Implement simplified Nesterov momentum #53
Comments
|
Hi I might be mistaken, but I dont think your interpretation of the Bengio et al. paper is right. They show that the parameter update (Formula 7) is the same as the one in the regular momentum (Formula 5), except for different coefficients. These coefficients however are then not the same as those used to update the velocity (Formula 6) (which would make if completely the same). That's what makes the difference (although probably a rather slight one?). |
|
Hi @pwohlhart , due to the limitation of the current gradient based solver that it only evaluates the gradient once and updates the parameters once every iteration, my implementation is slightly different from (and perhaps slightly faster than) the original NAG. Each iteration of the standard NAG can be viewed as:
Due to the aforementioned limitations, my implementation is:
Here several parameter updates in the original algorithm are consolidated. The only slight difference between this method and the standard NAG is that the parameter states between iterations are always the "future point" of that iteration, i.e. |
Fix caffe managed Nuget packages
- as solution provided compilation param DISABLE_DEVICE_HOST_UNIFIED_MEMORY to force disabling support host unified memory
Mali GPU does not support host unified memory in fact #53
- missed changes to CMakeLists.txt for original issue
Mali GPU does not support host unified memory in fact #53
The main idea of Nesterov accelerated gradient (NAG, Nesterov momentum) is to update the parameter with the gradient at the predicted (peeked-ahead) parameter. To reduce the sample variance, NAG smoothes the update by exponentially averaging the histories.
Sutskever et al.[1] proved that NAG was effective to improve the stability and convergence rate of stochastic optimization of deep network. They showed it could be done in two steps.
Simplified Nesterov momentum updates:
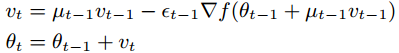
Bengio et al.[2] reformulated it to indicate that it was equivalent to the standard momentum except for different linear weighting coefficients.
[1] Sutskever, I., Martens, J., Dahl, G. and Hinton, G. E. On the importance of momentum and initialization in deep learning. In 30th International Conference on Machine Learning, Atlanta, USA, 2013. JMLR: W&CP volume 28.
[2] Yoshua Bengio, Nicolas Boulanger-Lewandowski, Razvan Pascanu. Advances in Optimizing Recurrent Networks. arXiv 1212.0901.
The text was updated successfully, but these errors were encountered: