN_BATCH_SIZE
Batch size for training. default:128
--eval_batch_size EVAL_BATCH_SIZE
Batch size for validation. default:100
--momentum MOMENTUM Momentum for MomentumOptimizer. default:0.9
--lr LR Learning rate for train. default:1e-2
--lr_decay_step LR_DECAY_STEP [LR_DECAY_STEP ...]
the iterval of learn rate decay. default:30
--weight_decay WEIGHT_DECAY
The weight decay of loss. default:5e-4
--random_rule RANDOM_RULE
Weight initialization criterion after random clipping.
default:default
optional:default,random_pretrain,l1_pretrain
--test_only Test only?
--honey_model Path to the model wait for Beepruning. default:None
--calfitness_epoch Calculate fitness of honey source: training epochs. default:2
--max_cycle Search for best pruning plan times. default:10
--food_number number of food to search. default:10
--food_limit Beyond this limit, the bee has not been renewed to become a scout bee default:5
--honeychange_num Number of codes that the nectar source changes each time default:2
--best_honey If this hyper-parameter exists, skip bee-pruning and fine-tune from this prune method default:None
--best_honey_s Path to the best_honey default:None
--best_honey_past If you want to load a resume without honey code, input your honey hode into this hyper-parameter default:None
--honey get flops and params of a model with specified honey(prune plan )
--from_scratch if this parameter exist, train from scratch
--warm_up if this parameter exist, use warm up lr like DALI
--bee_from_scratch if this parameter exist, beepruning from scratch
--label_smooth if this parameter exist, use Lable smooth criterion
--split_optimizer if this parameter exist, split the weight parameter that need weight decay