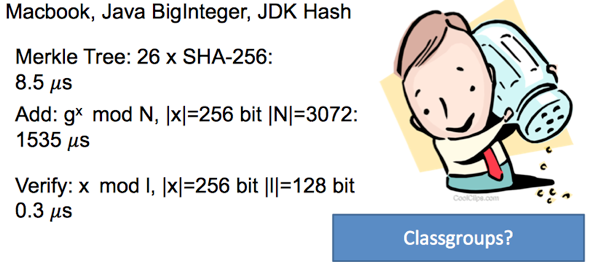
You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Bitcoin Core开发者对dust output的定义是an output that costs more in fees to spend than the value of the output,通常没有经济动机去花费UTXO集合中的dust output。为了计算花费一个output所需的代价,既需要知道output的大小也需要知道相应的input的大小。由于无法提前知道input的大小,Bitcoin Core就用148个字节来作为input的粗略估计(根据最常见的P2PKH交易类型做出的估计)。
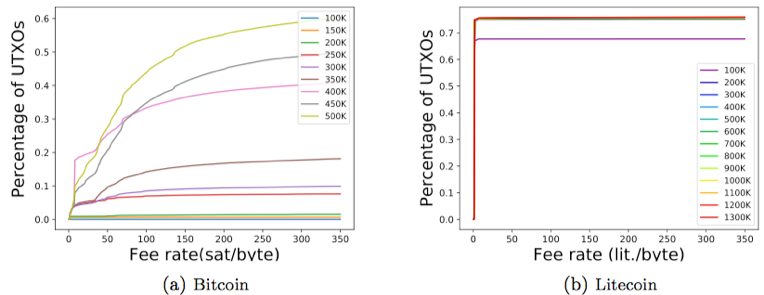
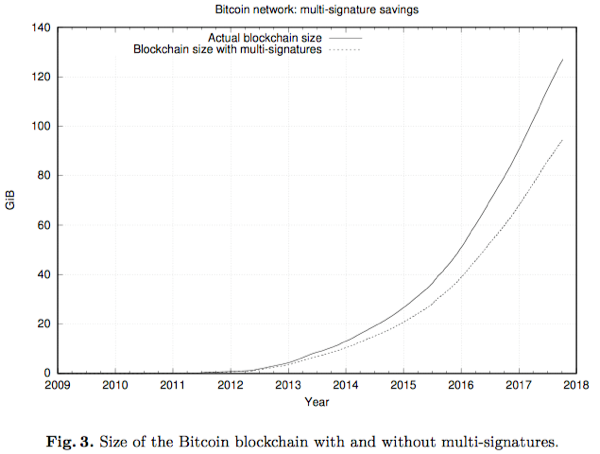
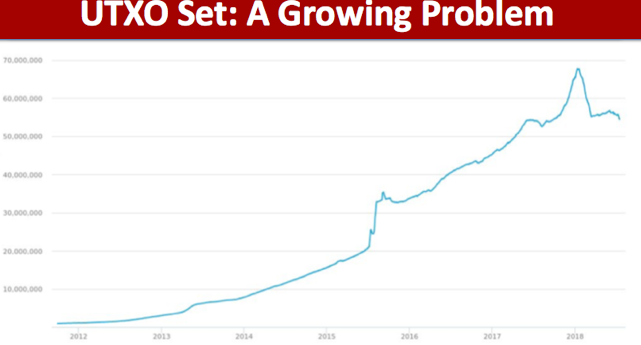
这篇工作中指出,dust output的这种定义在刻画不值得花费的output方面并不精确:1)根据交易类型的不同,input的大小会有不同;2)dust output的定义中同时考虑了output和input的大小,这项工作中,作者谈到“we claim that since the transaction containing the output is already in the blockchain, its size should not be taken into account when analyzing the dust problem (since it has already been paid).”基于这两点原因,给出了unprofitable output的定义,该定义与dust output基本相同,差别在于unprofitable output定义中仅考虑花费相应output所需的input的大小。根据交易类型的不同,有可能准确推断出input的大小也有可能无法准确估计,因此给出了两种度量unprofitable_low和unprofitable_est,前者考虑可能的最小的input大小,或者则根据链上数据的给出尽可能准确的input的大小。然后用这三种指标度量了Bitcoin、Bitcoin Cash和Litecoin的UTXO集合,在下图中以50k block为间距绘制了unprofitable outputs随着时间推移在不同的费率条件下在UTXO集合中的占比。一个很自然的观察是,unprofitable outputs总是在增加。根据论文统计分析,在Bitcoin中P2PKH交易贡献了所有的unprofitable outputs中的81%。另外Bitcoin Cash和Bitcoin在450k之前相同,所以可直接参考Bitcoin的数据。Litecoin图标的诡异之处是因为“67% of Litecoin’s UTXOs belong to the first five months of the coin and a similar amount carries just one satoshi”。
总结下,在费率为100sat/byte时,35~45%的Bitcoin和Bitcoin Cash以及67%的Litecoin的UTXO为unprofitable outputs,也占据了全节点中UTXO集合同等比例的存储体积,然而这些output仅代表了各自币种中非常小的货币供应:0.01% for BTC & BCH,negligible for LTC。
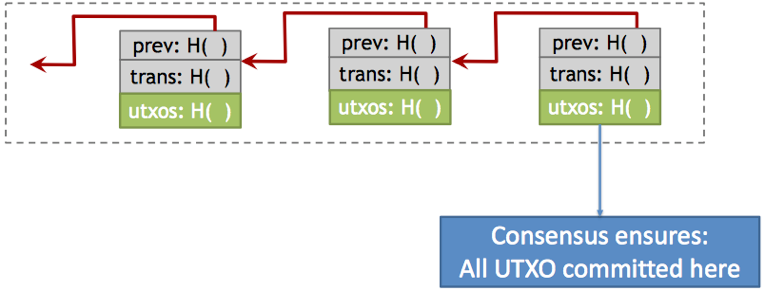
应对策略?1)TXO commitment by Peter Todd;2)output consolidation when fees are low;3)good coin selection algorithm is important, specially for exchanges。
##How Much Privacy is Enough? Threats, Scaling, and Trade-offs in Blockchain Privacy Protocols
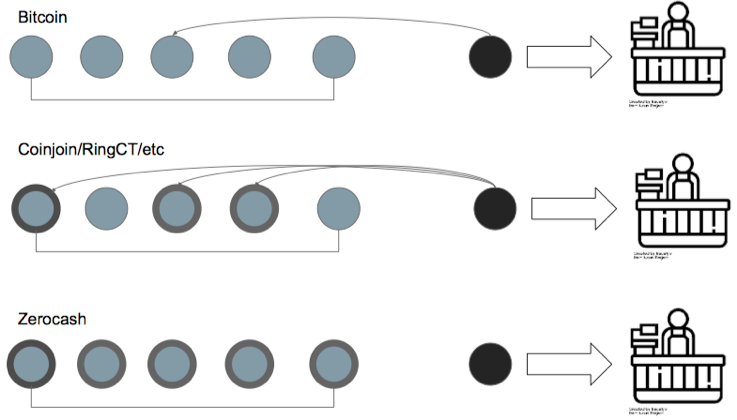
Bitcoin地址仅仅提供了化(Pseudonymity)而非匿名(Anonymity),通过交易分析,可以逆向地址的化名特性,相关工作参见下图中列出的工作。
讨论数字货币的隐私问题,首先需要考虑如何评估隐私?这跟1992年时候讨论Internet的隐私问题非常类似。不能仅根据经验主义进行评估,而需要进行一个思想实验,这就需要先了解一些真是的威胁。Google、Facebook、Mastercard、Target、Venmo等公司极大侵犯了个人隐私。
数字货币领域的Fungibility问题与Internet上的隐私问题类似,因为历史干净的Coin可能更受欢迎,交易所可能会根据历史交易针对用户采取特定措施(相对于区块上的历史交易图谱,交易所了解更多信息)。相关的应对措施?“In a world of AL/ML and targeted ads, plausible deniability is not a plausible defense.”当前的区块链隐私保护技术在上图有粗线条的展示。
Blockchain privacy is not intuitive。不仅存在被动的观察者,也存在主动的攻击者,通过与目标用户进行交易来获取信息。上图中的技术,大概分3类:
接下来的报告关注decoy system是否具有足够的隐私,当前的decoy system不够安全。通过taint tree分析可以跟踪客户、识别匿名的店主,而通过粉尘攻击则可以在decoy system中观察到某人的资金流动。如果想要用decoy system达到隐私保护的目的,Ian给出了几点建议:1)用足够大的decoy size(i.e. 5,000,000 instead of 5);2)Decoy sets substantially overlap across all recent transactions;3)Decoys are sampled really carefully。但是仍然需要进行更详尽的分析以搞明白隐私保护在什么情况下失效并界定decoy system的能力边界。随后Ian给出了scalable decoy schemes需要满足的条件:
在最后,Ian给出scalability与privacy关系的思考(见下图),其中个人最有感触一点:privacy problems don’t magically go away with small tweaks。
额外参考An Empirical Analysis of Traceability in the Monero Blockchain【https://arxiv.org/pdf/1704.04299/】讨论Monero的隐私问题
##Playing With Fire: Adjusting Bitcoin's Block Subsidy
####Anthony Towns (Xapo)
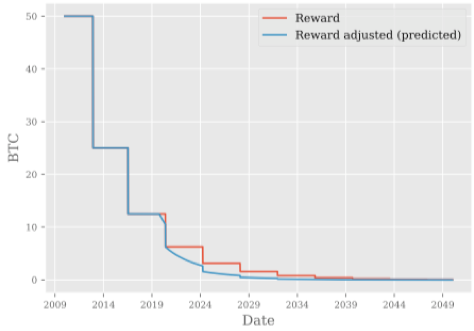
很有争议的题目也是很有争议的报告,确实是在玩火(Anthony Towns的个人标签里有Bitcoin Core),考虑到当年区块扩容的场景。报告的中心主题,通过更改Bitcoin的挖矿奖励方式(仍然保持货币总量不变),有可能在未来降低Bitcoin网络挖矿的电力消耗。当前的挖矿奖励是每4年折半一次,Anthony给出的一个具体的方案(甚至给出了该提议的实现方案)根据全网算力的变化来计算挖矿奖励,而不是机械的每4年减半一次,例如:算力每翻倍一次,挖矿奖励就减少20%。
为了说明自己并不是真的在担心挖矿的电力消耗,Anthony首先明确了观点“saying Bitcoin uses too much energy is saying it should be less secure”。但是为什么会有人担心Bitcoin挖矿消耗了太多电力,Anthony给出了以下几个原因,看起来非常合理:
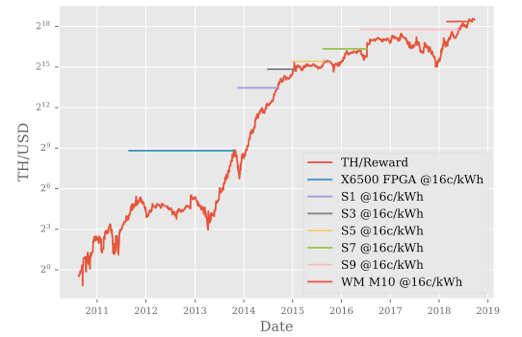
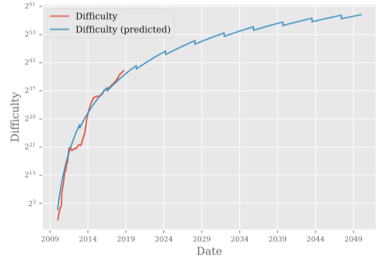
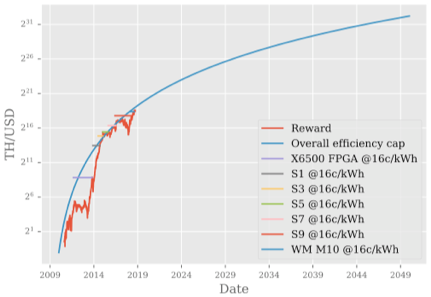
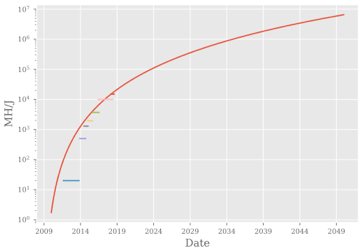
但是这些争论都是定性的讨论,是否能够定量讨论相关问题,也是接下来报告的重点。Anthony在Hashrate(TH/s),Electricity(kWh/year)和Value(USD)中选用TH/USD指标来进行讨论
基于TH/USD指标进行定量讨论,根据上述图标,有以下观察:
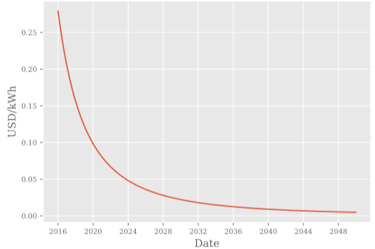
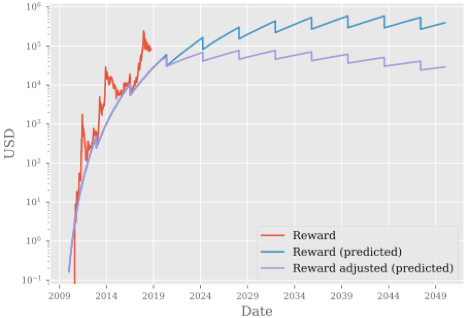
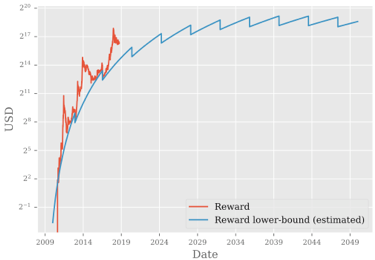
基于以上观察,Anthony尝试做出一些预测,但是Bitcoin中挖矿会收到各方面因素的影响:币价、矿机效率和电费。如果对这三个因素的如下假设
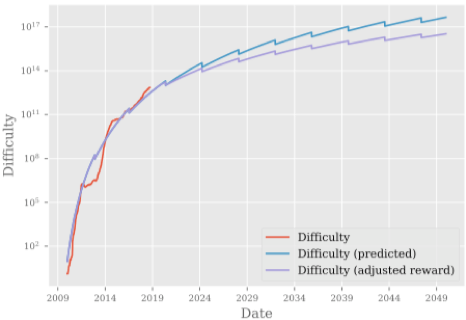
基于上述假设Anthony对奖励(USD)、挖矿难度、电力消耗做以下预测:
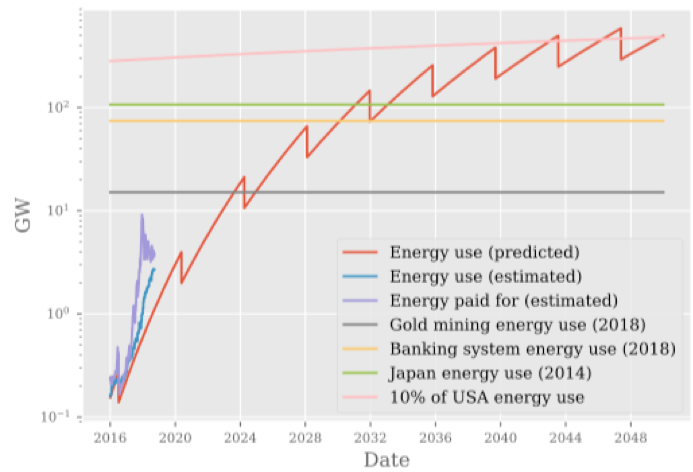
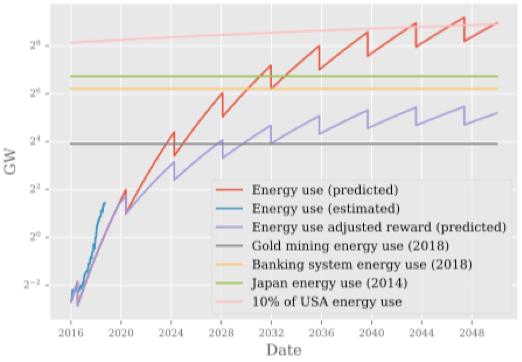
根据上述预测,Bitcoin的电力消耗并没有传说中的那么恐怖“Bitcoin Mining on Track to Consume All of the World's Energy by 2020”,但是电力消耗也足够多,促使人(Anthony)重新思考如何降低电力消耗。因此有了提议:
报告中给出了详细的技术细节来实现这一提案,此处略去不讨论。上述方案的部署,会带来怎样的效应,Anthony继续给出了如下预测图表:
随后Anthony继续提到,这一提案还有别的用处:1)Smothing the halvening schedule;2)Smoothing fee income when a fee market eventuates;3)As a cost mechanism for allowing temporary increases in the block weight limit。或许有别的方式能达到同样的效果,报告中未详细提及。报告最后,Anthony也说到,这不会是个win-win-win的提案:
##Forward Blocks: On-chain/Settlement Capacity Increases Without the Hard-fork
Slide首页标注报告人Mark:No organizational affiliation,但是Google得到的信息Mark似乎是Blockstream的cofounder。值得注意的是,在这个报告中也提及了修改挖矿奖励。Forward Blocks协议目标是用soft-fork的方式修改PoW机制,并且用soft-fork的方式实现privacy-enhancing alternative ledgers,但是后来发现该协议还带来额外的好处:1)Improved censorship resistance through sharding;2)Direct on-chain scaling up to 3584x (for bitcoin specifically)。同时还能其他益处:1)linearized block subsidy;2)将来支持confidential transaction和sidechain。
为了便于讨论,Mark首先给出了soft fork和forwards compatible soft fork的定义,其主要差别在于未升级的节点在后一种fork的情况下仍然能够接收并处理所有的交易。协议的第一个组件是Dual PoW through soft fork。这并不意味着对一个块执行两次PoW机制。Forward Blocks协议中包含separate chains with separate PoW,不同的链上的PoW机制所采用的Hash选择在协议中并没有明确给出,报告中Mark也特意讨论了这一可能的争论点,并说自己不做推荐。
Onchain scale的一个自然的想法是提高区块上限。之前已经讨论过的安全提高区块上限的措施是通过forced hard fork:“move transactions into a committed extension block with higher aggregate limits—and/or any other consensus changes—and then force the old blocks to be empty”。这种升级方式的问题在于未升级的节点再也看不到交易数据,因此只能被迫升级。并由此因此了Forward blocks协议的出发点:
Mark在报告中继续讲到“A Smooth Subsidy Schedule”的主题,具体说来是eliminate the “halvening” with a continuous subsidy curve,不过是针对forward block进行的区块奖励调整,但是要保证区块货币总量不超过2100w个上限并且在任意时间调整后的累计奖励不能超过Bitcoin原计划中累计奖励太多。(个人认为:通过调整forward block chain的奖励,可以影响compatibility block
chain中的区块奖励,通过合适的参数配置,应该可以达到前一个报告中Anthony提案的类似效果)“Most notably, we can use this opportunity to smooth out the step function used to calculate subsidy, making subsidy a continuous function”调整后的区块奖励的变化更为平滑,见图:
接下来Mark继续讨论multiple forward block chains,基本idea是,如果可以有一个forward block chain,也可以有多个multiple forward block chains。基本动机是,可以将一个forward block chain“分片”(与以太坊、ZILLIQA中的Sharding概念有区别)为多条链,每条链的UTXO集合无交集。通过将forward block chain分片为M条链,要求交易只能花费一个分片中的coin,并且每条链用不同的PoW机制(separately-salted work function)。注意每个shard chain中还是以15分钟的间隔生成区块,这样大约每15min/M就可以产生一个shard block,能够达到“M-fold increase in censorship resistance for a given aggregate weight across all shards, if activity is evenly distributed amongst the shards.”可以用前述的coinbase方法在shards之间进行value transfer。
一番折腾之后,理论上会有多少TPS的提升?Mark在下图的slide中给出了理论的上界(利用time warp bug缩短compatibility block chain的区块间隔在保证compatibility时的理论上限),结果比较有意思,基本可以支持1tx/pp/day的目标,即支持地球上每个人每天在Bitcoin上发送一笔交易。
在报告的最后,还提及coinbase payout queue还有别的用处(Generalized ledger transfer mechanism)。还不太理解这部分,需要研读相关论文。
##Self-Reproducing Coins as Universal Turing Machine
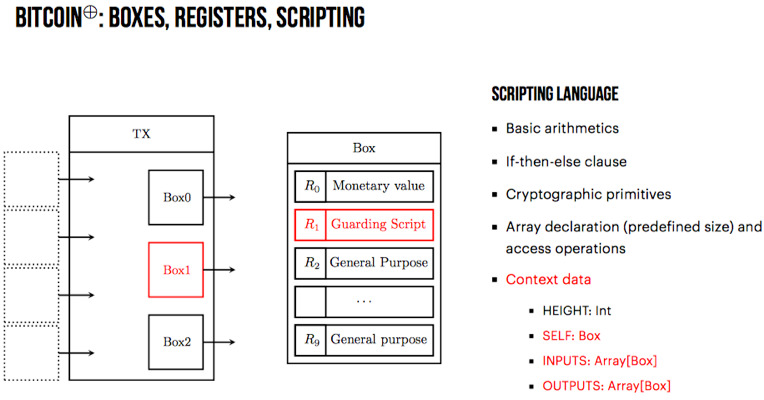
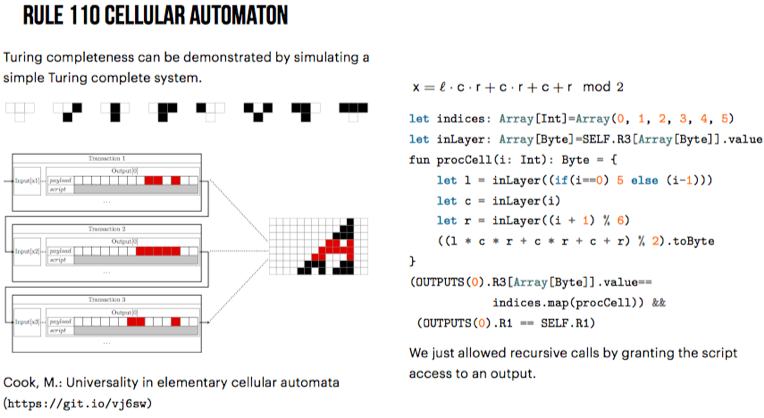
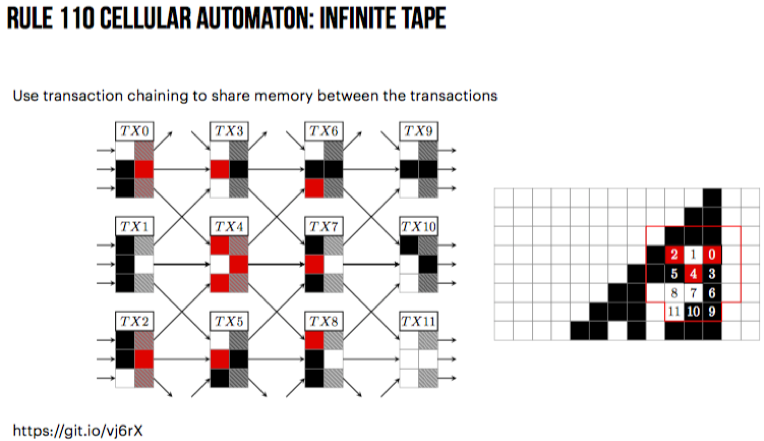
挺有意思的一个报告,展示了do more with less的方法论。相关工作的基本结论是:“Turing-completeness of a blockchain system can be achieved through unwinding the recursive calls between multiple transactions and blocks instead of using a single one”。通过在UTXO模型下构建一个简单的通用图灵机(universal Turing machine)的展示证明了这个结论。
在上述操作的基础之上,展示了这些操作足够达成图灵完备目标。“Turing completeness can be demonstrated by simulating a simple Turing complete system”。另外有工作证明复杂度学科中的Rule 110元胞自动机是图灵完备的。所以通过展示利用上述操作可以模拟Rule 110元胞自动机的执行,就可以证明在UTXO模型下如果脚本语言支持以上语言特性,则该脚本语言是图灵完备的。
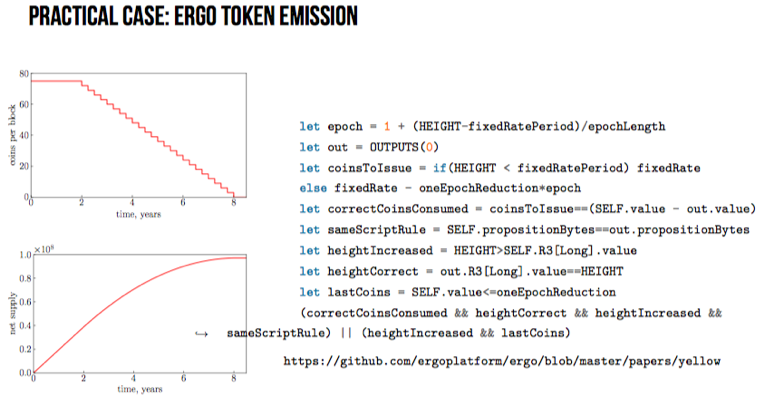
在关于上述构造的实际应用方面,报告给出了如下几个方面:1)Crowdfunding;2)Demurrage currency;3)Oracles(w. authenticated state);4)Decentralized exchanges。并给出了ERGO项目中Token实例:
最后报告给出了几个结论:1)图灵完备的区块链系统可以通过在交易之间展开递归调用达成;2)提供了Ergo区块链脚本系统的图灵完备证明;3)该构造方式非常明确并且功能已经完整实现;4)Self-reproducing coins allow one to make practical constructions,例如很多的验证操作可以从硬编码转到脚本语言层,更进一步则可以实现任意复杂的逻辑。
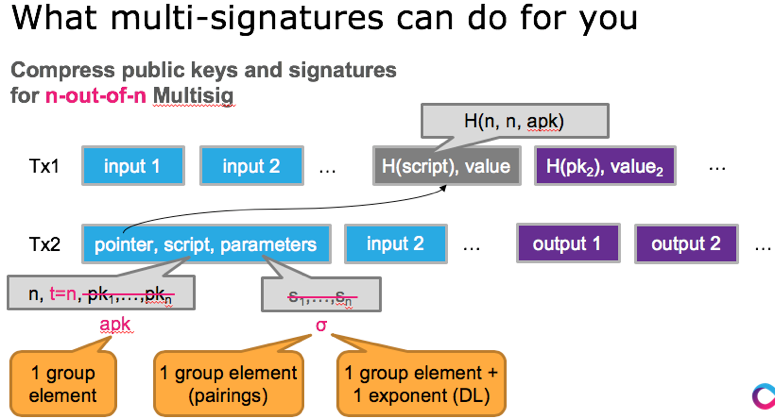
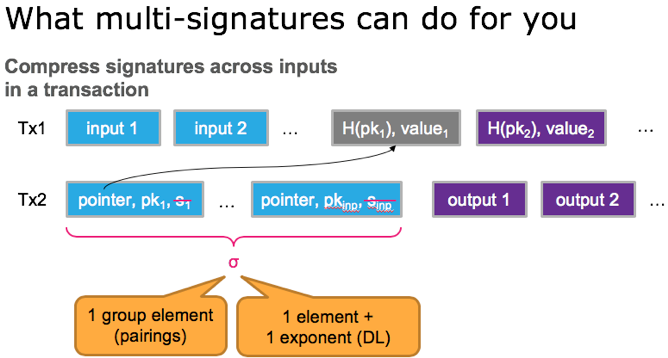
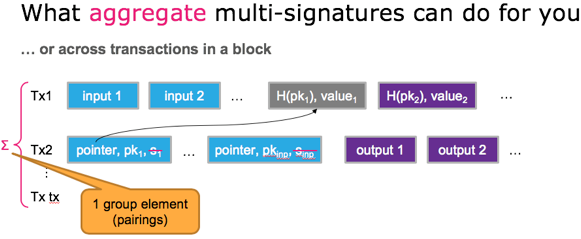
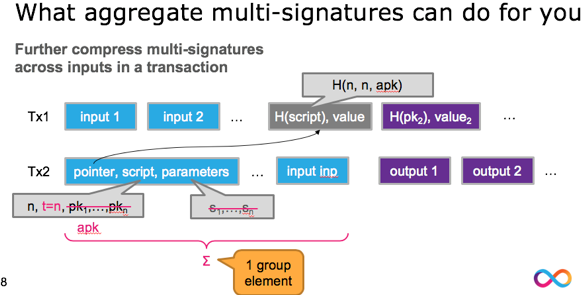
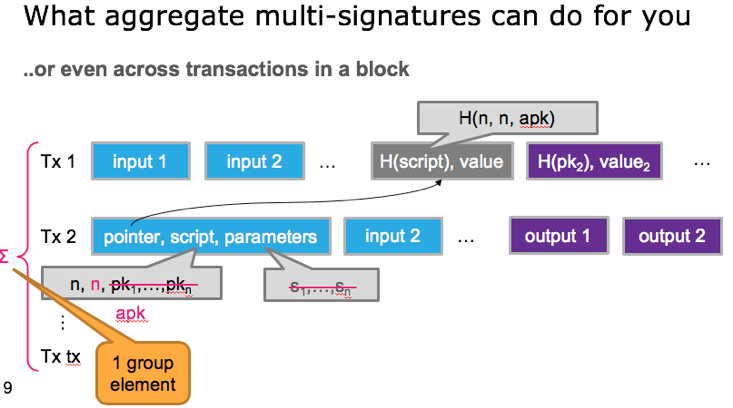
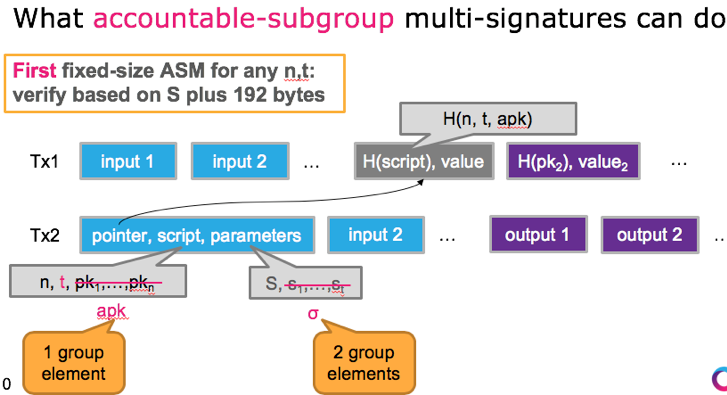
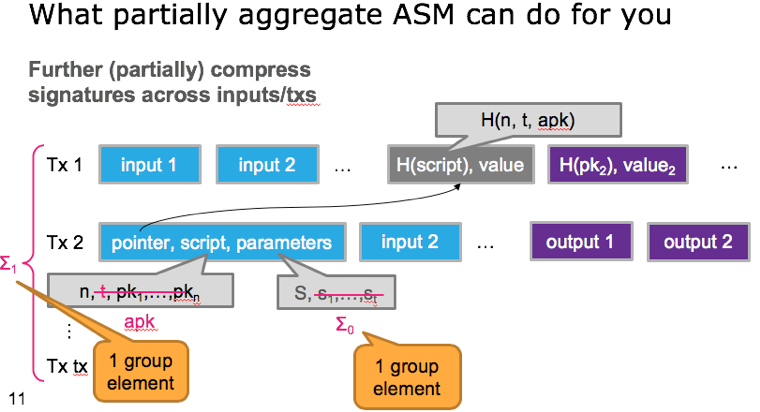
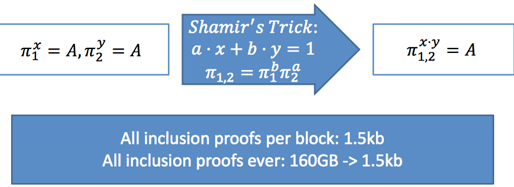
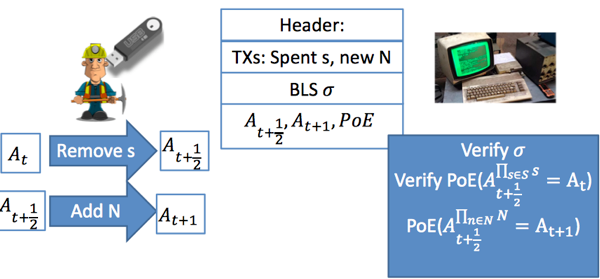
另外,这项工作还描述了aggregate multi-signature scheme (AMSP)用来将不同交易的多个签名值压缩成一个聚合签名。Aggregate multi-signature scheme lets each of the n parties sign a different message, but all these signatures can be aggregated into a single short signature. aggregate multi-signature可以看成是更广义的multi-signature,不仅可以在一个交易内部进行签名压缩,而且可以在交易之间进行压缩(将一个区块内的所有交易的签名压缩),参加下面3个图片示例。
此外,这项工作还构造了第一个accountable-subgroup multi-signature scheme(ASM)。An ASM enables any subset S of the n parties to jointly sign a message m, so that a valid signature implicates the subset S that generated the signature; hence S is accountable for signing m. The verifier in an ASM is given as input the (aggregate) ASM public key representing all n parties, the set S ⊆ {1, . . . , n}, the multi-signature generated by the set S, and the message m. 值得指出的,任意安全的签名体制都能够构造出ASM算法,例如比特币中的多签机制,多个签名的级联其实就是accountable multi-signature,只是公钥大小与组内成员个数n呈线性关系,而签名大小与参与签名的人员个数S呈线性关系。Boneh等人在这个工作中给出ASM的构造,签名大小在S的描述之外仅与安全参数k有关系,与n的大小无关,而公钥大小也为常量。就密码算法构造角度来讲,ASM是这项工作中最具创新性的工作。ASM机制允许在多签交易中设定任意的阈值,而且在解锁脚本中也无需重复列出所有的公钥。同样的ASM也可以在多个交易之间做压缩。
各签名算法之间的区别在下图中总结。还没有时间深入理解,但是聚合签名算法,BCH支持大区块的路线图中,也许可以用来降低计算量,在多个维度进行签名(或者公钥的聚合):1)在multisig交易中;2)在交易的多个input之间;3)在一个块内的所有交易之间。这个方向值得深入跟踪下。
##Improving SPV Client Validation and Security with Fraud Proofs
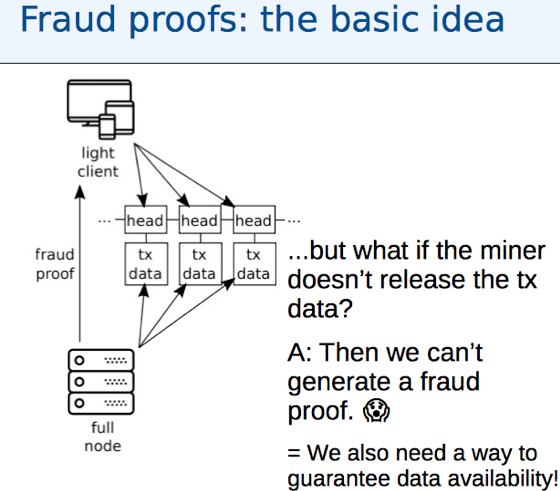
汇报的是V神参与的研究成果,关注如何利用Fraud Proofs增强SPV节点的安全性,问题来源于当前的SPV节点会接受非法的区块,因为SPV的安全性基于诚实的大多数这一假设。报告也从该问题出发:how can we make non-fully validating (SPV) nodes reject invalid blocks, so that they don’t have to trust miners? 链接中的论文摘要中阐述了这一工作的目标与意义:“By allowing such clients to receive fraud proofs generated by fully validating nodes that show that a block violates the protocol rules, and combining this with probabilistic sampling techniques to verify that all of the data in a block actually is available to be downloaded, we can eliminate the honest-majority assumption, and instead make much weaker assumptions about a minimum number of honest nodes that rebroadcast data. Fraud and data availability proofs are key to enabling on-chain scaling of blockchains (e.g., via sharding or bigger blocks) while maintaining a strong assurance that on-chain data is available and valid.”。
之前已经有部分关于fraud proof的工作,Bitcoin的白皮书中简略提到了“alerts”,全节点利用该消息通知SPV节点某个区块是非法的。Maxwell和Todd在“compact fraud proofs”方向上做了部分研究工作,早期的提案对不同规则的违反需要不同的fraud proof,汇报的内容在这个基础上进行改进。G. Maxwell has discussed on IRC using erasure coding for data availability with a scheme using a “designated source” with PoW rate-limiting (and no way to deal with incorrectly generated codes?)。
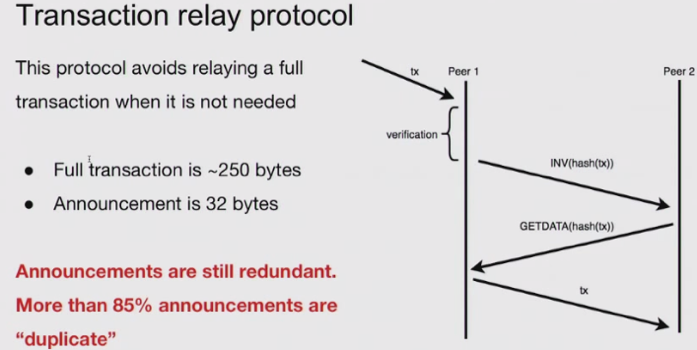
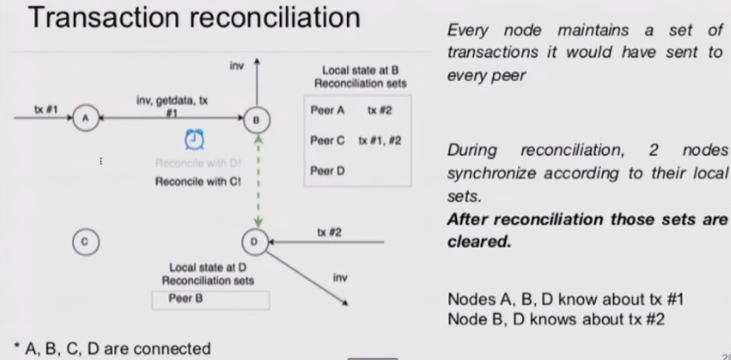
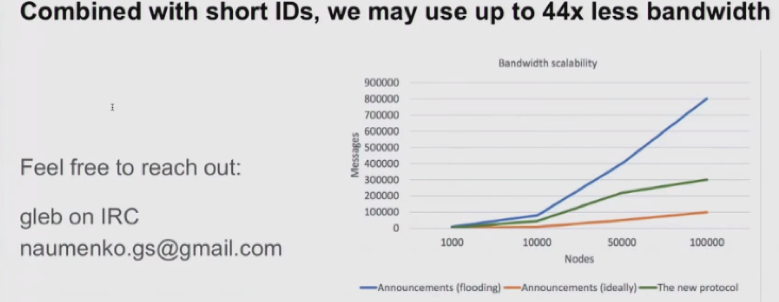
新协议包含两部分:low-fanout flooding (to relay txs only to a fraction of all network nodes)以及 transaction reconciliation(to bridge gaps)。Set reconciliation的目标是使拥有不同tx集合的两个节点A、B以最少的通信量计算并集。新协议允许利用short tx IDs来进行交易声明,并将带宽占用降低至原先的1/44。值得注意的是,BCH社区提出的Graphene协议也用set reconciliation技术减少带宽利用。
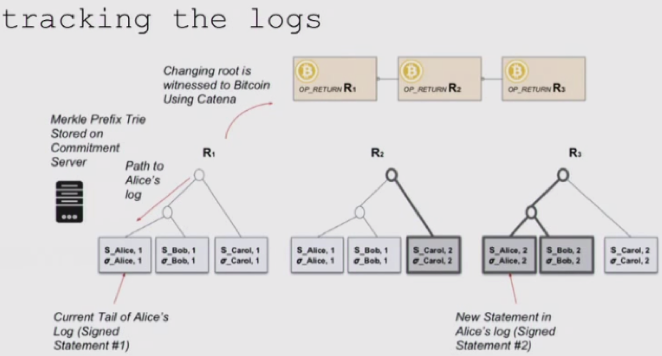
##WIP | b_verify
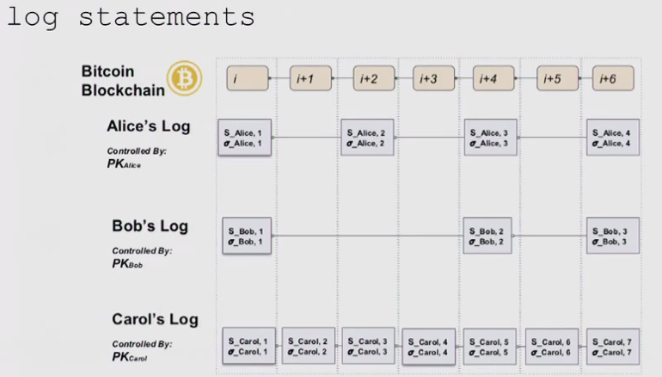
b_verify: a protocol that makes equivocation as hard as double spending on Bitcoin by providing the abstraction of multiple independent logs of statements in which each log is controlled by a cryptographic keypair.
Equivocation: is the deliberate presentation of inconsistent data by a participant within a system.
Perfect world意味着至少有一个诚实Commitment Server(CS),并检查其他CS提交的数据。网络中的每一方V有公私钥,并相互独立。每一方V用b_verify客户端将各自的观测存储到日志数据中,然后CS将日志数据组织成ADS(应用Merkle Patricia Tree,MPT),数据的改变(树根)通过Catena存储到Bitcoin区块中(OP_RETURN的output)作为见证。依赖MPT的认证特性与Bitcoin网络,可以保证日志和见证数据不被随意修改。
未解决的问题也即能够破坏b_verify协议的隐患,也是一开头perfect world假设存在的原因:
1)diabolical commitment server的问题如何解决?
2)malicious Bitcoin peer can hide new witness transactions from a light client
应用场景:1)公开可验证的注册服务;2)供应链中的数据管理
问题:跟open timestamp有什么区别?从提供的功能上貌似是一样的?
https://opentimestamps.org/ (主要区别是用CS?,演讲人不确定as WIP)
问题:使用BCH岂不是会更好一些?更低手续费?OP_RETURN的大小?
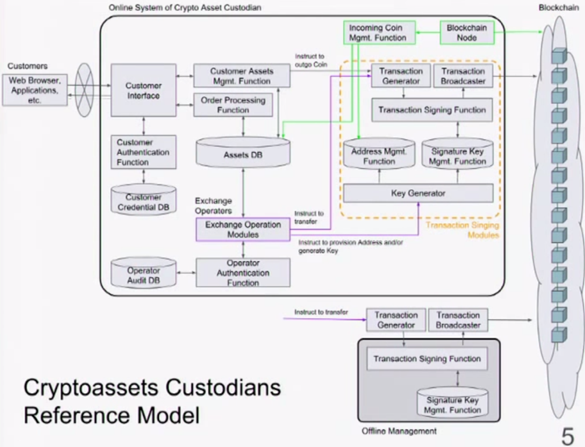
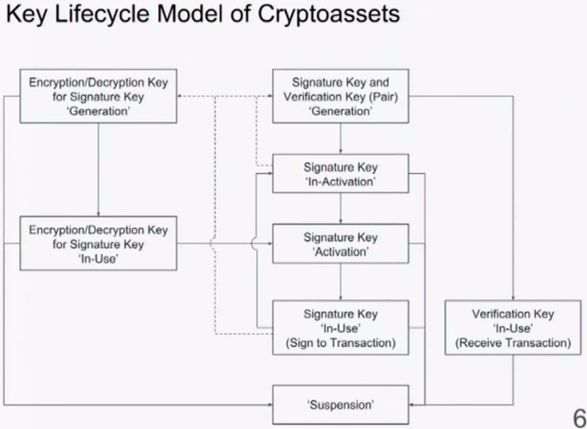
##Introduction of Internet-Draft: General Security Considerations for Crypto Asset Custodians
已经有太多安全事故,我们应该从过去的事故中学到经验教训。
Goals:
1) build a base document for crypto assets custodian’s security best practices
2) share lessons from past incidents without violating a confidentiality obligation (e.g. criminal investigation)
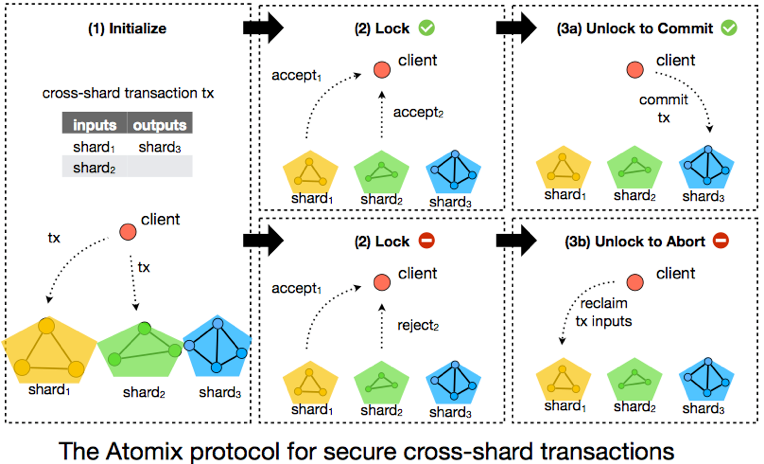
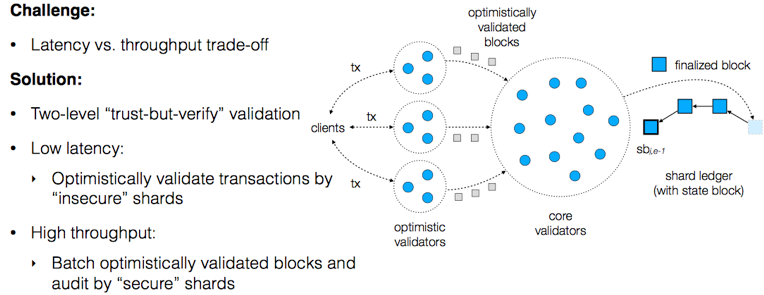
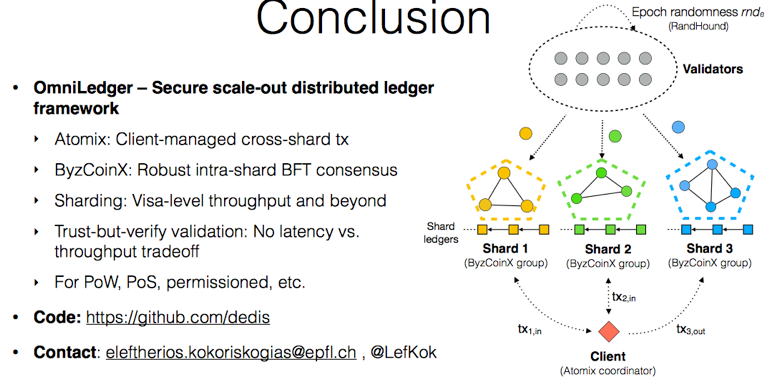
##OmniLedger: A Secure, Scale-Out, Decentralized Ledger via Sharding
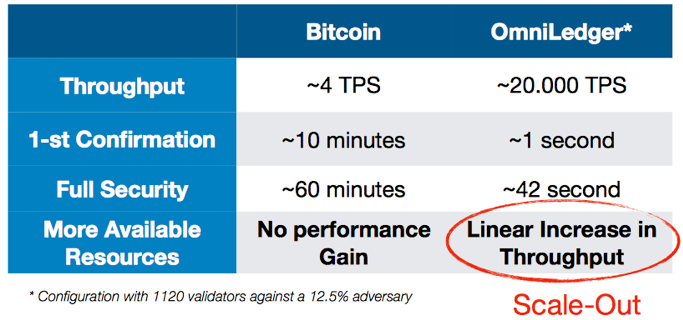
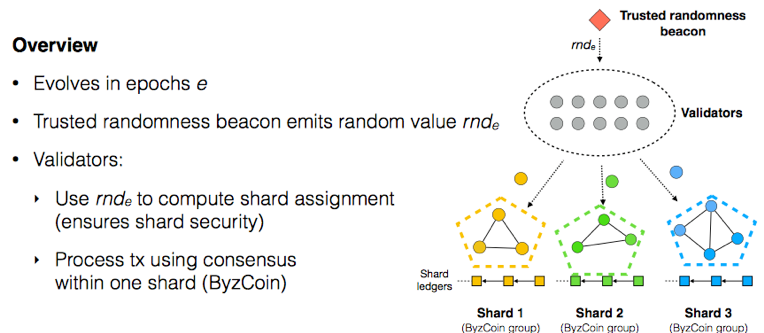
报告以OmniLedger与Bitcoin之间的TPS、确认时间等维度的对比开始,最重要的区别在于OmniLedger在有更多资源时(网络中更多的参与节点),其TPS随着资源线性增长(也即Sharding)。
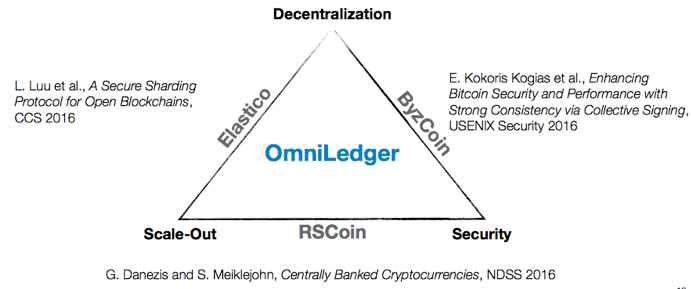
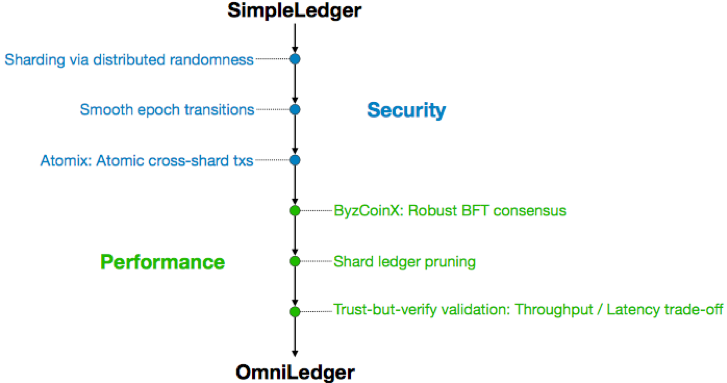
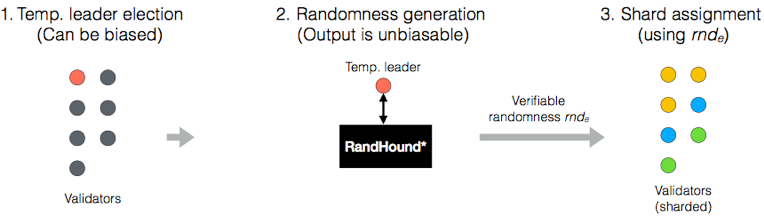
OmniLedger是新设计的区块链结构,汲取了近几年提出的新理念,包括Bitcoin-NG、Luu等人提出的Sharding理念、CollectiveSigning等,结合基于RandHound方法进行节点的随机选择分派。
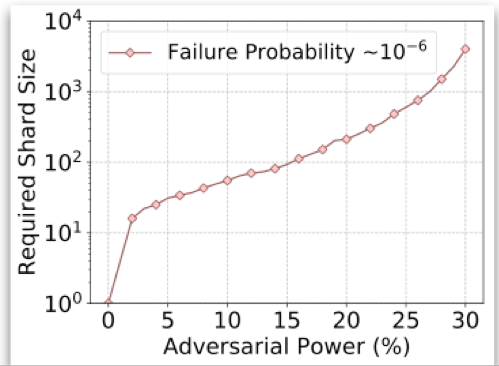
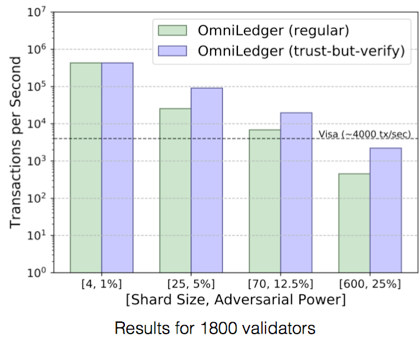
做Sharding时如果节点可以自由选择加入哪个分片,则恶意节点可以集结到同一个分片从而操控该分片。所以OmniLedger采用了随机分配的方式,过随机分配,在每个分片内都含有较多节点的情况下,可以保证高安全性,如下图所示,即使在有25%的恶意节点的条件下,每个分片内分配1000个节点,可以将失败概率控制在10^-6之下。
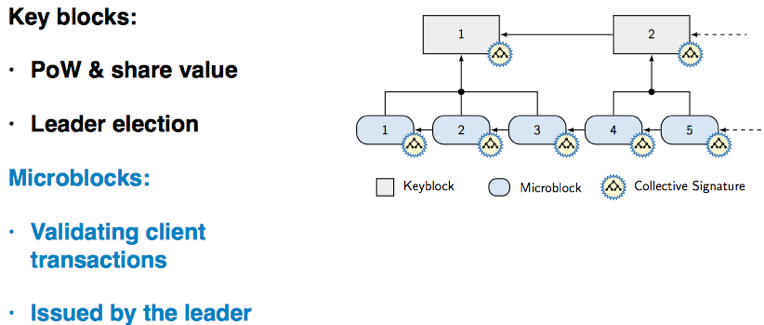
Bitcoin-NG的基本思想是在保持Bitcoin的10分钟PoW出块的前提下,在两个区块的间隔中通过生成microblock(利用签名做不可篡改保证,前一个PoW区块产生的节点在这个区间内有权生成microblock并用自己的私钥签名)继续打包tx,由此提高Bitcoin网络的TPS。然而Bitcoin-NG的构造中有重大缺陷,但是这个idea结合Sharding、PBFT等方法启发了多个后续工作,包括ByzCoin、ELASTICO和ZILLIQA等,OmniLedger是这个方向上的又一新的成果,发表在安全顶会IEEE S&P 2018,也是我个人一直比较喜欢的一个工作。在Sharding方向,cross-sharding通信一直是个难度,OmniLedger第一个(我所了解到的信息)明确针对这个问题给出解决方案(优雅程度另说)。
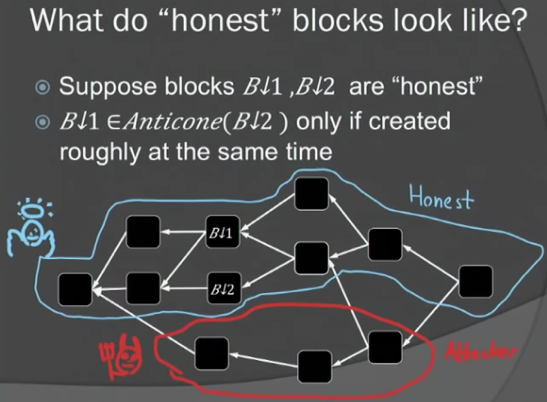
报告首先回顾了Bitcoin的共识协议,并介绍PHANTOM协议改动的地方
PHANTOM协议带来的好处是:security no longer breaks at higher throughput.但是latency会增加,也没有解决存储、验证时间等scaling相关的问题。
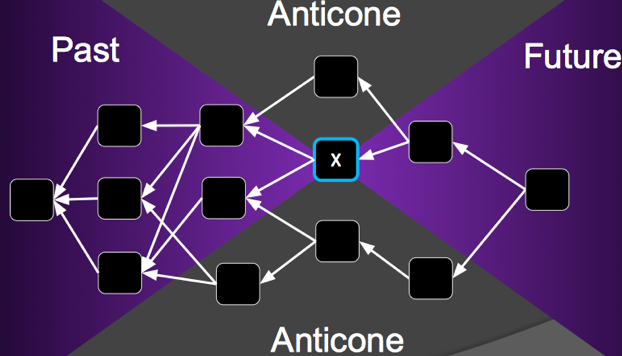
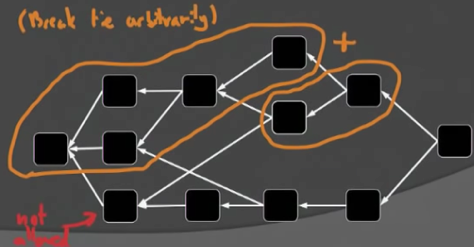
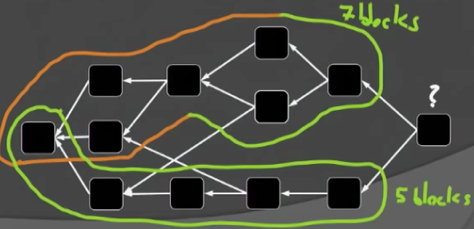
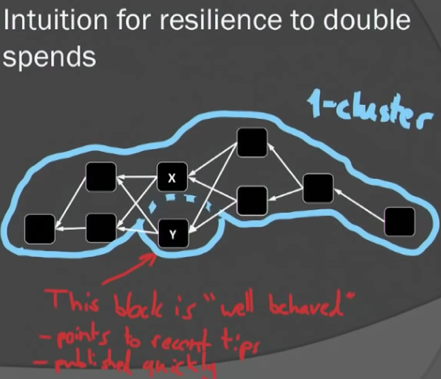
为方便讨论,先给出一些术语。Past区块是指被区块x直接或间接指向的区块,Future区块是指被区块x影响的后续区块,而Anticone的区块则是剩下的那些区块,没有被x直接或间接引用,也不直接或间接应用区块x。
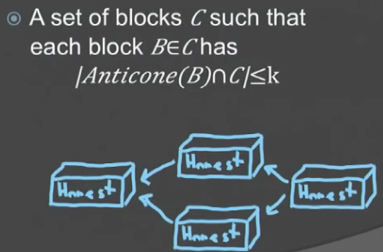
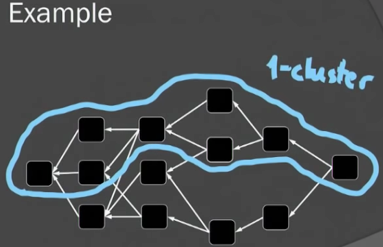
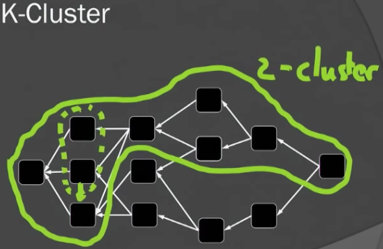
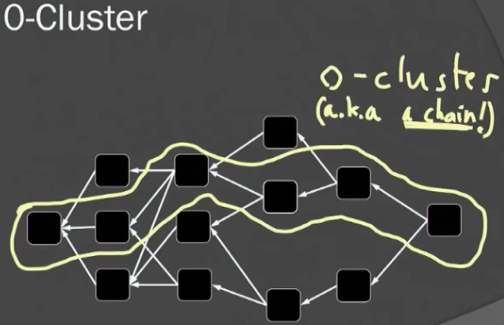
根据上述k-cluster的概念,不难想象中0-cluster其实就是Bitcoin中的链。也即k-cluster DAG是比chain更为广义的概念。
从k-cluster的概念出发,Zohar给出了PHANTOM协议概貌: pick a max weight k-cluster in the DAG, then sort it topologically in some canonical way。
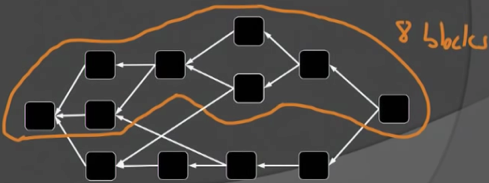
上述过程的难点在在于,在DAG中寻找maximal k-cluster是NP-Hard的。Zohar等人在这项工作中给出的解决方案是:用贪婪算法来获得k-cluster,由此有了名字:GHOST-DAG protocol。
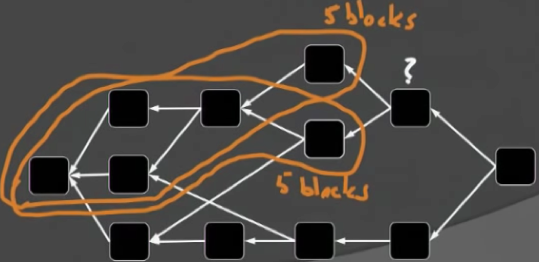
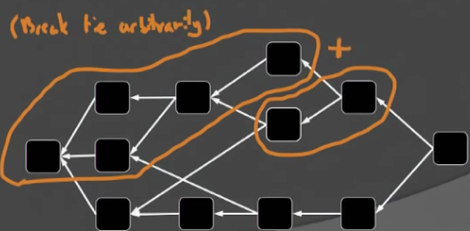
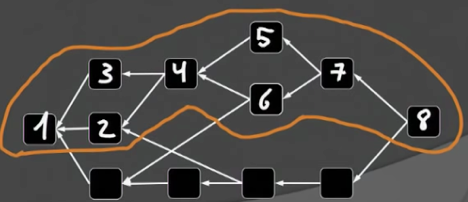
GHOST-DAG协议的核心思想也非常简单:1)each block inherits the “heaviest” k-cluster from one of its predecessors;2)adds blocks greedily (as long as still a k-cluster)。
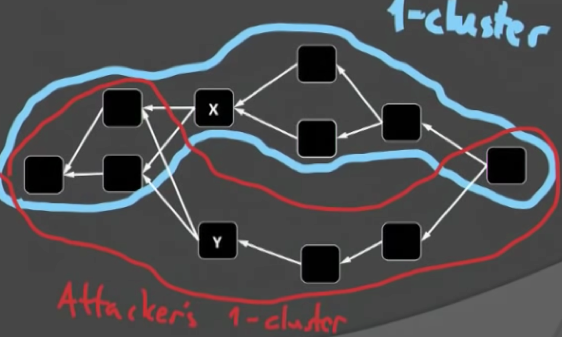
根据上述两条原则,在上图中,带?的区块在选择父辈区块时,两个可能的父辈区块的k-cluster包含的区块个数都是5,此时做一个随机选择就可以,然后在保持k-cluster性质的基础之上,将尽可能多的区块包含到当前的k-cluster集合中。