Support baselines #1149
Comments
|
That's interesting! I've never seen this before. I think we could support it? I'd been hoping that One point of confusion for me w/r/t the baseline file is that if it's just storing errors + line numbers, then if you edit a file (e.g., add a function to the top of a file that has some ignored errors), doesn't the baseline get invalidated? Since all the errors are pushed to new lines? |
|
I would recommend looking into what My experience with this system is very positive. I would definitely recommend it over adding a bunch of noqa comments everywhere, because now it becomes unclear what purposefully got a FYI, Happy to answer any questions on the topic (and linters in general 😁) |
That means it can't flag an issue being moved around, or code being rewritten but reintroducing the exact same issue it removed, right? (though I guess as developers learn about the new pattern they would hopefully stop introducing them entirely, and thus the odds of this occuring would diminish over time, so from a cost/benefit point of view it seems like a rather nice heuristic). Although what happens if a new issue is detected, does elm-review just output all the issues of the file? It can differentiate if it's a completely novel issue but if it's an additional occurrence of an existing issue it can't distinguish them can it? |
Correct. Though it can flag an issue if it's moved around from one file to another, just not in the same file. Also, As you say, you can basically swap one error in one file for another. While it's not necessarily always true (but generally is), this is fine as long as the severity of all the problems reported by a rule are the same, because you're not making the code necessarily worse, you're keeping it as it was before. And this is the worst scenario with this system, which IMO is a pretty good tradeoff considering the pros and cons of alternative solutions. As for the "moving" part, I think it's not a good thing to do things based on the line number. For instance, if I'm working on a file and adding a new function on line 100, then run the linter that tells me I now need to fix a suppressed/baseline error that was on line 500 (but is now on line 520), then that gives a very poor experience. The advice you'll likely get will be "oh you didn't touch it, so just suppress the error once again", which leads to a common habit of suppressing errors (and I mean that in a bad way).
Exactly, it outputs all the issues of the file for that specific rule. This is what the output looks like (focus on the orange parts in this example): |
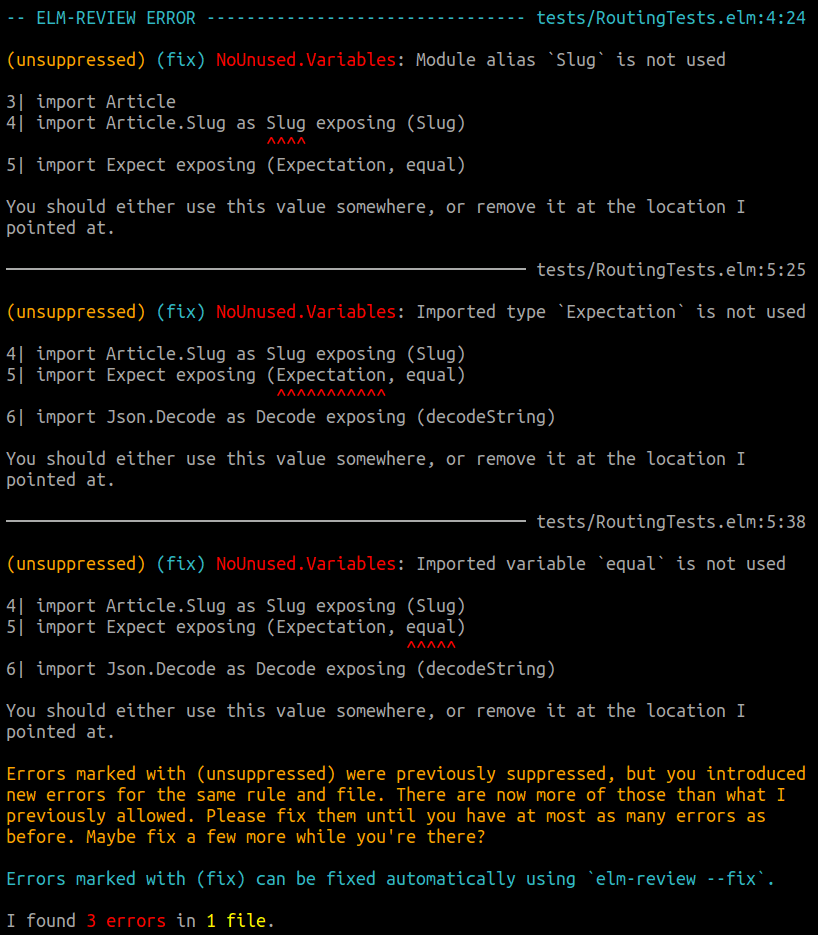
Oh I agree with that, you'd need to either store the sequence of issues which would still have false positives (when the relative ordering of different issue-types doesn't change), or you'd need the diff information in order to adjust the line numbers which would be a lot more work, hence my mention of cost/benefit in the original comment.
Makes sense, thanks for the explanations. |
|
For more information on this, I opened a similar issue in ESLint very recently: eslint/eslint#16755 Another prior art is
Reasons why I didn't go for some of these (that system is older than what
|
This should be quite easy to resolve using standard shell tools though e.g. will display the name of every file followed by its content, or maybe if intermediate subdirectories get added ( Of course it depends what you want specifically in terms of overview. But maybe ruff could support both styles by accepting both baseline file and baseline directory in which case it'd merge all the JSON files? |
|
This is an example of a I find that neither the file structure neither the file's contents are easy to get an overview. Here, I don't have to run any tool, know any bash-fu, or even leave GitHub to see what's happening. In this last example, I can clearly see which rules have been suppressed, and then I can look at those files to see how many suppressed errors there are. If I review a GitHub PR, it is easy to see whether new rules are being suppressed or more errors are being suppressed, which allows me to leave a comment asking my colleague whether this was necessary, and start a conversation. We ideally want those numbers to go down, not up, so talking it out is a healthy practice IMO. With
I don't think that having more choices for these things is beneficial in general, as that will make it harder to maintain things, confuse the users and split the community in how you do things. And you might end up with the worst of both worlds instead of the best of both worlds.
Can you clarify what you have in mind with baseline file and baseline directory? |
Right but that could just be that a location-based toplevel is the wrong approach.
Both have advantages and drawbacks though, and justifiably so. It's also not exactly rare, both Elm and Rust will let you split a single module file into a module directory after all.
Exactly that? For instance in your elm example each check has a JSON file with any number of entries, hence every two PRs which add or remove occurrences in the same category might conflict (even more so because of JSON's trailing-comma issues). However each check could be a directory then containing a file for each suppression
That can be done either way, a diff (whether The ember diffs will be noisier because it has additional and possibly (probably?) unnecessary metadata (especially as it seems to update them somewhat randomly) but a diff will still tell you clearly that (check, file) entries get added or removed: dfreeman/ember-truncate@b466413 |
|
I'm new to I'm definitely not an expert in the mechanism used to generate the baseline file, but just wanted to toss in some lived experience with this functionality. I believe it is similar to what others have called out above, in that it's tied to the filename and the line numbers, so we do occasionally see instances where very old legacy code is touched and multiple "unrelated" issues then pop up. However, in general, even on a code base with some fairly large legacy files (7k lines of Django serializers), it's usually not so bad to get things fixed up. This incrementally modernizes and even fixes our existing code, which is great. |
|
One possible implementation of baselines that would handle many of the issues herein (though it would introduce at least one of its own) would be to incorporate the baseline into the file itself with the For example, a file that contains an existing line of: could get a directive such as: In my view it has the following advantages:
Of course, it also has one distinct disadvantage:
This could be mitigated by providing an obvious separate author credit on this (commit the output of |
|
I also have a baseline implementation for mypy as a separate tool: mypy-baseline. As people already said in the thread, baseline doesn't store line numbers. In case of mypy-baseline, violations are matched to the baseline based on the file name and error message: In the case of flakehell (now flakeheaven) things were a bit easier because I could use error codes (since error messages may change): In case of a new violation being similar to the old one (the same file and the same error code), simply the last one is reported based on assumption that the new code is more often added closer to the end of the file. It may produce false-positives in theory but my teams haven't faced it yet. I think it was a good decision to keep baselines in a separate file. I also considered automatically adding
What I regret doing in flakehell is that the baseline is a collection of obscure md5 hashes. In mypy-baseline, the baseline is human-readable and we quite often use that fact to manually read and edit it. I hope this perspective can be of any help. |
flakeheaven stores md5 hash of the violation and it's context. If performance is a concern a cheaper hash should be fine too. The |
|
Hi, I wholeheartedly support the implementation of a separate baseline file as it proves to be an immensely valuable feature. Given the context of my position as the head of the department in a company with a substantial monolithic codebase, I am actively striving to enforce robust code standards. To achieve this, I have introduced linters during the code push to the repository and have provided the team with suitable tools. However, due to the sheer size of the codebase, it is not feasible to lint the entirety of it. Therefore, my objective is to exclusively lint the new code changes—the actual differences in the codebase as it progresses forward. Flakeheaven or flakehell do a great job doing this baseline, I wish ruff could bring something similar. |
|
Hello, A structured output for ruff violations with fingerprints has been added for gitlab output. |
|
Darker is a very relevant tool here (which isn't just for black). And for prior art, basedmypy and Qodana both support baseline functionality. |
|
Here's a bit of jq -nr --argfile ref gl-code-quality-report-baseline.json \
--argfile new gl-code-quality-report.json '
# Get fingerprints in new report that are not in the old.
[ $ref, $new ]
| map([.[].fingerprint])
| (.[1] - .[0]) as $new_fingerprints
# Take the new report and select only the entries with a new fingerprint.
| $new
| .[] | select(.fingerprint | IN($new_fingerprints[]))
| "- \(.description) - `\(.location.path):\(.location.lines.begin)`"
'I've added this in one of our GitLab projects while waiting for this issue to be resolved. Here's the merge request workflow.
|
|
You can use flakeheaven and flakehell are not supported because they rely on internal flake8 API, which can lead to compatibility issues as flake8 evolves. In contrast, ondivi uses only the text output of violations and the state of Git repository, making it more robust and easier to maintain.
WPS remove this page from the docs and replace it with https://wemake-python-styleguide.readthedocs.io/en/latest/pages/usage/integrations/ondivi.html |
Baselines would allow developers to introduce Ruff to their codebase incrementally by ignoring existing errors and address them as they reappear when making changes to the code.
Supported by some tools in the flake8 ecosystem:
A very basic proposal for this in ruff:
In the CLI
In pyproject.toml
The text was updated successfully, but these errors were encountered: