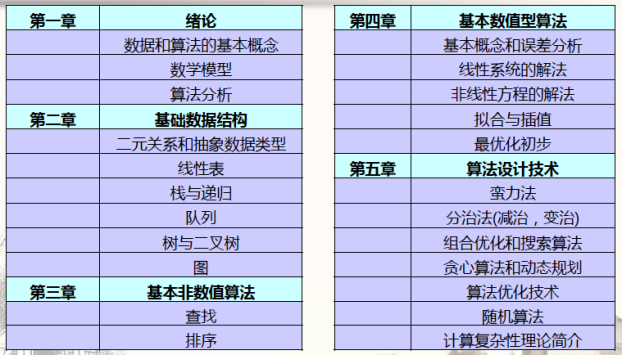
- 课程思路
- 算法:问题的程序化解决方案
- 5个重要特性:
- 有穷性
- 确定性
- 可行性
- 输入
- 输出
- 好算法衡量标准:
- 正确性
- 可行性
- 健壮性
- 高效率:时间空间资源占用少
- 算法的作用不是硬件性能提高所能替代的
- 算法执行时间的影响因素:
- 数据结构和算法的选择
- 问题规模
- 程序语言
- 计算机速度
- 运行情况
- 算法空间:
- 指令空间:存储程序指令
- 数据空间:存储常量和变量
- 环境空间:为程序运行、函数调用提供空间
- 5个重要特性:
- 数据的结构:
- 逻辑结构:集合、线性结构、树、图
- 存储结构:顺序存储、链式存储
- 数据与算法的关系:
- 数据是信息的载体,是算法处理的对象
- 算法是处理数据的系统和有效工具
- 数据处理技术
- 数据采集
- 数据存储
- 数据传输
- 数据计算
- 数学模型:对特定对象为达到某一目的得到的抽象简化的数学结构
- 算法 + 数据结构 = 程序
- 等价关系:=
- 自反性
- 对称性
- 传递性
- 偏序关系:≤
- 自反性
- 反对称性
- 传递性
- 拟序关系:<
- 反自反性
- 反对称性
- 传递性
- 全序关系:≤
- 设R是集合M上的偏序关系,若M中任意两个元素可比,则R是集合M上的全序关系
- 线性表特点:
- 线性表数据元素必须满足
同质性 - 相邻元素之间存在有序关系
位序
- 线性表数据元素必须满足
- 顺序表:线性表的顺序存取
- 主要操作:
- 插入:移动元素次数的期望为n/2
- 删除:移动元素次数的期望为(n-1)/2
- 算法稳健性的指标:
- 边界判断
- 存在性判断
- 溢出判断
- 特点:
- 可以随机存取元素
- 插入和删除时需要移动大量元素
- 需事先确定数据的规模,空间效率不高
- 主要操作:
- 链表:链式存储结构
- 特点:
- 逻辑上相邻的元素在物理地址上不需要相邻
- 依靠指针连接逻辑上相邻的元素
- 单向链表
- 链表结点:由数据域和指针域构成
- 主要操作:
- 插入:O(n)
- 删除:O(n)
- 优点:
- 插入和删除操作无需移动数据元素
- 空间利用率高
- 缺点:
- 不能随机存取
- 表长需要遍历链表得到
- 插入或者删除需要在链表中寻找操作位置
- 双向循环链表
- 缺点:双向循环链表的插入和删除需要修改两个方向的指针
- 特点:
-
基本概念:
- 栈的定义:只允许在一段进行插入和删除操作的线性结构
- 栈顶:允许插入和删除的一端
- 栈底:线性结构的另一端
- 栈长:数据元素的个数
- FILO == LIFO
-
顺序栈:
- 地址连续
- 栈的规模需要在初始化时确定
- 时间复杂度:进栈、出栈和销毁时间复杂度都是O(1)
- 空间复杂度:预先设置栈的长度,空间利用效率低
-
链式栈:栈的链表表示
- 地址任意
- 栈的规模不需要事先确定
- 时间复杂度:进出栈O(1),销毁O(n)
- 空间复杂度:一般不溢出,空间利用率高
-
栈的应用:
- 显式:括号匹配、表达式求值(前缀、中缀、后缀表达式)、迷宫求解
- 隐式:函数调用、递归
-
递归:直接或间接调用本身
- 递归的消除:
- 目的:提高时间和空间效率
- 递推法实现递归的消除
- 很多情形必须调用
显式的栈实现非递归
- 实际应用:阶乘求值、最大公因子、斐波那契数列、汉诺塔问题
- 递归的优势:便于叙述和设计,算法简洁易理解
- 递归的缺点:降低了运行效率
- 递归的消除:
-
栈混洗问题:
- Catalan数:可以使用Stirling公式逼近

- 基本概念
- 队列:在表的一端进行插入(入队),在另一端进行删除(出队)的线性结构
- 队尾:允许插入的一端
- 队头:允许删除的一端
- 队列的特点:先进先出(FIFO)
- 队列的分类:
- 循环队列:可以将队列看成一个圆形队列
- 存储队列的数组被当作首尾相接的表
- 区分循环队列的空与满:设置空位、设置标志、设置队列长度变量
- 链式队列:队头在链表头,队尾在链表尾
- 循环队列:可以将队列看成一个圆形队列
- 队列的应用:
- 缓冲技术:提高设备利用率,改善不同设备间速度不匹配
- 单缓冲
- 双缓冲
- 缓冲队列
- 缓冲技术:提高设备利用率,改善不同设备间速度不匹配
- 对"串"的理解
- 有限长度的字符序列
- 限定数据元素为字符的线性表
- 基本概念
- 子串:串中人一多个
连续字符组成的子序列 - 主串:包含该子串的串成为主串(相对于子串而言)
- 子串:串中人一多个
- 串匹配算法
- 目的:已知目标串和模式串,需要在目标串中找到一个与模式串相同的子串(又称为模式匹配或者子串定位)
- 应用:文本编辑、程序调试、搜索引擎、生命科学
- 蛮力算法
- 说明:每次移动一个字母,并且逐个字母匹配
- 时间复杂度:O(n*m)
- 优点:直观,实现起来很简单
- 缺点:算法效率过低,只适用于解决小规模问题
- KMP算法
- 说明:自左向右匹配,匹配过程中,出现不匹配情况,应尽量向右移动最大距离,避免重复。
- KMP算法需要进行预处理,逐个位置求出部分匹配串
- 时间复杂度:O(m+n)
- Boyer-Moore算法
- 基础:Horspool算法
- 预处理:Last-Occurenceh函数,记录每个字母在模式串中出现的最后的位置
- 时间复杂度:最坏情况下O(n*m+s);恒定数目匹配O(n)
- 基本概念
- 树的定义: 由n个结点(node)组成的有限集合。其中有一个根结点(root node),只有直接后继,没有直接前驱。
- 结点:
结点:数据元素,并且指向树的分支结点的度:结点的子树个数(分支结点度不为0,叶子结点度为0)树的度:树中结点的度的最大值。若最大值为k.则该树为k叉树孩子(child)结点:某个结点A的子树的根结点为B,则B为A的子结点,A为B的双亲(parent)结点或者父结点兄弟(sibling)结点:具有相同双亲结点的结点堂兄弟(cousin):某结点的不同子树的根结点的孩子结点祖先(ancestor):从根节点到某个结点A的路径上的所有结点称为结点A的祖先,某结点中所有子树的结点称为该结点的子孙(descendant)
- 树的基本术语:
- 结点的层次:根结点层次为1,第i层结点的子树的根结点的层次为i+1
- 树的深度(高度):树中叶子结点所在的最大层次
- 树的一些性质
- 树中结点数目等于所有结点的度数和加1
- 度为k的树中,第i层上至多有k^(i-1)个结点
- 深度为h的k叉树至多有(k^h - 1)/(k - 1)个结点
- 具有n个结点的k叉树的最小深度为log_k(n*(k-1)+1)
- 二叉树:k = 2时的k叉树
- 二叉树的表示
- 空间占用:
- k层二叉树需要2^k-1个存储单元。
- 空间效率:不完全二叉树,结点越少,空间效率越低、
- 二叉树的链式表示:
- 数据域和指针域(两个指针分别指向左子树和右子树)
- 空间占用:
- 二叉树的遍历
- 定义:按照某种次序访问树中的结点,每个结点访问一次且仅访问一次
- 遍历次序:
- 先序(根结点-左-右)
- 中序(左-根结点-右)
- 后序(左-右-根结点)
- 层序(从低到高逐层遍历,每层从左往右)
- 二叉搜索树
- 二叉树的表示
- Huffman(霍夫曼)树
- 基本概念:
- 分支:两结点之间的"线段"部分
- 路径:结点到结点的分支
- 带权路径:对分支加权的路径
- 路径长度:路径上的分支数
- 结点的(加权)路径长度:从根结点到该结点的路径上的(带权)路径长度
- 树的(加权)路径长度:从根结点到所有叶子结点的(带权)路径长度之和
- 霍夫曼树
- 定义:所有路径长度相同的二叉树中,带权路径长度最小的树,也称为最优二叉树。
- 特点:权值大的结点离根结点更近。
- 霍夫曼树的构造
- 霍夫曼编码
- 平均编码长度较短的编码方案具有更好的性能
- 变长编码:出现概率大的字符,编码短一些;概率小的编码长
- 霍夫曼编码:构造霍夫曼树,是一种最优编码
- 缺点:
- 霍夫曼码会有错误传播,无法查错和纠错
- 需要精确获得文本字符出现的概率
- 基本概念:
- 与普通队列的区别: 不再遵从FIFO原则,而是每次从队列中取出具有最高优先权(优先级)的队列
- 优先级队列的应用场景:
- 线程优先级
- 斯诺克台球
- 银行贵宾卡服务
- Windows消息队列
- 个人事务处理
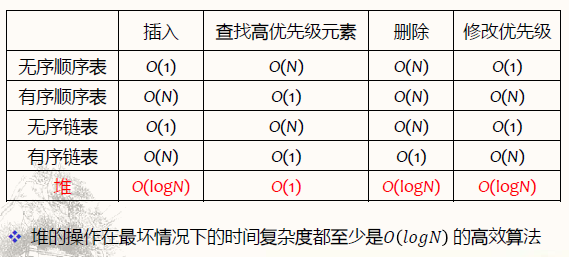
- 优先级队列的实现方式及时间复杂度分析
- 基于无序顺序表
- 插入:O(1)
- 取出最高优先级元素:O(N)
- 删除整个队列:O(N)
- 改变某个元素优先级:O(1)
- 基于有序顺序表
- 插入:O(N)
- 取出最高优先级元素:O(1)
- 删除整个队列:O(N)
- 改变某个元素优先级:O(N)
- 基于无序链表
- 插入:O(1)
- 取出最高优先级元素:O(N)
- 删除整个队列:O(N)
- 改变某个元素优先级:O(1)
- 基于无序链表
- 插入:O(N)
- 取出最高优先级元素:O(1)
- 删除整个队列:O(1)
- 改变某个元素优先级:O(N)
- 基于堆
- 基于无序顺序表
- 堆
- 定义:满足堆性质的完全二叉树
- 分类:
- 最大堆:父结点值较大,堆顶结点值最大
- 最小值:父结点值较小,堆顶结点值最小
- 存储方式: 顺序存储于一维数组
- 堆的高度:堆顶结点的高度
- 堆的操作
- 插入(堆的建立) 新结点加入到堆尾,自底向上堆化(自顶向下的堆构造),时间复杂度小于O(NlogN) 自底向上的堆构造:O(n),线性复杂度
- 删除: 将堆顶结点删除,将堆尾结点放到堆顶,通过自顶向下堆化修复
- 堆的修复: 以最大堆为例: 结点大于父结点:自底向上 结点小于子结点:自顶向下
- 时间复杂度:自底向上、自顶向下都是O(h)
- 空间复杂度:堆化操作都是本地操作,基本不需要辅助空间
- 堆与优先级队列
- 堆是实现优先级队列的主要数据结构之一
- 时间复杂度分析
- 插入操作:O(logN)
- 删除操作:O(logN)
- 取最高优先级:O(1)
- 修改元素优先级:O(logN)
- 结论:堆是一种高效算法
-
图的相关术语:
- 顶点
- 边(弧)
- 邻接顶点
- 有向图/无向图
- 有向完全图:任意顶点到另外任意一顶点都有边
- 无向完全图:任意两顶点间都存在边
- 稀疏图/稠密图
- 子图
- 有向图中顶点的入度与出度
- 有向图顶点的度等于入度和出度之和
- 有向图所有顶点入度之和等于出度之和
- 握手定理:图中所有顶点的度之和等于边数之和的两倍;入度之和等于出度之和等于边数之和
- 奇点:度为奇数的点;偶点:读为偶数的点
- 任意图一定有偶数个奇点
- 网络:边带权的图
- 路径:
- 简单路径:路径序列中没有重复出现的顶点
- 回路/环:路径的起点和终点相同(其余顶点不同的回路称为简单回路)
- 连通:存在路径;连通图
- 无向图的极大连通子图称为连通分量
- 有向图:强连通图,强连通分量
- 欧拉路径:遍历图中每条边且每条边只访问一次
- 欧拉回路:终点回到起点
- 图有欧拉回路的充要条件:图是连通的,且每个点的度都是偶数
- 图有欧拉路径的充要条件:图是连通的,且只有两个顶点的度是奇数
-
图的存储和表示
- 邻接矩阵:
- 存储空间:定点数的平方
- 时间复杂度:
- 边插入、删除、判断是否存在都是O(1)
- 邻接表:采用链表数组表示图
- 链表头结点为图的顶点
- 有向图的邻接表需要(边数+顶点数)个链表结点
- 无向图的邻接表需要(2×边数+顶点数)个链表结点
- 时间复杂度:
- 边插入:O(1)
- 边删除、判断是否存在:O(顶点数)

- 稠密图适合邻接矩阵
- 稀疏图适合邻接表
- 邻接矩阵:
-
图的遍历:
- 定义:沿着边访问图中每个顶点且每个顶点只被访问一次
- 深度优先遍历DFS:
- 递归实现
- 用于寻找图中从顶点v到顶点w的简单路径
- 广度优先遍历BFS:
- 分层搜索过程,不能递归实现
- 用于寻找图中从顶点v到顶点w的最短路径
-
最小生成树MST:
- 生成树:包含图中n个顶点,但只有n-1条边
- Prim算法:
- 把图分为两部分,MST和非MST,每次向MST加入一个结点和一条边
- 时间复杂度:O(顶点数的平方)
- 适用于稠密图
- Kruskal算法:
- 所有边按权值排序
- 时间复杂度:O(边数×log边数)
- 适用于稀疏图
-
最短路径:
- 最短路径树SPT:根到其他顶点的最短路径
- 源点-汇点最短路径:两个确定顶点之间的最短路径
- 单源最短路径:给定起始顶点,到其他顶点的最短路径
- Dijkstra算法:O(顶点数的平方)
- 全源最短路径:各对定点间的最短路径
- Floyd算法:O(顶点数的立方)
- 允许图中带负权值的边,但不允许带负权值边组成的回路

-
查找一般基于查询关键字和数据项关键字比较
- 复杂性取决于关键字和数据的规模
- 基于关键字比较的时间复杂度为O(logN)~O(N)
-
查找算法的分类:
- 内部查找、外部查找
- 静态查找、动态查找
-
查找算法的性能评价指标:
- 平均查找次数:查找过程中进行关键字比较次数的期望值
-
顺序查找算法:
- 顺序查找/线性查找:
- 从线性表一端开始,依次比较
- 对于长度为N的线性表,查找时平均比较次数为N/2
- 折半查找:
- 要求:顺序表有序
- 算法:
- 可用一个二叉树来描述
- 二叉树深度是折半查找需要比较的次数
- 折半查找需要比较的次数不超过floor(log_{2}^{N}) + 1
- 顺序查找/线性查找:
-
索引查找算法
- 将n个结点的线性表划分为m个子表,分别存储子表
- 划分原则:具有相同性质的结点归并到同一子表中
- 最终m个子表结点结合在一起,能构成原表的全部结点
- 四种索引存储方式
- 顺序索引-顺序存储
- 优点:索引查找比全局顺序查找效率高
- 顺序索引-链接存储
- 优点:结构简单,便于查找;子表结点的插入删除不需要移动表中元素
- 链接索引-顺序存储
- 链接索引-链接存储
- 顺序索引-顺序存储
- 索引表的特点:
- 表不大
- 表的元素不常变动
- 多重索引:当索引表很大时,对索引表再做索引
- 分块查找--索引顺序查找,顺序查找的改进
- 将线性表分成很多块
- 后一块的元素大于前一块的所有元素
- 某一块内的元素是无序的
- 单关键字索引文件结构:
- 索引文件:具有索引存储结构的文件
- 索引表:知识逻辑记录与物理地址关系的表
- 索引表的每一表项称为索引项
- 索引项按各记录关键字有序排列
- 稠密索引:索引项与主文件记录一一对应
- 稀疏索引:索引项与主文件部分记录对应
- 索引文件的好处:
- 减少外存访问次数
- 提高查找速度
- 索引查找表:对索引表建立索引
- 多关键字索引文件结构:
- 适用于多关键字查询
- 缺点:记录的插入和删除不方便
- 倒排文件
- 优点:多关键字查询时,通过集合运算即可
- 缺点:倒排表索引项长度不同,文件管理维护相对困难
- 将n个结点的线性表划分为m个子表,分别存储子表
-
二叉搜索树BST(重要的动态搜索结构)
- 一棵二叉搜索树代表了一个经过排序的关键字序列
- 具有如下性质的二叉树:
- 每个结点有一个关键字
- 任意结点的关键字不小于该结点左子树所有结点的关键字
- 任意结点的关键字不大于该结点右子树所有结点的关键字
- 二叉搜索树的旋转操作:
- 结点和结点的一个子孙互换角色,仍保持结点关键字的次序
- 左旋转:涉及结点和结点的右孩子
- 右旋转:涉及结点和结点的左孩子
- 特点:
- 插入操作和查找、排序操作同样简单
- 删除操作比较复杂,需要适当的修补操作
- 性能:算法运行时间由树的形状决定
- 平均情况下而二叉搜索树的平衡性还是相当好的
- 最好情况下:对数运行时间
- 最坏情况下:N次比较
- 平均情况下:2lnN次比较
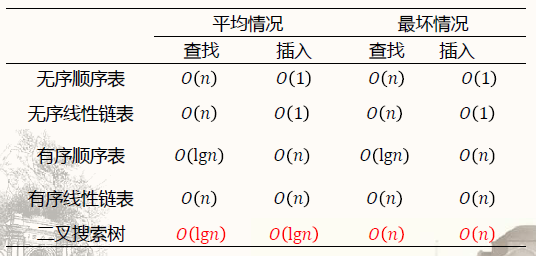
- 不同查找表的效率比较:
- 补充:
- AVL树:高度平衡的二叉搜索树
- 红黑树:实用的平衡二叉搜索树
- B-树:多路平衡的动态查找结构
-
散列:在存储量和查找时间之间寻找平衡
- 直接将关键字作为存储地址
- 核心问题:关键字和存储地址如何对应
- 解决方法:散列函数:将关键字集合映射到某个地址集合
- 散列表:将关键字映射到有限的、地址连续的区间
- 理想情况:不同关键字映射到不同的地址
- 非理想情况:多个关键字映射到同一地址,即为冲突现象
- 散列技术处理:散列函数和冲突调节
- 散列函数:
- 散列函数构造的原则:
- 简单
- 定义域包含全部关键码
- 近似为随机,对每个输入,输出在值域上等概
- 常用的散列函数类型:
- 乘法散列
- 模散列
- 平方取中法
- 折叠法:移位法、分界法
- 散列函数构造的原则:
- 冲突处理:
- 链地址法:
- 适用于元素数目大于表长
- 将散列到同一地址的不同关键字存入相应链表
- 开放定址法
- 适用于表长大于元素数目
- 依靠空的存储空间解决冲突问题
- 删除时不能直接对元素进行删除,而是给被删的关键字加上标志留在散列表
- 性能:依赖于负载因子=元素数目/表长。
- 链地址法:
- 双重散列:
- 元素数目过多,产生元素聚合现象
- 采用第二个散列函数,用于探测序列:
- 不能出现散列值为0
- 散列值必须与表长互素
- 散列技术比较

- 决定散列表查找性能的因素:
- 散列函数
- 冲突处理的方法
- 散列表饱和程度:负载因子
- 散列技术的应用
- 字符串匹配:Karp-Rabin
- 搜索引擎:URL散列
- 信息安全的内容鉴别:MD5、SHA算法
- 散列技术的优点:
- 实现简单
- 提供常数时间查找性能
- 散列技术的缺点:
- 散列函数不易找到
- 动态性能不好
- 最坏情况查找性能不好
- 忽略逻辑关系,不利于排序
- 直接将关键字作为存储地址
-
分类:
- 内排序:在排序期间数据对象全部存放在内存的排序
- 外排序:在排序期间全部对象个数太多,不能同时存放在内存,必须根据排序过程的要求,不断在内、外存之间移动
-
排序算法性能评估:
- 排序的时间开销
- 算法执行的附加存储
-
简单排序算法:
- 冒泡排序
- 插入排序
- 直接插入排序
- 折半插入排序
- 希尔排序:缩小增量排序
-
快速排序:
- 快速排序和冒泡排序都属于交换类排序
- 可以递归实现
- 不稳定算法
-
归并排序:
- 将多个有序表合并成新的有序表
- 自底向上归并排序:O(nlogn)
- 自顶向下归并排序:递归实现
- 稳定算法
-
堆排序:
- 自底向上堆化
- 自顶向下堆化
- 不稳定算法
- 堆排序不需要额外空间,是原地操作
-
排序算法的下界: O(𝑁𝑙𝑜𝑔𝑁)是一般情况下排序算法可期待的最好的时间复杂度
-
重要的总结表格
- 排序算法比较
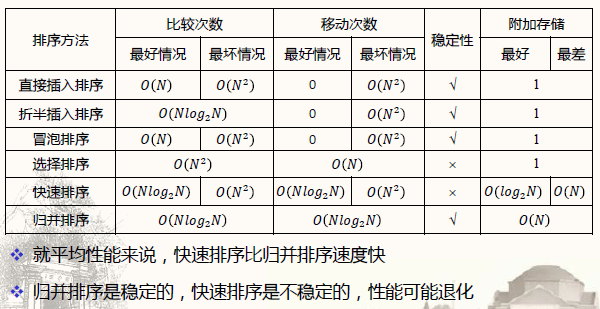
- 总结:归并排序:既快速,又稳定
- 数值分析研究范围:
- 线性方程组
- 非线性方程
- 拟合与插值
- 最优化问题
- 数值问题的特性:
- 适定问题:解唯一存在,且连续地依赖于问题数据
- 不适定问题:问题的微小变化引起不连续变化
- 适定问题中对输入数据很敏感的问题称为病态问题
- 病态是问题的特性,与算法无关
- 数值问题的误差分析:
- 总误差=计算误差+传播误差
- 算法只能影响计算误差,对传播误差没有影响
- 计算误差=截断误差+舍入误差
- 截断误差:无穷级数截断等
- 舍入误差:精度有限
- 前向误差:y值之差
- 后向误差:x值之差
- 敏感性和病态性:
- 指标:
- 相对条件数=|相对前向误差|/|相对后向误差|
- 绝对条件数=|前向误差|/|后向误差|
- 条件数不大于1,问题不敏感,是良态的
- 条件数远大于1,问题是敏感、病态的
- 函数与其反函数的条件数互为倒数
- 函数求值和方程的求解敏感性是相反(不一定相同)
- 指标:
- 算法的稳定性与精确性:
- 稳定性:算法对于计算中的微小扰动不敏感
- 精确性:问题的计算解与真实解的近似程度
- 结论:良态问题+稳定算法→精确解
- 计算机运算:
- 计算机浮点数系统由4个整数描述:
- 基数
- 精度
- 指数范围(两个整数表示区间)
- 正规化:除非表示0,尾数的首位不为0
- 任何浮点数表示方法唯一
- 最大程度利用有限的位数
- 次正规化:指数域达到最小值时,允许尾数首位不为0
- 当一个浮点数不能在系统中表示时,对浮点数进行舍入:
- 截断:向零舍入
- 最近舍入:取与x最接近的系统能够表示的浮点数
- 最近舍入时机器的精度是截断舍入的一半
- 计算机浮点数系统由4个整数描述:
-
范数:
- 向量范数
- 矩阵范数
- 1范数:各列向量求和后的最大值
- 无穷范数:各行向量求和后的最大值
- 矩阵的条件数:cond(A) = ||A||||A^-1||
- 矩阵的条件数刻画了矩阵对于非零矢量最大的伸展和压缩能力
- 矩阵条件数越大,越接近奇异
-
线性方程组直接解法:
- 形式:Ax=b
- 高斯消去法:
- 主要计算量在消元,时间复杂度n的3次方
- 列选主元,增加了计算复杂度,但是能够提高算法稳定性
- LU分解
- 高斯约当法:将矩阵A变化为对角阵,使得求解更简单
- 高斯约当法比高斯消去法的计算复杂度高
- 乔列斯基分解
- A是对称正定阵,A=LL^T
- 对称线上元素都是正的平方根,算法是良态的
- 对称正定阵,只需存储下三角部分
- 总结:直接解法运算量大,不适合高维线性方程组
-
线性方程组的迭代解法:
- 不动点

- 雅克比

-
高斯-塞德

- 高斯-赛德方法能够及时利用更新过的分量参与下一步计算,因此收敛速度要比雅可比大约快一倍
-
最速下降法
-
共轭梯度法
-
解的存在性和唯一性
- 非线性方程的近似解的表述:

- 具有重根的问题是病态的
-
非线性方程求解的方法
- 二分法:
- 收敛速度是线性的:每步迭代增长的有效数字是常数
- 迭代次数与函数具体形式无关,只取决于初始区间长度和收敛门限
- 优点:安全;缺点:效率比较低
- 不动点迭代法
- 收敛速度是超线性的:每步迭代的有效数字个数的增加是递增的
- 牛顿法
- 需要对非线性函数求导
- 平方收敛
- 收敛速度快,迭代过程有时出现震荡的情况
- 对于多重根情况,迭代收敛速度退化为线性
- 割线法:准牛顿法
- 利用前两次的迭代值决定一条直线,用这条直线与𝑥轴的交点作为一下次的迭代值
- 不对非线性函数求导,而是近似代替导数
- 收敛速度不如牛顿法,超线性r=1.618
- 反插
- 与割线法不同,通过高阶的多项式拟合来提高收敛速度
- 二次拟合,称为反二次插值
- 收敛速度超线性,r=1.839
- 综合利用两类方法:
- 二分法+反二次插值
- 二分法:较小的有根区间外
- 反二次插值:区间内
- 二分法:
-
拟合
- 超定方程与欠定方程
- 最小二乘法
- 正规方程法:Cholesky分解
- 可能导致敏感性的恶化
- QR分解
- Household变化
- 正规方程法与QR分解比较

-
插值
- 目的:
- 已有某些离散点,求过这些点的光滑曲线
- 使函数精确地通过给定数据点
- 函数形式:
- 多项式
- 分段多项式
- 三角函数
- 指数函数
- 系数矩阵:范德蒙矩阵
- 单项式基底插值:
- 采用单项式基底的多项式插值,单项式基底的数目越大,借书越高,系数矩阵的病态性也随之增加
- 给定点越多的插值问题,病态程度越高
- 拉格朗日插值:
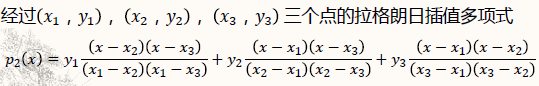
- 牛顿插值:

- 目的:
- 最优化问题
- 定义:在等式约束/不等式约束下,对目标问题求最优解(函数的最大最小值)
- 线性规划/非线性规划
- 凸优化问题:目标函数和约束集合都是凸的
- 无约束优化
- 黑塞矩阵:二阶偏导矩阵
- 黑塞矩阵判断临界点的性质:
- 正定,最小值
- 负定,最大值
- 不定,鞍点
- 奇异,病态
- 接近奇异,敏感问题
- 判断正定:特征值都是正,凑你再唯一乔列斯基分解,顺序主子式行列式均为0
- 等式约束优化
- 拉格朗日函数
- 拉格朗日乘子法:将等式约束优化问题转为无约束优化问题
- 单峰函数
- 黄金分割搜索
- 收敛速度是线性的,在速度上没有优势
- 每次迭代只更新一个点
- 逐次抛物插值
- 取两端点和近似极值点,进行抛物插值(二次多项式)进行拟合
- 将拟合函数的最小值点作为近似极值点
- 重复过程直至收敛
- 超线性收敛,r=1.324
- 保护法:采用混合方案,黄金分割搜索和逐次抛物插值混用,避免求函数的导数
- 最速下降法:
- 收敛是线性的
- 初值选择很重要
- 牛顿法:
- 平方收敛
- 不需要搜索参数
- 只有选择的初始值与最优解很近时,牛顿法才是收敛的
- 拟牛顿法:
- 包含:割线修正法、共轭梯度法
- 目的:提高牛顿法可靠性,降低复杂度
- 保持超线性收敛速度,明显降低迭代成本,更稳健
- 拟合问题
- 拟合问题同样是最优化问题
- 优化目标函数是:代价函数
-
随机算法:对于输入运行过程随机,运行结果也随机
- Sherwood算法:消除算法性能和输入数据的联系
- 快速排序
- 二叉搜索树:加入随机化步骤,有效避免性能恶化
- Las Vegas算法:算法求解中引入随机性决策
- 大整数因子分解问题:Pollard Rho算法
- 可通过多次调用Las Vegas算法增加问题解的概率
- Monte Carlo算法:
- 模拟积分:大量重复性实验,用频率估计概率
- 主元素问题、素数判定问题
- 矩阵乘积验证,随机生成矢量
- 三种随机方法比较
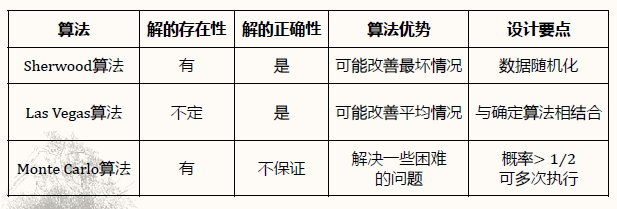
- Sherwood算法:消除算法性能和输入数据的联系
-
蛮力法:不采用技巧直接解决问题,思路直接、实现简单,适用于规模小的问题
- 蛮力字符串匹配:O(m×n)
- 求两个整数最大公因子
- 百元买百鸡
- 分治法:实例分解成若干较小规模的实例,分别解决再将解合并
- 分治递推式
- 分治法并不能总是改进时间复杂度(例:对序列求和)
- FFT是DFT的分治法体现
- 快速排序
- 大整数乘法:以增加算法为代价,减少乘法
- Strassen矩阵乘法
- 寻找最近的点对
- 减治法:将问题转化为规模较小的问题
- 折半查找
- 选择排序
- 辗转相除法
- 非线性方程二分法
- 变治法:将困难问题转换为有已知解法的问题
- 高斯消去法
- LU分解
- 小结:
- 分治法减少问题规模
- 减治法和分治法的思想相近
- 最优化问题回顾
- 组成:目标函数、约束条件、可行解、最优解
- 汉诺塔问题:递归/非递归算法
- 全排列问题
- 八皇后问题
- 穷举查找:遍历整棵状态空间树,复杂度为指数量级
- 回溯法:搜索解时如果当前的部分解是没有希望的,则可以停止对后续分支的搜索(已知出错的立刻放弃)
- 分支界限法:
- 一种:最佳优先分支边界
- 最佳值边界确定对各分支的扩展和遍历的顺序,以及确定最优解
- 旅行商问题
- 总结:回溯法和分支界限法为大规模的组合难题求解提供了可能性,但是不能保证求解的效率
- 货币找零钱问题:
- 目前的货币方案,贪心法均适用
- 7+5+1货币不能用贪心算法
- 贪心算法适用性:
- 贪心选择性质:通过一系列局部最优选择可以得到问题全局最优解的问题
- 贪心算法优缺点:
- 优点:实现简单,复杂度低
- 缺点:
- 不是所有优化问题都可使用贪心算法
- 不一定能够得到全局最优解
- 往往包含多种不同的贪心策略,得到不同解
- 贪心算法举例:
- Prim算法求最小生成树
- Kruskal算法求最小生成树
- Dijkstra算法求单源最短路径
- Huffman树和Huffman编码
- 最速下降法:负梯度方向是下降速度最快的方向
- 基本概念(三个基本要素):
- 阶段:动态规划将问题分成的若干个有顺序的环节
- 状态:将某一阶段的出发位置称为状态
- 决策:从某阶段的一个状态演变为另一个状态
- 两个条件
- 最优子结构(最优化原理):
- 将原问题转换成规模更小的问题时,原问题最优的充要条件是:当且仅当子问题最优
- 无后效性:
- 过去的步骤只能通过当前状态影响未来发展
- 最优子结构(最优化原理):
- 问题举例:
- 背包问题:在背包总重量固定时,选择合适的物品使物品总价值最大
- 典型算法举例:
- Floyd算法求全源最短路径
- Viterbi算法解卷积码
- 适用范围:
- 求解多阶段决策过程
- 重叠子问题
- 输入增强技术
- KMP算法实现字符串匹配
- 模式串、主串
- 预处理函数Next
- 字符串移动步数只与模式串有关,与目标串无关
- Horspool算法实现字符串匹配
- 反向比较
- 预处理函数Last-Occurrence
- 算法复杂度:最坏情况下O(n×m+s),s为字符表规模
- 最坏情况出现在数字图像信号或者DNA序列中
- Boyer-Moore算法:坏字符+好后缀
- 计数排序
- KMP算法实现字符串匹配
- 预构造技术
- 二叉搜索树:重要的动态查找结构
- 将待查找数据预先构造成为二叉搜索树
- 倒排索引:
- 通过精心预构造建立索引,使在海量数据中获取信息成为可能
- 并查集:
- Kruskal算法中可以采用基于数组的并查结构
- 图中环和回路的判断
- 堆和堆排序:
-
最大堆:任意结点值小于父结点的值
-
最小堆:任意结点值大于父结点的值
-
建立堆:向空堆中插入元素,同时调整堆
- 不断向堆尾插入新结点+自底向上堆化 = 自顶向下的堆构造:O(nlogn)
- 自顶向下堆化→自底向上的堆构造:线性复杂度
-
堆的修复:以最大堆为例,h为堆的高度
- 结点值小于子结点:自顶向下堆化,时间复杂度O(h)
- 结点值大于父结点:自底向上堆化,时间复杂度O(h)
-
堆是实现优先级队列的主要结构之一
- 优先级队列实现方法的比较
-
堆排序:
- 自底向上构造堆的时间复杂度为O(N)
- 堆元素的删除操作最坏情况下时间复杂度为O(lgN)
- 堆排序对N个元素排序最坏情况下的时间复杂度为O(NlogN)
-
- 二叉搜索树:重要的动态查找结构
- 时空平衡
- 比特逆序
- 散列:依靠存储空间的冗余解决冲突,实现更高的查找效率
- 算法的组合
- 插入排序改进快速排序
- 问题分类:
- 判定问题:对一个问题回答是或者否,相对容易
- 优化问题:找到最优解或者满意解
- 判定问题和优化问题有时可以互换:图着色、背包问题
- 一些优化问题不能转为判定问题:全排列
- 不是所有的判定问题都可以求解
- 停机问题:判断程序对于某个输入是否能够中止
- 停机问题不可判定
- 理发师悖论
- 哥德尔不完备定理
- P和NP问题:
- P问题:能在多项式时间内求解的判定问题
- NP问题:求解问题是困难的,但验证某个待定解是否是问题的可行解却是简单的;被称为是非确定性的,如果验证可以在多项式时间内解决,就被称为非确定性多项式(NP)问题
- 八皇后问题
- 汉密尔顿回路
- 旅行商问题
- 背包问题
- 学术定义:
- 存在确定的多项式界的算法的问题称为P问题
- 存在不确定的多项式界的算法的问题称为NP问题
- 争议问题:
- P =/≠ NP。能够在多项式时间内验证候选解的正确性的问题,是不是一定存在多项式时间的求解方法
- NPC问题:NP完全问题
- 最难的NP问题
- NP难问题
- 结论:NP问题+NP难问题 ==> NP完全问题