Documentation for the callbacks on the CBLAS-like API #15
Comments
|
Hi @fommil, |
|
@kknox a little example of how to call the BLAS functions wouldn't go amiss. the equivalent cuBLAS functions are much more closely aligned with the original BLAS API in comparison... although it is rather frustrating that neither library actually implements the BLAS that decades of middleware has conformed to. Hence my wrapper layer. |
|
you don't have an explicit dgemm example, but the C examples you pointed me at were useful. it looks to me like you're still some way from users being able to call you as BLAS. Ill attempt to wrap DDOT and DGEMM over the coming months, but I'll pause at that point to see where to go. |
|
Hi @fommil We recognize that the clBLAS API is slightly different than as defined with traditional NetLib BLAS; we did not break the BLAS API lightly or arbitrarily. The concerns for designing for heterogeneous platforms like modern GPU platforms necessitate different decisions than were made 30 years ago for homogeneous platforms like traditional CPU servers. There is a heavy cost in transferring data to and from the heterogeneous device (i.e. the GPU over the PCI express bus) and if data is managed carelessly, the performance will actually be worse than not having offloaded the computation in the first place. Our API, built on top of OpenCL, allows our clients to manage their own data. They control when and where data is transferred to and from the heterogeneous device. This is the reason that we added the extra OpenCL parameters to the BLAS API's; the user manages the OpenCL state and passes it into the library which ultimately generates OpenCL kernels and enqueues them into the command queue. With this API, the client controls when data is transferred to the device, executes a series of BLAS calls (or user defined kernels) while the data remains on the device and then transfers data back to the Host only when they are done processing. Otherwise, you get in a situation where data is transferred in a round-trip fashion to the device and back on every BLAS call, and then find yourself in the uncomfortable situation where you are better off not having offloaded to the device in the first place 😃 |
|
@kknox can you please take a look at this? It's a translation of your sgemm sample. https://github.com/fommil/netlib-java/blob/master/perf/src/main/c/clwrapper.c When I run my test file https://github.com/fommil/netlib-java/blob/master/perf/src/main/c/dgemmtest.c (compilation instructions at the top) I see this :-( I'm on OS X. Note that I changed the |
|
for completeness, I thought I would note that my Macbook Air doesn't seem to support OpenCL on the GPU :-( http://forums.macrumors.com/showthread.php?t=1119312 |
|
Apple will provide OpenCL 1.2 support on the integrated Iris graphics of Haswell-based MBA's in Mavericks when that's released soon. Sounds like you'll be justified in treating yourself to a new laptop! ;-) http://forums.macrumors.com/showthread.php?t=1620203 http://docs.huihoo.com/apple/wwdc/2013/session_508__working_with_opencl.pdf Simon On 11 Sep 2013, at 15:49, Sam Halliday notifications@github.com wrote:
Head of Microelectronics Group and University of Bristol Business Fellow |
|
@simonmcs heh, nah... I've got a relatively new iMac that I'll use for GPU performance tests. And clBLAS needs to work without segfaults before I can rationalise a frivolous upgrade :-P |
|
I don't understand what you are trying to do here To use clBLAS all you need to do is make offsets 0 and pass the other parameters as is. You are making it more complicated than it is worth. The segmentation fault is likely occurring because you are using yoru CPU as your OpenCL device and the wrapper code you have written is trying to access elements that are out of bounds. |
|
@pavanky I am copying the code from the example. I don't understand why the offsets are +1! I thought it was some device specific nonsenses. |
|
The example has the following line. Since you want matrix multiplication on the entire matrix, try setting offsets to 0 for your case. Use M, N, K, LDA, LDB, LDC directly. |
|
oh, I missed that bit :-D now, why would a gemm example not do gemm? |
|
@fommil it is doing gemm, but only on the bottom right corner of the buffers. The equivalent in standard gemm would've used something like This kind of an API is necessary for OpenCL because such offsets to pointers are not possible from the host side. But such offsets are required for some libraries that are downstream from BLAS (such as various LAPACK implementations). |
|
@pavanky I'm still getting the segfault with no offsets. Actually, this happened last night too and that's why I added all the offsets (I thought it was some hocus pocus and didn't see the note about sub matrices). |
|
I get the segfaults when on a GPU device as well. I won't be able to test this again until next weekend. |
|
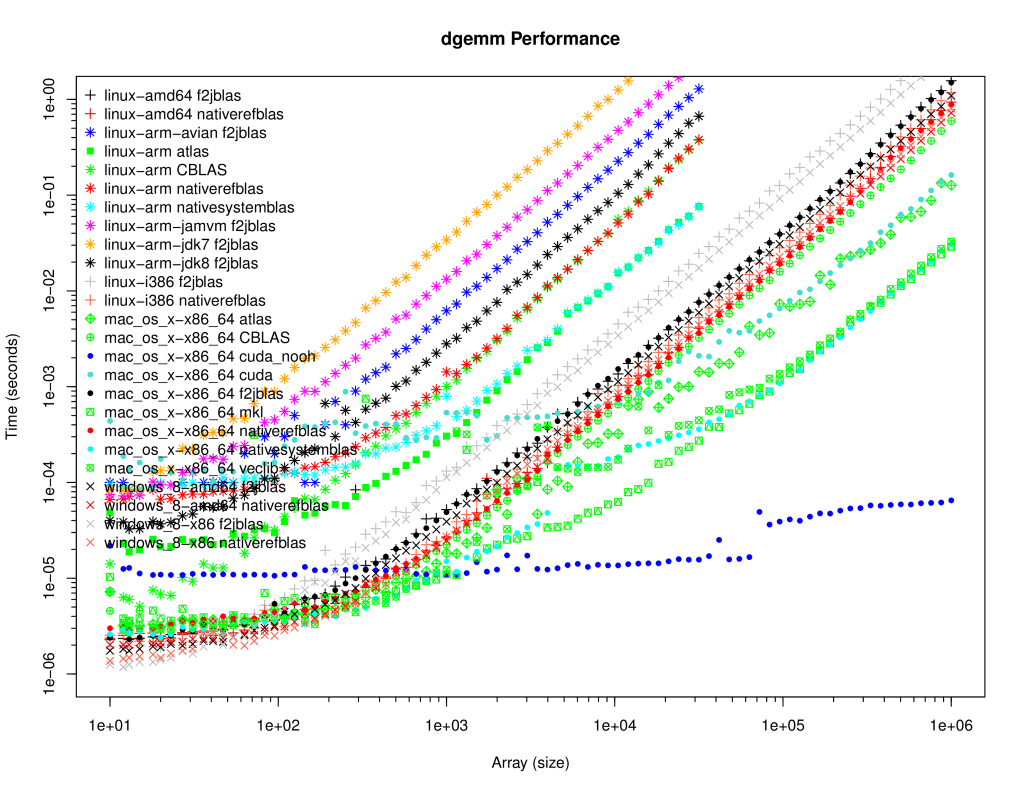
@kknox @pavanky I'm still unable to get results with clBLAS but I've been able to run some DGEMM tests with CUDA to confirm your comments about the memory overhead. Indeed, it is pretty spectacular. Turquoise (light blue below the red lines, keep pace with the green ATLAS) is CUDA + overhead, dark blue is CUDA just the dgemm call (and I checked that it is computing the result correctly!) |
|
Closing old clBLAS issues for the new year I believe that this question has been answered, in part here and in part with the comments in #12. |
I just got clBLAS compiling on OS X (see #7) and did a very simple DGEMM test, see https://github.com/fommil/netlib-java/
The results are, frankly, a little unbelievable... so I'm going to have to check that the DGEMM is actually being performed.
However, as part of the setup I found it very hard to understand the
clblasDgemmAPI. It looks like you've added offsets to the arrays (which doesn't make much sense in C, since this can be done by just moving the pointer) and also added the followingI just set these to
NULLor0as appropriate: https://github.com/fommil/netlib-java/blob/master/perf/src/main/c/clwrapper.cWhat are these for and what are sensible defaults just to get me up and running?
The text was updated successfully, but these errors were encountered: