Add Multithreading for L2_LR Solver #25
Conversation
…ted yet and is subject to change.
|
@bwaldvogel Any progress on the PR? Would love to see an official release now that the C/Liblinear has multi-core support. |
…nt logic, supplement README.
|
FYI due to a lack of action on this pull request I have "hard" forked the project (https://github.com/jeffpasternack/liblinear-java) and deployed to the Central Repository (https://search.maven.org/artifact/com.jeffreypasternack/liblinear/2.21/jar). Multithreaded training is a major speedup when training large problems so I wanted to make sure it is widely available to those who want it. |
|
I’m sorry that it took me so long to answer. I would like to move forward with this topic and eventually integrate multicore support in liblinear-java.
|
{kind=link}
|
Closing this PR for the following reasons:
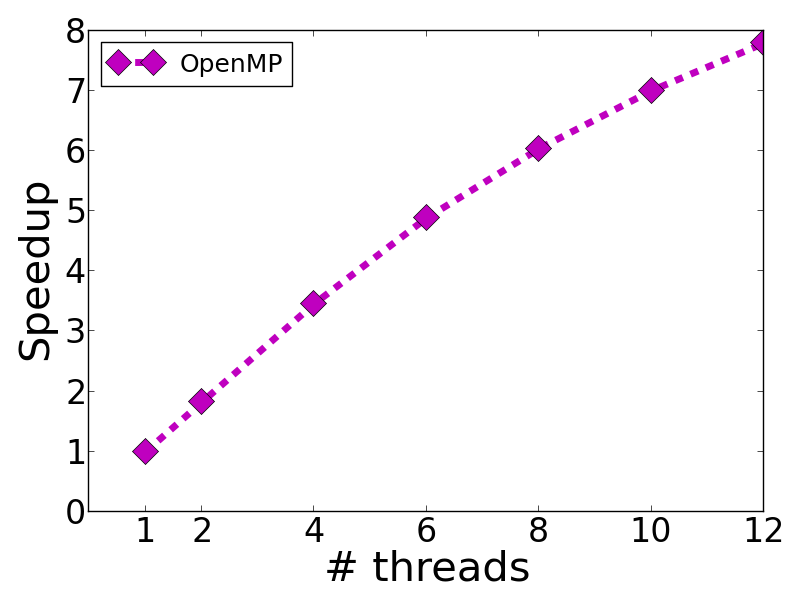
I see a couple of problems in the approach of this PR. For example, the A speed-up of factor 2.4 with 4 cores sounds like too much potential is given away. I would like to add multithreading but this will only work for me if
BTW: In most of my use cases in the past I trained multiple models in parallel with different threads (Yes, |
|
@bwaldvogel sorry that I didn't see your previous message. Yes, so far we've been fine with the hard fork, so for the moment there's no material incentive to invest in resolving the conflicts. With regards to the speed-up factor, this will depend on the number of examples and weights, but I agree it's definitely possible that a better synchronization scheme is possible. E.g. in the extreme a "hogwild" update scheme would use no synchronization, or (without potentially compromising correctness) using a more sophisticated fork-join scheme. Other approaches to parallelization are also possible, e..g parallelizing updates across parameters rather than examples (I don't know offhand what approach the original liblinear implementation opted for). |
(3) The actual multithreaded operations are in L2R_LrFunction. If multithreading is not used, the code paths are exactly the same as before, except that inner loops are factored into separate functions to avoid code duplication.
(4) Added unit tests.
I've tried to keep to the style of the original code. Wall clock speedup of a problem with 100K examples in 5 dimensions on a MacBook with 4 threads was roughly 2.4x (not rigorously tested).