安装了3.9或更高版本的Python就可以运行本书的所有代码。
有的人电脑已经安装了Python,如何查看安装的Python的版本?
开始——运行——powershell——python
可以看到,下图Python版本为3.11.2
- 安装Python注意勾选“Add Python 3.11 to PATH”
编辑完,请注意保存代码。可以选择在VSCode的File菜单中勾选自动保存。
什么是终端?
终端我们可以简单理解为命令行工具,即非图形化的,比如Windows的CMD,PowerShell,苹果系统的Terminal,Linux系统的Bash Shell等。
进入PowerShell
cd ~\desktop\python_work
python hello_world.py.\hello_workld.py 和 hello_world.py对此场景没有区别,.\表示当前目录下,也就是python_work目录下。
注意,比较下面使用引号的区别:
print("Hello World")message = "Hello World"
print(message)如果打印的是文字,文字包含在引号中;
如果打印的是变量所代表的的文字,变量没有包含在引号中。
关于变量名命名规范,实际上,如果是不规范的,VSCode会有红色波浪线的提示(如下截图),如果强行运行,报错如下:

name = "ada lovelace"
print(name.title())
上面是书中的范例代码,如果不太好理解print(name.title())
可以试着理解下面的代码:
name = "ada lovelace" #原始的字符串
name = name.title() #处理字符串
print(name) #打印处理后的字符串lower()方法很有用。把数据全部转换成小写保存,用的时候根据需要再转换为首字母大写或全大写。
f 字符串,有的地方会看到叫f-string,string翻译过来也是字符串。非常常用和重要的。
制表符(\t)通常就是按tab键的效果。
" python" 和 "python"是不同的,前面的python的p前面有一个空格,要对空格敏感,对计算机而言,空也是一种东西,虽然,对人而言,看上去好像空是不存在的。
# 练习2.3
name = "Eric"
msg = f"Hello {name}, would you like to learn some Python today?"
print(msg)
# 练习2.4
print("=======================================")
print(name.lower())
print(name.upper())
print(name.capitalize())
# 练习2.5
print("=======================================")
print('Albert Einstein once said, "A person who never made a mistake never tried anything new."')
# 练习2.6
print("=======================================")
famous_person = "Albert Einstein"
msg2 = f'{famous_person} once said, "A person who never made a mistake never tried anything new."'
print(msg2)
# 练习2.7
print("=======================================")
name2 = " Mumu \t Wu \n "
name3 = "Mumu \t Wu"
print(name2.strip())
print(name2.lstrip())
print(name2.rstrip())
print(len(name2.strip()))
print(len(name3.strip()))
# 练习2.8
print("=======================================")
filename = "python_notes.txt"
print(filename.removesuffix(".txt"))练习2.7,为了验证删除空白的效果,我创建了name3作为对照,len()函数用于获取结果的长度,发现长度是一致的,所以,对于删除空白,name3的内容等价于name2删除空白后的结果。

任意两个数相除,结果总是浮点数,即使这两个数是整数且能整除。
程序中变量是允许再次被赋值的,不能再赋值的变量称为常量,Python中没有内置的常量类型,以全大写字母当做常量。
其他语言,比如JavaScript是有变量常量的:
let a = 1 //用let表明a是一个变量
const b = 2 //用const表明b是一个常量在VSCode中,Ctrl + /可以将光标所在行快速的注释和取消注释。
输入exit()可以退出Python终端。

# 练习 2.9
print(4 + 4)
print(2 * 4)
print(10-2)
print(64/8)
# 练习 2.10
favourite_number = 3
msg = f"my favourite number is {favourite_number}" #拼字符串
print(msg)# 练习 3.1
names = ["张三", "李四", "王五"]
print(names[0])
print(names[1])
print(names[2])
# 练习 3.2
print(f"你好,{names[0]}")
print(f"你好,{names[1]}")
print(f"你好,{names[2]}")
# 练习 3.3
methods = ["开车", "骑车"]
print(f'通常,我都是{methods[0]}上班,偶尔,为了锻炼身体也会{methods[1]}去上班。(我信你个鬼')
## 注意中英文标点符号
# 英文标点:'' "" , .
# 中文标点:‘’ “” , 。从此刻开始,请注意,中英文标点符号在VSCode中的不同,对于包裹字符串用的引号是英文的。

列表中某个特定元素的修改,也就是对这个特定索引重新赋值。
对于删除列表中的元素,如果不使用删除后的内容,使用del语句,如果还使用删除后的内容,用pop()方法。
remove()只删除第一个指定的元素,如果要全部删除需要用循环遍历,以后会学到。
# 练习 3.4
invitees = ["张三", "李四", "王五"]
print(f'{invitees[0]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[1]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[2]}您好,诚挚地邀请您一起参加晚餐。')
# 练习 3.5
# 张三不能参加
print(f"{invitees[0]}不能参加晚宴。")
invitees[0] = "赵四"
print(f'{invitees[0]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[1]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[2]}您好,诚挚地邀请您一起参加晚餐。')
# 练习 3.6
print("大家好,我找到了一张更大的餐桌,将邀请更多的人参加晚餐。")
invitees.insert(0, "新1")
invitees.insert(2, "新2")
invitees.append("新3")
print(invitees)
print(f'{invitees[0]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[1]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[2]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[3]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[4]}您好,诚挚地邀请您一起参加晚餐。')
print(f'{invitees[5]}您好,诚挚地邀请您一起参加晚餐。')
# 练习 3.7
print("因为新买的餐桌无法送达,因此这次只能邀请两位朋友参加完餐,十分抱歉。")
target = invitees.pop()
print(f'很抱歉,{target},没有办法邀请您参加晚宴了。')
target = invitees.pop()
print(f'很抱歉,{target},没有办法邀请您参加晚宴了。')
target = invitees.pop()
print(f'很抱歉,{target},没有办法邀请您参加晚宴了。')
target = invitees.pop()
print(f'很抱歉,{target},没有办法邀请您参加晚宴了。')
print(f'{invitees[0]},请您参加晚宴。')
print(f'{invitees[1]},请您参加晚宴。')
del invitees[1]
del invitees[0]
print(invitees)关于使用del语句删除的顺序的问题,请大家比较下面的区别:
del invitees[1]
del invitees[0]
del invitees[0]
del invitees[1]
del invitees[0]
del invitees[0]向sort()方法传递一个参数,第一次使用参数。
cars = ['audi','bmw','subaru','toyota']
cars.sort(reverse=True)True在这里可以理解为reverse这个参数的开关,=也就是设定,设定为True,表示该选项打开。
注意比较下面的区别:
cars.sort() #method
sorted(cars) #functioncars是列表,sort()是列表这种东西身上的方法,所以使用的方式是cars.sort()
sorted()是一个函数,具备特定的功能,对cars执行特定的功能,比如print(),也可以执行特定的功能。
感受这种区别。
len()其实在我前面的笔记中已经提到过了,也可以用于获取字符串的长度,比如hello有5个字符:
>>> len("hello") #length
5未来,学习了if判断,可以判断列表的长度是否为0,避免空列表索引错误。
>>> len([])
0# 练习 3.8
locations = ["Japan","Korea","France","Germany","Canada","Australia"]
print(locations) #打印列表
print(sorted(locations)) #不改变原列表按字母排序
print(locations)
print(sorted(locations,reverse=True)) #不改变原列表按字母反向排序
print(locations)
locations.reverse() #改变原列表逆转列表元素
print(locations)
locations.reverse() #改变原列表再逆转回来
print(locations)
locations.sort() #改变原列表按字母顺序排序
print(locations)
locations.sort(reverse=True) #改变原列表按字母顺序反向排序
print(locations)
# 练习 3.9
#我就直接打印练习3.8的列表长度了
print(len(locations))
# 练习 3.10
list = ["Japan","黄河","北京","德语","北京","bmw"]
print(list)
print(len(list))
list.pop()
print(list)
list.append("hi")
print(list)
list.insert(0,'mumu')
print(list)
list.remove("北京")
print(list)
del list[2]
print(list)
list.sort()
print(list)
list.reverse()
print(list)
# 练习 3.11
print(list[9])sorted()使用reverse参数的参考:

概括一下:对于for里面的内容,要向右缩进,如果跟for的代码是左边是上下对齐的,就是for之外的代码,或者说是跟for平级的代码。
属于for循环的内容的内容,要向右缩进
提示一下:for的第一行结尾需要英文的冒号:
File "c:\Users\vwumumu\Desktop\python_work\4.1-4.2.py", line 5
for pizza in pizzas
^
SyntaxError: expected ':'# 练习 4.1
pizzas = ["Margherita", "Pepperoni", "Hawaiian"]
for pizza in pizzas:
print(pizza)
print(f"I like {pizza} pizza.")
print("I really love pizza!")
# 练习 4.2
animals = ["lion", 'tiger', 'cougar']
for animal in animals:
print(f"{animal} can roar loudly")
print('All these animals can roar loudly.')range(1,6)的结果是数字1,2,3,4,5,即括号内的范围是含左不含右的。
列表推导式,新人不掌握也没关系,但是需要知道,避免看到别人的代码不认识。
# 练习 4.3
for i in range(1,21):
print(i)
# 练习 4.4
list = range(1,1_000_001)
# for i in list:
# print(i)
# 练习 4.5
print(min(list))
print(max(list))
print(sum(list))
# 练习 4.6
odd = range(1,21,2)
for i in odd:
print(i)
# 练习 4.7
three_times = range(3,31,3)
for i in three_times:
print(i)
# 练习 4.8
cube = []
list2 = range(1,11)
for i in list2:
cube.append(i ** 3)
print(cube)
# 练习 4.9
cube = [i ** 3 for i in range(1,11)]
print(cube)cube = []
for i in range(1,11):
cube.append(i ** 3)
print(cube)
# cube = [i ** 3 for i in range(1,11)]# 练习 4.10
three_times = list(range(3,31,3))
# for i in three_times:
# print(i)
print(f"The first three items in the list are: {three_times[0:3]}")
print(f"Three items from the middle of the list are: {three_times[4:7]}")
print(f"The last three items in the list are: {three_times[-3:]}")
# 练习 4.11
pizzas = ["Margherita", "Pepperoni", "Hawaiian"]
friend_pizzas = pizzas[:]
friend_pizzas.append("榴莲披萨")
for pizza in pizzas:
print(f"I like {pizza} pizza.")
for pizza in friend_pizzas:
print(f"I like {pizza} pizza.")
# 练习 4.12
#同练习4.11不可变的列表称为元组(tuple)。
不能修改元组中的元素,但是可以对元组的变量重新赋值一个新元组,这本质上是赋值,跟元组本身并没有什么关系。
# 练习 4.13
foods = ("苹果", "香蕉", "西瓜", "草莓", "橙子")
for food in foods:
print(food)
# foods[0] = "榴莲"
foods = ("苹果", "榴莲", "葡萄", "草莓", "橙子")
for food in foods:
print(food)通过VSCode实现代码的格式化
-
如下图,在VSCode中安装Python插件:

-
在任意Python代码文件的代码区域右键选择
Format Document With...
-
设置默认的格式化Python代码所使用的插件

-
选择Python作为默认:

-
之后,在VSCode代码区右键选择
Format Document或者同时按键盘Shift + Alt + F自动格式化Python代码:
对于新手,可能会比较难判断什么情况下执行if代码块的内容。
尤其是涉及到and, or的情况,因为需要判断的内容可能会比较多和复杂。
一个简化的方式是直接把需要判断的内容print出来看看是True还是False,如果结果是True,就会执行if代码块内的代码。
比如:
age_0 = 22
age_1 = 18
if age_0 >= 21 and age_1 >= 21:
print("Hi")
print(age_0 >=21 and age_1 >=21)把age_0 >=21 and age_1 >=21打印出来,结果是False,自然if不会执行,无法打印Hi。
# 练习 5.1
print("1" == 1)
print("a" == "A")
print("?" == "?")
print(1 > 2 and 3>2)
print(2 > 1 and 3>2)
print(1 > 2 or 3>2)
print(2 > 1 or 3>2)
print("Mumu" in ["Mumu","Zhang San"])
print("mumu" in ["Mumu".lower(),"Zhang San"])
print("Mumu" not in ["Mumu","Zhang San"])
# 练习 5.2
#同练习5.1注意,if elif,从上向下,当有一个elif满足时,后面的条件将不再判断。
如果需要把所有的条件都判断,需要写成一个个独立的if。
多体会5.3.6披萨的例子。
# 练习 5.3
alien_color = "green"
if alien_color == "green":
print("获得5分")
alien_color2 = "red"
if alien_color2 == "green":
print("获得5分")
# 练习 5.4
if alien_color == "green":
print("获得5分")
elif alien_color != "green":
print("获得10分")
if alien_color2 == "green":
print("获得5分")
elif alien_color2 != "green":
print("获得10分")
# 练习 5.5
if alien_color == "green":
print("获得5分")
elif alien_color == "yellow":
print("获得10分")
else:
print("获得15分")
# 练习 5.6
age = 18
if age < 2:
print("婴儿")
elif age < 4:
print("幼儿")
elif age < 13:
print("儿童")
elif age < 18:
print("少年")
elif age < 65:
print("中青年人")
else:
print("老年人")
# 练习 5.7
favorite_fruits= ["apple","orange","banana"]
if "a" in favorite_fruits:
print("You really like a")
if "b" in favorite_fruits:
print("You really like a")
if "c" in favorite_fruits:
print("You really like a")
if "apple" in favorite_fruits:
print("You really like apple")
if "banana" in favorite_fruits:
print("You really like banana")如何验证空列表是False?
>>> a = []
>>> a == False
False
>>> a == True
False
>>> type(a)
<class 'list'>
>>> type(False)
<class 'bool'>
>>> bool(a) == False
True同类型的值才可以比较,比如1和“1”不相等。
问题?如何验证[1] == False的结果?
# 练习 5.8
users = ["admin","a","b","c","d"]
for user in users:
if user == "admin":
print("admin")
else:
print("user")
# 练习 5.9
if users:
for user in users:
if user == "admin":
print("admin")
else:
print("user")
else:
print("We need to find some users!")
# 练习 5.10
current_users = []
for i in users:
current_users.append(i.lower())
new_users = ["c","d","e","f","g"]
for user in new_users:
if user in current_users:
print("The user name has been used. Please using another one.")
else:
print("The user name is avaliable.")
# 练习 5.11
list = list(range(1,10))
for i in list:
if i == 1:
print("1st")
elif i == 2:
print("2nd")
elif i == 3:
print("3rd")
else:
print(f"{i}th")同4.6
# 练习 6.1
person = {"firstname": "mumu", "lastname": "wu", "age": 18, "city": 'beijing'}
print(person["firstname"])
print(person["lastname"])
print(person["age"])
print(person["city"])
# 练习 6.2
db = {"a": 1, "b": 2, "c": 3, "d": 4, "e": 5}
print(f'a like {db["a"]}')
print(f'b like {db["b"]}')
print(f'c like {db["c"]}')
print(f'd like {db["d"]}')
print(f'e like {db["e"]}')
# 练习 6.3
db2 = {"string": "一串文字", "int": "整数",
"float": "小数", "list": "列表", "tuple": "元组"}
print(f'string: {db2["string"]}')
print(f'int: {db2["int"]}')
print(f'float: {db2["float"]}')
print(f'list: {db2["list"]}')
print(f'tuple: {db2["tuple"]}')python提供很多方法,既可以遍历字典的所有键值对,也可以只遍历键或者值。
.items()是字典的所有元素;
.key()是字典的键;
.value()是字典的值。
# 练习 6.4
db2 = {"string": "一串文字", "int": "整数",
"float": "小数,浮点数", "list": "列表", "tuple": "元组", "set": "集合", "boolean": "布尔值,Ture和False"}
for k, v in db2.items():
print(k, ":", v)
# 练习 6.5
rivers = {"尼罗河": "埃塞俄比亚,苏丹,埃及,乌干达,坦桑尼亚,肯尼亚,卢旺达,布隆迪,摩洛哥,刚果和南苏丹",
"亚马逊和": "巴西,玻利维亚,秘鲁,厄瓜多尔,哥伦比亚,委内瑞拉,圭亚那,苏里南和法属圭亚那", "Danube": "德国,奥地利,斯洛伐克,匈牙利,克罗地亚,塞尔维亚,罗马尼亚,保加利亚,摩尔多瓦和乌克兰"}
for k, v in rivers.items():
print(f"The {k} runs through {v}.")
print("\n河流的名字:")
for k in rivers.keys():
print(k)
print("\n国家的名字:")
for v in rivers.values():
print(v)
# 练习 6.6
favorite_languages = {
"jen": "python",
"sarah": "c",
"edward": "rust",
"phil": "python",
}
people = ["jen","edward","mumu"]
for p in people:
if p in favorite_languages.keys():
print(f"Hi {p.title()}, thanks for take the survey.")
else:
print(f"Hi {p.title()}, could you please help to complate the survey?")嵌套就是字典里面套字典,列表里面套字典。
字典数组,[{},{}]
# 练习 6.7
person1 = {"firstname": "mumu", "lastname": "wu", "age": 18, "city": 'beijing'}
person2 = {"firstname": "san", "lastname": "zhang",
"age": 19, "city": 'shanghai'}
person3 = {"firstname": "si", "lastname": "li", "age": 20, "city": 'guangzhou'}
list = [person1, person2, person3]
for i in list:
print(i)
# 练习 6.8
pets = {"amao": {"category": "cat", "owner": "zhangsan"},
"agou": {"category": "dog", "owner": "lisi"}}
for k,v in pets.items():
print(k,v)
# 练习 6.9
#类似6.8
# 练习 6.10
#类似编程语言的题目:
favorite_languages = {
"jen": ["python", "rust"],
"sarah": ["c"]
}
for name, language in favorite_languages.items():
if(len(language) == 1):
print(f"{name}'s favorite langue is:")
for i in language:
print(i)
else:
print(f"{name}'s favorite langue are:")
for i in language:
print(i)
# 练习 6.11
#重复练习,跳过
# 练习 6.12
#参考练习6.10,结合了if对遍历内容做判断。7.1.1中的示例使用了+=,还记得这是什么吗?
+=就是先+然后再=(赋值),比如下面两行代码是等价的:
a += b
a = a + binput()函数得到的结果会转换为字符串,即使输入的是数字。
求模运算符(%),取余数。
# 练习 7.1
car = input("请问您想要租什么车?")
print(f"让我查询一下是否有{car}") #f-string
# 练习 7.2
customers = int(input("请问您有几位用餐?"))
if customers > 8:
print("很抱歉,已经没有空位了。")
else:
print("可以的,欢迎就餐。")
# 练习 7.3
number = int(input("请输入一个数字"))
if number % 10 == 0:
print("这个数字是10的整数倍。")
else:
print("这个数字不是10的整数倍。")continue是继续的意思,往往容易让人误解,实际上是break+continue,结束本次循环,然后继续后面的循环。
# 练习 7.4
active = True
while active:
a = input("请输入您需要添加的披萨配料:")
if a != "quit":
print(f"将在披萨中添加{a}")
else:
active = False
# 练习 7.5
while True:
age = int(input("请问您的年龄是?"))
if age < 3:
print("免费")
elif age < 12:
print("10元")
else:
print("15元")
# 练习 7.6
while True:
a = input("请输入您需要添加的披萨配料:")
if a != "quit":
print(f"将在披萨中添加{a}")
else:
break
# 练习 7.7
while True:
print("按Ctrl + C,或者关闭窗口结束无限循环。")for循环是一种遍历列表的有效方式,但不应该在for循环中修改列表,否则将导致Python难以跟踪其中的元素。要在遍历列表的同时修改它,可使用while循环。通过将while循环与列表和字典结合起来使用,可收集、存储并组织大量的输入,供以后查看和使用。
来自GPT4: 这句话是关于Python编程的一条建议。for循环在Python中通常用于遍历序列类型的数据,如列表或字符串。然而,在for循环中直接修改列表可能会导致迭代过程混乱,因为程序可能会错过一些元素或者重复处理某些元素。
下面给你一个例子。假设我们有一个列表,并想在遍历中将列表中的所有偶数删除。
numbers = [1, 2, 3, 4, 5, 6] for number in numbers: if number % 2 == 0: numbers.remove(number) print(numbers)这段代码可能无法正确地删除所有偶数。原因是在每次删除元素后,列表的长度都会减少,而for循环还在按原计划进行,这可能会导致索引错误或跳过一些元素。
为了解决这个问题,我们可以使用while循环来修改列表:
numbers = [1, 2, 3, 4, 5, 6] while i < len(numbers): if numbers[i] % 2 == 0: numbers.remove(numbers[i]) else: i += 1 print(numbers)这段代码会正确地删除所有偶数,因为while循环每次运行都会检查列表的长度,以及当前处理的元素的索引位置。
至于将while循环与列表和字典结合起来使用,目的是在接收大量输入的同时存储和组织这些输入。这种做法常用于建立一些需要用户输入并需要保存输入记录的程序。
# 练习 7.8
sandwich_orders = ["a", "pastrami", "b", "pastrami", "c", "pastrami"]
finished_sandwiches = []
for i in sandwich_orders:
print(f"I made your {i}")
finished_sandwiches.append(i)
print(finished_sandwiches)
# 练习 7.9
print("pastrami have sold out.")
sandwich_orders2 = ["a", "pastrami", "b", "pastrami", "c", "pastrami"]
finished_sandwiches2 = []
while "pastrami" in sandwich_orders2:
sandwich_orders2.remove("pastrami")
finished_sandwiches2 = sandwich_orders2[:] #实现列表的copy
print(finished_sandwiches2)
# 练习7.10
while True:
target = input("If you could visit one place in the world, where would you go?")
print(target)关于形参实参,如果不好记什么是形参,我们可以记住实参,即调用一个函数时实际要提供的参数。
比如例子:greet_user("mumu"),mumu是实际上要提供给函数greet_user()的,所以mumu在这里是实参(实际的参数),那greet_user(username)的username就是形参。
比如,张三,张是姓,三是名,姓,名就是形参,实际的姓和名,就是形参姓和名的实参,张和三。
位置实参,也就是说,在提供给函数的参数的顺序,位置,决定了这个参数值是对应到哪个参数的变量。
关键字实参,将参数值指定给某个具体的参数变量。
建议把包含默认值的形参放到函数的后面,这样实参还可以按照位置顺序指定给没有默认值的形参。
# 练习 8.1
def display_message():
print("function")
display_message()
# 练习 8.2
def favorite_book(title):
print(f"One of my favorite books is {title}")
favorite_book("Alice in Wonderland.")
# 练习 8.3
def make_shirt(size, text):
print(f"shirt size is {size}, and text: {text} on it")
make_shirt(1, "hi")
make_shirt(text="hello", size=2)
# 练习 8.4
def make_shirt2(size="Big", text="I love Python"):
print(f"shirt size is {size}, and text: {text} on it")
make_shirt2()
make_shirt2("Middle")
make_shirt2("Small", "Coding")
# 练习 8.5
def describe_city(city, country="China"):
print(f"{city} is in {country}")
describe_city("Beijing")
describe_city("Shanghai", "China")
describe_city("Tokyo", "Japan")请认真阅读,理解8.3.2,如何让实参变成可选的:指定默认值为空字符串,移到形参列表的末尾,在函数体内对空值进行判断,实现实参可选。
# 练习 8.6
def city_country(city, country):
return f"{city.title()}, {country.title()}"
print(city_country("beijing", "china"))
print(city_country("shanghai", "china"))
print(city_country("guangzhou", "china"))
# 练习 8.7
def make_album(singer, album, songs=None):
if songs == None:
return {singer.title(): {"Album": album.title()}}
else:
return {singer.title(): {"Album": album.title(), "Songs": songs}}
print(make_album("zhoujielun", "a"))
print(make_album("zhoujielun", "b"))
print(make_album("zhoujielun", "c", 12))
# 练习 8.8
while True:
singer = input("请提供歌手名:(输入q退出程序)")
if singer == "q":
break
album = input("请提供专辑名:(输入q退出程序)")
if album == "q":
break
print(make_album(singer, album))每个函数都应该只负责一项具体工作。
# 练习 8.9
list = ["a", "b", "c"]
def show_messages(list):
for i in list:
print(i)
show_messages(list)
# 练习 8.10
list2 = []
def send_messages(list,list2):
for i in list:
list2.append(i)
send_messages(list,list2)
print(list)
print(list2)
# 练习 8.11
send_messages(list[:],list2) #如果移除用pop()实现,可以保留原list传递任意数量的参数就是把这些实参作为形参的元素,构成一个元组,然后在函数内部,可以操纵这个元组。
注意8.5.1和8.5.2的不同,一个星号*是任意实参为元组,两个星号*是任意实参为字典。
你经常会看到通用形参名*args,收集任意数量的位置实参。
你经常会看到通用形参名**kwargs,收集任意数量的关键字实参。
# 练习 8.12
def sandwich(*args):
print("用户的三明治添加了下面的食材:")
for i in args:
print(i)
sandwich("a", "b", "c")
# 练习 8.13
#就是替换一下函数的值为自己的信息,忽略。
# 练习 8.14
def make_car(made,model,**kwargs):
kwargs["made"]=made
kwargs["model"]=model
return kwargs
car = make_car("subaru","outback",color="blue",two_package=True)
print(car)# 导入所有函数
import module_name
# 导入特定函数
from module_name import function_0, function_1
导入所有函数使用函数:module_name.function_name()
导入特定函数使用函数:无需使用module_name + . 直接使用函数即可。
给形参指定默认值,等号两边不要有空格。
所有的import都应该放在文件的开头,除了描述整个程序的注释。
# 练习 8.15
#没找到printing_models.py
import printing_models
# 练习 8.16
#将练习8.12-8.14命名为sandwich.py,然后:
import sandwich
from sandwich import sandwich
from sandwich import sandwich as san
import sandwich as san
from sandwich import *
# 练习 8.17
#跳过比较重要的术语:根据类来创建对象成为实例化,这让你能够使用类的实例。
创建类就是找到共性,可以把类理解成是一种事物的模板,给这个模板提供具体的参数,就是通过模板创建具体的事物,就是通过类实例化对象。
比如,狗,就是一类事物,这类事物有很多具体的实例,比如不同品种的狗狗,不同毛色的狗狗,但是他们都有品种,毛色这些属性,class Dog就是模板,包含这些共有属性和能做的事情(方法)。
首字母大写的名称指的是类。
书中提到,因为这是我们创建的全新的类,所以定义时不加括号。加括号的类是指从别的类继承而来的类,其中括号里面是父类名。9.3会讲到。
需要注意__init__的前后两个横线都是两个短下划线,即总共4个短下划线。
def __init__(self)是固定套路。
以self为前缀的变量可供类中的所有方法使用。
# 练习9.1
class Restaurant:
def __init__(self, restaurant_name, cuisine_type):
self.name = restaurant_name
self.cuisine_type = cuisine_type
def describe_restaurant(self):
print(self.name, self.cuisine_type)
def open_restaurant(self):
print("The restaurant is open!")
restaurant = Restaurant("Burger King", "American")
print(restaurant.name)
print(restaurant.cuisine_type)
restaurant.describe_restaurant()
restaurant.open_restaurant()
# 练习9.2
restaurant1 = Restaurant("a", "American")
restaurant2 = Restaurant("b", "China")
restaurant3 = Restaurant("c", "Japan")
restaurant1.describe_restaurant()
restaurant2.describe_restaurant()
restaurant3.describe_restaurant()
# 练习9.3
class User:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
def describe_user(self):
print(self.first_name, self.last_name)
def greet_user(self):
print("Hello", self.first_name, self.last_name)
user1 = User("John", "Doe")
user1.describe_user()
user1.greet_user()
user2 = User("Jane", "Smith")
user2.describe_user()
user2.greet_user()小白新手要是对self产生疑问,先忽略更好,掌握写class的“套路”即可。回头有了更多的经验,再研究。
# 练习9.4
class Restaurant:
def __init__(self, restaurant_name, cuisine_type):
self.name = restaurant_name
self.cuisine_type = cuisine_type
self.number_served = 0
def describe_restaurant(self):
print(self.name, self.cuisine_type, self.number_served)
def open_restaurant(self):
print("The restaurant is open!")
def set_number_served(self, number_served):
self.number_served = number_served
def increment_number_served(self):
number_served = input(
"How many people can this restaurant served every day do you think it? ")
self.number_served += int(number_served)
restaurant = Restaurant("Burger King", "Italian")
restaurant.describe_restaurant()
restaurant.set_number_served(5)
restaurant.describe_restaurant()
restaurant.increment_number_served()
restaurant.describe_restaurant()
# 练习9.5
class User:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
self.login_attempts = 0
def describe_user(self):
print(self.first_name, self.last_name, self.login_attempts)
def greet_user(self):
print("Hello", self.first_name, self.last_name)
def increment_login_attempts(self):
self.login_attempts += 1
def reset_login_attempts(self):
self.login_attempts = 0
user = User("John", "Doe")
user.describe_user()
user.increment_login_attempts()
user.increment_login_attempts()
user.increment_login_attempts()
user.describe_user()
user.reset_login_attempts()
user.describe_user()在创建子类时,父类必须包含在当前文件中,且位于子类前面。
父类也成为超类。
# 练习9.6
# class Restaurant is copy from 练习 9.4
class Restaurant:
def __init__(self, restaurant_name, cuisine_type):
self.name = restaurant_name
self.cuisine_type = cuisine_type
self.number_served = 0
def describe_restaurant(self):
print(self.name, self.cuisine_type, self.number_served)
def open_restaurant(self):
print("The restaurant is open!")
def set_number_served(self, number_served):
self.number_served = number_served
def increment_number_served(self):
number_served = input(
"How many people can this restaurant served every day do you think it? ")
self.number_served += int(number_served)
class IceCreamStand(Restaurant):
def __init__(self, restaurant_name, cuisine_type):
super().__init__(restaurant_name, cuisine_type)
self.flavors = ["vanilla", "chocolate", "strawberry"]
def get_ice_cream_flavor(self):
print(f"We have {len(self.flavors)} flavors of ice cream.")
for flavor in self.flavors:
print(flavor)
ice_cream = IceCreamStand("Ice Cream Stand", "Dessert")
ice_cream.get_ice_cream_flavor()
# 练习9.7
# class User is copy from 练习 9.5
class User:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
self.login_attempts = 0
def describe_user(self):
print(self.first_name, self.last_name, self.login_attempts)
def greet_user(self):
print("Hello", self.first_name, self.last_name)
def increment_login_attempts(self):
self.login_attempts += 1
def reset_login_attempts(self):
self.login_attempts = 0
class Admin(User):
def __init__(self, first_name, last_name):
super().__init__(first_name, last_name)
self.priviledges = ["can add post", "can delete post", "can ban user"]
def show_priviledges(self):
print("You have the following priviledges:")
for privilege in self.priviledges:
print(privilege)
admin = Admin("admin", "admin")
admin.show_priviledges()
# 练习9.8
class Admin2(User):
def __init__(self, first_name, last_name):
super().__init__(first_name, last_name)
self.priviledges = Priviledges()
class Priviledges():
def __init__(self):
self.priviledges = ["can add post", "can delete post", "can ban user"]
def show_priviledges(self):
print("You have the following priviledges:")
for priviledge in self.priviledges:
print(priviledge)
admin2 = Admin2("mumu", "wu")
admin2.priviledges.show_priviledges()
# 练习9.9
# 从网上抄了个基础,然后改了改
class Car:
"""一次模拟汽车的简单尝试。"""
def __init__(self, make, model, year):
"""初始化描述汽车的属性。"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性信息。"""
long_name = f"{self.year} {self.make} {self.model}"
return long_name.title()
def read_odometer(self):
"""打印一条指出汽车里程的消息。"""
print(f"The car has covered {self.odometer_reading} miles.")
def update_odometer(self, mileage):
"""将里程表读数设置为指定的值。
禁止将里程表读数往回调。
"""
if mileage >= self.odometer_reading:
self.odometer_reading = mileage
else:
print("You can't roll back an odometer.")
def increment_odometer(self, miles):
"""将里程读数增加指定的值。"""
self.odometer_reading += miles
class Battery:
"""一次模拟电动汽车电瓶的简单尝试。"""
def __init__(self, battery_size=75):
"""初始化电瓶的属性。"""
self.battery_size = battery_size
def describe_battery(self):
"""打印一条描述电瓶容量的消息。"""
print(f"The car has a {self.battery_size}-kwh battery.")
def get_range(self):
"""打印一条消息,指出电瓶的续航里程。"""
global range
if self.battery_size == 65:
range = 260
elif self.battery_size == 100:
range = 315
print(f"This car can go about {range} miles on a full charge.")
def upgrade_battery(self):
"""检查电瓶容量。"""
if self.battery_size != 100:
self.battery_size = 100
print("Upgrade the battery capacity.")
class ElectricCar(Car):
"""电动汽车的独特之处。"""
def __init__(self, make, model, year):
"""初始化父类的属性。
再初始化电动汽车特有的属性。
"""
super().__init__(make, model, year)
self.battery = Battery()
def car_model(self):
"""指出电动汽车的型号与电池容量的关系。"""
if self.model == "model s":
self.battery.battery_size = 65
elif self.model == "model m":
self.battery.battery_size = 100
my_tesla = ElectricCar('tesla', 'model s', 2019, )
print(my_tesla.get_descriptive_name())
my_tesla.battery.describe_battery()
my_tesla.car_model()
my_tesla.battery.upgrade_battery()
my_tesla.battery.get_range()共勉:
一开始应让代码结构尽量简单。首先尝试在一个文件中完成所有的工作,确定一切都能正确运行后,再将类移到独立的模块中。如果你喜欢模块和文件的交互方式,可在项目开始时就尝试将类存储到模块中。先找出让你能够编写出可行代码的方式,再尝试让代码更加整洁。
# 练习9.10
from restaurant import Restaurant
restaurant = Restaurant("便宜坊","中餐")
restaurant.describe_restaurant()
# 练习9.11
#from user import User,Privileges,Admin
# 练习9.12
# electric_car.py 中:
# from car import Car
# class ElectricCar(Car):
# class Battery:
# my_cars.py 中:
# from car import Car
# from electric_car import ElectricCarfrom random import choice
meeting_host = ["爱梅","志全","坤琳","Mumu"]
print(choice(meeting_host))# 练习9.13
import random
class Die:
def __init__(self, sides=6):
self.sides = sides
def roll_die(self):
print(random.randint(1, self.sides))
die = Die(6)
for i in range(10):
die.roll_die()
# 练习9.14
list = list(range(10))
a = random.sample(list, 4)
print(a)
print("如果彩票上是下面的4个数字您就中奖了:")
for i in a:
print(i)
# 练习9.15
count = 0
a.sort()
while True:
b = random.sample(list, 4)
count += 1
b.sort()
if b == a:
break
print(f"共{count}次抽奖后中奖。")
# 练习9.16
#https://pymotw.com/3/驼峰命名法:类名中的每个单词的首字母都大写,并且不使用下划线。实例名和模块名都采用全小写格式,并在单词之间加上下划线。
Python读取文件时将所有文本都解释为字符串。比如数值,需要用int(),float()进行转换。
# 练习10.1
from pathlib import Path
path = Path("learning_python.txt")
content = path.read_text()
print(content)
print(content.splitlines())
# 练习10.2
print(content.replace("python", "C"))
# 练习10.3
# 参考10.2,删除变量,让代码简洁# 练习10.4
from pathlib import Path
path = Path("guest.txt")
username = input("请输入你的名字:")
path.write_text(username)
# 练习10.5
path2 = Path("guest_book.txt")
while True:
username = input("请输入你的名字:")
with path2.open("a") as f:
f.write(username + "\n")我的一时没有转过弯的想到的问题和来自GPT的回答:
来自GPT4: 在Python中,
try/except/else语句和直接使用try/except然后跟上独立的代码,有一些区别。
else子句在try子句没有引发任何异常的情况下执行。如果try子句引发了异常,那么else子句就不会执行。这实际上允许你对成功的操作进行响应。try: # 可能会抛出异常的代码 except Exception: # 如果有异常,这部分代码会执行 else: # 如果没有异常,这部分代码会执行
- 如果你不使用
else子句,而是在try/except后面直接写代码,那么无论try子句是否引发异常,这部分代码都会执行。try: # 可能会抛出异常的代码 except Exception: # 如果有异常,这部分代码会执行 # 不管是否有异常,这部分代码都会执行所以,使用
else子句可以让你更明确地区分出哪部分代码应该在没有异常时执行,哪部分代码应该在有异常时执行。它可以提高代码的可读性和可维护性。
# 练习 10.6
import urllib.request
from pathlib import Path
print("输入两个数字,我可以把它们加到一起,告诉您结果是什么。")
while True:
try:
num1 = input("请输入第一个数字:")
if num1 == 'q':
break
num1 = int(num1)
num2 = input("请输入第二个数字:")
if num2 == 'q':
break
num2 = int(num2)
print(f"计算结果为:{num1 + num2}\n输入q退出")
except ValueError:
print("您输入的不是数字,请重新输入!")
# 练习 10.7
# 10.6已满足
# 练习 10.8
try:
cats_path = Path("cats.txt")
cats = cats_path.read_text()
print(cats)
except:
print("cats.txt文件不存在")
try:
dogs_path = Path("dogs.txt")
dogs = dogs_path.read_text()
print(dogs)
except:
pass
# 练习 10.9
# 10.8的dogs.txt部分已满足
# 练习 10.10
content = ""
target_url = "https://www.gutenberg.org/files/71317/71317-0.txt"
for line in urllib.request.urlopen(target_url):
content += line.decode('utf-8')
print(content.lower().count("the "))注意,示例10.4.1的contents是什么类型的数据?
可以试着使用type()打印出来看看。
from pathlib import Path
import json
numbers = [2, 3, 5, 7, 11, 13]
path = Path('numbers.json')
contents = json.dumps(numbers)
print(type(contents))<class 'str'>同样的,通过json.loads()读回来的数据是什么类型?
from pathlib import Path
import json
contents = path.read_text()
numbers = json.loads(contents)
print(numbers)
print(type(numbers))[2, 3, 5, 7, 11, 13]
<class 'list'>path.exists()判断path所指向的文件是否存在。
pathlib处理的是硬盘中的数据,读和写等;
json处理的是内存中的数据,dumps()和loads()等。
所以,对于写,先dumps()后write_text(),对于读,先read_text()后loads()。
# 练习 10.11
from pathlib import Path
import json
path = Path("favourite_number.json")
# favourite_number = input("请输入一个数字:")
# path.write_text(json.dumps(int(favourite_number)))
favourite_number = json.loads(path.read_text())
print(f"I know your favourite number is: {favourite_number}")
# 练习 10.12
from pathlib import Path
import json
path = Path("favourite_number.json")
if path.exists():
favourite_number = json.loads(path.read_text())
print(f"I know your favourite number is: {favourite_number}")
else:
favourite_number = input("请输入一个数字:")
with path.open("w") as f:
f.write(json.dumps(int(favourite_number)))
# 练习 10.13
from pathlib import Path
import json
def greet_user():
"""问候用户,并返回用户的名字"""
path = Path("username.json")
if path.exists():
contents = json.loads(path.read_text())
name = contents["username"]
age = contents["age"]
sex = contents["sex"]
times = 3
while True:
login = input("请输入你的登录名:")
if login == name:
print(
f"Hello, {name}, you are {age} years, and you are {sex}!")
break
else:
times -= 1
if times != 0:
print(f"请输入正确的用户名,剩余{times}次机会。")
else:
print("机会已用完。")
break
else:
username = input("请输入你的名字:")
sex = input("请输入你的性别:")
age = input("请输入你的年龄:")
contents = {
"username": username,
"sex": sex,
"age": age,
}
contents = json.dumps(contents)
path.write_text(contents)
print(f"We'll remember you {username}!")
greet_user()如果遇到报错,考虑用管理员权限运行终端。

测试文件,测试函数 的名称必须以test_打头。
要将某个参数设为可选的,将该参数移至末尾,然后设置默认值为"",即空字符串,然后对该参数判断,决定代码的选择,比如:
def get_formatted_name(first, last, middle=''):
if middle:
full_name = f"{first} {middle} {last}"
else:
full_name = f"{first} {last}"
return full_name.title()# 练习 11.1
# 文件city_functions.py中的代码
def cityinfo(city, country):
return f"{city.title()}, {country.title()}"
# 文件test_cities.py中的代码
from city_functions import cityinfo
def test_city_country():
assert cityinfo('santiago', 'chile') == 'Santiago, Chile'运行结果:
PS C:\Users\vwumumu\Desktop\python_work\11.1> pytest
================ test session starts ==============================
platform win32 -- Python 3.11.4, pytest-7.4.0, pluggy-1.0.0
rootdir: C:\Users\vwumumu\Desktop\python_work\11.1
plugins: anyio-3.6.2
collected 1 item
test_cities.py . [100%]
================ 1 passed in 0.01s ================================# 练习 11.2
# 文件city_functions.py中的代码
def cityinfo(city, country, population=""):
if population:
return f"{city.title()}, {country.title()} - population {population}"
else:
return f"{city.title()}, {country.title()}"
# 文件test_cities.py中的代码
from city_functions import cityinfo
def test_city_country():
assert cityinfo('santiago', 'chile') == 'Santiago, Chile'
def test_city_country_population():
assert cityinfo('santiago', 'chile',
population=5000000) == 'Santiago, Chile - population 5000000'运行结果:
PS C:\Users\vwumumu\Desktop\python_work\11.2> pytest.exe
================ test session starts ==============================
platform win32 -- Python 3.11.4, pytest-7.4.0, pluggy-1.0.0
rootdir: C:\Users\vwumumu\Desktop\python_work\11.2
plugins: anyio-3.6.2
collected 2 items
test_cities.py .. [100%]
================ 2 passed in 0.01s ================================# 练习11.3
# 文件employee.py的代码
class Employee:
def __init__(self, firstname, lastname, sallary) -> None:
self.firstname = firstname
self.lastname = lastname
self.sallary = sallary
def give_raise(self, increase=5000):
self.sallary += increase
# 文件test_employee.py的代码
import pytest
from employee import Employee
@pytest.fixture
def employee():
employee = Employee("mumu", "wu", 1800)
return employee
def test_give_default_raise(employee):
employee.give_raise()
assert employee.sallary == 6800
def test_give_custom_raise(employee):
employee.give_raise(increase=10000)
assert employee.sallary == 11800运行结果:
================ test session starts ==============================
platform win32 -- Python 3.11.4, pytest-7.4.0, pluggy-1.0.0
rootdir: C:\Users\vwumumu\Desktop\python_work\11.3
plugins: anyio-3.6.2
collected 2 items
test_employee.py .. [100%]
================ 2 passed in 0.01s ===========================================# 练习 15.1,15.2
import matplotlib.pyplot as plt
x_values = range(1, 6)
# x_values = range(1, 5001) #显示 5000 个正整数的立方值
y_values = [x**3 for x in x_values]
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, s=10)
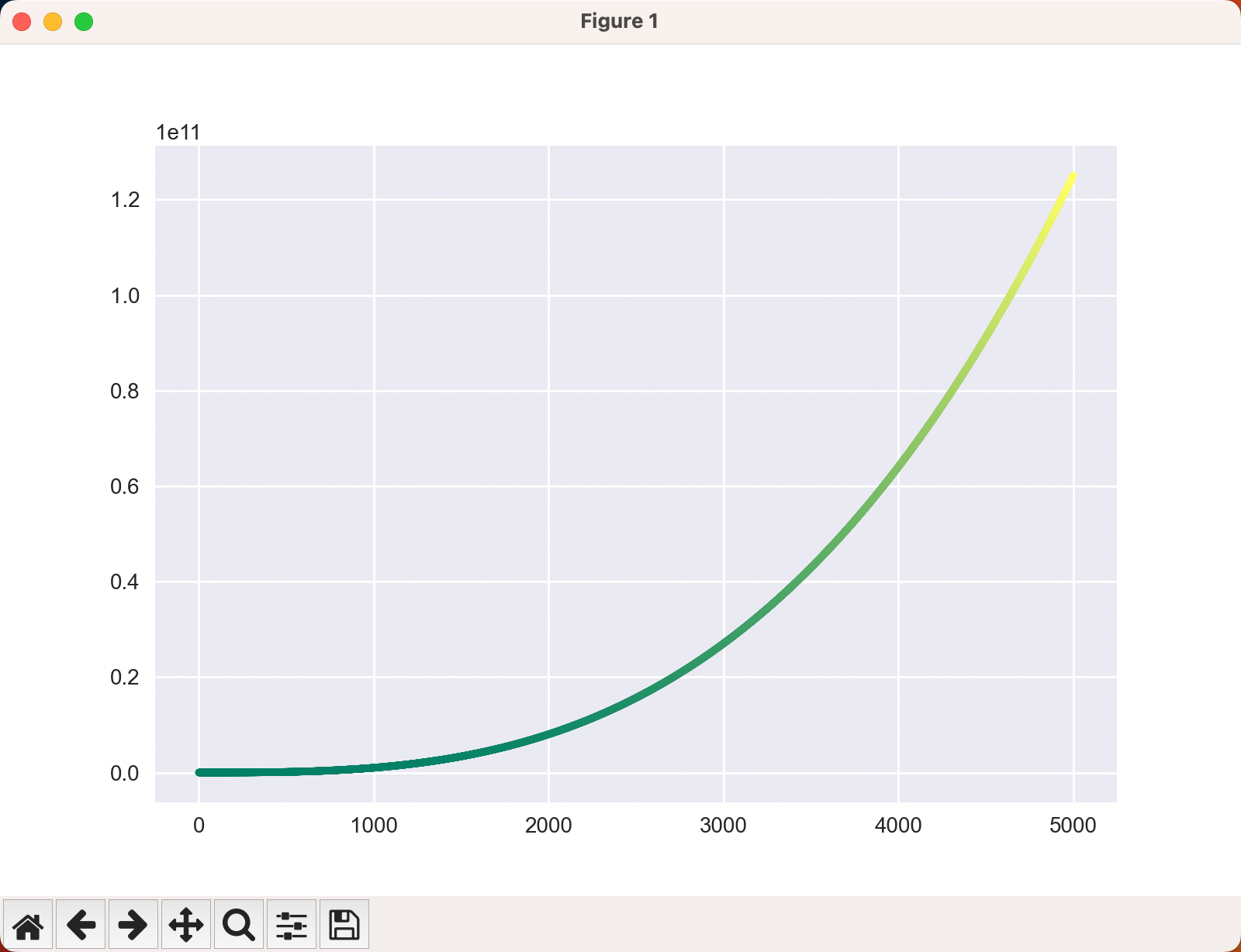
# ax.scatter(x_values, y_values, s=10, c=y_values, cmap=plt.cm.summer) #5000个正整数的代码线条选择了彩色,对应练习 15.2,为了映下景,配色方案选择了夏天“summer”
plt.show()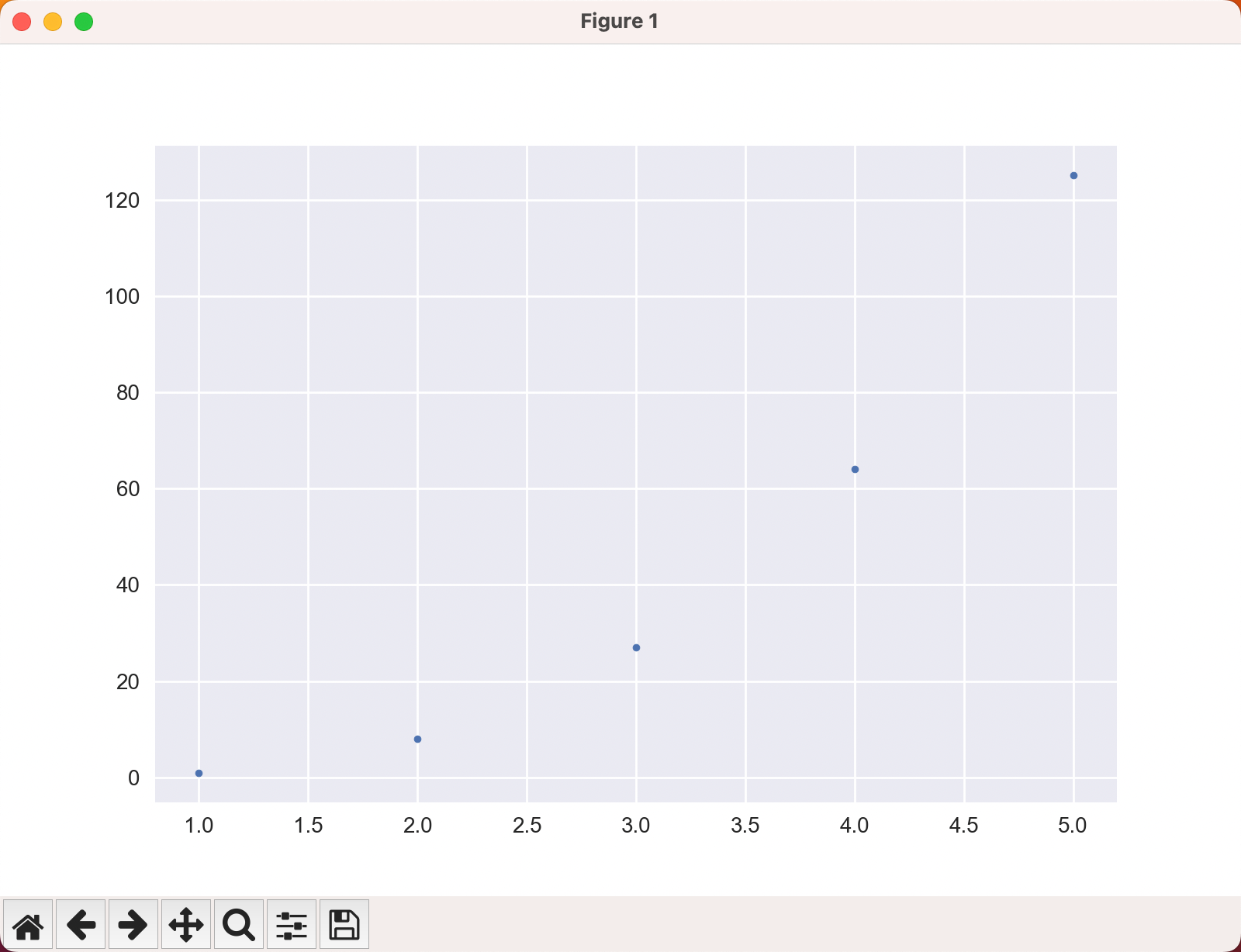
# 练习15.3
import matplotlib.pyplot as plt
from random import choice
class RandomWalk:
def __init__(self, num_points=5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_direction = choice([-1, 1])
x_distance = choice([0, 1, 2, 3, 4])
x_step = x_direction * x_distance
# print(x_step)
y_direction = choice([-1, 1])
y_distance = choice([0, 1, 2, 3, 4])
y_step = y_direction * y_distance
# print(y_step)
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
# print(next_x)
next_y = self.y_values[-1] + y_step
# print(next_y)
self.x_values.append(next_x)
self.y_values.append(next_y)
for i in range(1):
rw = RandomWalk()
rw.fill_walk()
plt.style.use('classic')
fig, ax = plt.subplots(figsize=(40.96, 21.60), dpi=128)
point_numbers = range(rw.num_points)
ax.plot(rw.x_values, rw.y_values, linewidth=1)
ax.set_aspect('equal')
ax.get_xaxis().set_visible(False)
print(ax.get_xaxis)
ax.get_yaxis().set_visible(False)
plt.show()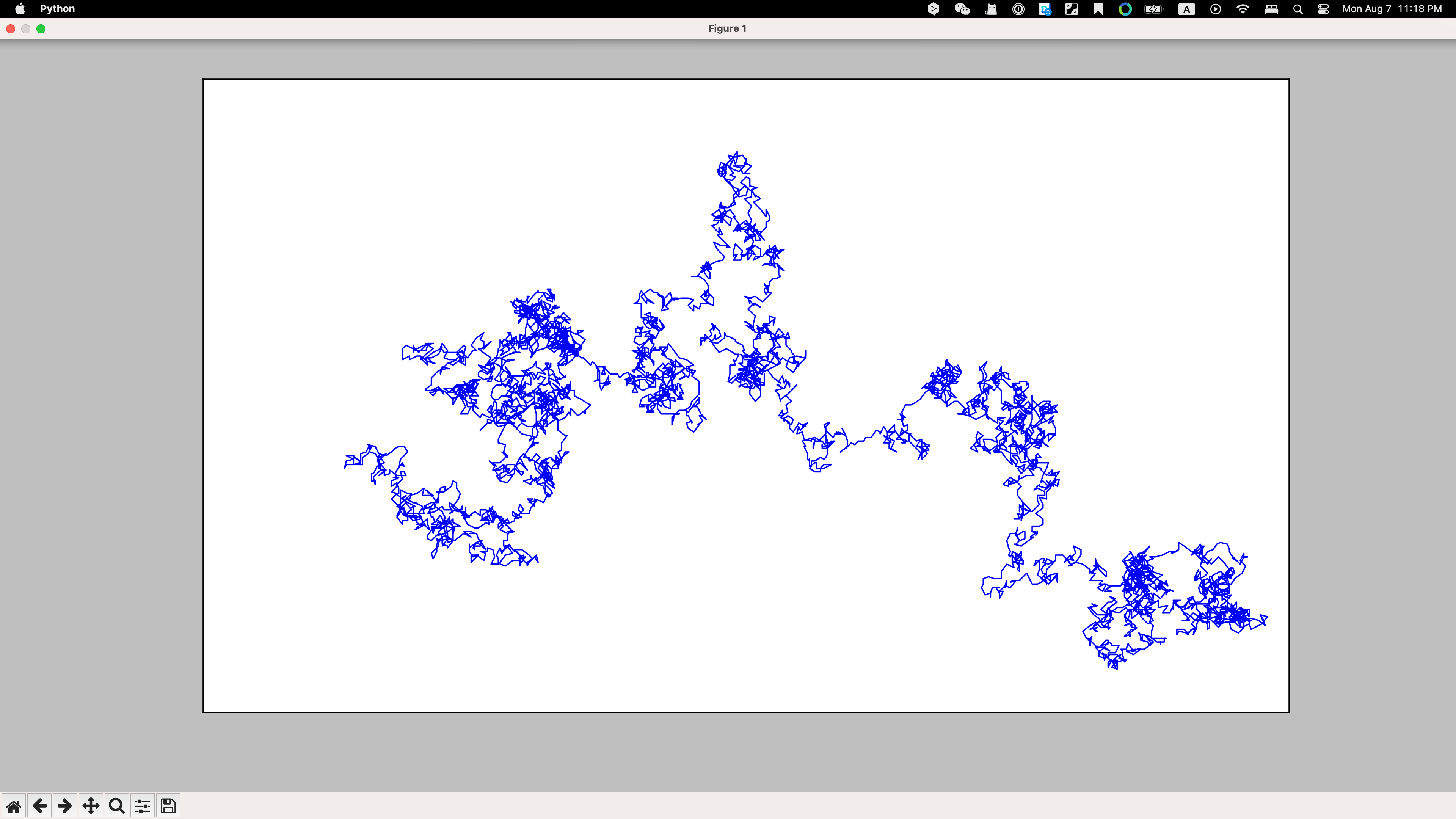
# 练习15.4
# 练习15.3
import matplotlib.pyplot as plt
from random import choice
class RandomWalk:
def __init__(self, num_points=5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_direction = choice([1])
x_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
x_step = x_direction * x_distance
# print(x_step)
y_direction = choice([-1, 1])
y_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
y_step = y_direction * y_distance
# print(y_step)
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
# print(next_x)
next_y = self.y_values[-1] + y_step
# print(next_y)
self.x_values.append(next_x)
self.y_values.append(next_y)
for i in range(1):
rw = RandomWalk()
rw.fill_walk()
plt.style.use('classic')
fig, ax = plt.subplots(figsize=(40.96, 21.60), dpi=128)
point_numbers = range(rw.num_points)
ax.scatter(rw.x_values, rw.y_values, s=1, c=point_numbers,
cmap=plt.cm.Blues, edgecolors='none')
ax.set_aspect('equal')
ax.scatter(0, 0, c='green', edgecolors='none', s=100)
ax.scatter(rw.x_values[-1], rw.y_values[-1],
c='red', edgecolors='none', s=100)
ax.set_aspect('equal')
ax.get_xaxis().set_visible(False)
print(ax.get_xaxis)
ax.get_yaxis().set_visible(False)
plt.show()
# 练习 15.5
import matplotlib.pyplot as plt
from random import choice
class RandomWalk:
def __init__(self, num_points=5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_step, y_step = self.get_step()
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
# print(next_x)
next_y = self.y_values[-1] + y_step
# print(next_y)
self.x_values.append(next_x)
self.y_values.append(next_y)
def get_step(self):
while len(self.x_values) < self.num_points:
x_direction = choice([-1, 1])
x_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
x_step = x_direction * x_distance
y_direction = choice([-1, 1])
y_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
y_step = y_direction * y_distance
return x_step, y_step
for i in range(1):
rw = RandomWalk(num_points=50000)
rw.fill_walk()
plt.style.use('classic')
fig, ax = plt.subplots(figsize=(40.96, 21.60), dpi=128)
point_numbers = range(rw.num_points)
ax.scatter(rw.x_values, rw.y_values, s=1, c=point_numbers,
cmap=plt.cm.Blues, edgecolors='none')
ax.set_aspect('equal')
ax.scatter(0, 0, c='green', edgecolors='none', s=100)
ax.scatter(rw.x_values[-1], rw.y_values[-1],
c='red', edgecolors='none', s=100)
ax.set_aspect('equal')
ax.get_xaxis().set_visible(False)
print(ax.get_xaxis)
ax.get_yaxis().set_visible(False)
plt.show()# 练习15.6
from random import randint
import plotly.express as px
class Die:
"""表示一个骰子的类"""
def __init__(self, num_sides=6):
"""骰子默认为 6 面的"""
self.num_sides = num_sides
def roll(self):
""""返回一个介于 1 和骰子面数之间的随机值"""
return randint(1, self.num_sides)
die1 = Die(8)
die2 = Die(8)
# 掷几次骰子并将结果存储在一个列表中
results = []
for roll_num in range(100000):
result = die1.roll() + die2.roll()
results.append(result)
print(results)# 练习15.7
from random import randint
import plotly.express as px
class Die:
"""表示一个骰子的类"""
def __init__(self, num_sides=6):
"""骰子默认为 6 面的"""
self.num_sides = num_sides
def roll(self):
""""返回一个介于 1 和骰子面数之间的随机值"""
return randint(1, self.num_sides)
die1 = Die()
die2 = Die()
die3 = Die()
# 掷几次骰子并将结果存储在一个列表中
results = []
for roll_num in range(10000):
result = die1.roll() + die2.roll() + die3.roll()
results.append(result)
frequencies = []
max_result = die1.num_sides + die2.num_sides + die3.num_sides
poss_results = range(3, max_result +1)
for value in poss_results:
frequency = results.count(value)
frequencies.append(frequency)
title = "Results of rolling 3 D6 10000 times."
labels = {"x": "Result", "y": "Frequency of Result"}
fig = px.bar(x=poss_results, y=frequencies, labels=labels, title=title)
fig.update_layout(xaxis_dtick=1)
fig.show()
# 练习15.8
from random import randint
import plotly.express as px
class Die:
"""表示一个骰子的类"""
def __init__(self, num_sides=6):
"""骰子默认为 6 面的"""
self.num_sides = num_sides
def roll(self):
""""返回一个介于 1 和骰子面数之间的随机值"""
return randint(1, self.num_sides)
die1 = Die()
die2 = Die()
# 掷几次骰子并将结果存储在一个列表中
results = []
for roll_num in range(10000):
result = die1.roll() * die2.roll()
results.append(result)
frequencies = []
max_result = die1.num_sides * die2.num_sides
poss_results = range(1, max_result +1)
for value in poss_results:
frequency = results.count(value)
frequencies.append(frequency)
title = "Results of rolling 2 D6 10000 times."
labels = {"x": "Result", "y": "Frequency of Result"}
fig = px.bar(x=poss_results, y=frequencies, labels=labels, title=title)
fig.update_layout(xaxis_dtick=1)
fig.show()
# 练习15.9
from random import randint
import plotly.express as px
class Die:
"""表示一个骰子的类"""
def __init__(self, num_sides=6):
"""骰子默认为 6 面的"""
self.num_sides = num_sides
def roll(self):
""""返回一个介于 1 和骰子面数之间的随机值"""
return randint(1, self.num_sides)
die1 = Die()
die2 = Die()
# 掷几次骰子并将结果存储在一个列表中
results = []
results = [die1.roll() * die2.roll() for roll_num in range(10000)]
frequencies = []
max_result = die1.num_sides * die2.num_sides
poss_results = range(1, max_result +1)
frequencies = [results.count(value) for value in poss_results]
title = "Results of rolling 2 D6 10000 times."
labels = {"x": "Result", "y": "Frequency of Result"}
fig = px.bar(x=poss_results, y=frequencies, labels=labels, title=title)
fig.update_layout(xaxis_dtick=1)
fig.show()# 练习15.10
# 用Matplotlib实现掷骰子
from random import randint
import matplotlib.pyplot as plt
class Die:
"""表示一个骰子的类"""
def __init__(self, num_sides=6):
"""骰子默认为 6 面的"""
self.num_sides = num_sides
def roll(self):
""""返回一个介于 1 和骰子面数之间的随机值"""
return randint(1, self.num_sides)
die1 = Die()
die2 = Die()
# 掷几次骰子并将结果存储在一个列表中
results = []
results = [die1.roll() * die2.roll() for roll_num in range(10000)]
frequencies = []
max_result = die1.num_sides * die2.num_sides
poss_results = range(1, max_result +1)
frequencies = [results.count(value) for value in poss_results]
fig, ax = plt.subplots()
results = poss_results
counts = frequencies
ax.bar(results, counts)
plt.show()
# 练习15.10
# 用Plotly实现随机游走
from random import choice
import plotly.express as px
class RandomWalk:
def __init__(self, num_points=5000):
self.num_points = num_points
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
while len(self.x_values) < self.num_points:
x_step, y_step = self.get_step()
if x_step == 0 and y_step == 0:
continue
next_x = self.x_values[-1] + x_step
# print(next_x)
next_y = self.y_values[-1] + y_step
# print(next_y)
self.x_values.append(next_x)
self.y_values.append(next_y)
def get_step(self):
while len(self.x_values) < self.num_points:
x_direction = choice([-1, 1])
x_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
x_step = x_direction * x_distance
y_direction = choice([-1, 1])
y_distance = choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
y_step = y_direction * y_distance
return x_step, y_step
for i in range(1):
rw = RandomWalk(num_points=10000)
rw.fill_walk()
fig = px.scatter(x=rw.x_values, y=rw.y_values, title='Random Walk')
fig.show()
对于练习15.10,我们需要找到对方的库中相似的图形,然后参考样例的代码,替换呈现部分的数据,元数据保持不变即可。
# 16.1
from pathlib import Path
import csv
import matplotlib.pyplot as plt
from datetime import datetime
path = Path('project2\\16\sitka_weather_2021_full.csv')
path2 = Path('project2\\16\death_valley_2021_full.csv')
lines = path.read_text().splitlines()
lines2 = path2.read_text().splitlines()
# convert lines to csv
reader = csv.reader(lines)
reader2 = csv.reader(lines2)
# get index and content of first line
header_row = next(reader)
header_row2 = next(reader2)
for i,c in enumerate(header_row2):
print(i,c)
water,dates = [],[]
water2,dates2 = [],[]
for row in reader:
dates.append(datetime.strptime(row[2], "%Y-%m-%d"))
# print(type(row[5]))
water.append(float(row[5]))
for row in reader2:
dates2.append(datetime.strptime(row[2], "%Y-%m-%d"))
# print(type(row[5]))
water2.append(float(row[3]))
# print(dates2,water2)
plt.style.use("seaborn")
fig, (ax1,ax2) = plt.subplots(2,1)
ax1.bar(dates, water, color="blue")
ax2.bar(dates2, water2, color="red")
plt.show()
# 练习16.2
from pathlib import Path
import csv
import matplotlib.pyplot as plt
from datetime import datetime
path = Path('project2\\16\sitka_weather_2021_full.csv')
path2 = Path('project2\\16\death_valley_2021_full.csv')
lines = path.read_text().splitlines()
lines2 = path2.read_text().splitlines()
# convert lines to csv
reader = csv.reader(lines)
reader2 = csv.reader(lines2)
# get index and content of first line
header_row = next(reader)
header_row2 = next(reader2)
for i,c in enumerate(header_row2):
print(i,c)
water,dates = [],[]
water2,dates2 = [],[]
for row in reader:
dates.append(datetime.strptime(row[2], "%Y-%m-%d"))
# print(type(row[5]))
water.append(float(row[5]))
for row in reader2:
dates2.append(datetime.strptime(row[2], "%Y-%m-%d"))
# print(type(row[5]))
water2.append(float(row[3]))
# print(dates2,water2)
plt.style.use("seaborn")
fig, (ax) = plt.subplots()
ax.bar(dates, water, color="blue")
ax.bar(dates2, water2, color="red")
plt.show()
# 练习 16.3
#雷同问题,跳过。
# 练习 16.4
#获取表头后,通过if判断,然后使用不同的代码。
# 练习 16.5
#雷同,跳过。# 练习 16.6
for eq_dict in all_eq_dicts:
mags.append(eq_dict['properties']['mag'])
titles.append(eq_dict['properties']['title'])
lons.append(eq_dict['geometry']['coordinates'][0])
lats.append(eq_dict['geometry']['coordinates'][1])
# 练习 16.7
title= all_eq_data['metadata']["title"],
# 练习 16.8
#跳过
# 练习 16.9
from pathlib import Path
import csv
import plotly.express as px
path = Path("project2\\16.9\world_fires_1_day.csv")
lines = path.read_text().splitlines()
reader = csv.reader(lines)
header_row = next(reader)
for i,c in enumerate(header_row):
print(i,c)
longitude, latitude, brightness = [], [], []
for row in reader:
longitude.append(float(row[1]))
latitude.append(float(row[0]))
brightness.append(float(row[2]))
fig = px.scatter_geo(lon=longitude, lat=latitude, size=brightness, color=brightness, color_continuous_scale='bluered', range_color=(0, 400), title='Global Fires', projection='natural earth')
fig.show()文中涉及的<a>标签,CSS都是Web开发的相关技术,可先完成内容的理解即可,不必深究。
# 练习 17.1
#只需要修改url的关键字即可,比如把Python改成JavaScript:
url += "?q=language:javascript+sort:stars+stars:>10000"
# 练习 17.2
import requests
# import json
from operator import itemgetter
import plotly.express as px
url = "https://hacker-news.firebaseio.com/v0/topstories.json"
r = requests.get(url)
submission_ids = r.json()
submission_dicts = []
for submission_id in submission_ids[:30]:
url = f"https://hacker-news.firebaseio.com/v0/item/{submission_id}.json"
r = requests.get(url)
# print(f"id: {submission_id}\tstatus: {r.status_code}")
response_dict = r.json()
try:
submission_dict = {
"title": response_dict["title"],
"hn_link": f"https://news.ycombinator.com/item?id={submission_id}",
"comments": response_dict["descendants"],
}
except:
pass
else:
submission_dicts.append(submission_dict)
submission_dicts = sorted(submission_dicts, key=itemgetter("comments"), reverse=True)
comments, hn_links, hover_texts = [], [], []
for submission_dict in submission_dicts:
title = submission_dict['title']
comment = submission_dict['comments']
hn_link = submission_dict['hn_link']
comments.append(comment)
hn_links.append(f"<a href='{hn_link}'>{title}</a>")
hover_text = f"{title}<br />{comment}"
hover_texts.append(hover_text)
title="Top stories on HN"
labels={'x':'Titles', 'y':'Comments'}
fig = px.bar(x=hn_links, y=comments, title=title, hover_name= hover_texts )
fig.update_layout(title_font_size=28, xaxis_title_font_size=20, yaxis_title_font_size=20)
fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)
fig.show()
# 练习 17.3
#把status_code换成其他的属性即可,跳过。
# 练习 17.4
#重复性练习,赶赶进度,先跳过了。下面基本上相当于模板,套用替换内容即可。
从API获取数据:
import requests
import json
# Make an API call, and store the response.
url = "https://hacker-news.firebaseio.com/v0/item/31353677.json"
# Explore the structure of the data.
response_dict = r.json()
response_string = json.dumps(response_dict, indent=4)处理CSV数据:
from pathlib import Path
import csv
path = Path('weather_data/death_valley_2021_simple.csv')
lines = path.read_text().splitlines()
reader = csv.reader(lines)处理JSON数据:
from pathlib import Path
import json
# 读取作为字符串的数据并转换为Python对象。
path = Path('eq_data/eq_data_1_day_m1.geojson')
contents = path.read_text()
all_eq_data = json.loads(contents)通过API,CSV或JSON拿到数据之后处理数据,得到图标需要的元素,比如用于做X,Y轴的数据,然后最简单的拿来就用的方式就是“抄”,“模仿“ Matplotlib和Plotly的官方例子,参考例子的源代码,替换其中的变量,如果想进一步研究就需要阅读其官方文档。
#跳过每当需要修改“学习笔记”管理的数据时,都采取如下三个步骤:修改 models.py,对 learning_logs 调用 makemigrations,以及让 Django 迁移项目。
topic = models.ForeignKey(Topic,on_delete=models.CASCADE)在Entries的代码中,通过上面的代码,将Entries表与Topic进行了关联,Entries中有了Topic中创建的记录。
# 练习 18.2
def __str__(self):
"""Return a string representation of the model."""
if len(self.text) < 50:
return self.text
else:
return self.text[:50] + "..."
# 练习 18.3
#https://docs.djangoproject.com/en/4.2/topics/db/queries/#making-queries这个练习当做前面的“套路”的梳理。
-
新建环境:
cd D:\SynologyDrive\projects\ mkdir pizzeria_project cd pizzeria_project python -m venv pizzeria_project -
激活环境:
.\pizzeria_project\Scripts\activate
-
安装Django:
pip install --upgrade pip pip install django -
通过Django创建项目:
django-admin startproject pizzeria_project . -
创建数据库:
python .\manage.py migrate
-
运行站点:
python .\manage.py runserver
-
创建应用:
python .\manage.py startapp pizzas
-
定义模型
models.pyfrom django.db import models # Create your models here. class Pizza(models.Model): """A pizza the user can order.""" name = models.CharField(max_length=200) def __str__(self): """Return a string representation of the model.""" return self.name class Topping(models.Model): """Toppings for pizza.""" pizza = models.ForeignKey(Pizza, on_delete=models.CASCADE) name = models.TextField() def __str__(self): """Return a string representation of the model.""" return self.name
-
激活模型
settings.py:INSTALLED_APPS = [ "pizzas", # "pizzas" is the name of the app we just created 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]
-
更新数据库:
python .\manage.py makemigrations pizzas python .\manage.py migrate
-
创建管理员用户:
python .\manage.py createsuperuser -
向管理网站注册模型
admin.py:from .models import Pizza, Topping admin.site.register(Pizza) admin.site.register(Topping)
-
通过Django shell查询:
(pizzeria_project) PS D:\SynologyDrive\projects\pizzeria_project> python .\manage.py shell Python 3.11.4 (tags/v3.11.4:d2340ef, Jun 7 2023, 05:45:37) [MSC v.1934 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>> from pizzas.models import Topping >>> Topping.objects.all() <QuerySet [<Topping: Pineapple>, <Topping: Canadian bacon>, <Topping: Sausage>]> >>>
18.5跳过,因为已经通过18.4详细的梳理了过程。
练习18.6当做前面的“套路”的梳理。
url=>view=>html
-
在
pizzeria_project/urls.py配置url:from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path("", include("pizzas.urls")) ]
-
新建
pizzas/urls.py并添加:from django.urls import path from . import views app_name = "pizzas" urlpatterns = [ path("", views.index, name="index"), ]
-
在
view.py中指定index.html页面:from django.shortcuts import render # Create your views here. def index(request): return render(request,"pizzas/index.html")
-
编写
pizzas\templates\pizzas\index.htm内容:<h2>Pizza Shop</h2> <p> Welcome to the Pizza Shop! Here you can order a pizza, and see all the pizzas that have been ordered. </p>
Base:
<p>
<h2><a href="{% url 'learning_logs:index' %}">Learning Log</a></h2>
</p>
{% block content %}{% endblock content %}Extend:
{% extends "learning_logs/base.html" %} {% block content %}
<p>
Learning Log helps you keep tack of your learning, for any topic you're
inserestted in.
</p>
{% endblock content %}# 练习 18.7
# https://docs.djangoproject.com/en/4.2/topics/templates/
# 练习 18.8
# 将learning_note的关键字改成Pizzas项目的关键字即可实现。