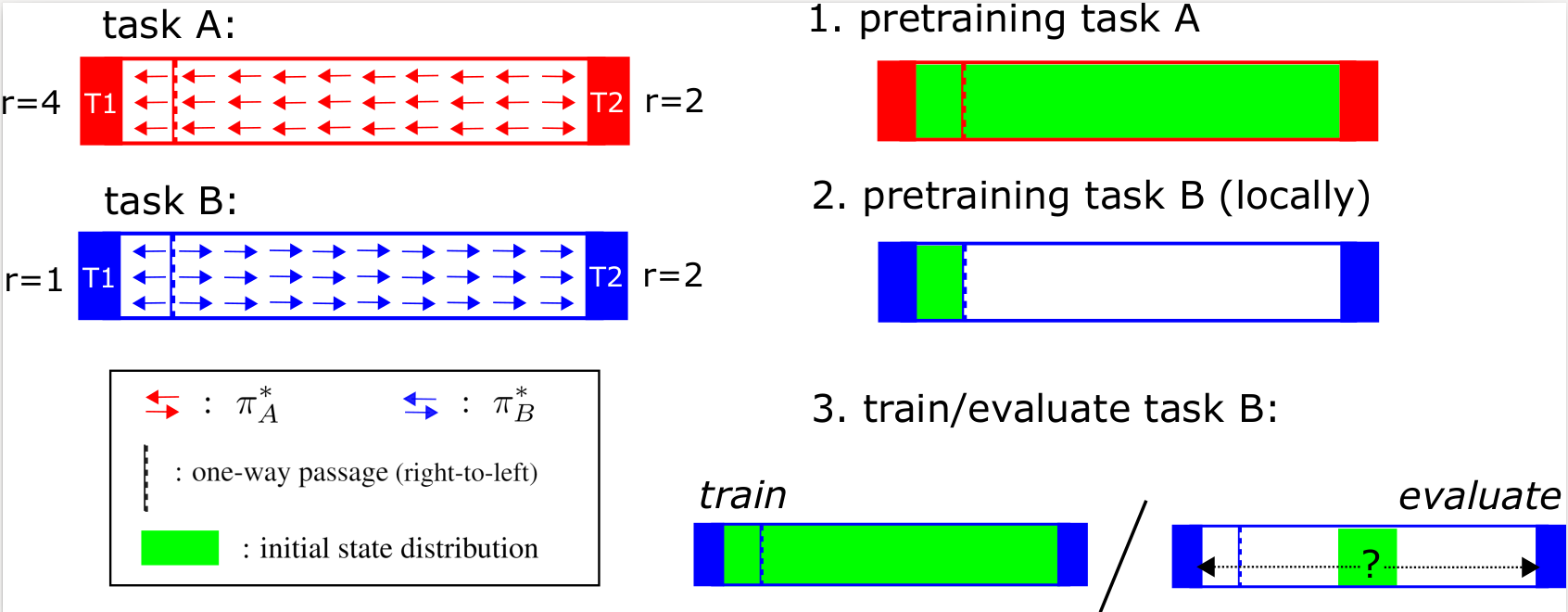
we introduce an experimental setup to evaluate model-based behavior of RL methods, inspired by work from neuroscience on detecting model-based behavior in humans and animals.
Task A and task B have the same transition dynamics, but a reward function that is locally different. An experiment consists of first pretraining a method on task A, followed by local pretraining around T1 of task B. After pretraining, the agent is trained and evaluated on the full environment of task B. The additional training a method needs before it has fully adapted to task B determines the size of the LoCA regret.
This code is tested with python 3.7. To install the required packages you can use:
pip install -r requirements.txt

First, change the directory to the LoCA_tabular:
cd LoCA_tabular
then use these commands to run the training or plot the results.
- Training:
python main.py - Visualize results :
python show_results.py
| PARAMETERS | Description |
|---|---|
--method {1: mb_vi, 2: mb_su, 3: mb_nstep, 4: sarsa_lambda, 5: qlearning} |
algorthms |
--LoCA_pretraining {False, True} |
skip the pretraining phase |
--alpha_multp |
step-size parameter, any value > 0 |
--S_multp {1, 2, 3, ...} |
artificially increasing the size of the state space |
--n_step 1 |
only relevant when method = 3 (mb_nstep) |
We adopted MountainCar env for LOCA regret calculation. In our variation, the existing terminal state at the top of the hill corresponds with T1; we added an additional terminal state to the domain, T2, that corresponds with the cart being at the bottom of the hill with a velocity close to 0.

First, change the directory to the LoCA_tabular:
cd LoCA_MountainCar
- Pre-training + Training:
python main.py --method sarsa_lambda --env MountainCar - Pre-training with shuffled actions + Training:
python main.py --env MountainCar --flipped_actions - Training:
python main.py --env MountainCar --no_pre_training - Visualize results :
python show_results.py - Visualize MuZero results :
tensorboard --logdir=/results
| Arguments | Description |
|---|---|
--method {sarsa_lambda, MuZero} |
Name of the algorithm |
--env {MountainCar} |
Name of the environment |
----no_pre_training |
Skip the pretraining phase |
----flipped_actions |
pretrain with shuffled actions to cancel the effect of model learning |
The MuZero code for the experiments is adopted from here.
If you found this work useful, please consider citing our paper.
@article{van2020loca,
title={The LoCA Regret: A Consistent Metric to Evaluate Model-Based Behavior in Reinforcement Learning},
author={Van Seijen, Harm and Nekoei, Hadi and Racah, Evan and Chandar, Sarath},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={6562--6572},
year={2020}
}