ARC: 自动引用计数, MRC:手动引用计数
在MRC时代,开发者通过retain, release, autorelease这些函数,手动的控制引用计数。
而ARC将开发者从这个工作中解放出来,在编译期间,自动插入这些函数调用。
ARC是一个编译器的特性。
ARC引入了一些新的修饰关键字,如strong, weak。
不管是ARC还是MRC,内存管理的方式并没有改变。
-
动态类型 动态类型指的是对象指针类型的动态性,具体是指使用id任意类型将对象的类型确定推迟到运行时,由赋给它的对象类型,决定对象指针的类型。与动态类型相对,其它的指明类型的对象为静态类型对象。静态类型的好处是,错误可以在编译阶段提前查出,可读性好。
一个id类型的对象,Xcode的代码提示功能,可以提示常用的方法。因此下面的代码,编译阶段不会有任何的警告。// 1.id任意类型,编译器就不会把testObject在当成NSString对象了 id testObject = [[NSData alloc] init]; // 2.调用NSData的方法编译通过 [testObject base64EncodedDataWithOptions:NSDataBase64Encoding64CharacterLineLength]; // 3.调用NSString的方法编译也通过 [testObject stringByAppendingString:@"string"]; -
动态绑定 动态绑定是指方法确定的动态性,一方面利用OC的消息传递机制和转发机制,将要执行的方法的确定推迟到运行时;另一方面可以利用runtime为一个类动态的添加方法。也就是说,一个OC对象在运行时,具体是调用哪个方法,不是由编译器决定的,而是在运行时决定的。
这个特性决定了,在OC里面,所有的方法都是虚函数(C++中的概念)。
在ARC下,runtime有一套对autorelease返回值的优化策略。
比如一个工厂方法:
+ (instancetype)createSark {
return [self new];
}
// caller
Sark *sark = [Sark createSark];
秉着谁创建谁释放的原则,返回值需要是一个autorelease对象才能配合调用方正确管理内存,于是乎编译器改写成了形如下面的代码:
+ (instancetype)createSark {
id tmp = [self new]; //被retain
return objc_autoreleaseReturnValue(tmp); // 代替我们调用autorelease
}
// caller
id tmp = objc_retainAutoreleasedReturnValue([Sark createSark]) // 代替我们调用retain
Sark *sark = tmp;
objc_storeStrong(&sark, nil); // 相当于代替我们调用了release
一切看上去都很好,不过既然编译器知道了这么多信息,干嘛还要劳烦autorelease这个开销不小的机制呢?于是乎,runtime使用了一些黑魔法将这个问题解决了。
-
黑魔法之Thread Local Storage
Thread Local Storage(TLS)线程局部存储,目的很简单,将一块内存作为某个线程专有的存储,以key-value的形式进行读写,比如在非arm架构下,使用pthread提供的方法实现:void* pthread_getspecific(pthread_key_t); int pthread_setspecific(pthread_key_t , const void *);说它是黑魔法可能被懂pthread的笑话。
在返回值身上调用objc_autoreleaseReturnValue方法时,runtime将这个返回值object储存在TLS中,然后直接返回这个object(不调用autorelease);同时,在外部接收这个返回值的objc_retainAutoreleasedReturnValue里,发现TLS中正好存了这个对象,那么直接返回这个object(不调用retain)。
于是乎,调用方和被调方利用TLS做中转,很有默契的免去了对返回值的内存管理。
于是问题又来了,假如被调方和主调方只有一边是ARC环境编译的该咋办?(比如我们在ARC环境下用了非ARC编译的第三方库,或者反之) 只能动用更高级的黑魔法。
- 黑魔法之
__builtin_return_address
这个内建函数原型是char *__builtin_return_address(int level),作用是得到函数的返回地址,参数表示层数,如__builtin_return_address(0)表示当前函数体返回地址,传1是调用这个函数的外层函数的返回值地址,以此类推。
- (int)foo {
NSLog(@"%p", __builtin_return_address(0)); // 根据这个地址能找到下面ret的地址
return 1;
}
// caller
int ret = [sark foo];
看上去也没啥厉害的,不过要知道,函数的返回值地址,也就对应着调用者结束这次调用的地址(或者相差某个固定的偏移量,根据编译器决定) 也就是说,被调用的函数也有翻身做地主的机会了,可以反过来对主调方干点坏事。 回到上面的问题,如果一个函数返回前知道调用方是ARC还是非ARC,就有机会对于不同情况做不同的处理。
- 黑魔法之反查汇编指令
通过上面的__builtin_return_address加某些偏移量,被调方可以定位到主调方在返回值后面的汇编指令:
// caller
int ret = [sark foo];
// 内存中接下来的汇编指令(x86,我不懂汇编,瞎写的)
movq ??? ???
callq ???
而这些汇编指令在内存中的值是固定的,比如movq对应着0x48。
于是乎,就有了下面的这个函数,入参是调用方__builtin_return_address传入值。
static bool callerAcceptsFastAutorelease(const void * const ra0) {
const uint8_t *ra1 = (const uint8_t *)ra0;
const uint16_t *ra2;
const uint32_t *ra4 = (const uint32_t *)ra1;
const void **sym;
// 48 89 c7 movq %rax,%rdi
// e8 callq symbol
if (*ra4 != 0xe8c78948) {
return false;
}
ra1 += (long)*(const int32_t *)(ra1 + 4) + 8l;
ra2 = (const uint16_t *)ra1;
// ff 25 jmpq *symbol@DYLDMAGIC(%rip)
if (*ra2 != 0x25ff) {
return false;
}
ra1 += 6l + (long)*(const int32_t *)(ra1 + 2);
sym = (const void **)ra1;
if (*sym != objc_retainAutoreleasedReturnValue)
{
return false;
}
return true;
}
它检验了主调方在返回值之后是否紧接着调用了objc_retainAutoreleasedReturnValue,如果是,就知道了外部是ARC环境,反之就走没被优化的老逻辑。
每个线程都需要自动释放池,否则无法处理被调用了autorelease方法的对象。
在main.m中,主线程已经包含了一个自动释放池的块。
使用GCD, Operation这些多线程技术时,线程里面也会包含自动释放池的块。
自动释放池可以有多个,形成一个栈的结构。
可以自己创建自动释放池的块,在块开始的时候,会PUSH一个自动释放池对象,在块结束的时候,会从栈中pop。
自动释放池被pop的时候,会对它所包含的对象发送release消息。
使用容器的block版本的枚举器时,内部会自动添加一个AutoreleasePool,所以建议使用这个API来进行循环。
The Application Kit creates an autorelease pool on the main thread at the beginning of every cycle of the event loop, and drains it at the end, thereby releasing any autoreleased objects generated while processing an event
在开始每一个事件循环之前系统会在主线程创建一个自动释放池, 并且在事件循环结束的时候把前面创建的释放池释放, 回收内存。
关于原理,看下面两篇文章,应该能够搞定面试了:
黑幕背后的Autorelease
Objective-C Autorelease Pool 的实现原理
ARC下,我们使用@autoreleasepool{}来使用一个AutoReleasePool,随后编译器将其改写成下面的样子:
extern "C" __declspec(dllimport) void * objc_autoreleasePoolPush(void);
extern "C" __declspec(dllimport) void objc_autoreleasePoolPop(void *);
struct __AtAutoreleasePool {
__AtAutoreleasePool() {atautoreleasepoolobj = objc_autoreleasePoolPush();}
~__AtAutoreleasePool() {objc_autoreleasePoolPop(atautoreleasepoolobj);}
void * atautoreleasepoolobj;
};
/* @autoreleasepool */ { __AtAutoreleasePool __autoreleasepool;
}
//简化的版本:
/* @autoreleasepool */ {
void *atautoreleasepoolobj = objc_autoreleasePoolPush();
// 用户代码,所有接收到 autorelease 消息的对象会被添加到这个 autoreleasepool 中
objc_autoreleasePoolPop(atautoreleasepoolobj);
}
而这两个函数都是对AutoreleasePoolPage的简单封装,所以自动释放机制的核心就在于这个类。
AutoreleasePoolPage是一个C++实现的类:

- AutoreleasePool并没有单独的结构,而是由若干个AutoreleasePoolPage以双向链表的形式组合而成(分别对应结构中的parent指针和child指针)
- AutoreleasePool是按线程一一对应的,结构中的thread指针指向当前线程。
- AutoreleasePoolPage每个对象会开辟4096字节内存(也就是虚拟内存一页的大小),除了上面的实例变量所占空间,剩下的空间全部用来存储autorelease对象的地址。
- 上面的id *next指针作为游标指向栈顶最新add进来的autorelease对象的下一个位置。当 next == begin() 时,表示 AutoreleasePoolPage 为空;当 next == end() 时,表示 AutoreleasePoolPage 已满。
- 一个AutoreleasePoolPage的空间被占满时,会新建一个AutoreleasePoolPage对象,连接链表,后来的autorelease对象在新的page加入
- Thread-local storage(线程局部存储)指向 hot page ,即最新添加的 autoreleased 对象所在的那个 page 。
所以,若当前线程中只有一个AutoreleasePoolPage对象,并记录了很多autorelease对象地址时内存如下图:

图中的情况,这一页再加入一个autorelease对象就要满了(也就是next指针马上指向栈顶),这时就要执行上面说的操作,建立下一页page对象,与这一页链表连接完成后,新page的next指针被初始化在栈底(begin的位置),然后继续向栈顶添加新对象。
所以,向一个对象发送- autorelease消息,就是将这个对象加入到当前AutoreleasePoolPage的栈顶next指针指向的位置。
每当进行一次objc_autoreleasePoolPush调用时,runtime向当前的AutoreleasePoolPage中add进一个哨兵对象,值为0(也就是个nil),那么这一个page就变成了下面的样子:

objc_autoreleasePoolPush的返回值正是这个哨兵对象的地址,被objc_autoreleasePoolPop(哨兵对象)作为入参,于是:
根据传入的哨兵对象地址找到哨兵对象所处的page
在当前page中,将晚于哨兵对象插入的所有autorelease对象都发送一次- release消息,并向回移动next指针到正确位置
补充2:从最新加入的对象一直向前清理,可以向前跨越若干个page,直到哨兵所在的page
刚才的objc_autoreleasePoolPop执行后,最终变成了下面的样子:

知道了上面的原理,嵌套的AutoreleasePool就非常简单了,pop的时候总会释放到上次push的位置为止,多层的pool就是多个哨兵对象而已,就像剥洋葱一样,每次一层,互不影响。
- @property有两个对应的词,一个是 @synthesize,一个是 @dynamic。如果 @synthesize和 @dynamic都没写,那么默认的就是@syntheszie var = _var;
- @synthesize 的语义是如果你没有手动实现 setter 方法和 getter 方法,那么编译器会自动为你加上这两个方法。
- @dynamic 告诉编译器:属性的 setter 与 getter 方法由用户自己实现,不自动生成。(当然对于 readonly 的属性只需提供 getter 即可)。假如一个属性被声明为 @dynamic var,然后你没有提供 @setter方法和 @getter 方法,编译的时候没问题,但是当程序运行到 instance.var = someVar,由于缺 setter 方法会导致程序崩溃;或者当运行到 someVar = var 时,由于缺 getter 方法同样会导致崩溃。编译时没问题,运行时才执行相应的方法,这就是所谓的动态绑定。
- @dynamic经常用于ManagedObject,一个属性的读取方法,由CoreData框架在运行时利用消息转发机制,动态的添加实现。
现在的Xcode,一般情况下是不需要我们再去写@synthesize了,但是还是会有以下的情况,需要我们去写:
- 实现一个协议,协议中声明了有属性。
- 对于一个readwrite的属性,如果我们同时自己实现了getter和setter方法,会发现iVar是不存在的,这个时候还是需要去写。
- 对于一个readonly的属性,如果我们实现了getter方法,会发现iVar是不存在的。
每个 Objective-C 对象都有相同的结构,如下图所示:

- 所有父类的成员变量和自己的成员变量都会存放在该对象所对应的存储空间中.
- 每一个对象内部都有一个isa指针,指向他的类对象,类对象中存放着本对象的
1)对象方法列表(对象能够接收的消息列表,保存在它所对应的类对象中)
2)成员变量的列表
3)属性列表
它内部也有一个isa指针指向元对象(meta class),元对象内部存放的是类方法列表,类对象内部还有一个superclass的指针,指向他的父类对象。 - 根对象就是NSObject,它的superclass指针指向nil
- 类对象既然称为对象,那它也是一个实例。类对象中也有一个isa指针指向它的元类(meta class),即类对象是元类的实例。元类内部存放的是类方法列表,根元类的isa指针指向自己,superclass指针指向NSObject类。
struct objc_method {
SEL method_name OBJC2_UNAVAILABLE;
char *method_types OBJC2_UNAVAILABLE;
IMP method_imp OBJC2_UNAVAILABLE;
}
typedef struct objc_method *Method;
typedef struct method_list_t {
uint32_t entsize_NEVER_USE; // low 2 bits used for fixup markers
uint32_t count;
struct method_t first;
} method_list_t;
typedef struct objc_selector *SEL; //可以认为是一个C字符串
//定义了一个函数指针类型
typedef id _Nullable (*IMP)(id _Nonnull, SEL _Nonnull, ...);

@implementation Son : Father
- (id)init
{
self = [super init];
if (self) {
NSLog(@"%@", NSStringFromClass([self class]));
NSLog(@"%@", NSStringFromClass([super class]));
}
return self;
}
@end
网上的答案是,都输出Son。先来解释一下,两者都是调用的NSObject的实例方法class,区别是,[self class]是从类对象Son出发,寻找class方法的实现,而[super class]是从父类对象Father出发,寻找class方法的实现。如果在整个类层次中,没有类对class方法进行override,那么最终就会找到NSObject类中的实现:
- (Class)class {
return object_getClass(self);
}
答案确实是Son。
但是,假设Father类重写了class方法:
- (Class)class {
return [NSString class];
}
那么答案就会变成NSString.
_objc_msgForward是一个函数指针,IMP类型,用于消息转发的。当向一个对象发送一条消息,但它并没有实现的时候,会用这个函数来尝试做消息转发。
在消息传递的过程中,objc_msgSend的动作比较清晰:首先在Class中的缓存查找IMP(没缓存则初始化缓存),如果没找到,则向父类的Class查找。如果一直查找到根类仍旧没有发现,则用_objc_msgForward函数指针代替IMP。最后,执行这个IMP。
执行的过程,就是下道题目的消息转发过程。
直接调用该函数,是非常危险的事,如果用不好会直接导致程序崩溃,但是如果用得好,可以做很多非常酷的事。一旦调用该函数,将跳过查找IMP的过程,直接触发“消息转发”。有哪些场景需要直接调用该函数呢?最常见的场景是:你想获取某方法所对应的NSInvocation对象。
JSPatch就是直接调用该函数来实现其核心功能的。作者的博文《JSPatch实现原理详解》详细记录了实现原理,有兴趣的可以看看。
RAC源码中也用到了该方法。
如果向一个对象发送一个不支持的消息,那么默认的实现是会调用NSObject类中的doesNotRecognizeSelector:方法,此方法会抛出异常,导致应用崩溃。
但是runtime在此之前,会给3次机会。
第1次,+(BOOL)resolveInstanceMethod:(SEL)name 或+ (BOOL)resolveClassMethod:(SEL)name
@interface Person : NSObject
@property (nonatomic, copy) NSString* name;
@property (nonatomic, assign) NSUInteger age;
@end
@implementation Person
//如果需要传参直接在参数列表后面添加就好了
void dynamicAdditionMethodIMP(id self, SEL _cmd) {
NSLog(@"dynamicAdditionMethodIMP");
}
+ (BOOL)resolveInstanceMethod:(SEL)name {
NSLog(@"resolveInstanceMethod: %@", NSStringFromSelector(name));
if (name == @selector(appendString:)) {
class_addMethod([self class], name, (IMP)dynamicAdditionMethodIMP, "v@:");
return YES;
}
return [super resolveInstanceMethod:name];
}
+ (BOOL)resolveClassMethod:(SEL)name {
NSLog(@"resolveClassMethod %@", NSStringFromSelector(name));
return [super resolveClassMethod:name];
}
@end
第2次 - (id)forwardingTargetForSelector:(SEL)aSelector; 可以override这个函数,返回其它的能处理这个消息的对象。
@implementation TestClass
- (void)logString:(NSString *)str {
NSLog(@"log string: %@", str);
}
@end
self.tc = [TestClass new];
//self并没有logString:这个方法,如果不处理转发,则会崩溃。
[self performSelector: @selector(logString:) withObject: @"Hello"];
- (id)forwardingTargetForSelector:(SEL)aSelector {
if (aSelector == @selector(logString:)) {
return self.tc;
}
return [super forwardingTargetForSelector: aSelector];
}
第3次 完整转发流程
必须override这个方法,消息转发过程利用这个函数返回的信息,来创建NSInvocation对象。
- (NSMethodSignature*)methodSignatureForSelector:(SEL)aSelector {
if (aSelector == @selector(logString:)) {
return [self.tc methodSignatureForSelector: aSelector];
}
return [super methodSignatureForSelector: aSelector];
}
- (void)forwardInvocation:(NSInvocation *)anInvocation {
SEL aSelector = [anInvocation selector];
if ([self.tc respondsToSelector: aSelector]) {
[anInvocation invokeWithTarget: self.tc];
}
else {
[super forwardInvocation: anInvocation];
}
}
完整的转发流程,代价比较高。
用图来总结:

该特性的实质是,为类添加一个新的方法,然后将目标方法和新的方法的IMP进行互换,结果就是修改selector和IMP的对应关系。
在 Objective-C 中向 nil 发送消息是完全有效的——只是在运行时不会有任何作用。
当返回值是对象类型时,返回nil;
当返回值是标量,如整型时,返回0;
当返回值是结构体时,会返回一个结构体对象,不过里面的成员的值都为0.
如果返回值不是以上几种情况,那么返回的结果就是未定义的。
- 不能向编译后得到的类中增加实例变量;
- 能向运行时创建的类中添加实例变量;
解释下:
因为编译后的类已经注册在 runtime 中,类结构体中的objc_ivar_list实例变量的链表 和instance_size实例变量的内存大小已经确定,同时runtime 会调用class_setIvarLayout或class_setWeakIvarLayout来处理 strong weak 引用。所以不能向存在的类中添加实例变量;
运行时创建的类是可以添加实例变量,调用 class_addIvar 函数。但是得在调用 objc_allocateClassPair 之后,objc_registerClassPair 之前,原因同上。
可以添加。代码如下:
#include <objc/runtime.h>
#import <Foundation/Foundation.h>
@interface SomeClass : NSObject {
NSString *_privateName;
}
@end
@implementation SomeClass
- (id)init {
self = [super init];
if (self) _privateName = @"Steve";
return self;
}
@end
NSString *nameGetter(id self, SEL _cmd) {
Ivar ivar = class_getInstanceVariable([SomeClass class], "_privateName");
return object_getIvar(self, ivar);
}
void nameSetter(id self, SEL _cmd, NSString *newName) {
Ivar ivar = class_getInstanceVariable([SomeClass class], "_privateName");
id oldName = object_getIvar(self, ivar);
if (oldName != newName) object_setIvar(self, ivar, [newName copy]);
}
int main(void) {
@autoreleasepool {
objc_property_attribute_t type = { "T", "@\"NSString\"" };
objc_property_attribute_t ownership = { "C", "" }; // C = copy
objc_property_attribute_t backingivar = { "V", "_privateName" };
objc_property_attribute_t attrs[] = { type, ownership, backingivar };
class_addProperty([SomeClass class], "name", attrs, 3);
class_addMethod([SomeClass class], @selector(name), (IMP)nameGetter, "@@:");
class_addMethod([SomeClass class], @selector(setName:), (IMP)nameSetter, "v@:@");
id o = [SomeClass new];
NSLog(@"%@", [o name]);
[o setName:@"Jobs"];
NSLog(@"%@", [o name]);
}
}
runtime对注册的类会进行布局,对于weak修饰的对象会放入一个hash表中。用weak指向的对象内存地址作为key,当此对象的引用计数为0的时候会dealloc,假如weak指向的对象内存地址是a,那么就会以a为键在这个weak表中搜索,找到所有以a为键的weak对象,从而设置为nil。
其中会用到id objc_storeWeak(id _Nullable *location, id obj);这个函数,在初始化的时候,第二个参数非空;在指向的对象析构的时候,第2个参数为nil。
atomic只能保证属性系统生成的set/get方法读写线程安全,对属性发送其他消息如release等等,还是需要lock等其它的同步机制来确保线程安全。
那OC是如何实现atomic的属性的getter/setter呢?
在objc-accessors.mm中,查看代码可知,property 的 atomic 是采用 spinlock_t 也就是俗称的自旋锁实现的。
// getter
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
// ...
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
id value = objc_retain(*slot);
slotlock.unlock();
// ...
}
// setter
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
// ...
if (!atomic) {
oldValue = *slot;
*slot = newValue;
} else {
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
// ...
}
@property (nonatomic, copy) NSString *name;
NSString *str = @"Alice";
self.name = str;
NSString *str2 = self.name;
NSLog(@"%p", str); //0x1000782f8
NSLog(@"%p", _name); //0x1000782f8
NSLog(@"%p", str2); //0x1000782f8
name属性分别用copy和retain修饰有什么不同? 运行上述程序发现三个字符串指向同一地址,因为string常量池的存在, 对于NSString来说copy和retain的操作都只是对其引用计数+1.
将分类中的方法加入类中这一操作,是在运行期系统加载分类时完成的。运行期系统会把分类中所实现的每个方法都加入类的方法列表中。如果类中本来就有此方法,而分类又实现了一次,那么分类中的方法会覆盖原来那一份实现代码。实际上可能会发生很多次覆盖,比如某个分类中的方法覆盖了“主实现”中的相关方法,而另外一个分类中的方法又覆盖了这个分类中的方法。多次覆盖的结果以最后一个分类为准。
所以,最好的做法是为方法加前缀,避免发生覆盖。
关于实现原理,可以看下面的两篇文章:
深入理解Objective-C:Category
Objective-C Category 的实现原理
简单的来说,就是在加载的时候,分类中的方法会被添加到类的方法列表中。
实际的结果是:
- 分类中的方法没有“完全替换掉”原来类中已经有的方法,也就是说如果分类和原来的类都有methodA,那么分类附加完成之后,类的方法列表里会有两个methodA。
- 分类的方法被放到了新方法列表的前面,而原来类的方法被放到了新方法列表的后面,这也就是我们平常所说的category的方法会“覆盖”掉原来类的同名方法,这是因为运行时在查找方法的时候是顺着方法列表的顺序查找的,它只要一找到对应名字的方法,就会停止。
- 多个分类写了同样的分类方法时,后编译的覆盖前面的。
因此,原来的方法还是可以被调用到的,只要利用运行时获得方法列表,查找到最后一个就是了。
load:
当一个类或是分类被加载进runtime的时候,会被调用load方法。
父类的load方法先被调用,子类的load方法之后被调用。
分类的load方法在类的load方法之后被调用。
load方法的调用,在main()函数被调用之前。
一个类有多个分类时,根据编译顺序,调用相应分类的load方法,先编译的先被调用。
initialize: 当一个类,或是它的子类在接收到第一个消息之前,这个类都会收到initialize消息。
父类先收到消息,然后是子类。
每个类只会收到一次,分类不会收到。
顺序:先是load,然后是initialize。
- 若想检测对象的等同性,需要同时提供isEqual:和hash两个方法。
- 相同的对象必须具有相同的哈希码,但是两个哈希码相同的对象却未必相同,这种情况发生时叫碰撞。
- hash值用于确定对象在哈希表中的位置。
- 不要盲目地逐个检测每条属性,而是应该依照具体需求来制定检测方案。
- 编写hash方法时,应该使用性能好而且哈希码碰撞几率低的算法。一个例子是:
- (NSUInteger)hash {
NSUInteger firstNameHash = [_firstName hash];
NSUInteger lastNameHash = [_lastName hash];
NSUInteger ageHash = _age;
return firstNameHash ^ lastNameHash ^ ageHash;
}
Block本身是对象,下图描述了Block对象的内存布局:

在内存布局中,最重要的就是invoke变量,这是一个函数指针,指向Block的实现代码,函数原型至少要接受一个void*型的参数,此参数代表块。
descriptor变量是指向结构体的指针,每个块里都包含此结构体,其中声明了块对象的总体大小,还声明了copy与dispose这两个辅助函数所对应的函数指针。辅助函数在拷贝及丢弃块对象时运行,其中会执行一些操作,比方说,前者要保留捕获的对象,而后者则将之释放。
块还会把它所捕获的所有变量都拷贝一份。这些拷贝放在descriptor变量后面,捕获了多少个变量,就要占据多少内存空间。请注意,拷贝的并不是对象本身,而是指向这些对象的指针变量。invoke函数为何需要把块对象作为参数传进来呢?原因就在于,执行块时,要从内存中把这些捕获到的变量读出来。
- 全局Block
int global = 0;
void (^globalBlock)(void) = ^{
global = 100;
NSLog(@"This is a block");
};
NSLog(@"global block is kind of class: %@", [globalBlock class]);
输出:global block is kind of class: NSGlobalBlock
上面定义的globalBlock,因为没有捕捉任何状态(比如外围的变量等),运行时也无须有状态来参与。块所使用的整个内存区域,在编译期已经完全确定了,因此,全局块可以声明在全局内存里,而不需要在每次用到的时候于栈中创建。这种块实际上相当于单例。
- 堆上的Block
void (^block)(void) = ^{
NSLog(@"self = %@", self);
};
block();
NSLog(@"block is kind of class: %@", [block class]);
输出:block is kind of class: NSMallocBlock
上面定义的block,因为在内部捕捉了self,就从全局Block变成了堆上的Block。
- 栈上的Block
Block在定义的时候,其所占的内存区域是分配在栈中的。
CGFloat f = 1.1;
NSLog(@"%@", ^{NSLog(@"%lf",f);});
NSLog(@"%@",[^{NSLog(@"%lf",f);} copy]);
void(^deliveryBlock)(void) = ^{NSLog(@"%lf",f);};
NSLog(@"%@", deliveryBlock);
经打印得知,只有第一次打印输出类型为__NSStackBlock__, 其它的两次都变成了__NSMallocBlock__。所以栈上的Block,在ARC环境下,一经赋值,copy,参数传递,就都变成了堆上的Block。
系统的某些block api中,UIView的block版本写动画时不需要考虑,但也有一些api 需要考虑:
所谓“引用循环”是指双向的强引用,所以那些“单向的强引用”(block 强引用 self )没有问题,比如这些:
[UIView animateWithDuration:duration animations:^{ [self.superview layoutIfNeeded]; }];
[[NSOperationQueue mainQueue] addOperationWithBlock:^{ self.someProperty = xyz; }];
[[NSNotificationCenter defaultCenter] addObserverForName:@"someNotification"
object:nil
queue:[NSOperationQueue mainQueue]
usingBlock:^(NSNotification * notification) {
self.someProperty = xyz; }];
这些情况不需要考虑“引用循环”。
但如果你使用一些参数中可能含有 ivar 的系统 api ,如 GCD 、NSNotificationCenter就要小心一点:比如GCD 内部如果引用了 self,而且 GCD 的其他参数是 ivar,则要考虑到循环引用:
__weak __typeof__(self) weakSelf = self;
dispatch_group_async(_operationsGroup, _operationsQueue, ^
{
__typeof__(self) strongSelf = weakSelf;
[strongSelf doSomething];
[strongSelf doSomethingElse];
} );
类似的:
__weak __typeof__(self) weakSelf = self;
_observer = [[NSNotificationCenter defaultCenter] addObserverForName:@"testKey"
object:nil
queue:nil
usingBlock:^(NSNotification *note) {
__typeof__(self) strongSelf = weakSelf;
[strongSelf dismissModalViewControllerAnimated:YES];
}];
self --> _observer --> block --> self 显然这也是一个循环引用。
想要学习的话,可以看下面两篇文章:
深入解构iOS的block闭包实现原理
深入研究Block捕获外部变量和__block实现原理
简单的来说,没有加__block时,外部变量被只是值被拷贝到了block中,在block的函数内,访问的是一个副本。
当加了__block时,外部变量会被包装到一个结构体中,在block内部和外部,访问的都是同一结构体中的变量,因此可以在block内部修改外部变量的值。
这个只有一家问到了,觉得了解就行了。
//假设从主线程开始执行
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"222");
});
NSLog(@"1");
上面代码执行后的打印顺序是什么? 经测试结果是:输出顺序不固定,如果dispatch_async执行完,如全局并发队列分配到时间片则先会打印222再打印1, 如没分配到则先打印1再打印222. 如将global_queue换成自定义的串行队列也是同样的结果.
下面的代码,会造成死锁(真机)/ 崩溃(模拟器):
#import "ManageA.h"
@implementation ManageA
+ (ManageA *)sharedInstance
{
static ManageA *manager = nil;
static dispatch_once_t token;
dispatch_once(&token, ^{
manager = [[ManageA alloc] init];
});
return manager;
}
- (instancetype)init
{
self = [super init];
if (self) {
[ManageB sharedInstance];
}
return self;
}
@end
@implementation ManageB
+ (ManageB *)sharedInstance
{
static ManageB *manager = nil;
static dispatch_once_t token;
dispatch_once(&token, ^{
manager = [[ManageB alloc] init];
});
return manager;
}
- (instancetype)init
{
self = [super init];
if (self) {
[ManageA sharedInstance];
}
return self;
}
@end
上面的代码,会导致ManagerA的dispatch_once的block里,再次调用ManagerA的dispatch_once,出现重入现象,导致死锁。这个死锁的原理,非常类似于dispatch_sync(dispatch_get_main_queue)。
所以在使用时,要注意:
- block代码里尽量只做初始化的事情,不要调用很多其它的方法。
- block中的代码尽量不要抛出异常,不要Crash。Bugly和dispatch_once Crash
Key-Value Coding:
通过key来访问一个对象的属性或是实例变量的值,而不是通过具体的访问方法。
直接或者间接继承自NSObject的类,都拥有这个能力,是因为NSObject类中提供了缺省的实现。
实现的原理就是,将key映射到真正的访问方法。
例如Setter方法的寻找:
- 找名字为
set<Key>:或_set<Key>的方法,如果找到,调用之。 - 如果第1步没有找到,并且类方法accessInstanceVariablesDirectly返回YES(默认),那么会按
_<Key>, _is<Key>, <Key>, is<Key>的顺序去寻找实例变量。如果找到了,就将值直接设置到实例变量上。 - 如果最后没有找到,会去调用
setValue:forUndefinedKey:。默认的实现是抛出异常,但是子类可以提供不同的行为。
原理:
假设self.man为Person类的对象,有如下的注册观察者的代码:
[self.man addObserver: self forKeyPath: @"name" options: kNilOptions context: NULL];
如果我们在这一行打上断点,当断点停下来的时候,执行这行代码,然后在控制台里运行po self.man->isa,那么会打印NSKVONotifying_Person,可以发现对象的isa指针被指向了一个运行期创建的类。但是运行po [self.man class],却还是显示的Person。
使用运行时的class_copyMethodList方法,获取并打印临时类的方法列表,会打印出以下:
setName:
class
dealloc
_isKVOA
背后的实现原理:
当类Person的对象被观察时,KVO在运行时动态创建了一个Person类的子类:NSKVONotifying_Person,并为这个新的子类重写了被观察属性keyPath的setter方法。子类的setter方法会去负责通知观察者对象属性的改变。被观察的实例对象的isa指针被修改为指向新创建的子类。
子类中的setter方法的工作原理:
-(void)setName:(NSString *)newName{
[self willChangeValueForKey:@"name"]; //KVO 在调用存取方法之前总调用
[super setValue:newName forKey:@"name"]; //调用父类的存取方法
[self didChangeValueForKey:@"name"]; //KVO 在调用存取方法之后总调用
}
子类中的class方法返回Person。
集合类型的监听: 假设有一个属性是可变数组类型,通过常规的方法,只能监听到数组被赋值的时候。如果想监听到里面的值被添加,删除,那么就得依赖于手动的触发KVO了。
为了减少不必要的通知,或是为了将几个变化归为一组一起发出通知,可以覆写下面的类方法来告诉KVO,哪些key使用自动的触发。
+ (BOOL)automaticallyNotifiesObserversForKey:(NSString *)theKey {
BOOL automatic = NO;
if ([theKey isEqualToString:@"balance"]) {
automatic = NO;
}
else {
automatic = [super automaticallyNotifiesObserversForKey:theKey];
}
return automatic;
}
非集合类型的属性,比较简单,只用指定变化的key。
///Testing the value for change before providing notification
- (void)setBalance:(double)theBalance {
if (theBalance != _balance) {
[self willChangeValueForKey:@"balance"];
_balance = theBalance;
[self didChangeValueForKey:@"balance"];
}
}
对于一个to-many类型的属性,不但要指定变化的key,还要指定变化的类型和所涉及到的对象的索引集。
//Implementation of manual observer notification in a to-many relationship
- (void)removeTransactionsAtIndexes:(NSIndexSet *)indexes {
[self willChange:NSKeyValueChangeRemoval
valuesAtIndexes:indexes forKey:@"transactions"];
// Remove the transaction objects at the specified indexes.
[self didChange:NSKeyValueChangeRemoval
valuesAtIndexes:indexes forKey:@"transactions"];
}
-
通知:
使用Notification,可以在发送通知者和观察者之间解耦,观察者只需要知道通知的名字,以及通知中携带的参数即可。传值是通过userInfo来传一个字典。 -
代理:
此种情况下,一般是A持有B,然后A遵从B制定的协议,实现代理方法。在代理方法中,可以自由的传值。 -
block:
使用block,可以实现两种场景:回调;调用传入的block,来实现自身的逻辑。 -
selector:
例如UIGestureRecognizer, UIControl都有addTarget:action:之类的方法,支持添加多于一个的target, action,在需要时通过[target persormSelector]来回调。

从高地址到低地址分别为:栈、堆、BBS段、数据段、代码段
提示:栈和堆是运行时分配,BBS段、数据段、代码段是编译器分配
BBS段:通常是指用来存放程序中未初始化的全局变量和静态变量
数据段:通常是指用来存放程序中已经初始化的全局变量和静态变量、字符串常量等
代码段:通常是指用来存放程序执行代码的一块内存区域
堆:是用于存放进程运行中被动态分配的内存段(调用malloc函数,新分配的内存动态添加到堆上;调用free函数,释放内存从堆中删除)
栈:又称堆栈,是用户存放程序临时创建的局部变量
在iOS中,堆区的内存是应用程序共享的,堆中的内存分配是系统负责的;
系统使用一个链表来维护所有已经分配的内存空间;
当一个app启动后,代码区,常量区,全局区大小已固定。而堆区和栈区是时时刻刻变化的。
float, double, iteger, boolean, URL, NSData, NSString, NSNumber, NSDate, NSArray, NSDictionary.
- 为什么会有CALayer? 为了代码复用,在它之上,分别是NSView和UIView。
- UIView持有一个CALayer的实例,并实现了CALayerDelegate协议,CALayer的内容需要重新加载时,通过-drawLayer:inContext:或-displayLayer:方法,要求UIView提供内容。CALayer之后去管理这个内容。当然CALayer也有自己的一些可视属性。
- Core Animation是负责图形渲染和动画的框架。自身并不是一个绘制系统,它负责合成和操作一个应用的显示内容,并且利用GPU来实现硬件加速。
- 很多属性,如frame, position,在UIView层面上修改,也会作用于CALayer上。从这一点儿来看,UIView象是一个CALayer的包装。
- UIView还用来处理事件,参与职责链,一个APP并不能只用CALayer来去构建。
- 普通的视图的layer都是CALayer的实例,但可以通过覆写+(Class)layerClass这个方法,改变layer的类型。
- 树形结构:和UIView的树形结构类似,layer也有相应的树形结构。也可以在不添加视图的情况下,往layer上再添加子layer。
- 动画:没有与UIView相关联的layer,修改属性值时,会带有隐式动画。UIView自带的那个layer,隐式动画被关闭了,需要通过UIView的动画block,或是Core Animation来做动画。
- 坐标系统:CALayer相比UIView多了一个anchorPoint属性,使用CGPoint结构表示,值域是[0 1]。这个点是各种图形变换的中心点,同时会决定layer的position的位置,缺省值是[0.5,0.5]。
不是指三个树状层级,而是指三个layer对象的集合。
- model layer tree
这个集合里面的对象,存储了动画的目标值。平常我们都是和这里的对象打交道。 - presentation tree
这个集合里面的对象,存储的是动画的执行过程中的即时值。 - render tree
这个集合里面的对象,执行实际的动画,是核心动画的私有的。
从架构上来说,Core Graphics位于Core Animation的下方,如图所示:

Core Graphics也叫Quartz 2D, 是一个先进的,二维绘图引擎,可以工作于iOS, tvOS, macOS。
三个核心概念:
上下文: 主要用于描述图形写入哪里
路径:是在图层上绘制的内容
状态:用于保存配置变换的值,填充和alpha值等。
个人的理解:UIView会去利用Core Graphics去绘制,绘制好的内容交给Core Animation去做渲染。
有一个简单的办法,可以拿到一个webview的JSContext:
JSContext *context = [self.webView valueForKeyPath:@"documentView.webView.mainFrame.javaScriptContext"];
即使我们在viewDidLoad和webViewDidFinishLoad方法中,利用上述方法获取JSContext,然后向其中注入Native Object,在某些情况下仍然会出问题:当在html进行页面跳转的时候,JS调用OC对象出现undefined.
webViewDidFinishLoad这个方法是在web的window.onload以后才调用(也就是html所有的资源已经加载和渲染结束后),这就明了了,在JS调用OC的对象时,还没有注入。
从这篇文章里,可以学习到正确的方法:
- 为NSObject添加一个分类,并实现下面的方法
@implementation NSObject (JSTest)
- (void)webView:(id)unuse didCreateJavaScriptContext:(JSContext *)ctx forFrame:(id)frame {
[[NSNotificationCenter defaultCenter] postNotificationName:@"DidCreateContextNotification" object:ctx];
}
@end
调用这个方法的时候WebKit就已经创建了JSContext对象,在这个方法中我们发出一个通知,这个通知会把获取到的JSContext环境对象传递出去。
- 在WebViewController的viewDidLoad方法中观察通知
- (void)viewDidLoad {
[super viewDidLoad];
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(didCreateJSContext:) name:@"DidCreateContextNotification" object:nil];
NSURL *url = [[NSBundle mainBundle] URLForResource:@"test" withExtension:@"html"];
[self.webView loadRequest:[NSURLRequest requestWithURL:url]];
}
- 在通知回调函数中判断JSContext对象是不是当前WebView的
- (void)didCreateJSContext:(NSNotification *)notification {
NSString *indentifier = [NSString stringWithFormat:@"indentifier%lud", (unsigned long)self.webView.hash];
NSString *indentifierJS = [NSString stringWithFormat:@"var %@ = '%@'", indentifier, indentifier];
[self.webView stringByEvaluatingJavaScriptFromString:indentifierJS];
JSContext *context = notification.object;
//判断这个context是否属于当前这个webView
if (![context[indentifier].toString isEqualToString:indentifier]) return;
_context = context; //如果属于这个webView
MyJSObject *jsObject = [MyJSObject new];
_context[@"ttf"] = jsObject; //将对象注入这个context中
}
UIWebView: 通过注入到JSContext的JSExport对象的名字,调用上面的约定方法。
WKWebView: JS端调用window.webkit.messageHandlers.myName.postMessage(message);
而在Native端,会去执行
```
- (void)userContentController:(WKUserContentController *)userContentController didReceiveScriptMessage:(nonnull WKScriptMessage *)message
```
- 在Core Data打开一个store的时候,如果老版本的格式,与新的模型不兼容,那么需要执行数据迁移,如果不执行,那么会发生崩溃。
- Core Data会在store的metadata中存储一些Hash值,利用这些值,Core Data可以迅速的判断当前store的格式,是否与用来打开store的模型相匹配。
- Core Data也允许针对Entity或是Attribute设置一个hash modifier,来强制Hash值发生改变。一个例子:只是改变了一个属性的内部格式。
- .xcdatamodeld文件实际上是一个文件包,里面包含了不同版本的model,每个由.xcdatamodel和Info.plist文件组成。在Xcode里,我们可以指定当前要使用哪个版本。
- 在许多情况下,Core Data都可以执行自动的数据迁移,即lightweight migration。 Core Data基于源和目的managed object model的不同,会去推断出一个mapping model。
- 如果对一个Entity或是attribute进行了重新的命名,应该在新版本的model中,设置对应的renaming identifier。这样Core Data就可以知道新版本中的名字,对应的是旧版本中的哪个Entity或是attribute。
- 要想使用轻量级迁移,除了Core Data能够推断出mapping model之外,我们还应该请求Core Data去执行迁移。关键点就在于在调用addPersistentStoreWithType:configuration:URL:options:error: 方法的时候,传入两个选项:NSMigratePersistentStoresAutomaticallyOption和 NSInferMappingModelAutomaticallyOption, 值均设为YES。 代码如下:
NSError *error = nil;
NSURL *storeURL = <#The URL of a persistent store#>;
NSPersistentStoreCoordinator *psc = <#The coordinator#>;
NSDictionary *options = [NSDictionary dictionaryWithObjectsAndKeys:
[NSNumber numberWithBool:YES], NSMigratePersistentStoresAutomaticallyOption,
[NSNumber numberWithBool:YES], NSInferMappingModelAutomaticallyOption, nil];
BOOL success = [psc addPersistentStoreWithType:<#Store type#>
configuration:<#Configuration or nil#> URL:storeURL
options:options error:&error];
if (!success) {
// Handle the error.
}
- 要想使用轻量级迁移,Core Data必须在运行期能够找到源和目的managed object models。默认是在NSBundle的allBundles和allFrameworks方法返回的位置。如果模型被存储在别的位置,那么我们就得自己去写代码产生mapping model,然后使用migration manager去发起迁移。示例代码如下:
- (BOOL)migrateStore:(NSURL *)storeURL toVersionTwoStore:(NSURL *)dstStoreURL error:(NSError **)outError {
// Try to get an inferred mapping model.
NSMappingModel *mappingModel =
[NSMappingModel inferredMappingModelForSourceModel:[self sourceModel]
destinationModel:[self destinationModel] error:outError];
// If Core Data cannot create an inferred mapping model, return NO.
if (!mappingModel) {
return NO;
}
// Create a migration manager to perform the migration.
NSMigrationManager *manager = [[NSMigrationManager alloc]
initWithSourceModel:[self sourceModel] destinationModel:[self destinationModel]];
BOOL success = [manager migrateStoreFromURL:storeURL type:NSSQLiteStoreType
options:nil withMappingModel:mappingModel toDestinationURL:dstStoreURL
destinationType:NSSQLiteStoreType destinationOptions:nil error:outError];
return success;
}
- 如果Core Data不能推断出Mapping model,那么就麻烦了,需要自己去定义。不过这个一般用不到,用到时再去看文档就可以。
关于两者的协同工作,iOS核心动画高级技巧这本书里有讲,在第12章的第1节。
动画和屏幕上组合的图层实际上被一个单独的进程管理,而不是你的应用程序。这个进程就是所谓的渲染服务。在iOS5和之前的版本是SpringBoard进程(同时管理着iOS的主屏)。在iOS6之后的版本中叫做BackBoard。
当运行一段动画时候,这个过程会被四个分离的阶段被打破:
布局 - 这是准备你的视图/图层的层级关系,以及设置图层属性(位置,背景色,边框等等)的阶段。
显示 - 这是图层的寄宿图片被绘制的阶段。绘制有可能涉及你的-drawRect:和-drawLayer:inContext:方法的调用路径。
准备 - 这是Core Animation准备发送动画数据到渲染服务的阶段。这同时也是Core Animation将要执行一些别的事务例如解码动画过程中将要显示的图片的时间点。
提交 - 这是最后的阶段,Core Animation打包所有图层和动画属性,然后通过IPC发送到渲染服务进行显示。
但是这些阶段仅仅发生在你的应用程序之内,在动画在屏幕上显示之前仍然有更多的工作。一旦打包的图层和动画到达渲染服务进程,他们会被反序列化来形成另一个叫做渲染树的图层树(在第一章“图层树”中提到过)。使用这个树状结构,渲染服务对动画的每一帧做出如下工作:
对所有的图层属性计算中间值,设置OpenGL几何形状(纹理化的三角形)来执行渲染
在屏幕上渲染可见的三角形
所以一共有六个阶段;最后两个阶段在动画过程中不停地重复。前五个阶段都在软件层面处理(通过CPU),只有最后一个被GPU执行。而且,你真正只能控制前两个阶段:布局和显示。Core Animation框架在内部处理剩下的事务,你也控制不了它。

在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。随后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。
从上面的图中可以看到,CPU 和 GPU 不论哪个阻碍了显示流程,都会造成掉帧现象。所以开发时,也需要分别对 CPU 和 GPU 压力进行评估和优化。
主要有:Atomic Operations, Lock和Condition。 GCD中的group, barrier, semaphore也是用来在GCD中做同步的。
系统提供了一些原子性的数学运算和逻辑运算函数,声明在/usr/include/libkern/OSAtomic.h中。 原子操作的性能比锁要高。
这些函数分为以下类别:
Add: Adds two integer values together and stores the result in one of the specified variables.
Increment: Increments the specified integer value by 1.
Decrement: Decrements the specified integer value by 1.
Logical OR: Performs a logical OR between the specified 32-bit value and a 32-bit mask.
Logical AND: Performs a logical AND between the specified 32-bit value and a 32-bit mask.
Logical XOR: Performs a logical XOR between the specified 32-bit value and a 32-bit mask.
Compare and swap:
Test and set:
Test and clear:
- Using a POSIX Mutex Lock
pthread_mutex_t mutex;
void MyInitFunction()
{
pthread_mutex_init(&mutex, NULL);
}
void MyLockingFunction()
{
pthread_mutex_lock(&mutex);
// Do work.
pthread_mutex_unlock(&mutex);
}
- Using the NSLock Class
基本的互斥锁,除了标准的加锁和解锁外,还提供了非阻塞的tryLock,设置超时的lockBeforeDate:
BOOL moreToDo = YES;
NSLock *theLock = [[NSLock alloc] init];
...
while (moreToDo) {
/* Do another increment of calculation */
/* until there’s no more to do. */
if ([theLock tryLock]) {
/* Update display used by all threads. */
[theLock unlock];
}
}
- Using @synchronized
一个使用互斥锁的便利方式,使用括号中的对象作为锁的token。性能是最差的。 @synchronized 指令实现锁的优点就是我们不需要在代码中显式的创建锁对象,便可以实现锁的机制,但作为一种预防措施,@synchronized 块会隐式的添加一个异常处理例程来保护代码,该处理例程会在异常抛出的时候自动的释放互斥锁。所以如果不想让隐式的异常处理例程带来额外的开销,你可以考虑使用锁对象。
- (void)myMethod:(id)anObj
{
@synchronized(anObj)
{
// Everything between the braces is protected by the @synchronized directive.
}
}
- NSRecursiveLock
递归锁,可以被同一线程加锁多次,而不会导致死锁问题。递归锁会追踪被加锁多少次,每次成功的加锁都得匹配一次解锁。只有加锁和解锁的次数相同,锁才会被释放,其它的线程才可以加锁成功。 该锁经常使用在递归函数中。
NSRecursiveLock *theLock = [[NSRecursiveLock alloc] init];
void MyRecursiveFunction(int value)
{
[theLock lock];
if (value != 0)
{
--value;
MyRecursiveFunction(value);
}
[theLock unlock];
}
MyRecursiveFunction(5);
- NSConditionLock
该类型的锁可以使用一个特定的值去加锁和解锁,一个典型的例子就是一个线程生产数据,另一个消费数据。
lockWhenCondition: 1 是指当前condition为1时,才能加锁成功。
unlockWithCondition: 1 是指解锁后,将condition置为1.
//生产者
id condLock = [[NSConditionLock alloc] initWithCondition:NO_DATA];
while(true)
{
[condLock lock];
/* Add data to the queue. */
[condLock unlockWithCondition:HAS_DATA];
}
//消费者
while (true)
{
[condLock lockWhenCondition:HAS_DATA];
/* Remove data from the queue. */
[condLock unlockWithCondition:(isEmpty ? NO_DATA : HAS_DATA)];
// Process the data locally.
}
一种特殊类型的锁,主要是用来同步操作执行的顺序。
A condition object acts as both a lock and a checkpoint in a given thread. The lock protects your code while it tests the condition and performs the task triggered by the condition. The checkpoint behavior requires that the condition be true before the thread proceeds with its task. While the condition is not true, the thread blocks. It remains blocked until another thread signals the condition object.
The semantics for using an NSCondition object are as follows:
- Lock the condition object.
- Test a boolean predicate. (This predicate is a boolean flag or other variable in your code that indicates whether it is safe to perform the task protected by the condition.)
- If the boolean predicate is false, call the condition object’s wait or waitUntilDate: method to block the thread. Upon returning from these methods, go to step 2 to retest your boolean predicate. (Continue waiting and retesting the predicate until it is true.)
- If the boolean predicate is true, perform the task.
- Optionally update any predicates (or signal any conditions) affected by your task.
- When your task is done, unlock the condition object.
Using a Cocoa condition:
[cocoaCondition lock];
while (timeToDoWork <= 0)
[cocoaCondition wait];
timeToDoWork--;
// Do real work here.
[cocoaCondition unlock];
Signaling a Cocoa condition:
[cocoaCondition lock];
timeToDoWork++;
[cocoaCondition signal];
[cocoaCondition unlock];
一次signal调用只能唤醒一个线程,而broadcoast则能唤醒所有的线程。
一个Lock只能由一个线程加锁成功,其它的线程必须等待,直到其它线程释放锁。 Condition相当于Lock + Condition,可以由多个线程加锁成功,加锁成功以后还需要检查condition是否满足,不满足的话需要一直wait。
盗用YY博客中的图:

可以从NSMutableArray派生,根据苹果的文档,要继承这样的类,需要实现NSMutableArray的Primitive Methods:
- (void)addObject:(id)anObject;
- (void)insertObject:(id)anObject atIndex:(NSUInteger)index;
- (void)removeLastObject;
- (void)removeObjectAtIndex:(NSUInteger)index;
- (void)replaceObjectAtIndex:(NSUInteger)index withObject:(id)anObject;
以及NSArray的Primitive Methods:
- (NSUInteger)count;
- (id)objectAtIndex:(NSUInteger)index;
而要达到线程安全,不外乎就是在这些方法内部都加上锁,简化多线程情景下的容器使用,不必手动逐一添加锁。
在加锁时,选择递归锁会比较安全,以防以上函数有被另一个调用的危险。
但这样的做法并不推荐,原因就是因为性能问题。当你使用容器来频繁的处理大量数据则不推荐这样选择,仅当线程间的同步成了数据共享的瓶颈时,一个安全的容器类才有存在的价值。
以上内容,学习自线程安全的可变容器类
下述内容摘自博客文章:更可靠和高精度的 iOS 定时器
-
NSTimer
可靠性:
NSTimer不可靠,其所在的RunLoop 会定时检测是否可以触发 NSTimer 的事件,但由于 iOS 有多个 RunLoop 的运行模式,如果被切到另一个 run loop,NSTimer 就不会被触发。每个 RunLoop 的循环间隔也无法保证,当某个任务耗时比较久,RunLoop 的下一个消息处理就只能顺延,导致 NSTimer 的时间已经到达,但 Runloop 却无法及时触发 NSTimer,导致该时间点的回调被错过。最小精度:
理论上最小精度为0.1毫秒,不过由于受RunLoop的影响,会有50~100毫秒的误差,所以,实际精度可以认为是0.1秒。 -
CADisplayLink
也可以用作定时器,其调用间隔与屏幕刷新频率一致,也就是每秒60帧,间隔16.67ms。与NSTimer类似,如果在两次屏幕刷新之间执行了一个比较耗时的任务,其中的某一帧就会被跳过,造成UI卡顿。可靠性:
如果执行的任务很耗时,也会导致回调被错过,所以并不十分可靠。但是,假如调用者能够确保任务能够在最小时间间隔内执行完成,CADisplayLink就比较可靠,因为屏幕的刷新频率是固定的。最小精度:
受限于每秒60帧的屏幕刷新频率,注定CADisplayLink的最小精度为16.67毫秒。误差在1毫秒左右。 -
dispatch_source_t
精度很高,因为API接口中设置的都是纳秒的单位。但是当遇到比较耗时的运算任务的时候,就无法保证了。 -
更高精度的定时器
上述的各种定时器,都受限于苹果为了保护电池和提高性能采用的策略,导致无法实时地执行回调。并且前述的定时器的核心代码实际上是一样的。如果你的确需要使用更高精度的定时器,官方也是提供了方法。
而有别于普通定时器的高精度定时器,则是基于高优先级的线程调度类创建的定时器,在没有多线程冲突的情况下,这类定时器的请求会被优先处理。实现方法:
把定时器所在的线程,移到高优先级的线程调度类。
使用更精确的计时器API:mach_wait_until。换言之,你想要10秒后执行,就绝对在10秒后执行,绝不提前,也不延迟。最小精度: 小于0.5毫秒。
The queue you specify should be a concurrent queue that you create yourself using the dispatch_queue_create function. If the queue you pass to this function is a serial queue or one of the global concurrent queues, this function behaves like the dispatch_async function.
根据苹果的官方文档,barrier功能只能用在自定义的并发队列中,不能用在默认提供的并发队列中。如果用了,那么barrier功能是不起作用的,退化为普通的dispatch调用。
之前都会说下面的代码会死锁:
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"I will dead lock");
});
其实现在在最新的Xcode9下,下面的代码直接就崩溃了,应该是系统改进了,便于发现问题。
关于dispatch_get_current_queue被废弃的问题,是因为之前写下面的代码会导致死锁:
void func(dispatch_queue_t queue, dispatch_block_t block)
{
if (dispatch_get_current_queue() == queue) {
block();
}else{
dispatch_sync(queue, block);
}
}
- (void)deadLockFunc
{
dispatch_queue_t queueA = dispatch_queue_create("com.yiyaaixuexi.queueA", NULL);
dispatch_queue_t queueB = dispatch_queue_create("com.yiyaaixuexi.queueB", NULL);
dispatch_sync(queueA, ^{
dispatch_sync(queueB, ^{
dispatch_block_t block = ^{
//do something
};
func(queueA, block);
});
});
}
上面的代码会导致连续两次针对queueA调用dispatch_sync函数,问题在于GCD队列本身是不可重入的。
那么替代的方案是:
void dispatch_queue_set_specific(dispatch_queue_t queue, const void *key, void *context, dispatch_function_t destructor);
void dispatch_set_target_queue(dispatch_object_t object, dispatch_queue_t queue);
例如如下代码:
dispatch_queue_t queueA = dispatch_queue_create("com.yiyaaixuexi.queueA", NULL);
dispatch_queue_t queueB = dispatch_queue_create("com.yiyaaixuexi.queueB", NULL);
//这行代码是必须的
dispatch_set_target_queue(queueB, queueA);
static int specificKey;
CFStringRef specificValue = CFSTR("queueA");
dispatch_queue_set_specific(queueA,
&specificKey,
(void*)specificValue,
(dispatch_function_t)CFRelease);
dispatch_sync(queueB, ^{
dispatch_block_t block = ^{
//do something
};
//当前线程为queueB对应的线程里,但是却能够获取到specific值,就是由于前面设置了queueA为queueB的target queue.
CFStringRef retrievedValue = dispatch_get_specific(&specificKey);
if (retrievedValue) {
block();
} else {
dispatch_sync(queueA, block);
}
});
优先级反转是指在某种条件下,低优先级的任务阻塞了高优先级任务的执行,从而反转了任务的优先级。由于GCD有不同优先级的后台队列(background queue),所以最好是了解这种可能性。
当一个高优先级的任务和一个低优先级的任务访问一个共享资源时,优先级反转的问题就有可能发生。当低优先级的任务对共享资源加锁后,它应该非常快的执行完,然后释放出锁,让高优先级的任务执行。然而,在高优先级的任务被阻塞期间,有可能中优先级的任务得到执行的机会,从而抢占了低优先级任务的执行机会。这样的话,中优先级的任务就抢在了高优先级任务前面,得到了执行的机会。
下面的图描述了这种可能性:

为了避免这个问题的出现,在使用GCD时,总是使用默认优先级的队列,即使不同的优先级看起来很好。
-
搭建多线程环境
另外创建NSManagedObjectContext时,指定并发模式为NSPrivateQueueConcurrencyType,这样context会创建并管理一个private queue.
应用启动时创建的context,使用的是NSMainQueueConcurrencyType,被关联到了主线程。 -
在private queue context中进行操作时,应该使用performBlock:或是performBlockAndWait:方法,这两个方法能够保证操作会在正确的queue中执行。
-
多个context同步最简单的方案如下:
NSNotificationCenter.defaultCenter().addObserver(self,
selector: "backgroundContextDidSave:",
name: NSManagedObjectContextDidSaveNotification,
object: backgroundContext)
func backgroundContextDidSave(notification: NSNotification){
mainContext.performBlock(){
mainContext.mergeChangesFromContextDidSaveNotification(notification)
}
}
这里要注意的是,注册通知时一定要设置object参数,不要传nil。原因是一些系统框架内部也会使用Core Data,如果不指定产生通知的对象,那么有可能会收到意料之外的通知。
- 大量数据的处理
大量数据意味着需要我们关注内存占用和性能,写代码时需要刻如下规则:
1)尽可能缓存需要的数据,不相关的数据保持faults状态。
2)fetch时尽可能精准,少引入不相关的数据。
3)构建多context时尽量将同类managed object集中,最大限度减少合并需求。
4)提升操作效率,对Asynchronous Fetch, Batch Update, Batch Delete等新特性尽可能利用。


iOS中的响应者对象可能是UIView及其子类,UIViewController, UIWindow, UIApplication, AppDelegate。
UIView:
如果视图是ViewController的根视图,下一个响应者为ViewController,否者是视图的父视图。
UIViewController:
UIViewController的nextResponder属性为其管理view的superview.
UIWindow:
下一个响应者为UIApplication对象
UIApplication:
下一个响应者为app delegate,但是代理应该是UIResponder的一个实例
AppDelegate:
下一个响应者应该是nil。
职责链是如何建立起来的呢?
我们的app中,所有的视图都是按照一定的结构组织起来的,即树状层次结构,每个view都有自己的superView,包括controller的topmost view(controller的self.view)。当一个view被add到superView上的时候,他的nextResponder属性就会被指向它的superView,当controller被初始化的时候,self.view(topmost view)的nextResponder会被指向所在的controller,而controller的nextResponder会被指向self.view的superView,这样,整个app就通过nextResponder串成了一条链,也就是我们所说的响应链。所以响应链就是一条虚拟的链,并没有一个对象来专门存储这样的一条链,而是通过UIResponder的属性串连起来的。如第一张图所示。
- 可以为UIView扩展一个viewController方法,利用responder链条,可以得到视图所属的view controller.
- casa大神博客里有篇文章:一种基于ResponderChain的对象交互方式提到了一种新的交互方式。
在商品详情页中使用了这种对象交互方式:商品详情页有各种cell,每个cell上面又有各种button事件,每个Cell也有各自的子View,子View中也有button事件需要传递,而cell本身也需要响应点击事件。在这种复杂且多层级UI事件场景下,如果用delegate的方式层层传递,代码确实不如用Responder Chain的事件交互方式容易维护。用block的话,事件处理逻辑就会被分散在各个对象生成的地方。用Notification则更加不合适了,毕竟它并不属于一对多的逻辑,如若其他业务工程师在其它地方也监听了这个Notification,事件处理逻辑就会变得极为难以管理。
- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event {
if (!self.isUserInteractionEnabled || self.isHidden || self.alpha <= 0.01) {
return nil;
}
if ([self pointInside:point withEvent:event]) {
for (UIView *subview in [self.subviews reverseObjectEnumerator]) {
CGPoint convertedPoint = [subview convertPoint:point fromView:self];
UIView *hitTestView = [subview hitTest:convertedPoint withEvent:event];
if (hitTestView) {
return hitTestView;
}
}
return self;
}
return nil;
}
一些讲的比较好的文章收集:
- 深入理解 RunLoop
- iOS刨根问底-深入理解RunLoop
- 解密-神秘的 RunLoop
- Run Loop 记录与源码注释
- https://blog.ibireme.com/2015/05/18/runloop/
事件驱动模型,相比于轮询等其他方式,其优点在于极大的提高了CPU使用率,在没有事件的时候,能够让出CPU时间片,来事件时也可以快速的得到响应。
NSRunLoop是CFRunLoop的高层抽象,runloop在cocoa中的应用相当广泛。
NSTimer,UIEvent,NSObject (NSDelayedPerforming),NSObject (NSThreadPerformAdditions),NSURLConnection 是通过 Source 的机制把事件加入到 RunLoop 中。
Autorelease,CADisplayLink,CATransition,CAAnimation 则是利用 observer 的机制,在 RunLoop 的循环周期中执行各自的操作。
更加底层的 GCD,mach kernel 也与 RunLoop 存在协作关系。
Inputsources异步的发送事件到一个线程。有两种类型:基于port的input source监视应用的Mach ports;自定义的input source监视自定义的事件源。这两种类型的input source的唯一区别在于信号是怎么发出的。基于port的源由内核自动的发出信号;自定义的源必须从另一个线程手动的发出信号。
由于CFRunloop的源码中有source0, source1这样的字眼,所以有些文章中,也将基于port的源称之为source1;而将自定义的源称之为source0。
自定义的输入源中,有一种是我们平常会用到的,即是下面这些函数:
performSelectorOnMainThread:withObject:waitUntilDone:
performSelectorOnMainThread:withObject:waitUntilDone:modes:
performSelector:onThread:withObject:waitUntilDone:
performSelector:onThread:withObject:waitUntilDone:modes:
performSelector:withObject:afterDelay:
performSelector:withObject:afterDelay:inModes:
要注意的是,上面的这些函数要想能够正常工作,目标线程必须有一个活动的run loop。否则selector是不会被执行的。也就是说,在下面的代码中,test方法并不会被执行。
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_BACKGROUND, 0);
dispatch_async(queue, ^{
[self performSelector: @selector(test) withObject: nil afterDelay: 2];
});
- (void)test {
NSLog(@"test");
}
NSTimer的执行必须依赖于RunLoop,也就是说,在一个创建的后台线程里,如果不创建并启动RunLoop,那么timer的回调方法是不会被执行的。
GCD Timer是通过dispatch port给Run Loop发送消息,来使RunLoop执行相应的block。如果所在线程没有RunLoop,那么GCD会临时创建一个线程去执行block,执行完之后再销毁掉,因此GCD的Timer是不依赖RunLoop的。并且在有RunLoop的情况下,也不受所处的mode的影响。
iOS应用启动后会注册两个Observer管理和维护AutoreleasePool。
第一个Observer会监听RunLoop的进入,它会回调objc_autoreleasePoolPush()向当前的AutoreleasePoolPage增加一个哨兵对象标志创建自动释放池。这个观察者的order是-2147483647优先级最高,确保发生在所有回调操作之前。
第二个Observer会监听RunLoop的即将进入休眠和即将退出RunLoop两种状态。在即将进入休眠时会调用objc_autoreleasePoolPop()和objc_autoreleasePoolPush()根据情况从最新加入的对象一直往前清理,直到遇到哨兵对象。而在即将退出RunLoop时会调用objc_autoreleasePoolPop()释放自动释放池对象。这个观察者的order是2147483647,优先级最低,确保发生在所有回调操作之后。
有一个Observer,专门负责UI变化后的更新,比如修改了frame、调整了UI层级(UIView/CALayer)或者手动设置了setNeedsDisplay/setNeedsLayout之后就会将这些操作提交到全局容器。而这个Observer监听了主线程RunLoop的即将进入休眠和退出状态,一旦进入这两种状态则会遍历所有的UI更新并提交进行实际绘制更新。
有一篇很牛的文章,对NSDictionary做了分析。
没有细看,简单总结一下:
对象的内存布局中,在实例变量的后面,还可以有更多的额外字节,这段内存的地址可以由void * object_getIndexedIvars(id obj);来返回。
这段内存以key1, object1, key2, object2,...的方式存储所有的(key, value).
下面上图。
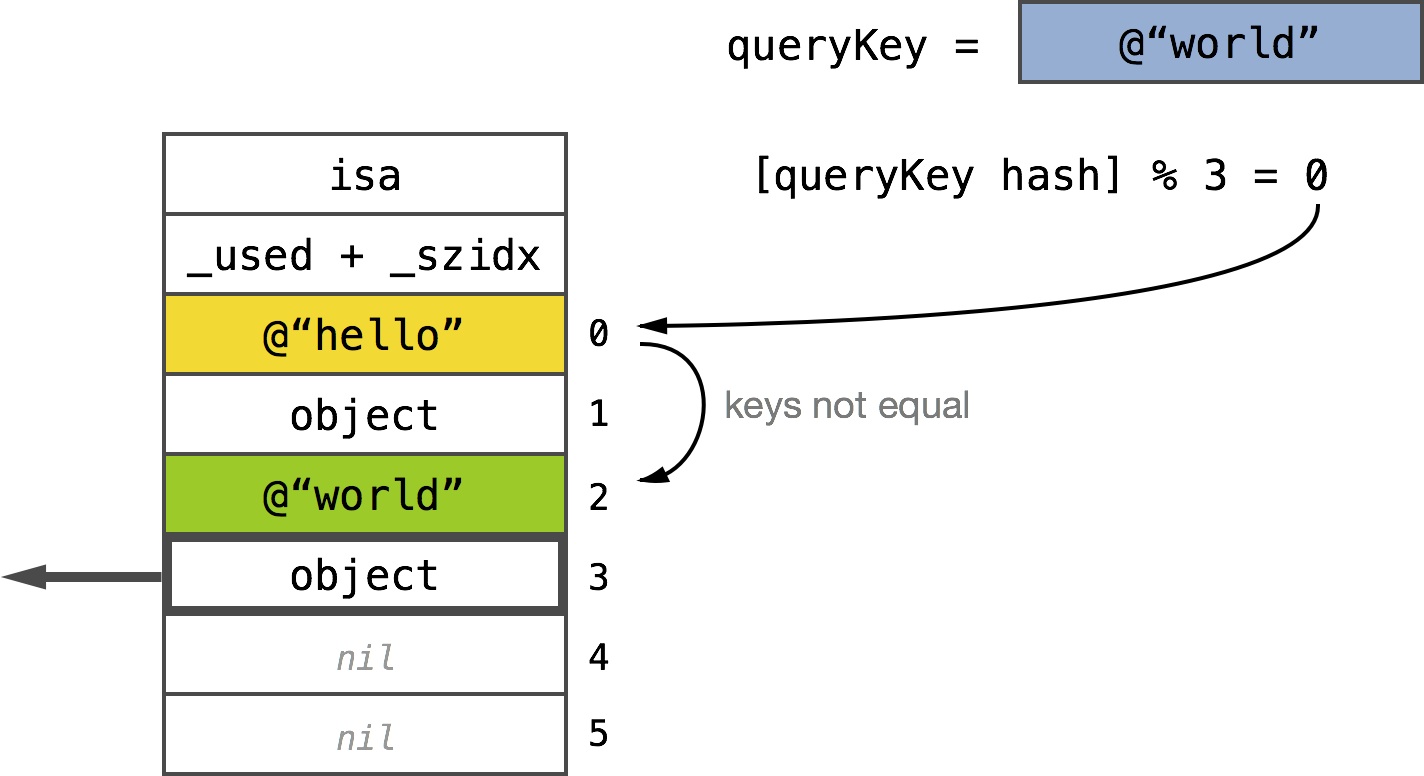
Keys and objects are stored alternately

When the key slot is empty, nil is returned
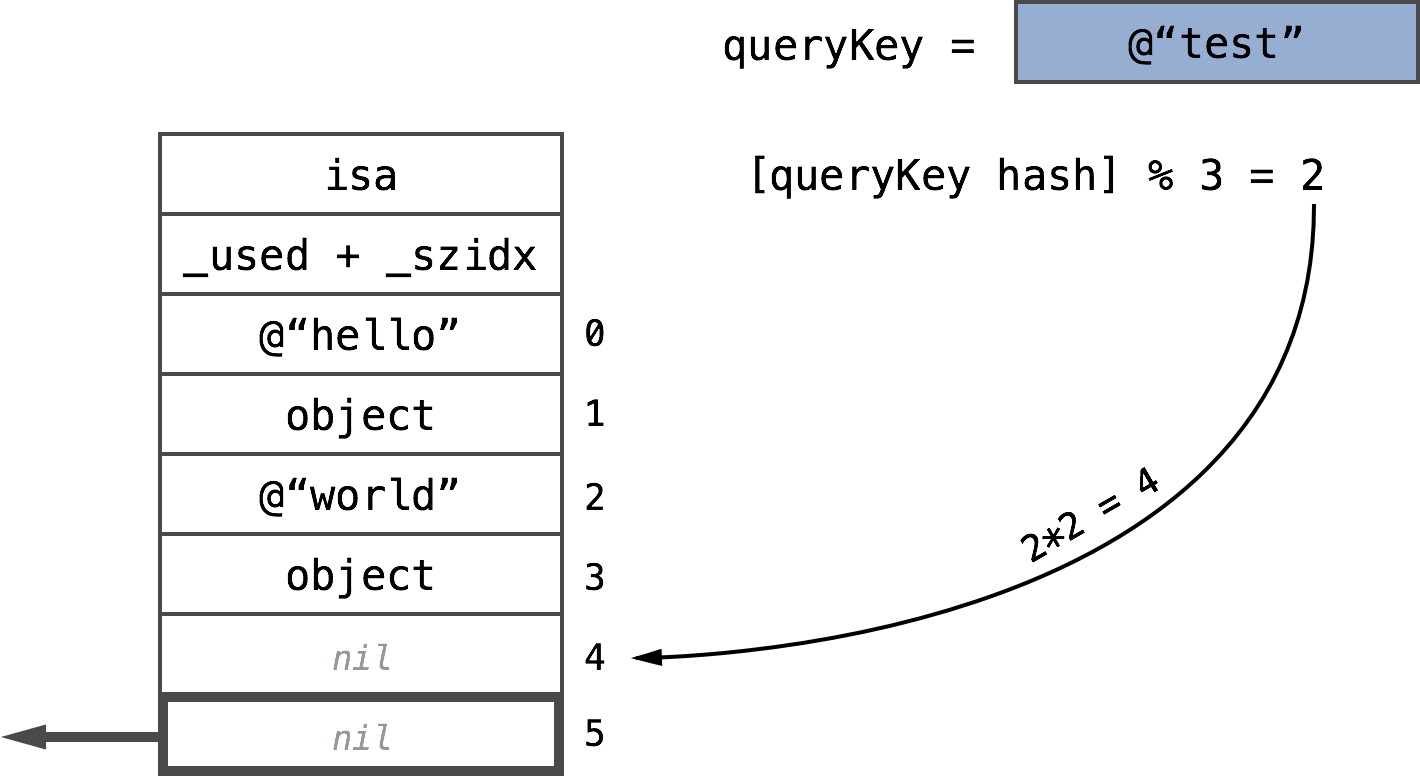
Key found after one collision
当app支持universal link时,用户可以点击到你站点的链接,然后跳转到安装的app,这个过程中不需要经过Safari。如果app没有安装,那么会在safari中打开链接。
universal link相比custom URL schemes, 有以下好处:
- 唯一性。Custom URL schemes由于是自定义的,多个APP之间就有可能产生冲突。而universal link就不会,因为使用了到自己站点的链接。
- 安全性。iOS在打开安装的APP之前,会先去你的web server去检查一个文件的内容,看你的站点是否允许你的应用打开这个链接。而只有开发者可以创建和上传这个文件,所以站点和APP之间的关联是安全的。
- 灵活性。在APP没有安装的情况下,universal link也是工作的。这时会在safari中打开链接。
- 简单性。一个URL可以同时用于website和APP。
- 私密性。其它的app和你的APP通信时,不需要知道你的APP是否已经安装。
对称加密:
这类算法在加密和解密时使用相同的密钥。
常见的对称加密算法有:DES, 3DES, AES, Blowfish, IDEA, RC5, RC6
特点:加密解密效率高,速度快,适合进行大数据量的加解密。
非对称加密:
非对称的加密算法,需要用到两个密钥:公钥和私钥。公钥对外公开,但并不会危害到另外一个的秘密性质。加密用公钥,解密用私钥。
常见的非对称加密算法有:RSA, DSA, ECC
特点:算法复杂,加解密速度慢,但安全性高,一般与对称加密结合使用(对称加密对内容加密,非对称加密对所使用的密钥加密)。
最常见的,在erase(iter)的时候,iter会失效。但是好在这种情况下,erase函数会返回一个新的迭代器。