You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
structtask_struct {
volatilelongstate; /* -1 unrunnable, 0 runnable, >0 stopped */void*stack;
atomic_tusage;
unsigned intflags; /* per process flags, defined below */unsigned intptrace;
#ifdefCONFIG_SMPstructllist_nodewake_entry;
inton_cpu;
structtask_struct*last_wakee;
unsigned longwakee_flips;
unsigned longwakee_flip_decay_ts;
intwake_cpu;
#endifinton_rq;
intprio, static_prio, normal_prio;
unsigned intrt_priority;
conststructsched_class*sched_class;
structsched_entityse;
structsched_rt_entityrt;
#ifdefCONFIG_CGROUP_SCHEDstructtask_group*sched_task_group;
#endifstructsched_dl_entitydl;
#ifdefCONFIG_PREEMPT_NOTIFIERS/* list of struct preempt_notifier: */structhlist_headpreempt_notifiers;
#endif#ifdefCONFIG_BLK_DEV_IO_TRACEunsigned intbtrace_seq;
#endifunsigned intpolicy;
intnr_cpus_allowed;
cpumask_tcpus_allowed;
#ifdefCONFIG_PREEMPT_RCUintrcu_read_lock_nesting;
unionrcu_specialrcu_read_unlock_special;
structlist_headrcu_node_entry;
#endif/* #ifdef CONFIG_PREEMPT_RCU */#ifdefCONFIG_PREEMPT_RCUstructrcu_node*rcu_blocked_node;
#endif/* #ifdef CONFIG_PREEMPT_RCU */#ifdefCONFIG_TASKS_RCUunsigned longrcu_tasks_nvcsw;
boolrcu_tasks_holdout;
structlist_headrcu_tasks_holdout_list;
intrcu_tasks_idle_cpu;
#endif/* #ifdef CONFIG_TASKS_RCU */#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
structsched_infosched_info;
#endifstructlist_headtasks;
#ifdefCONFIG_SMPstructplist_nodepushable_tasks;
structrb_nodepushable_dl_tasks;
#endifstructmm_struct*mm, *active_mm;
#ifdefCONFIG_COMPAT_BRKunsignedbrk_randomized:1;
#endif/* per-thread vma caching */u32vmacache_seqnum;
structvm_area_struct*vmacache[VMACACHE_SIZE];
#if defined(SPLIT_RSS_COUNTING)
structtask_rss_statrss_stat;
#endif/* task state */intexit_state;
intexit_code, exit_signal;
intpdeath_signal; /* The signal sent when the parent dies */unsigned intjobctl; /* JOBCTL_*, siglock protected *//* Used for emulating ABI behavior of previous Linux versions */unsigned intpersonality;
unsignedin_execve:1; /* Tell the LSMs that the process is doing an * execve */unsignedin_iowait:1;
/* Revert to default priority/policy when forking */unsignedsched_reset_on_fork:1;
unsignedsched_contributes_to_load:1;
#ifdefCONFIG_MEMCG_KMEMunsignedmemcg_kmem_skip_account:1;
#endifunsigned longatomic_flags; /* Flags needing atomic access. */pid_tpid;
pid_ttgid;
#ifdefCONFIG_CC_STACKPROTECTOR/* Canary value for the -fstack-protector gcc feature */unsigned longstack_canary;
#endif/* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->real_parent->pid) */structtask_struct__rcu*real_parent; /* real parent process */structtask_struct__rcu*parent; /* recipient of SIGCHLD, wait4() reports *//* * children/sibling forms the list of my natural children */structlist_headchildren; /* list of my children */structlist_headsibling; /* linkage in my parent's children list */structtask_struct*group_leader; /* threadgroup leader *//* * ptraced is the list of tasks this task is using ptrace on. * This includes both natural children and PTRACE_ATTACH targets. * p->ptrace_entry is p's link on the p->parent->ptraced list. */structlist_headptraced;
structlist_headptrace_entry;
/* PID/PID hash table linkage. */structpid_linkpids[PIDTYPE_MAX];
structlist_headthread_group;
structlist_headthread_node;
structcompletion*vfork_done; /* for vfork() */int__user*set_child_tid; /* CLONE_CHILD_SETTID */int__user*clear_child_tid; /* CLONE_CHILD_CLEARTID */cputime_tutime, stime, utimescaled, stimescaled;
cputime_tgtime;
#ifndefCONFIG_VIRT_CPU_ACCOUNTING_NATIVEstructcputimeprev_cputime;
#endif#ifdefCONFIG_VIRT_CPU_ACCOUNTING_GENseqlock_tvtime_seqlock;
unsigned long longvtime_snap;
enum {
VTIME_SLEEPING=0,
VTIME_USER,
VTIME_SYS,
} vtime_snap_whence;
#endifunsigned longnvcsw, nivcsw; /* context switch counts */u64start_time; /* monotonic time in nsec */u64real_start_time; /* boot based time in nsec *//* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */unsigned longmin_flt, maj_flt;
structtask_cputimecputime_expires;
structlist_headcpu_timers[3];
/* process credentials */conststructcred__rcu*real_cred; /* objective and real subjective task * credentials (COW) */conststructcred__rcu*cred; /* effective (overridable) subjective task * credentials (COW) */charcomm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by setup_new_exec *//* file system info */intlink_count, total_link_count;
#ifdefCONFIG_SYSVIPC/* ipc stuff */structsysv_semsysvsem;
structsysv_shmsysvshm;
#endif#ifdefCONFIG_DETECT_HUNG_TASK/* hung task detection */unsigned longlast_switch_count;
#endif/* CPU-specific state of this task */structthread_structthread;
/* filesystem information */structfs_struct*fs;
/* open file information */structfiles_struct*files;
/* namespaces */structnsproxy*nsproxy;
/* signal handlers */structsignal_struct*signal;
structsighand_struct*sighand;
sigset_tblocked, real_blocked;
sigset_tsaved_sigmask; /* restored if set_restore_sigmask() was used */structsigpendingpending;
unsigned longsas_ss_sp;
size_tsas_ss_size;
int (*notifier)(void*priv);
void*notifier_data;
sigset_t*notifier_mask;
structcallback_head*task_works;
structaudit_context*audit_context;
#ifdefCONFIG_AUDITSYSCALLkuid_tloginuid;
unsigned intsessionid;
#endifstructseccompseccomp;
/* Thread group tracking */u32parent_exec_id;
u32self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, * mempolicy */spinlock_talloc_lock;
/* Protection of the PI data structures: */raw_spinlock_tpi_lock;
#ifdefCONFIG_RT_MUTEXES/* PI waiters blocked on a rt_mutex held by this task */structrb_rootpi_waiters;
structrb_node*pi_waiters_leftmost;
/* Deadlock detection and priority inheritance handling */structrt_mutex_waiter*pi_blocked_on;
#endif#ifdefCONFIG_DEBUG_MUTEXES/* mutex deadlock detection */structmutex_waiter*blocked_on;
#endif#ifdefCONFIG_TRACE_IRQFLAGSunsigned intirq_events;
unsigned longhardirq_enable_ip;
unsigned longhardirq_disable_ip;
unsigned inthardirq_enable_event;
unsigned inthardirq_disable_event;
inthardirqs_enabled;
inthardirq_context;
unsigned longsoftirq_disable_ip;
unsigned longsoftirq_enable_ip;
unsigned intsoftirq_disable_event;
unsigned intsoftirq_enable_event;
intsoftirqs_enabled;
intsoftirq_context;
#endif#ifdefCONFIG_LOCKDEP# defineMAX_LOCK_DEPTH 48UL
u64curr_chain_key;
intlockdep_depth;
unsigned intlockdep_recursion;
structheld_lockheld_locks[MAX_LOCK_DEPTH];
gfp_tlockdep_reclaim_gfp;
#endif/* journalling filesystem info */void*journal_info;
/* stacked block device info */structbio_list*bio_list;
#ifdefCONFIG_BLOCK/* stack plugging */structblk_plug*plug;
#endif/* VM state */structreclaim_state*reclaim_state;
structbacking_dev_info*backing_dev_info;
structio_context*io_context;
unsigned longptrace_message;
siginfo_t*last_siginfo; /* For ptrace use. */structtask_io_accountingioac;
#if defined(CONFIG_TASK_XACCT)
u64acct_rss_mem1; /* accumulated rss usage */u64acct_vm_mem1; /* accumulated virtual memory usage */cputime_tacct_timexpd; /* stime + utime since last update */#endif#ifdefCONFIG_CPUSETSnodemask_tmems_allowed; /* Protected by alloc_lock */seqcount_tmems_allowed_seq; /* Seqence no to catch updates */intcpuset_mem_spread_rotor;
intcpuset_slab_spread_rotor;
#endif#ifdefCONFIG_CGROUPS/* Control Group info protected by css_set_lock */structcss_set__rcu*cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */structlist_headcg_list;
#endif#ifdefCONFIG_FUTEXstructrobust_list_head__user*robust_list;
#ifdefCONFIG_COMPATstructcompat_robust_list_head__user*compat_robust_list;
#endifstructlist_headpi_state_list;
structfutex_pi_state*pi_state_cache;
#endif#ifdefCONFIG_PERF_EVENTSstructperf_event_context*perf_event_ctxp[perf_nr_task_contexts];
structmutexperf_event_mutex;
structlist_headperf_event_list;
#endif#ifdefCONFIG_DEBUG_PREEMPTunsigned longpreempt_disable_ip;
#endif#ifdefCONFIG_NUMAstructmempolicy*mempolicy; /* Protected by alloc_lock */shortil_next;
shortpref_node_fork;
#endif#ifdefCONFIG_NUMA_BALANCINGintnuma_scan_seq;
unsigned intnuma_scan_period;
unsigned intnuma_scan_period_max;
intnuma_preferred_nid;
unsigned longnuma_migrate_retry;
u64node_stamp; /* migration stamp */u64last_task_numa_placement;
u64last_sum_exec_runtime;
structcallback_headnuma_work;
structlist_headnuma_entry;
structnuma_group*numa_group;
/* * numa_faults is an array split into four regions: * faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer * in this precise order. * * faults_memory: Exponential decaying average of faults on a per-node * basis. Scheduling placement decisions are made based on these * counts. The values remain static for the duration of a PTE scan. * faults_cpu: Track the nodes the process was running on when a NUMA * hinting fault was incurred. * faults_memory_buffer and faults_cpu_buffer: Record faults per node * during the current scan window. When the scan completes, the counts * in faults_memory and faults_cpu decay and these values are copied. */unsigned long*numa_faults;
unsigned longtotal_numa_faults;
/* * numa_faults_locality tracks if faults recorded during the last * scan window were remote/local. The task scan period is adapted * based on the locality of the faults with different weights * depending on whether they were shared or private faults */unsigned longnuma_faults_locality[2];
unsigned longnuma_pages_migrated;
#endif/* CONFIG_NUMA_BALANCING */structrcu_headrcu;
/* * cache last used pipe for splice */structpipe_inode_info*splice_pipe;
structpage_fragtask_frag;
#ifdefCONFIG_TASK_DELAY_ACCTstructtask_delay_info*delays;
#endif#ifdefCONFIG_FAULT_INJECTIONintmake_it_fail;
#endif/* * when (nr_dirtied >= nr_dirtied_pause), it's time to call * balance_dirty_pages() for some dirty throttling pause */intnr_dirtied;
intnr_dirtied_pause;
unsigned longdirty_paused_when; /* start of a write-and-pause period */#ifdefCONFIG_LATENCYTOPintlatency_record_count;
structlatency_recordlatency_record[LT_SAVECOUNT];
#endif/* * time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */unsigned longtimer_slack_ns;
unsigned longdefault_timer_slack_ns;
#ifdefCONFIG_FUNCTION_GRAPH_TRACER/* Index of current stored address in ret_stack */intcurr_ret_stack;
/* Stack of return addresses for return function tracing */structftrace_ret_stack*ret_stack;
/* time stamp for last schedule */unsigned long longftrace_timestamp;
/* * Number of functions that haven't been traced * because of depth overrun. */atomic_ttrace_overrun;
/* Pause for the tracing */atomic_ttracing_graph_pause;
#endif#ifdefCONFIG_TRACING/* state flags for use by tracers */unsigned longtrace;
/* bitmask and counter of trace recursion */unsigned longtrace_recursion;
#endif/* CONFIG_TRACING */#ifdefCONFIG_MEMCGstructmemcg_oom_info {
structmem_cgroup*memcg;
gfp_tgfp_mask;
intorder;
unsigned intmay_oom:1;
} memcg_oom;
#endif#ifdefCONFIG_UPROBESstructuprobe_task*utask;
#endif#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsigned intsequential_io;
unsigned intsequential_io_avg;
#endif#ifdefCONFIG_DEBUG_ATOMIC_SLEEPunsigned longtask_state_change;
#endif
};
// <sched.h>structtask_struct {
...
structlist_headchildren; /* list of my children */structlist_headsibling; /* linkage in my parent’s children list */
...
}
#ifndefCONFIG_HAVE_COPY_THREAD_TLS/* For compatibility with architectures that call do_fork directly rather than * using the syscall entry points below. */longdo_fork(unsigned longclone_flags,
unsigned longstack_start,
unsigned longstack_size,
int__user*parent_tidptr,
int__user*child_tidptr)
{
return_do_fork(clone_flags, stack_start, stack_size,
parent_tidptr, child_tidptr, 0);
}
#endif
#ifdef__ARCH_WANT_SYS_FORKSYSCALL_DEFINE0(fork)
{
#ifdefCONFIG_MMUreturn_do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
#else/* can not support in nommu mode */return-EINVAL;
#endif
}
#endif
0x24_LinuxKernel_进程(一)进程的管理(生命周期、进程表示)
在UNIX操作系统下运行的应用程序、服务器以及其他程序都被称为进程。每个进程都在CPU的虚拟内存上分配地址空间。每个进程的地址空间都是独立的,因此进程和进程不会意识对方的存在,觉得自己是CPU上唯一运行的进程。从处理器的角度,系统上有几个CPU,就最多能运行几个进程。但Linux是一个多任务的系统,内核为了支持多任务需要在不同的进程之间切换,这样从时间维度的划分造成了多进程同时运行的假象。
内核借助CPU的帮助,负责进程切换,欺骗进程独占了CPU。这就需要在切换进程之前保存进程的所有状态及相关要素,并将进程置于IDLE状态。在进程切换回来之前,这些资源和信息需要恢复到CPU和内存上面。这些资源被成为进程上下文。
内核除了要保存进程一些必要信息之外。还需要合理分配每一个进程的时间片,通常重要的进程得到CPU的时间多一点,次要的进程时间少一点。这个时间分配的过程成为调度。
本文对于进程的表述的结构如下所示:
1. 用户空间定义
这部分介绍一些从用户空间视角来观摩进程的概念。
1.1 进程树
Linux对进程的表述采用了一种层次结构,每个进程都依赖于一个父进程。内核启动
init程序作为第一个进程,该进程负责进一步的系统初始化操作,并显示视提示符和登陆界面。因此init进程被称为进程树的根,所有的进程都直接或者间接起源自该进程。如下使用pstree程序的输出所示。这个树形结构的进程上面和新进程的创建方式密切相关。UNIX操作系统有两种创建新进程的机制分别是
fork()和exec()。fork()可以创建当前进程的一个副本且有独立的PID号码(父进程和子进程只有PID号码不同)。Linux使用了一个中所周的的技术来使fork更高效,那就是写时复制(copy on write)操作。exec()将一个新程序加载到当前的内存中执行,旧程序的内存页面被逐出,其内容被替换为新数据,然后开始执行新的程序。1.2 线程
除了重量级进程(有时候也成为UNIX进程),还有一个轻量级进程(线程)。本质上,一个进程包含若干个线程,这些线程使用着同样的地址空间,共享同样的数据和资源,因此除了使用同步的方法保护共享的资源之外,没有额外的通信机制了。这也是线程和进程的差别。
Linux使用
clone()的方法创建线程。其工作方式类似于fork,但启用了精准的检查,以确认那些资源与父进程共享、哪些资源为线程独立创建。1.3 用户空间进程编程
linux提供一些关于进程的系统调用,例如
fork()、getpid()、getppid()、wait()、waitpid(),可以创建进程,对父进程和子进程流程的一些控制。1.3.1 fork进程
https://github.com/carloscn/clab/blob/master/linux/test_pid/test_pid.c
两个进程会竞争一个终端输出:
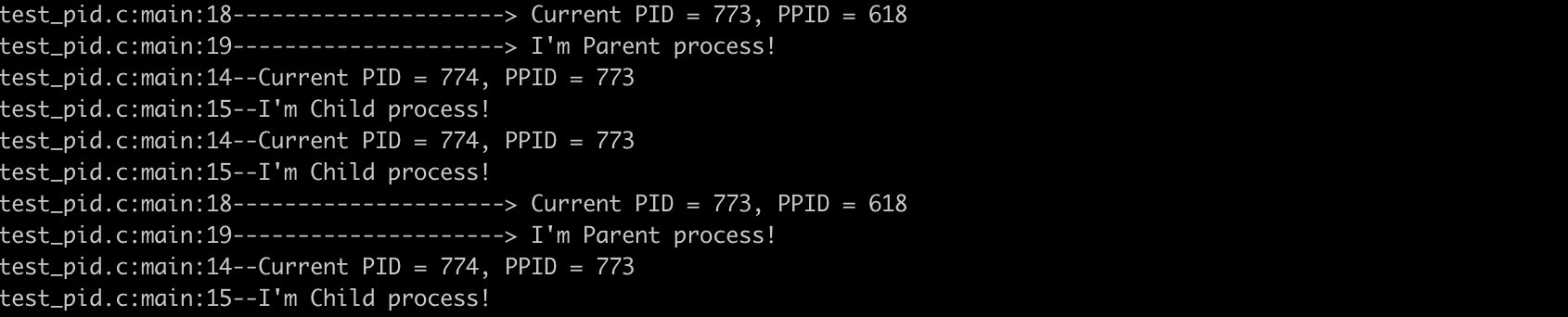

但是后台是被fork了两个进程:
1.3.2 zombie进程
fork进程之后,子进程的处理程序中直接退出,而父进程处理程序中没有任何等待子进程的操作。这时候子进程就会成为僵尸进程。僵尸进程会被init 0收养,等待父进程退出之后,僵尸进程会被init 0进程释放掉。
https://github.com/carloscn/clab/blob/master/linux/test_pid/test_pid_zombie.c
子进程退出之后,它成为僵尸进程。

父进程使用
waitpid可以观测到子进程是否已经退出,以及时回收进程资源。2. 进程的管理和调度
2.1 进程优先级
进程优先级粗暴分为实时进程和非实时进程:
进程优先级模型转换为时间片长度,优先级越高的占用的时间片越多。这种方案被称为抢占式多任务处理(preemptive multitasking),即各个进程都被分配到一定的时间片用来执行。时间到了之后,内核会从当前进程收回控制权,让不同的进程运行。抢占的时候所有的CPU寄存器的内容和页表都会保存起来,因此其结果并不会因为进程的切换而丢失。
2.2 进程的生命周期
2.2.1 状态机
一个进程是有状态机可以表示的,我们可以分为:**运行(running)、等待(waiting)、休眠(sleeping)和终止(stopped) **四个状态,如图所示:
状态机的切换是调度器来完成,切换条件可以解释为:
① Running -> Sleeping:如果进程必须等待事件,则状态变为“运行”直接切换到“睡眠”,但这个过程是不可逆的。
② Running -> Waiting: 调度器决定从进程收回资源的时候,过程状态从R变为W。
③ Sleeping -> Waiting:正如①所说,Sleeping没有办法直接变回Running,必须有一个中间状态waiting。
④ Waiting -> Running: CPU此时把资源分配给其他进程。在调度器授予CPU时间之前,进程一直保持waiting的状态。在分配CPU之后,其状态变为Running。
不在于周期范围内的进程:“僵尸进程(zombie)”:子进程被KILL信号(SIGTERM和SIGKILL)杀死,父进程没有调用wait4()。正常流程是,子进程被KILL,父进程调用wait4系统调用,通知内核子进程已死。处于僵尸进程状态进程:
2.2.2 抢占式多任务处理
2.3 进程的表示
Linux有一套自己对于进程管理的方式,还有调度器,调度器可以理解为真正去执行和指挥进程如何运行的东西,而管理方式可以说是调度器去管理进程的一个笔记计划表(task_struct)在include/sched.h中,这里有如何管理进程,进程命名,编号法等等。
2.3.1 task结构体
-Linux 通常把process當做是task,PCB (processing control block) 通常也稱為 struct tast_struct 1
https://elixir.bootlin.com/linux/v3.19.8/source/include/linux/sched.h#L1274
成员非常多,弄清楚费劲,可以分类:
2.3.2 进程状态机
2.3.3 进程资源限制
用户进程通过setrlimit()系统调用来增减当前限制,最大值不能超过rlim_max;getrlimits()用于检查当前限制。那么设定的资源是什么呢?
cat /proc/self/limits来查看当前系统设定进程的资源限制。Linux系统启动的时候会设定好当前资源限制的属性,在
include/asm-generic/resource.h中定义进程的资源限制,在linux启动的时候通过init进程完成配置。在init_task.h中挂载该数组。
2.3.4 进程类型
进程是由(二进制代码应用程序)、(单线程)、分配给应用程序的资源(内存、文件)。新进程是使用(fork)或者(exec)系统调用产生的。
2.3.5 命名空间
命名空间是解决进程之间权限访问问题的一种设计机制。Linux的全局管理特性,比如PID、UID和系统调用uname返回系统的信息都是全局调用。因此就导致资源和重用的问题,在虚拟化中亟需解决。把全局资源通过命名空间抽象出来,划分不同的命名空间对应不同的资源分配,可实现虚拟化环境。
父命名空间生成多个子命名空间,子命名空间有映射关系到父命名空间。
a) 命名空间的数据结构
创建新进程的使用使用fork可以建立一个新的命名空间,所以在fork的时候需要标记创建新的命名空间的类别。
在task_struct里面有有关于命名空间的定义:
struct task_struct里面挂的是stcut nsproxy的指针,只要挂上不同命名空间的指针,就算是赋予不同的命名空间了。
NOTE: 命名空间的支持必须在编译的时候启动 General setup -> Namespaces support,而且必须逐一指定需要支持的命名空间。如果内核编译的时候没有指定命名空间的支持,默认的命名空间的作用则类似于不启用命名空间,所有的属性相当于全局的。
b) UTS命名空间和用户命名空间
b.1) UTS命名空间
UTS命名空间是Linux内核Namespace(命名空间)的一个子系统,主要用来完成对容器HOSTNAME和domain的隔离,同时保存内核名称、版本、以及底层体系结构类型等信息。
就一个名字和kref,引用计数器,可以跟踪内核中有多少地方使用了struct uts_namespace的实例。
b.2) 用户命名空间
用户命名空间在数据结构管理方面类似于UTS:在要求创建新的用户命名空间时,则生成当前用户命名空间的一份副本,并关联到当前进程的nsproxy实例。但用户命名空间自身的表示要稍微复杂一些:
2.3.6 进程ID号
我们耳熟能详的PID(process id)在其命名空间中唯一的标识号码,我们也可以通过PID找到一个进程,对进程进行操作。在进程的领域,并不是只有PID,也有其他很多的ID类型。这些概念延伸至进程组2。
Linux对于PID是要进行管理的,而管理手段对PID进行数据结构的表述,这些数据结构一只脚踏入task_struct中,还有一只脚在命名空间映射,而且对于繁琐的PID的数据结构查找,Linux内核也提供了若干辅助函数用于扫描PID的数据结构。
PID的分配,首要保证的是PID在命名空间上的唯一性,内核提供了这样的方法,
alloc_pidmap和free_pidmap这样的方法可以分配和释放PID。a) 进程组的TGID
每个进程除了PID之外还有TGID(进程组的ID),组长(group leader)的PID = TGID。
在userspace提供
setpgid,getpgrp,getpgid的系统调用。这部分可以做一个实验,https://github.com/carloscn/clab/blob/master/linux/test_pid/test_process_grp.c
b) 管理PID
除了
pid和tgid还需要其他成员来管理PID,如下结构体:c) 管理PID函数
生成唯一的PID:
d) 进程关系
除了ID链接之外,内核还负责管理建立在UNIX进程创建模型之上的“家族关系”。术语如下:
task_struct之间的互相联系可以表现如图所示3:3. 进程管理相关的系统调用
在这部分,我们来讨论
fork和exec的系统调用实现。这部分其实在# 13_ARMv8_内存管理(一)-内存管理要素 有提及,但是是从内存管理的角度来看(内存分页技术在fork上面提供了写时复制功能,为其效率提升做了很大的贡献)。在这一节我们来了解一下fork如何实现的。同时,我们把
fork的系统调用实现,归纳到# 0x21_LinuxKernel_内核活动(一)之系统调用 的“可用系统调用”章节中去。3.1 进程复制
在Linux系统中,不仅仅只有一个
fork系统调用,还有其他系统调用,例如vfork,clone。fork进程依赖于写时复制技术的实现。fork、vfork、clone调用的内核函数分别是sys_fork,sys_vfork,sys_clone函数。三个函数最终也都调用了do_fork函数,这个函数内部大多数工作都是由copy_process复制进程的内核函数完成的。进程内部至少包含一个线程,因此进程复制中比较重要的处理过程就是对于线程的复制。每个线程都有自己独立的栈空间,因此这部分要很谨慎小心的处理。
进程复制涉及方方面面,比如对于进程一些共享信息的处理(内存),
shmat这样的系统调用就强调了在进程复制之前,复制后的行为4。3.1.1 写时复制
关于进程的系统调用分为:
fork():属于重量级调用,因为其建立了一个完整的进程副本,然后作为子进程去执行。为了减少工作量,linux内核使用了写时复制的的技术。由于写时复制技术的实现,vfork速度方面不再有优势,应避免使用vfork。vfork():类似于fork(),但是不会创建一个进程副本,父进程和子进程之间共享一份数据。好处就是节约了大量的CPU,而坏处是,父进程或者子进程之间任意一个成员修改数据都能影响到对方。vfork的设计用于子进程形成之后立即执行execve系统调用5加载新程序的情形。在子进程退出或者加载新程序之前,内核保证父进程处于阻塞状态。clone():产生线程,可以对父子进程之间的共享、复制进行精准控制。写时复制(Copy-on-write, COW)技术,防止了父进程被复制之后建立真的数据,避免了使用大量的内存,复制时操作耗费更多的时间。如果复制之后执行exec立即加载程序,那么负面效应更加严重,甚至复制都是多余的,因为exec会把新数据的内存替换到当前进程的内存位置,然后运行。
写时复制技术在底层实现的是在fork的时候,只复制父进程的页表,而不是复制真正的数据,而且父子进程不允许修改彼此的物理页(共享内存的物理页除外), 这种实现很简单,通过标记页表为只读属性,无论父子进程在尝试访问内存的时候,由于访问了只读属性的页面,处理器会向内核报告访问段错误,接着在段错误的处理函数中开始真正的复制数据。
COW机制使得内核可能尽可能的延迟内存的复制,更重要的是,实际上在很多情况下不需要复制,这样节约了大量的时间。
3.1.2 执行系统调用
do_fork
do_fork:https://elixir.bootlin.com/linux/v3.19.8/source/kernel/fork.c#L1626
NPTL(Native Poxsix Threads Library)库线程需要实现这个两个参数。6
linux-4.2之后选择引入一个新的
CONFIG_HAVE_COPY_THREAD_TLS,和一个新的COPY_THREAD_TLS接受TLS参数为额外的长整型(系统调用参数大小)的争论。改变sys_clone的TLS参数unsigned long,并传递到copy_thread_tls。新版本的系统中clone的TLS设置标识会通过TLS参数传递, 因此_do_fork替代了老版本的do_fork。sys_fork
从设计层次来看,
sys_fork是架构级定义(在arch/xxx/kernel目录下),调用linux/kernel下实现的do_fork实现。早期内核2.4.31版本都在自己的架构目录上实现:
新版本例如4.1.15版本的内核把
sys_fork已经去掉,换成:我们可以看到唯一使用的标志是SIGCHLD。这意味着在子进程终止后将发送信号SIGCHLD信号通知父进程。由于写时复制(COW)技术,最初父子进程的栈地址相同,但是如果操作栈地址闭并写入数据,则COW机制会为每个进程分别创建一个新的栈副本。如果do_fork成功,则新建进程的pid作为系统调用的结果返回,否则返回错误码。
sys_vfork
早期内核2.4.31版本都在自己的架构目录上实现:
同样,新版本例如4.1.15版本的内核把
sys_vfork已经去掉,换成:可以看到
sys_vfork的实现与sys_fork只是略微不同, 前者使用了额外的标志CLONE_VFORK | CLONE_VM。sys_clone
早期内核2.4.31版本都在自己的架构目录上实现:
同样,新版本例如4.1.15版本的内核把
sys_clone已经去掉,换成:我们可以看到sys_clone的标识不再是硬编码的,而是通过各个寄存器参数传递到系统调用,因而我们需要提取这些参数。其次,clone也不再复制进程的栈,而是可以指定新的栈地址,在生成线程时,可能需要这样做,线程可能与父进程共享地址空间, 但是线程自身的栈可能在另外一个地址空间。 另外,还指令了用户空间的两个指针(parent_tidptr和child_tidptr), 用于与线程库通信6。
3.1.3 进程的生命周期
下图是一个进程的生命周期和相应的探针点:
Unix 进程生成分为两个阶段3:
fork()系统调用。kernel 创建一个父进程的副本, 包括地址空间(在copy-on-write模式下),打开的文件,分配一个新的 PID。 如果fork()调用成功,这个将返回在两个进程的上下文中,这个有同一个指令指针(PC 指针是一样的) 在子进程中随后的代码通常用来关闭文件,重置信号等。execve()系统调用,这个将使用新的 based 传递给 execve() 来替换掉进程的地址空间。当调用
exit()系统调用,子进程将结束。 但是,进程也可以会被killed,当 kernel 出现不正确的条件(引发 kernel oops) 或者机器错误。 如果父进程像等待子进程结束,这个可以调用wait()系统调用(或者waitid()),wait()调用将收到进程的退出码,随后关联的task_struct将被销毁。 如果父进程不像等待子进程,子进程退出后,这个将被作为僵尸进程。 父进程可能会收到 kernel 发送的SIGCHLD信号。3.1.4 do_fork的实现
do_fork overview
do_fork无论是最新版还是老的linux版本,都是内核级的实现,这部分给架构级的sys_fork函数调用。从这里可以看出,这部分已经不是和平台相关的代码了,纯属内核内部的软件逻辑。kernel/fork.cdo_fork以调用copy_process开始,后者执行新进程的实际工作(收尾工作)。我们暂时不去理会copy_process内部做了什么。pid_nr_ns;如果没有创建命名空间只在局部PID获取即可task_pid_vnr。wake_up_new_task唤醒。copy_process
copy_process是do_fork中核心函数,任务是完成父进程的复制功能,这里面必须包含三个系统调用的请求处理fork\vfork\clone。这个复制过程比较复杂,我们大部分过程略过,具体解析参考《深入Linux内核架构》P55-P61,原版参考P66-P75。
thread问题
父进程的PCB实例只有一个成员不同:新进程分配了一个新的内核态栈,
task_struct->stack。通常栈和thread_info保存在一个联合体中,thread_info保存了线程所需要的所有特定处理器的底层信息。关系可以看:
在内核的某个特定组件使用了过多的栈空间的时候,内核栈就会溢出到thread_info上,这可能会出现严重的故障。在这种情况下,调用栈回溯的时候就会导致错误的信息出现,因此内核提供了
kstack_end函数,用于判断给出的地址是否位于栈的有效部分。Linux 並沒有特定的data structure來標示thread or process,thread與process都使用process的PCB。
3.2 内核线程
在linux系统中, 我们接触最多的莫过于用户空间的任务,像用户线程或用户进程,因为他们太活跃了,也太耀眼了以至于我们感受不到内核线程的存在,但是内核线程却在背后默默地付出着,如内存回收,脏页回写,处理大量的软中断等,如果没有内核线程那么linux世界是那么的可怕!7在进入我们真正的主题之前,我们需要知道一下事实:
我们知道linux所有任务的祖先是0号进程,然后0号进程创建了天字第一号的1号init进程,init进程是所有用户任务的祖先,而内核线程同样也有自己的祖先那就是kthreadd内核线程他的pid是2,我们通过top命令可以观察到:红色方框都是父进程为2号进程的内核线程,绿色方框为kthreadd,他的父进程为0号进程。
这里面有一个知识点惰性TLB(lazy TLB),把task_struct里面的mm_struct设定为空指针将成为惰性TLB进程。假设内核线程之后运行的进程与之前是同一个,在这种情况下,内核并不需要修改用户空间的地址表,地址表转换后备缓冲器(TLB)中的信息仍然有效。只有在内核线程执行的进程是与此前不同的用户层才需要切换,清除TLB数据。
创建内核线程的辅助方法是,
kthread_create:该函数创建一个新的内核线程,命名为namefmt。最初线程是挺值得,需要使用
wake_up_process启动它。词汇会调用kthreadfn给出线程函数。另一个备选方案是通过
kthread_run宏来代替。使用
ps fax可以输出方括号的进程为内核线程所属进程,与普通进程区分。3.3 启动新程序
Linux提供
execve系统调用启动新的程序,通过新代码替换现存程序。3.3.1 execve实现
该系统调用的入口节点是
sys_execve函数,早期内核2.4.31版本都在自己的架构目录上实现:bprm_init处理几个管理型的任务,包括mm_struct初始化,mm_init用于栈创建;prepare_binprm:用于提供一些父进程相关的值UID和GID;search_binary_handler用于do_execve结束之后查找一个适当的二进制格式,用于执行特定的文件。start_code和end_code指定该段在地址空间驻留区域。start_data和end_data之间。start_brk和brk指定边界。start_stack定义。几乎所有的寄存机栈都是自动向下增长的。唯一的例外是PA-RISC。对于栈反向增长,体系结构相关部分的实现必须告知内核,可以通过设定STACK_GROWSUP完成。arg_start和arg_end之间,还有env_end和env_start、除了ELF格式,还有几种Linux支持的二进制格式,这里列举作为参考:
3.3.2 解释二进制
在linux内核中,每种二进制都表示下列数据结构的实例:
load_binary:用于加载普通程序load_shlib:用于加载共享库core_dump:用于在程序错的情况下输出内存转储。内存转储随后可以使用调试器,例如gdb分析,以便解决问题。min_coredump是生成内存转储时,内存转储文件长度的下界。注意每种二进制格式首先必须使用
resgister_binfmt像内核注册。该函数的目的是向一个链表增加一种新的二进制格式。3.3.3 退出进程
进程必须
exit系统调用终止。这使得内核有机会将该进程的资源释放回系统。该调用入口点是sys_exit函数,需要一个错误码作为其参数。很快退出进程调度委托给do_exit。简言之,该函数的实现就是将各个引用计数器-1。4. 参考文献
Footnotes
# 奔跑吧 CH 3.1 進程的誕生 ↩
【进程】进程组__月雲之霄的博客-CSDN博客__进程组 ↩
Process management ↩ ↩2
Linux进程之间的通信-内存共享(System V) ↩
execve ↩
Linux下进程的创建过程分析(_do_fork/do_fork详解)--Linux进程的管理与调度(八) ↩ ↩2
深入理解Linux内核之内核线程(上) ↩
The text was updated successfully, but these errors were encountered: