Sequential 모델은 층layer을 순서대로 쌓은 것입니다.
아래와 같이 각 층 인스턴스를 리스트 형식으로 나열하여 생성자constructor인 Sequential로 넘겨주면 모델이 만들어집니다.
from keras.models import Sequential # Sequential 생성자를 불러옵니다.
from keras.layers import Dense, Activation # Dense와 Activation 두 층 인스턴스를 불러옵니다.
# Sequential 생성자에 층을 순서대로 담은 리스트를 전달하여 모델을 만듭니다.
model = Sequential([
Dense(32, input_shape=(784,)), # 784 차원의 입력을 받아 32 차원으로 출력하는 완전 연결 신경망 층입니다.
Activation('relu'), # 'relu' 활성화 함수를 적용하는 층입니다.
Dense(10), # 입력을 10차원으로 출력하는 완전 연결 신경망 층입니다.
Activation('softmax'), # 'softmax' 활성화 함수를 적용하는 층입니다.
])각 층을 리스트 형식으로 입력하는 방법 외에도, Sequential 생성자로 만든 모델에 .add() 메소드를 사용하면 손쉽게 새 층을 덧붙일 수 있습니다.
model = Sequential() # 먼저 Sequential 생성자를 이용하여 빈 모델을 만들고,
model.add(Dense(32, input_dim=784)) # Dense 층을 추가하고,
model.add(Activation('relu')) # Activation 층을 추가합니다.각 모델은 어떤 형태shape의 값이 입력될지 미리 알아야 합니다. 때문에 Sequential 모델의 첫 번째 층은 입력할 데이터의 형태 정보를 받습니다(이후의 층들은 자동으로 이전 층의 출력 정보를 입력 정보로 채택하여 형태를 추정합니다). 형태 정보는 다음과 같은 방법으로 입력할 수 있습니다.
- 첫 번째 층의
input_shape인자argument에 형태를 입력하는 방법입니다.input_shape인자는 입력 데이터의 각 차원별 크기를 나타내는 정수값들이 나열된 튜플이며, 정수 대신None을 쓸 경우 아직 정해지지 않은 양의 정수를 나타냅니다. 배치 크기는input_shape인자에 포함되지 않습니다. input_shape인자는 입력 값의 크기와 시계열 입력의 길이를 포괄합니다. 따라서Dense와 같이 2D 처리를 하는 층의 경우input_shape대신에input_dim인자를 통해서도 입력 크기를 지정할 수 있으며, 시계열과 같이 3D 처리를 하는 층은input_dim과input_length의 두 인자를 사용해서 입력 차원의 크기와 시계열 길이를 각각 지정할 수 있습니다.- 배치 크기를 고정해야 하는 경우
batch_size인자를 사용합니다(순환 신경망Recurrent Neural Network과 같이 현 시점의 결과를 저장하여 다음 시점으로 넘기는 처리를 하는 경우 배치 크기 고정이 필요합니다). 예를 들어,batch_size=32와input_shape=(6, 8)을 층에 입력하면 이후의 모든 입력을(32, 6, 8)의 형태로 처리합니다.
이에 따라, 아래의 두 코드는 완전히 동일하게 작동합니다.
model = Sequential()
model.add(Dense(32, input_shape=(784,))) # input_shape를 이용하여 입력 차원(input_dim)을 768로 지정model = Sequential()
model.add(Dense(32, input_dim=784)) # input_dim을 이용하여 입력 차원을 768로 지정모델을 학습시키기 전에 compile 메소드를 통해서 학습과정의 세부 사항을 설정합니다. compile 메소드는 다음 세 개의 인자를 입력받습니다.
- 최적화 함수optimizer: 기존의 최적화 함수를(예:
Adam,adagrad등) 문자열로 된 식별자identifier를 통해 불러오거나Optimizer클래스의 인스턴스를 만들어서 사용할 수 있습니다. - 손실 함수loss function: 모델이 학습을 통해 최소화하고자 하는 목적 함수objective function입니다. 이 또한 기존 손실 함수의 문자열 식별자(예:
categorical_crossentropy,mse등)를 입력하거나 별도의 목적 함수를 지정하여 사용할 수 있습니다. - 평가 지표metric 리스트: 모델의 성능을 평가할 지표를 리스트 형식으로 입력합니다. 예컨대 분류문제라면
metrics=['accuracy']를 통해 정확도accuracy를 산출할 수 있습니다. 평가 지표는 기존 지표 함수를 문자열 식별자로 불러오거나 사용자가 함수를 정의하여 지정할 수 있습니다.
# 다중 분류 문제 예시
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 이진 분류 문제 예시
model.compile(optimizer='Adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 회귀분석에 사용할 평균 제곱근 오차 계산
model.compile(optimizer='Adam',
loss='mse')
# 사용자 정의 평가 지표 예시
import keras.backend as K
def mean_pred(y_true, y_pred): # y_true와 y_pred 두 개의 인자를 받는 지표 함수 mean_pred를 정의합니다.
return K.mean(y_pred) # y_pred의 평균값을 반환합니다.
model.compile(optimizer='Adam',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred]) # metrics에 'accuracy'와 앞서 정의한 mean_pred를 리스트 형식으로 입력합니다.케라스 모델들은 데이터와 레이블로 구성된 NumPy 배열을 입력받아 학습합니다. 모델의 학습에는 일반적으로 fit 함수를 사용합니다.
# 하나의 데이터를 입력받아 두 개의 클래스로 분류하는 이진 분류 모델의 경우:
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100)) # 입력 100차원, 출력 32차원에 'relu' 함수를 적용하는 Dense 층입니다.
model.add(Dense(1, activation='sigmoid')) # 1차원 출력에 'sigmoid' 함수를 적용하는 Dense 층입니다.
model.compile(optimizer='Adam', # 최적화 함수 = 'Adam'
loss='binary_crossentropy', # 손실 함수 = 'binary_crossentropy'
metrics=['accuracy']) # 평가 지표 = 'accuracy'
# 예제를 위한 더미 데이터 생성
import numpy as np
data = np.random.random((1000, 100)) # 0과 1 사이 값을 갖는 1000 x 100 차원의 난수 행렬을 무작위로 생성합니다.
labels = np.random.randint(2, size=(1000, 1)) # 0 또는 1의 값을 갖는 1000 x 1 차원의 레이블 행렬을 무작위로 생성합니다.
# 학습시키기
model.fit(data, labels, epochs=10, batch_size=32) # 생성된 데이터를 32개씩의 배치로 나누어 전체를 총 10회 학습시킵니다.# 하나의 데이터를 입력받아 열 개의 클래스로 분류하는 다중 분류 모델의 경우:
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax')) # 10 출력에 'sigmoid' 함수를 적용하는 Dense 층입니다.
model.compile(optimizer='Adam',
loss='categorical_crossentropy', # 손실 함수 = 'categorical_crossentropy'
metrics=['accuracy'])
# 예제를 위한 더미 데이터 생성
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1)) # 0과 9사이 정수값을 갖는 100 x 1 차원 레이블 행렬을 무작위로 생성합니다.
# 레이블을 열 개 클래스의 원-핫 인코딩 데이터로 변환
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# 각 32개씩의 배치로 나누어 총 10회 학습
model.fit(data, one_hot_labels, epochs=10, batch_size=32)바로 실험해볼 수 있는 예시들입니다!
- CIFAR10 소형 이미지 분류: 실시간 데이터 증강을 포함하는 합성곱 신경망Convolutional Neural Network
- IMDB 영화 후기 감정 분류: 순서를 가진 문자열을 다루는 LSTMLong Short-Term Memory 모형
- 로이터 뉴스Reuters Newswires 주제 분류: 다층 퍼셉트론Multilayer Perceptron 모형
- MNIST 손으로 쓴 숫자 이미지 분류: 다층 신경망과 합성곱 신경망
- LSTM을 이용한 문자 단위 텍스트 생성기
...등등.
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# 예제를 위한 더미 데이터 생성
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# 아래의 Dense(64)는 64개의 은닉 유닛을 갖는 완전 연결 신경망입니다.
# 첫번째 층에서 반드시 입력될 데이터의 형태를 명시해야 합니다.
# 본 예시에서는 20차원 벡터가 입력됩니다.
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# 예제를 위한 더미 데이터 생성
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# 예제를 위한 더미 데이터 생성
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# 입력 데이터: R, G, B 3개의 색상 채널을 가진 100x100 사이즈 이미지 -> (100, 100, 3)의 텐서
# 이 입력 데이터에 3x3 크기를 가진 서로 다른 합성곱 필터 32개를 적용합니다.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
max_features = 1024
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
seq_length = 64
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)시계열 데이터의 고차원적인 요인들을 학습할 수 있도록 3개의 LSTM층을 연결한 모델을 만듭니다.
처음의 두 LSTM 층은 순서의 모든 지점에서 결과값을 출력합니다 return_sequences=True. 즉, 입력값의 순서 개수와 출력값의 순서 개수가 같습니다. 하지만 마지막 LSTM 층은 출력 시퀀스의 최종 시점에서 결과를 출력합니다. 따라서 앞서 구성한 LSTM층의 최종 출력은 시계열 차원이 없어진 크기를 가집니다(이 과정은 길이를 가진 여러 벡터의 입력 시퀀스를 하나의 벡터로 변환하는 것과도 같습니다).
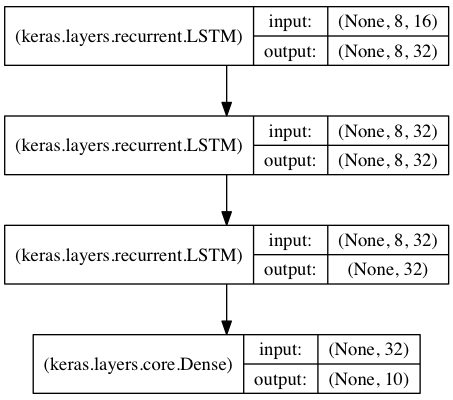
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16 # 입력 데이터는 16 차원입니다.
timesteps = 8 # 8개의 순서 시점을 갖습니다.
num_classes = 10 # 목표 클래스는 10개 입니다.
# 입력 데이터의 형태: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 32 차원의 순서형 벡터를 반환합니다.
model.add(LSTM(32, return_sequences=True)) # 32 차원의 순서형 벡터를 반환합니다.
model.add(LSTM(32)) # 32 차원의 단일 벡터를 반환합니다.
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
# 예제를 위한 더미 훈련 데이터 생성
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# 예제를 위한 더미 검증 데이터 생성
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))상태 저장 순환 신경망stateful Recurrent Model은 입력된 배치를 처리하여 얻은 내부 상태(메모리)를 다음 배치의 초기 상태로 재사용합니다. 이를 통해서 계산 복잡도가 지나치게 높지 않게끔 유지하면서 보다 긴 시퀀스를 처리할 수 있도록 합니다. (예를 들어, 하나의 매우 긴 시계열을 보다 짧은 시계열 길이로 쪼갠 뒤 연속된 배치로 바꾸어 처리하는 경우를 생각해볼 수 있습니다. 이 경우 상태 저장 옵션은 이전 배치의 결과를 다음 배치로 연결해주기 때문에 서로 다른 배치가 마치 하나의 시계열로 이어진 것과 같은 효과를 냅니다.)
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# 입력 데이터의 형태: (batch_size, timesteps, data_dim)
# 상태 저장을 활용하기 위해서는 모든 배치의 크기가 같아야 합니다.
# 이 경우 input_shape 인자 대신 batch_input_shape 인자를 사용하여 배치 크기를 함께 명시합니다.
# k번째 배치의 i번째 표본은 k-1번째 배치의 i번째 표본으로부터 상태를 이어받습니다.
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
# 예제를 위한 더미 훈련 데이터 생성
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# 예제를 위한 더미 검증 데이터 생성
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))X 데이터가 문제집, y 데이터가 답지라 가정했을때 batch_size는 몇문제를 풀고 답지와 비교할 것인지를 나타내는 것입니다.
X = 100
batch_size = 1한 문제씩 풀고 답지와 비교하며 풀이 한 문제씩 풀면서 가중치(W)를 갱신하는 방법인데, 총 100문제를 풀면서 100번을 갱신하게 됩니다.
X = 100
batch_size = 1010 문제씩 풀고 답지와 비교하며 풀이 10 문제씩 풀면서 가중치(W)를 갱신하는 방법인데, 총 100문제를 풀면서 10번을 갱신하게 됩니다.
batch_size가 작을수록 가중치 갱신이 자주되며 이는 더 좋은 정확도를 가져오는 경우가 크지만 그만큼 학습시간이 오래 걸립니다. 반면에 batch_size가 클수록 정확도는 상대적으로 떨어지겠지만 시간적 효율성이 높아짐을 기대할 수 있습니다. 적절한 batch_size로 시작하여 모델의 정확도를 높일때 조금씩 줄여나가는 방법을 권장합니다.
epochs는 문제집의 권 수를 의미합니다. X=100일 경우, 이 100문항의 문제들을 몇번 풀것인가를 나타냅니다.
일반적으로 여러번 반복해서 풀면 정확도가 올라가겠지만, 적정선을 넘은 epochs에서는 Overfitting(오버피팅)이 일어날 수 있습니다. 같은 문제집을 여러번 풀다보면 문제 번호만 보고도 답을 맞추는 등의 상황(Overfitting)이 나오기 때문입니다.
Overfitting(오버피팅) : 훈련 데이터에만 익숙해져서 외부에서 들어오는 새로운 값에 대한 정확도가 떨어지는 상황