anaGo is a Keras implementation of sequence labeling.
anaGo can perform Named Entity Recognition (NER), Part-of-Speech tagging (POS tagging), semantic role labeling (SRL) and so on for many languages.
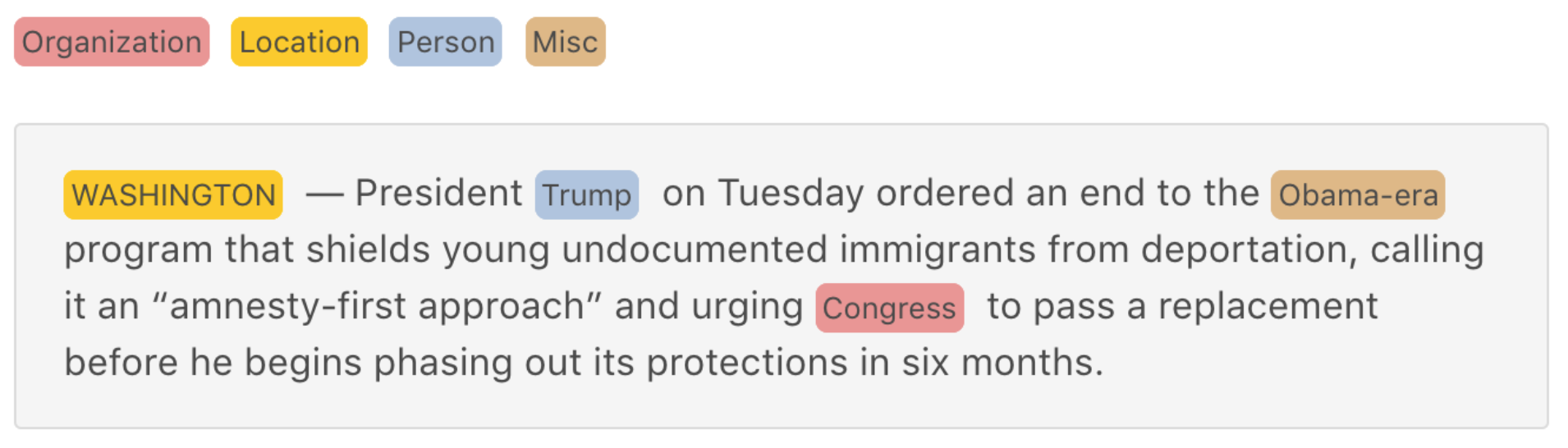
For example, the following picture shows Named Entity Recognition in English:
The following picture shows Named Entity Recognition in Japanese:

Similarly, you can solve your task (NER, POS,...) for your language. You don't have to define features. You have only to prepare input and output data. :)
anaGo supports following features:
- training the model without any features.
- defining the custom model.
- downloading pre-trained models.
To install anaGo, simply run:
$ pip install anago
or install from the repository:
$ git clone https://github.com/Hironsan/anago.git
$ cd anago
$ pip install -r requirements.txt
Training data takes a tsv format. The following text is an example of training data:
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
Peter B-PER
Blackburn I-PER
anaGo supports pre-trained word embeddings like GloVe vectors.
First, import the necessary modules:
import anago
from anago.reader import load_data_and_labelsAfter importing the modules, load training, validation and test dataset:
x_train, y_train = load_data_and_labels('train.txt')
x_valid, y_valid = load_data_and_labels('valid.txt')
x_test, y_test = load_data_and_labels('test.txt')Now we are ready for training :)
Let's train a model. To train a model, call train method:
model = anago.Sequence()
model.train(x_train, y_train, x_valid, y_valid)If training is progressing normally, progress bar would be displayed:
...
Epoch 3/15
702/703 [============================>.] - ETA: 0s - loss: 60.0129 - f1: 89.70
703/703 [==============================] - 319s - loss: 59.9278
Epoch 4/15
702/703 [============================>.] - ETA: 0s - loss: 59.9268 - f1: 90.03
703/703 [==============================] - 324s - loss: 59.8417
Epoch 5/15
702/703 [============================>.] - ETA: 0s - loss: 58.9831 - f1: 90.67
703/703 [==============================] - 297s - loss: 58.8993
...
To evaluate the trained model, call eval method:
model.eval(x_test, y_test)After evaluation, F1 value is output:
- f1: 90.67
Let's try tagging a sentence, "President Obama is speaking at the White House."
To tag a sentence, call analyze method:
>>> words = 'President Obama is speaking at the White House.'.split()
>>> model.analyze(words)
{
"words": [
"President",
"Obama",
"is",
"speaking",
"at",
"the",
"White",
"House."
],
"entities": [
{
"beginOffset": 1,
"endOffset": 2,
"score": 1,
"text": "Obama",
"type": "PER"
},
{
"beginOffset": 6,
"endOffset": 8,
"score": 1,
"text": "White House.",
"type": "ORG"
}
]
}To download a pre-trained model, call download function:
from anago.utils import download
dir_path = 'models'
url = 'https://storage.googleapis.com/chakki/datasets/public/models.zip'
download(url, dir_path)
model = anago.Sequence.load(dir_path)This library uses bidirectional LSTM + CRF model based on Neural Architectures for Named Entity Recognition by Lample, Guillaume, et al., NAACL 2016.