Sorry, this page has not translated yet.
ComicCafeをインストールして最初にやることは自炊ファイルのインポートです。
インポートすることで初めてComicCafeサーバは自炊ファイルを認識し、Androidアプリから検索して読むことができる状態になります。インポートはとても重要な処理で、少し複雑なルールがあるので詳しく説明します。
ComicCafeを使う最大のメリットは、大量の自炊ファイルを分類、管理し、それらを様々な条件で検索できることにあります。
自炊ファイルを管理する方法としてComicCafeでは3種類の方法を提供しています。
- フォルダ構成、ファイル名で管理
自炊ファイルのファイル名に著者名、タイトル、巻数などを含めて管理する方法です。
ファイルマネージャで管理する時にもファイル名は重要ですし、基本的に自炊されている方はこの方法で管理していると思います。一番オススメの方法です。 - メタデータによる管理
海外で人気のある方法のようです。自炊ファイルにメタデータとしてxmlファイルなどを含めておき、そのxmlにタイトル、著者、巻数などを記述する方法です。
ファイル名で管理する方法に比べて情報量が多いので、管理方法としては理想的だと思いますが、ファイル名で管理するよりも手間がかかります。 - ISBMによる管理
自炊する時にISBNが記載されたバーコードのあるページをスキャンしておき、そのバーコードを元にWebサービスから書籍情報を取得する方法です。
一見優れた方法に思えますが、以下の理由からオススメできません。- 古い書籍ではISBNがバーコードがプリントされていないものがあります。
- Webサービスから取得できる書籍情報の精度があまりよくありません。
- 画像の傾き、画質によってバーコードのスキャンに失敗する可能性があります。
基本的にComicCafeはインポート処理でファイル名を解析してブックを分類します。
ComicCafeでは自炊ファイルを以下のルールで管理することを期待して作成されています。
この管理ルールは強制ではありませんが、ルールに従うことでComicCafeの機能を効率良く使うことができます。
- 1冊のブックが1ファイル(圧縮ファイル、PDF)であること。
- 入れ子の圧縮ファイルもサポートしていますが、1ファイルを1ブックとして認識します。
- 圧縮ファイルに含まれている画像ファイルのファイル名はページ順にソートされていること。
- page1,page2,page3 ... page10のように桁数がバラバラのファイル名は問題なく処理されます。
- 同一シリーズのブックが同じフォルダに保存されていること。
- 例えば「北斗の拳」1巻~最終巻は「北斗の拳」というフォルダに入れて管理するという意味です。ComicCafeは自炊ファイルが格納されているフォルダをシリーズとして認識します。
- 本によってはシリーズによる分類が難しい場合もありますので、その場合は、著者名など適当なフォルダ名をつけるのが望ましいです。
- 自炊ファイルのファイル名には、最低でもタイトル、巻数、著者名がふくまれているのが望ましいです。例えば以下の様なファイル名です。
- [鳥山明]ドラゴンボール 1巻.zip
- [鳥山明] ドラゴンボール 第01巻.rar
- 【鳥山明】トラゴンボール_1巻.zip
- 鳥山明 トラゴンボール 1.zip
- 自炊ファイルが格納されているフォルダ以外のフォルダはカテゴリという扱いになります。私は以下の様なディレクトリ構成で管理していますが、フォルダの構成は自由に決めていただいて問題ありません。
Book
|-説明書
|-技術本
|-漫画
|-少女コミック
|-少年コミック
|-週間少年マガジン
|-週間少年ジャンプ
|-[鳥山明]ドラゴンボール
|-[鳥山明]ドラゴンボール 1巻.zip
|-[鳥山明]ドラゴンボール 2巻.rar
以下の文字はファイル名の解析処理において特別な意味を持ちます。
| カッコ | 著者を区切る文字 | 完結を意味する文字 | セパレータ | 無視される文字 |
|---|---|---|---|---|
| "" | × | 完 | 半角スペース | 第 |
| '' | x | 完結 | 全角スペース | 巻 |
| () | ☓ | 最終巻 | _ | Vol |
| [] | X | end | _ | Vol. |
| {} | ✕ | / | V | |
| <> | ・ | |V. | ||
| 「」 | ・ | v | ||
| 「」 | & | v. | ||
| {} | ||||
| () | ||||
| 【】 | ||||
| 『』 | ||||
| [] | ||||
| ≪≫ | ||||
| 《》 | ||||
| 〈〉 | ||||
| 〔〕 | ||||
| <> | ||||
| “” | ||||
| ‘’ |
インポートの処理を以下のパスにファイルが存在すると仮定して説明します。
/mnt/HDD/Books/漫画/週刊少年ジャンプ/[鳥山明]ドラゴンボール/[一般コミック][鳥山明]ドラゴンボール 1巻.zip
*** 2~41巻 ***
/mnt/HDD/Books/漫画/週刊少年ジャンプ/[鳥山明]ドラゴンボール/[一般コミック][鳥山明]ドラゴンボール 42巻 (完).zip
まず、インポートのルートとなるディレクトリを選択します。
今回の例では「Books」フォルダか「漫画」フォルダが適切だと思います。
仮に「mnt」フォルダをルートフォルダとしてしまうと、「mnt」「HDD」もカテゴリとして認識されてしまいます。
また、検索するファイル数が増えるためインポート処理に時間がかかることになります。
ここではルートフォルダに「Books」を選択した場合を例として説明します。
- Booksフォルダ以下にある、以下の条件に該当するファイルを再帰的に検索します。 - 拡張子がCBZ/ZIP,CBR/RAR,7Z/CB7,LZH,PDFのいずれかであること。(大文字小文字は区別しません) - 圧縮ファイルの中にJPG,JPEG,PNG,GIF,BMP,BPGのファイルが1つ以上存在すること - 既にインポート済みでないこと。(同じハッシュ値のファイルがインポートされている場合はスキップします) - 対象のファイルが無視リストに登録されていないこと。
- ルートフォルダから見つかった自炊ファイルが保存されているフォルダまでを、カテゴリ、シリーズとして認識します。 - 例では「Books」「漫画」「週刊少年ジャンプ」の3フォルダがカテゴリとして登録され、「[鳥山明]ドラゴンボール」がシリーズとして登録されます。 - 自炊ファイルが保存されていて、さらに子フォルダが存在するようなフォルダは、カテゴリ、シリーズの両方として登録される可能性があります。
- シリーズとなるフォルダのフォルダ名と、自炊ファイルのファイル名を解析します。 - まずカッコで括られている文字や、アンダーバー、ハイフン、スペースなので分割されている文字を分解します。 - 上記の例では、'一般コミック', '鳥山明', 'ドラゴンボール', '42', '巻', '完'に分割されます。 - ComicCafeのDBには予め大量の著者、出版社の情報が保存されています。そのデータを使って分割した文字列が何を意味しているのかを判断します。
| 文字列 | 結果 |
|---|---|
| 一般コミック | カッコにくくられている著者でも出版社でも特別な文字でもないので、タグとして認識します。 |
| 鳥山明 | 著者データベースに存在するデータなので、著者として認識します。 |
| ドラゴンボール | カッコなどにくくられていない不明な文字列なのでタイトルの一部として認識します。 |
| 42 | 数字なので巻数である可能性が高いと認識します。 |
| 巻 | 巻数を表す文字列だと認識します。 |
| 完 | カッコにくくられた特別な文字だと認識し、このシリーズが完結していると判断します。 |
- 例えば「エリア88」など数字を含む漫画の場合は、うまく判断できない可能性があります。
- 自炊ファイルに著者名が含まれていなくても、シリーズのディレクトリに著者名が含まれていれば、ブックの著者として登録されます。
- 例え著者の名前であっても、ComicCafeのDBに登録されていない場合は、著者として認識されません。その場合は著者の管理画面から著者を登録してください。
- カッコの対応が不正だと、うまく処理されません。例えば {一般コミック] などです。(半角、全角も区別します)
- 処理の結果、意図しない文字列がタグとして登録される可能性があります。その場合はタグの管理画面から不要なタグを削除してください。
- インポート設定で
インポート時にタグを作成するを無効にしている場合は、登録済みのキーワードのみタグとして処理されます。
ComicCafeは ComicRack, ComicBookInfo, CoMet の3種類のメタ情報をサポートしています。
これらは各アプリケーションが独自に定義したメタ情報の管理方法で、MP3タグのようなものです。
それぞれの詳しい仕様は、リンク先を参照してください。インポート時にこれらのメタファイルを検出した場合、ComicCafeはメタファイルの情報を優先し、ファイル名の解析処理はスキップします。
以下の設定はインポート処理の振る舞い、パフォーマンスに影響を与えますので 必要であればインポート処理を行う前に設定することをオススメします。
- [設定]->[インポート]->[インポート時にタグを作成する]
インポート時のファイル名解析処理においてカッコに囲まれていて、
かつ著者データベースや出版社データベースに登録されていない不明な文字列を検出した場合に、
その文字列を自動的にタグとして認識し登録します。
- [設定]->[インポート]->[インポート時に横長の画像は2分割して表紙画像を生成する]
インポート時に自炊ファイル内に含まれる最初の画像を表紙画像として登録します。
その画像は横長の場合、画像を分割して表紙画像とするかどうかを指定します。
これにより表紙を裏表紙と一緒にスキャンしている場合に、前表紙のみが表紙として表示されるようになります。
- [設定]->[システム]->[ISBNのスキャン]->[インポート時にISBNをスキャンする]
インポート時に画像に含まれるバーコードをスキャンするかどうかを指定します。
有効にした場合、画像の解析を行い画像の中からISBNのバーコードを探してスキャンします。
スキャンに成功した場合、ISBNとしてDBに登録されます。
この処理は負荷の高い処理になるので、有効にして大量の自炊ファイルをスキャンすると処理時間がかなりかかる可能性があります。
画像が不鮮明だったり、傾きが大きい場合は画像にバーコードが含まれていてもスキャンに失敗することがあります。
- [設定]->[システム]->[ISBNのスキャン]->[先頭ページからスキャンするページ数]
ISBNのスキャンを有効にした場合、最初のページから何ページまでをスキャンするか指定します。
最初のページに必ずバーコードが含まれている場合は、1に設定してください。
スキャンするページ数を増やすと、インポートにかかる時間が長くなります。
- [設定]->[システム]->[ISBNのスキャン]->[最終ページからスキャンするページ数]
ISBNのスキャンを有効にした場合、最後のページから何ページまでをスキャンするか指定します。
スキャンするページ数を増やすと、インポートにかかる時間が長くなります。
- [設定]->[システム]->[PDF]->[PDFを処理するライブラリ]
ComicCafeはPDFを処理する際、Jpeg画像に変換して処理します。
インポート時は表紙画像を生成する為に、画像変換を行います。
PDFを処理するのにComicCafeではPdfBoxとPdfRendererというオープンソースのライブラリを使用しています。
これらのライブラリは万能ではなく、PDFによっては正しく処理できない場合があります。
もし、PDFの表紙画像がうまく作成されなかった場合、は使用するライブラリを切り替えてみてください。
自炊ファイルに含まれる最初のページを表紙画像として、適切にリサイズしてDBに登録します。
表紙画像はクライアントがブックを検索した際に表示されます。
もし最初のページが表紙画像でない場合は、後から管理画面、クライアントから表紙画像を変更することが可能です。
設定でISBNの自動スキャンが有効で、システムで使用できるメモリ量が十分な場合にComicCafeは画像からISBNのバーコードをスキャンします。
ISBNを認識できた場合はDBに登録されWebサービスとの連携に利用されます。
画像の傾きが大きかったり、画質が悪い場合、バーコードを正確に読み取れない可能性があります。
ComicCafeは圧縮ファイルの解凍に7-Zip-JBindingというオープンソースのライブラリを使用しています。
このライブラリは非常に素晴らしいものですが、バグがあり特定の圧縮ファイルを解凍しようとすると、Javaのプロセスごとクラッシュしてしまいます。
このバグを回避する為に、ComicCafeではファイルのインポート処理を実施する前に、無視リストに対象のファイルを追加します。そしてインポート処理が終了したタイミングで無視リストから削除します。もしインポート処理中にJavaがクラッシュした場合は、無視リストからの削除処理が実行されないので、次回インポート時にクラッシュの原因となったファイルはスキップされます。
つまり、無視リストに登録されているファイルは7-Zip-JBindingが処理できないファイルということになります。
そのようなファイルに遭遇した場合は、一度ファイルを任意のアーカイバーで解凍し、無圧縮Zipなどで再度圧縮してください。無圧縮Zipであれば間違いなく7-Zip-JBindingは処理することができます。
今のところ無視リストからデータを削除する処理は提供しておりません。どうしても削除したい場合は、自身でデータベースに直接接続してSQLを実行してレコードを削除してください。
HDDとしてNAS(Network Attached Storage)を使用している場合、ComicCafeサーバーをインストールしたPCにネットワークドライブの割り当て(マウント)をすることで、NAS上のフォルダをインポートすることができます。
しかしPCとNASの間で余計な通信が発生するためインポート処理のパフォーマンスがかなり悪化するので注意が必要です。可能であればUSB3.0接続の外付けHDDを使うのが良いでしょう。
-
インポート処理を行うフォルダを選択して
インポートボタンを押します。選択したフォルダ以下にある全てのファイルがスキャンされインポートされます。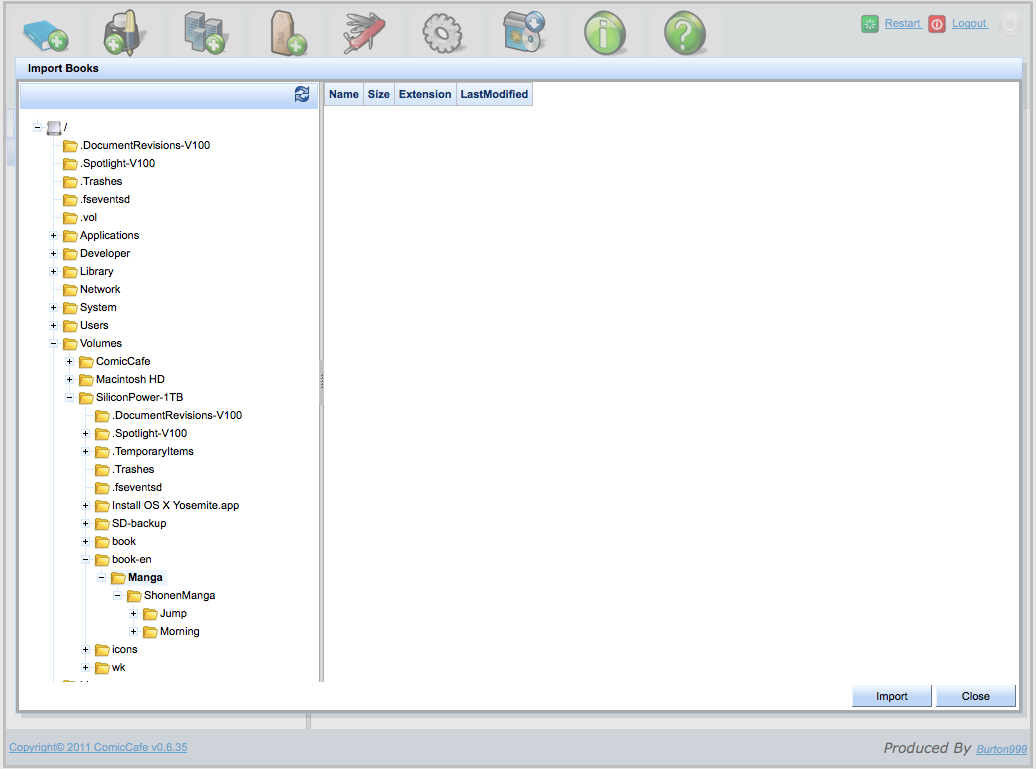
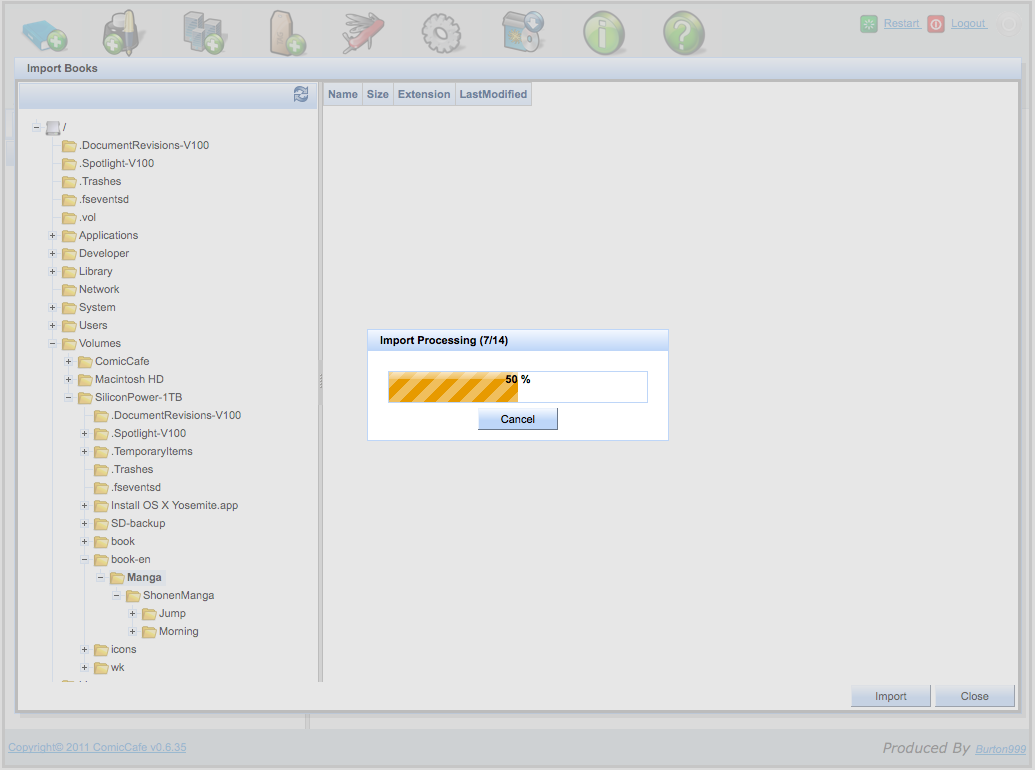
-
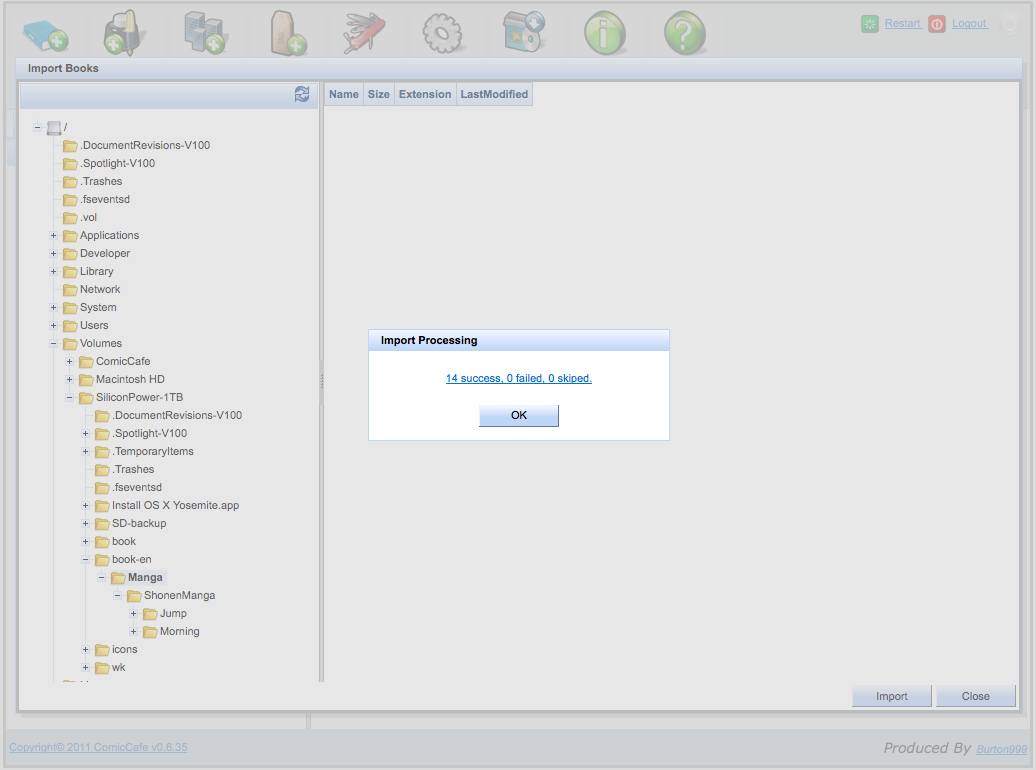
インポート処理が開始され、プログレスバーが表示されます。インポート処理は非常に時間のかかる処理です。自炊ファイル数が多いと半日ぐらいかかるので、気長に待ちましょう。インポート中でもクライアントからアクセスして読書することは可能です。
-
終了すると、インポートに成功した件数、失敗した件数、スキップした件数が表示されます。またリンクをクリックすると失敗した原因の詳細が確認できます。